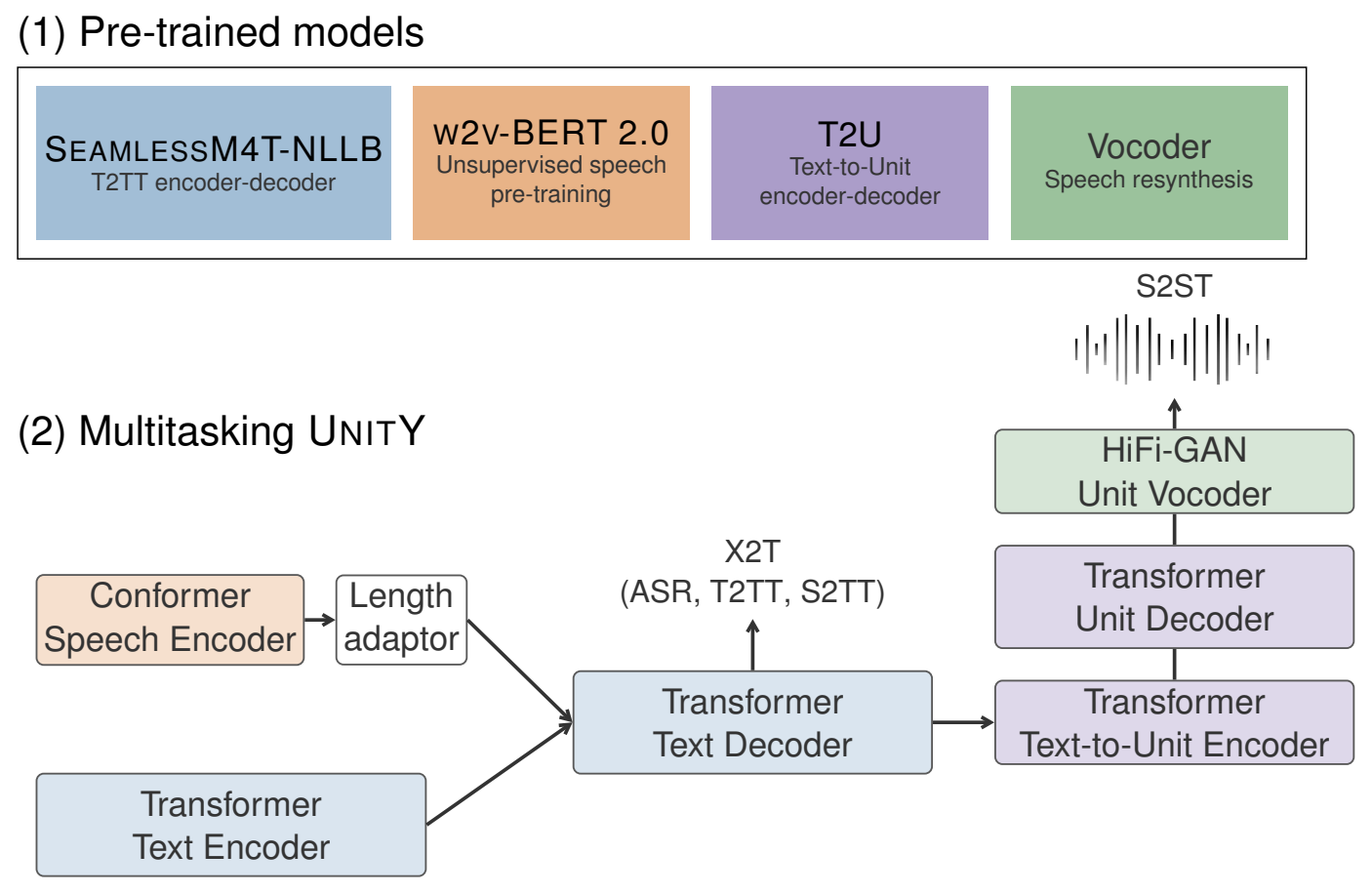
SeamlessM4T — Massively Multilingual & Multimodal Machine Translation(大规模多语言和多模式机器翻译)

- ASR: Automatic speech recognition for 96 languages.
- S2ST: Speech-to-Speech translation from 100 source speech languages into 35 target speech languages.
- S2TT: Speech-to-text translation from 100 source speech languages into 95 target text languages.
- T2ST: Text-to-Speech translation from 95 source text languages into 35 target speech languages.
- T2TT: Text-to-text translation (MT) from 95 source text languages into 95 target text languages.
SeamlessM4T 概述
安装 [Seamless Communication][seamless_communication]
克隆仓库 git clone https://github.