开源 OCR 引擎基准测试
OCR 引擎
EasyOCR 支持 80+ 语言。
Abaza = 'abq'
Adyghe = 'ady'
Afrikaans = 'af'
Angika = 'ang'
Arabic = 'ar'
Assamese = 'as'
Avar = 'ava'
Azerbaijani = 'az'
Belarusian = 'be'
Bulgarian = 'bg'
Bihari = 'bh'
Bhojpuri = 'bho'
Bengali = 'bn'
Bosnian = 'bs'
Simplified_Chinese = 'ch_sim'
// ...
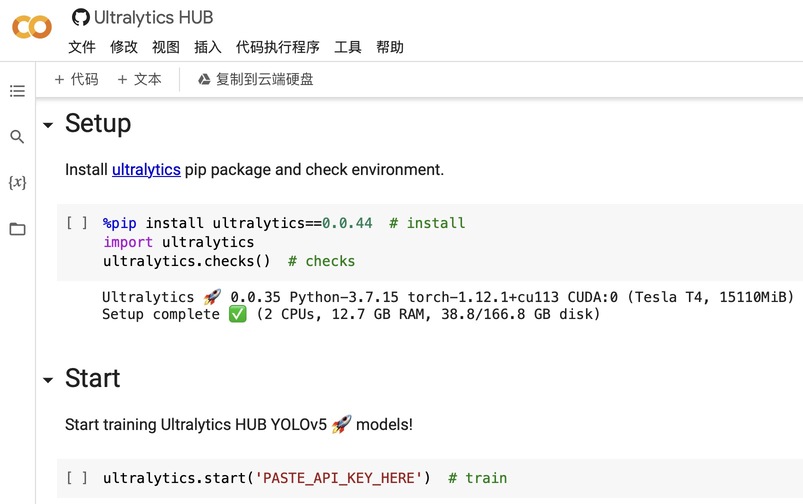
安装
pip install torch==2.0.1 torchvision==0.15.2 -i https://download.pytorch.org/whl/cpu
pip install easyocr
代码示例 import easyocr languages = ['ch_sim', 'en'] model = easyocr.

















{kind=link}
{kind=link}