31 篇文章带有标签 “machine-learning”
Open Source Models with Hugging Face
Natural Language Processing (NLP)
安装依赖库
pip install transformers
Conversational
生成式AI
机器学习的方法
监督学习(Supervised Learning)
监督学习使用带有标签的训练数据来训练模型。这些标签是预先定义的输出,模型通过学习输入数据与这些输出之间的关系来进行预测。监督学习的任务通常分为两类:分类(预测离散的标签)和回归(预测连续的数值)。常见的监督学习算法包括决策树、逻辑回归、支持向量机(SVM)、神经网络等。监督学习广泛应用于图像识别、语音识别、医疗诊断等领域。
无监督学习(Unsupervised Learning)
无监督学习不依赖于标签数据,而是试图在没有明确指导的情况下发现数据中的结构和模式。它的主要任务包括聚类(将数据分组到不同的簇中)和降维(减少数据的复杂性,同时保留其主要特征)。无监督学习常用于市场细分、社交网络分析、异常检测等场景。算法示例包括K-means聚类、主成分分析(PCA)等。
自监督学习(Self-Supervised Learning)
自监督学习是一种无监督学习的形式,它通过从数据本身生成伪标签来创建监督信号。这种方法通常涉及到设计任务,使得模型能够从数据中学习有用的特征表示,而不需要人工标注。自监督学习在计算机视觉和自然语言处理中尤其流行,例如,通过预测图像的旋转角度或文本的下一个字来训练模型。这种方法有助于减少对大量标注数据的依赖,同时为下游任务提供预训练的模型。
生成式AI(Generative AI) 生成式AI的目标是
Hugging Face NLP Course
1. TRANSFORMER 模型
自然语言处理
NLP 是语言学和机器学习交叉领域,专注于理解与人类语言相关的一切。 NLP 任务的目标不仅是单独理解单个单词,而且是能够理解这些单词的上下文。
以下是常见 NLP 任务的列表:
- 对整个句子进行分类:
- 获取评论的情绪
- 检测电子邮件是否为垃圾邮件
- 确定句子在语法上是否正确
- 确定两个句子在逻辑上是否相关
- 对句子中的每个词进行分类:
- 识别句子的语法成分(名词、动词、形容词)
- 识别句子的命名实体(人、地点、组织)
- 生成文本内容:
- 用自动生成的文本完成提示
- 用屏蔽词填充文本中的空白
- 从文本中提取答案:
- 给定问题和上下文,根据上下文中提供的信息提取问题的答案
- 从输入文本生成新句子:
- 将文本翻译成另一种语言
- 总结文本
- 语音识别:
- 生成音频样本的转录
- 计算机视觉:
- 生成图像描述
- 目标检测
Transformers 能做什么?
Transformers 库中最基本的对象是 pipeline() 函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够通过直接输入任何文本并获得最终的答案:
MLX LLMS Examples
克隆代码
git clone https://github.com/ml-explore/mlx-examples
cd mlx-examples
创建虚拟环境
python -m venv env
source env/bin/activate
pip install -r llms/phi2/requirements.txt
pip install -r llms/qwen/requirements.txt
创建大模型链接 mkdir llms/phi2/microsoft ln -s /Users/junjian/HuggingFace/microsoft/phi-2 llms/phi2/microsoft/phi-2 mkdir llms/qwen/Qwen ln -s /Users/junjian/HuggingFace/Qwen/Qwen-14B-Chat llms/qwen/Qwen/Qwen-14B-Chat ln -s /Users/junjian/HuggingFace/Qwen/Qwen-1_8B llms/qwen/Qwen/Qwen-1_8B ln -s /Users/junjian/HuggingFace/Qwen/Qwen-1_8B-Chat llms/qwen/Qwen/Qwen-1_8
MLX: An array framework for Apple silicon
统一内存:与 MLX 和其他框架的显着区别是统一内存模型。 MLX 中的数组位于共享内存中。 MLX 阵列上的操作可以在任何支持的设备类型上执行,而无需传输数据。
创建虚拟环境
mkdir ml-explore && cd ml-explore
git clone https://github.com/ml-explore/mlx
git clone https://github.com/ml-explore/mlx-examples
python -m venv env
source env/bin/activate
- 安装依赖包
cd llms/phi2
pip install -r requirements.txt
- 模型下载和转换
使用已经下载的模型
mkdir microsoft
ln -s /Users/junjian/HuggingFace/microsoft/phi-2 microsoft/phi-2
转换模型
python convert.py
这将生成 MLX 可以读取的 weights.npz 文件。
-rw-r--r-- 1 junjian staff 5.2G 12 20 20:36 weights.npz
- 运行
Transformers Pipeline
使用 Transformers 的 Pipeline 进行推理
安装依赖包
pip install datasets evaluate transformers[sentencepiece]
英文情感分类
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
)
LangChain HuggingFaceEmbeddings + FAISS
数据
weather_texts = [
"😀 今天天气舒适,心情大好。",
"😀 今天天气晴朗,阳光明媚。",
"😀 今天天气宜人,适合出门游玩。",
"😀 今天天气没有下雨,真是太好了。",
"😀 今天天气比昨天好多了,真是令人欣喜。",
"😀 今天天气晴空万里,蓝天白云,真是美不胜收。",
"😀 今天天气温暖如春,空气清新,让人心旷神怡。",
"😀 今天天气风和日丽,微风徐徐,让人心情舒畅。",
"😀 今天天气万里无云,阳光灿烂,让人精神振奋。",
"😀 今天天气秋高气爽,天朗气清,让人心胸开阔。",
"🥶 今天天气很糟糕。",
"🥶 今天天气阴沉沉的,让人心情烦躁。",
"🥶 今天天气下雨了,真是让人沮丧。",
"🥶 今天天气太热了,出门都觉得热得受不了。",
"🥶 今天天气太冷了,出门都要穿上厚衣服。",
"🥶 今天天气乌云密布,风雨欲来,真是让人提心吊胆。",
"🥶 今天天气寒风刺骨,道路结冰,真是让人寸步难行。",
"🥶 今天天气闷热潮湿,空气污浊,真是让人喘不过气来。",
"🥶 今天天气灰蒙蒙的,看不到蓝天白云,真是让人心情沉重。",
"🥶 今天天气狂风暴雨,树木倒伏,道路封闭,真是让人措手不及。"
]
Private GPT 中文 Embeddings 模型测试
文档
这里使用的文档是:合作方人员出勤及结算管理信息化支撑规则
一、出勤打卡
出勤打卡包括:正常出勤打卡、出差打卡、外出打卡、加班打卡。
1. 正常出勤打卡:指正常的出勤办公打卡。
(1)全天出勤打卡:上班打卡:8点30分之前打卡。下班打卡:17点30分之后打卡。
(2)半天出勤打卡。上午打卡时间段:8点30分之前、12点之后。下午时间段:13点之前,17点30分之后。
(3)打卡(考勤机或企业微信打卡)形式按部门要求为准,最小半天为统计单位。
2. 出差打卡:指出差地出勤办公或在途期间打卡。
(1)固定出差地打卡:打卡时间参照第1条正常出勤上下班打卡;无法定位有效范围的找部门管理员修改工作打卡位置。(具体按照各部门要求执行)
(2)出差在途打卡(使用手机外出打卡)。到车站坐车前打外出打卡一次,到达目的地后打外出打卡一次(往返同理)。下午出差的,上午需打正常出勤卡(上午正常出勤须闭环打卡);上午到达出差地的,下午需打一次外出打卡或上下班打卡。
3. 外出打卡:指外出办事打卡。提外出申请后,可以打外出卡,打外出卡时间需在申请时间内:
(1)半天外出:如外出时间在上午(12点前) 或者下午(12点后),则另外半天需正常出勤打卡。
(2)跨12点外出:如外出跨度期间包含12点,则12点前、12点后分别打外出卡即可记为合格出勤。
// ...
提示词模板 使用以下上下文来回答最后的问题。
AI 大模型
🔥 大模型
🔥 Andrej Karpathy
🔥 李沐 论文精读 如何读论文 AlexNet ResNet 零基础多图详解图神经网络(GNN/GCN) GAN Transformer BERT Pre-training ViT 卷积神经网络的两个归纳偏置:1、locality(相同区域有相同的特征);2、translation equivariance(平移等变性) local neighborhoods MAE Autoencoder 对比学习论文综述 数据增强:Crop 和 Color 的组合最有效 MoCo CLIP How to Train Really Large Models on Many GPUs?
How Diffusion Models Work
Intuition(直觉)
Making images useful to a neural network(使图像对神经网络有用)
噪声处理:添加不同的噪声级别到训练数据中。
灵感来源于物理学,你可以想像一滴墨水滴入一杯水中,最初你确切地知道它落在哪里,但随着时间的推移,你看到到扩散到水中,直到消失。
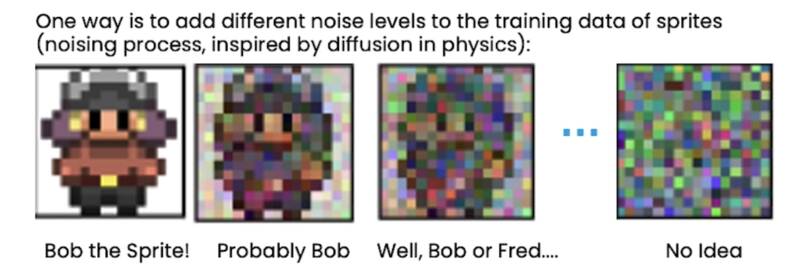
神经网络真正应该思考的是在每个噪声级别,当你逐渐向图像添加噪声时:
- Bob the Sprite!: 如果是 Bob Sprite,你想让神经网络说那是 Bob Sprite,让 Bob 保持原样。
- Probable Bob: 如果可能是 Bob Sprite,你可能想让神经网络说你知道这里有些噪声,建议可能填写的详细信息,让它看起来就像 Bob Sprite。
- Well, Bob or Fred...: 如果它只是精灵的轮廓,你想建议可能的精灵的一般细节。
- No Idea: 如果看起来什么也不知道,建议提出什么是轮廓,让它看起来更像精灵。
Training a neural network to make sprites(训练神经网络制作精灵)
神经网络学习不同的噪声图像并将它们变回精灵。
它学会消除您添加的噪声。

"No Idea" 的噪声级别很重要,因为它是正态分布的,每一个像素的采样都来自于正态分布。
Building Systems with the ChatGPT API
Building Systems with the ChatGPT API
Language Models, the Chat Format and Tokens(语言模型、聊天格式和 Tokens)
Load OpenAI API key
import os
import openai
import tiktoken
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
State of GPT - Andrej Karpathy
介绍
Learn about the training pipeline of GPT assistants like ChatGPT, from tokenization to pretraining, supervised finetuning, and Reinforcement Learning from Human Feedback (RLHF). Dive deeper into practical techniques and mental models for the effective use of these models, including prompting strategies, finetuning, the rapidly growing ecosystem of tools, and their future extensions.
了解 ChatGPT 等 GPT 助手的训练管道,从标记化到预训练、监督微调和人类反馈强化学习 (RLHF)。 深入研究有效使用这些模型的实用技术和心智模型,包括提示策略、微调、快速增长的工具生态系统及其未来的扩展。
PaddleSpeech 快速入门
介绍
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
功能
- 语音识别
- 语音合成
- 声音分类
- 声纹提取
- 标点恢复
- 语音翻译
学习
安装
conda create -n paddlespeech python==3.10.9
conda activate paddlespeech
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install pytest-runner paddlespeech
pip install "numpy<1.24"
测试数据下载
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
FAQ paddlespeech asr --lang zh --input zh.
Hugging Face 快速入门
Hugging Face 是所有机器学习任务的大本营。 您可以在这里找到开始一项任务所需的内容:演示、用例、模型、数据集等等!
创建和托管很棒的机器学习演示
Solutions
Expert Acceleration Program(专家加速计划)- 加速您的 ML 路线图
从我们屡获殊荣的机器学习专家那里获得指导。我们组建了一个世界一流的团队,帮助客户更快地构建更好的 ML 解决方案。
机器学习的成功取决于为用例找到最佳架构、微调模型并将它们部署到生产环境中。 所有这些都需要经验和技能的正确结合。 我们的专家加速计划提供必要的技术专长,以实施最先进的技术、做出更好的决策并更快地进入市场。
- 如何为我的用例微调(fine-tune)模型? 哪些基础架构(base architectures)?多少训练数据?
- 如何优化我的模型以获得最小延迟(latency)? 蒸馏(Distillation)。汇编(Compilation)。量化(Quantization)。修剪(Pruning)。 我们可以指导您完成每一步。
- 如何优化我的生产环境? 调整您的 CPU、GPU 或 AI 加速器配置以获得最大性能。
- 如何在 SageMaker 中使用 Transformers? 模型并行性(model parallelism)、数据并行性(data parallelism)、部署(deployment)等。
OpenAI API Documentation Embeddings
文本嵌入用于衡量文本字符串的相关性。嵌入通常用于:
- 搜索(结果按与查询字符串的相关性排序)
- 聚类(其中文本字符串按相似性分组)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别出相关性很小的异常值)
- 多样性测量(分析相似性分布)
- 分类(其中文本字符串按其最相似的标签分类)
嵌入是浮点数的向量(列表)。两个向量之间的距离衡量它们的相关性。小距离表示高相关性,大距离表示低相关性。
请求格式
{
"input": "A string to be embedded",
"model": "text-embedding-ada-002"
}
响应格式 { "data": [ { "embedding": [ -0.02181987278163433, ... -0.
Large Language Models(大语言模型)
LLMS
ChatGPT
LLaMA
ChatLLaMA
ChatGLM
- GLM
- ChatGLM-6B
- Hugging Face chatglm-6b
- ChatGLM-webui
- langchain-ChatGLM
- LangChain-ChatGLM-Webui
- 闻达:一个大规模语言模型调用平台
- InstructGLM:基于ChatGLM-6B在指令数据集上进行微调
- ChatGLM-6B 结合 langchain 实现本地知识库 QA Bot
- Hugging Face chatglm-6b
Alpaca Stanford Alpaca: An Instruction-following LLaMA Mode alpaca_data.json contains 52K instruction-following data we used for fine-tuning the Alpaca model.
ChatGLM-6B 模型基于 P-Tuning v2 微调的自定义数据集
Electrical Safety Work Procedures (电力安全工作规程) 数据
人工智能服务 REST API 响应的 JSON 格式
什么是 REST API?
REST API 也称为 RESTful API,是遵循 REST 架构规范的应用编程接口(API 或 Web API),支持与 RESTful Web 服务进行交互。REST 是表述性状态传递的英文缩写,由计算机科学家 Roy Fielding 创建。
如何实现 RESTful API?
API 要被视为 RESTful API,必须遵循以下标准:
- 客户端-服务器架构由客户端、服务器和资源组成,并且通过 HTTP 管理请求。
- 无状态客户端-服务器通信,即 get 请求间隔期间,不会存储任何客户端信息,并且每个请求都是独立的,互不关联。
- 可缓存性数据:可简化客户端-服务器交互。
- 组件间的统一接口:使信息以标准形式传输。这要求:
- 所请求的资源可识别并与发送给客户端的表述分离开。
- 客户端可通过接收的表述操作资源,因为表述包含操作所需的充足信息。
- 返回给客户端的自描述消息包含充足的信息,能够指明客户端应该如何处理所收到的信息。
- 超文本/超媒体可用,是指在访问资源后,客户端应能够使用超链接查找其当前可采取的所有其他操作。
- 组织各种类型服务器(负责安全性、负载平衡等的服务器)的分层系统会参与将请求的信息检索到对客户端不可见的层次结构中。
- 按需编码(可选):能够根据请求将可执行代码从服务器发送到客户端,从而扩展客户端功能。
虽然 REST API 需要遵循这些标准,但是