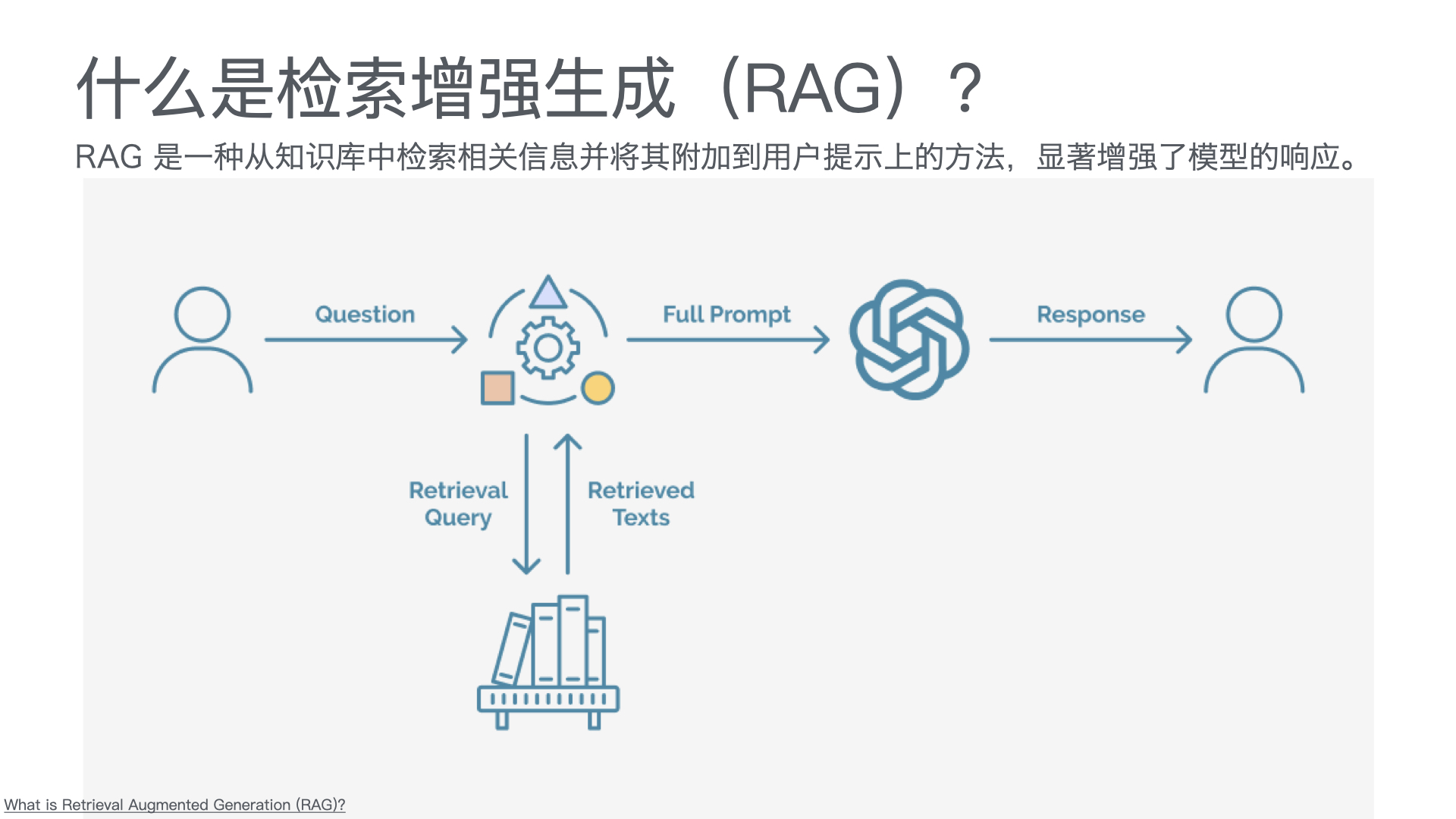
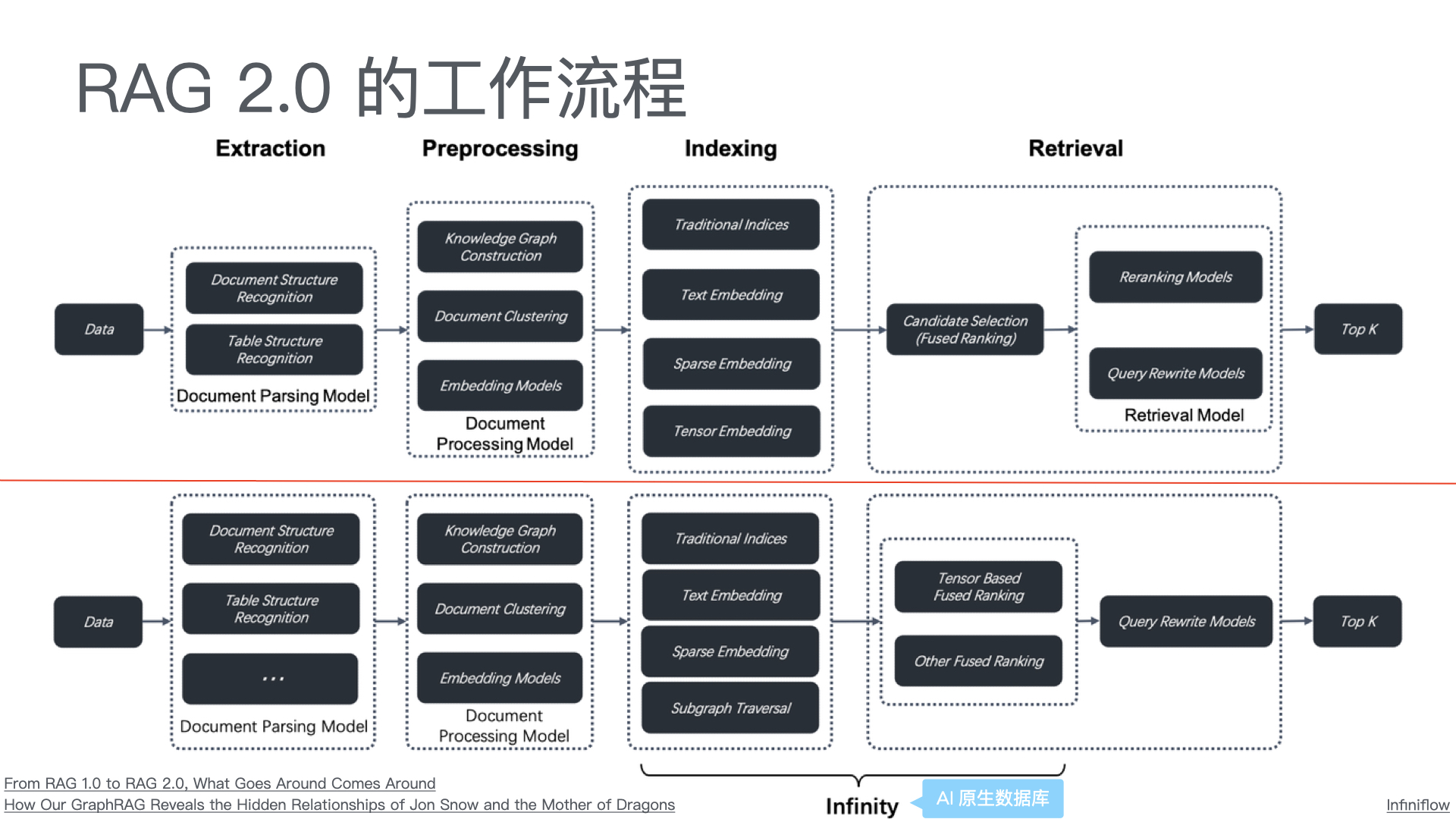
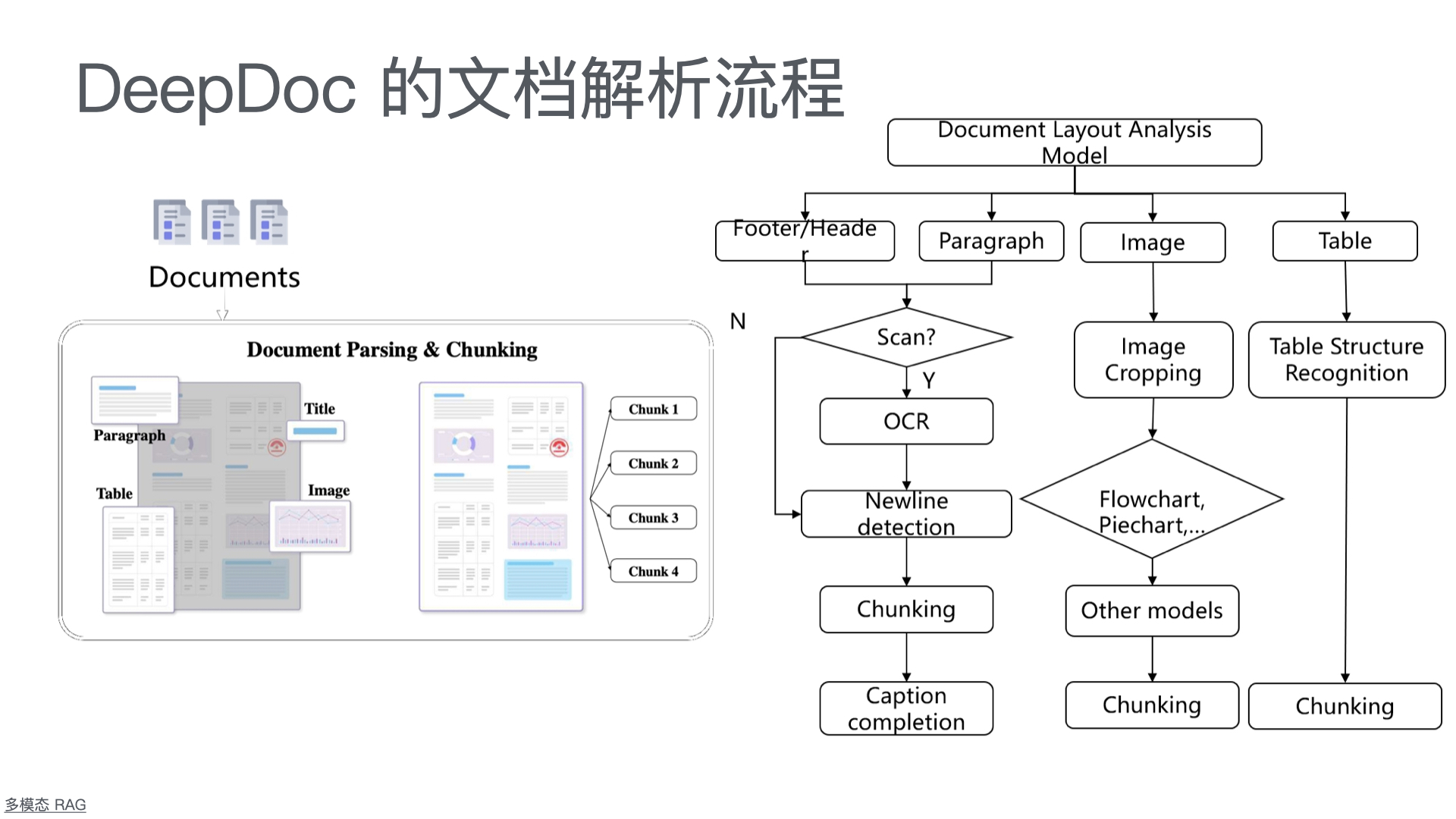
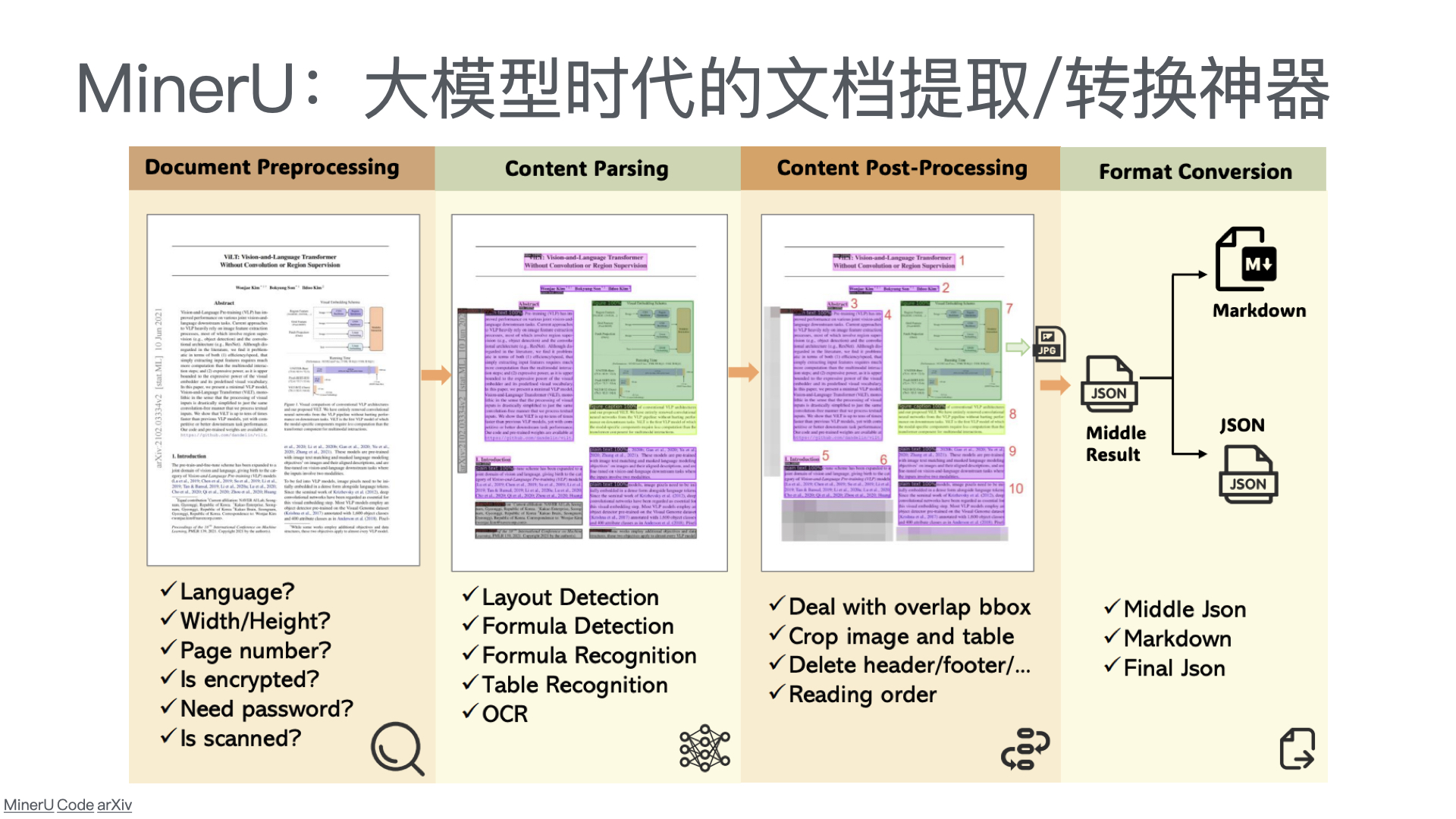
智能问答售后服务系统
一、技术方案
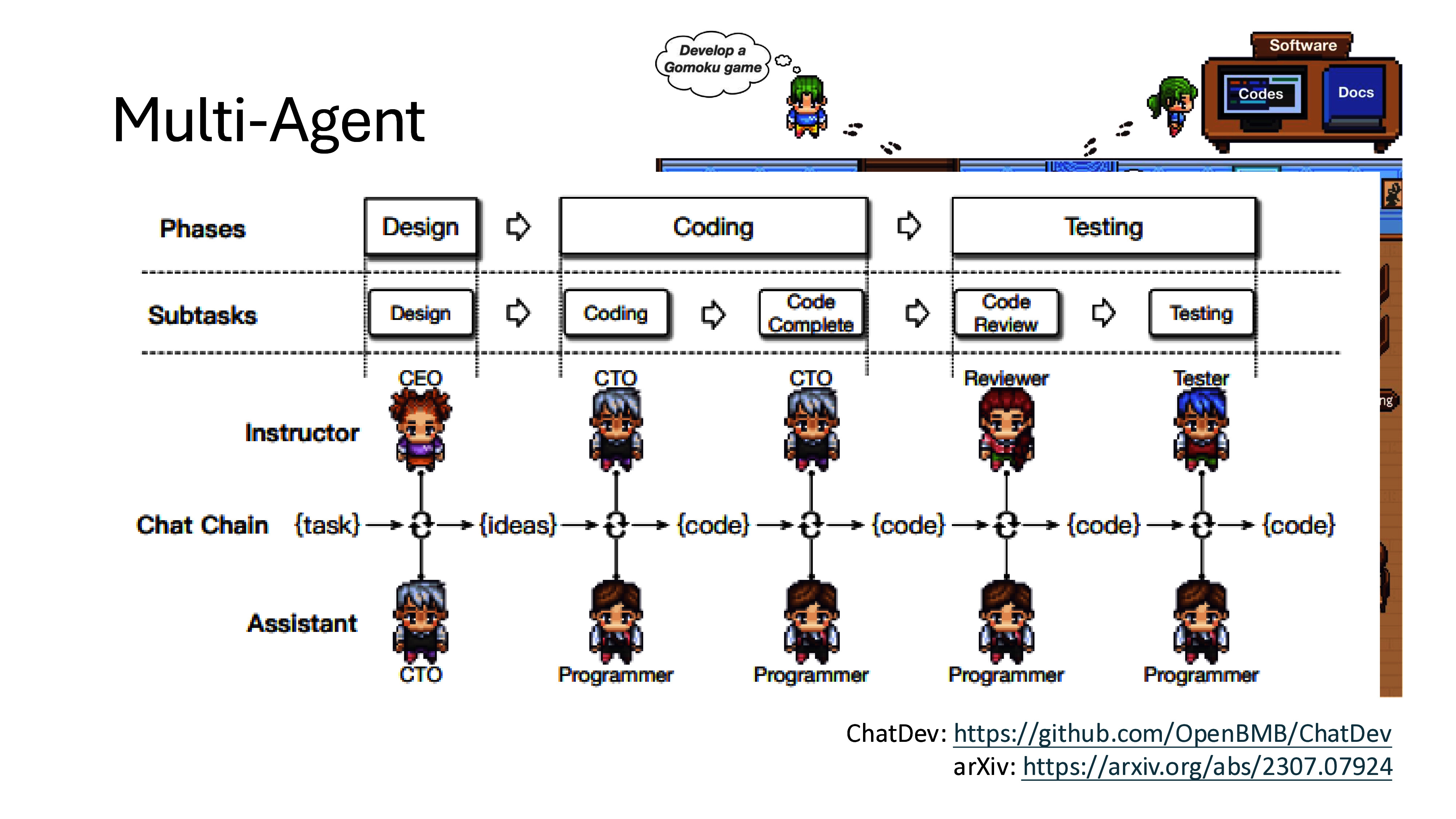
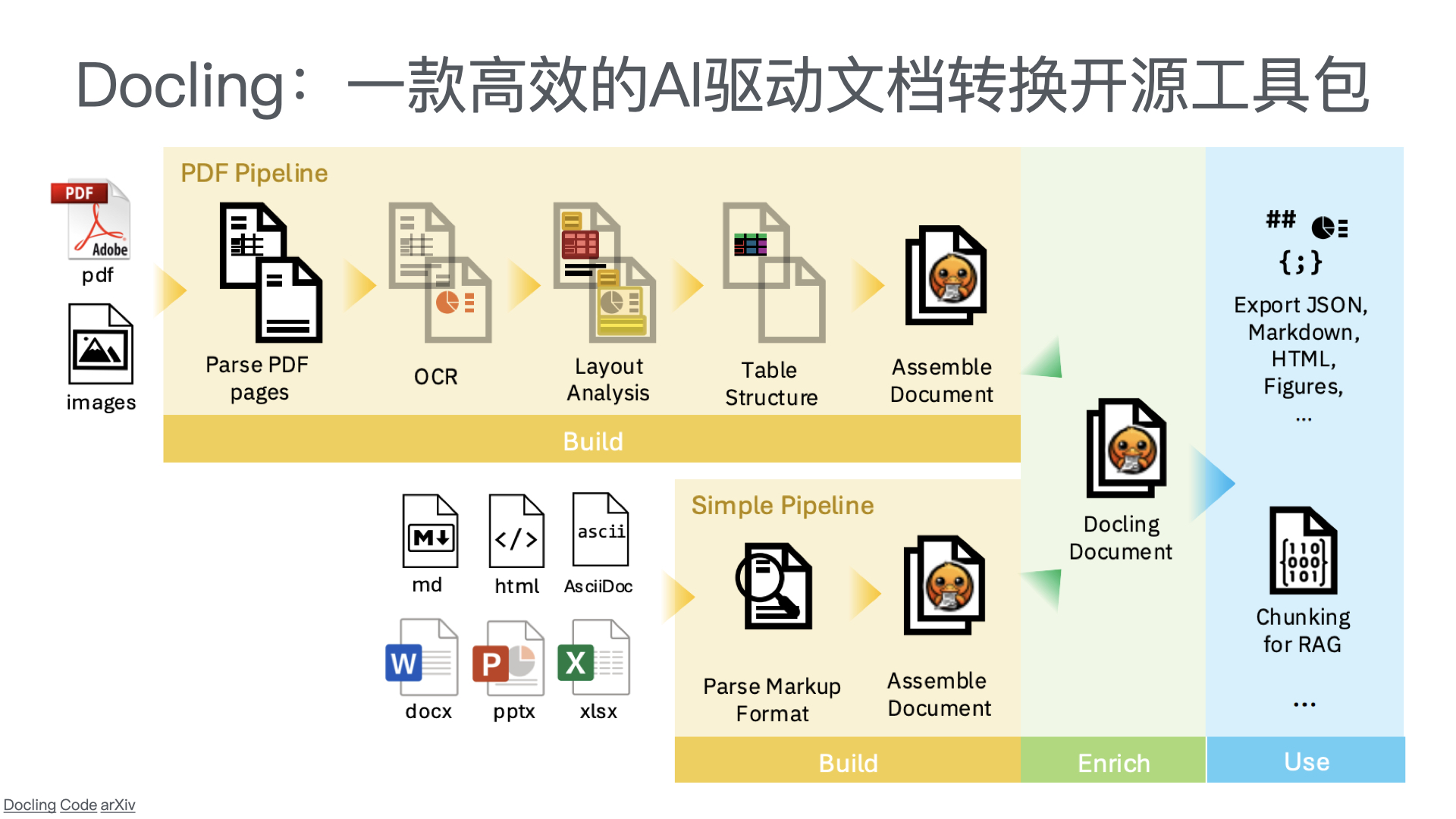
1.1 总体架构
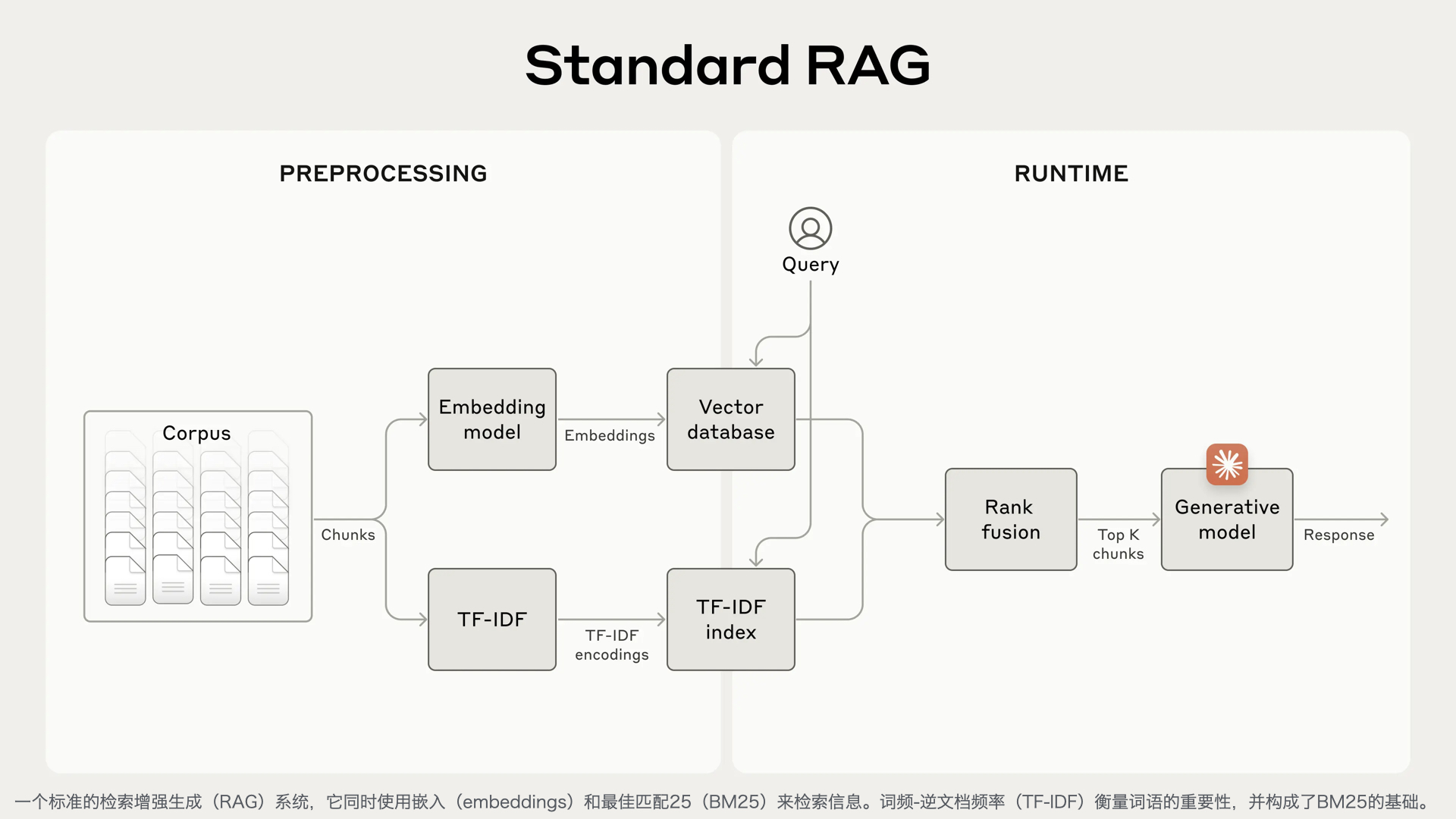
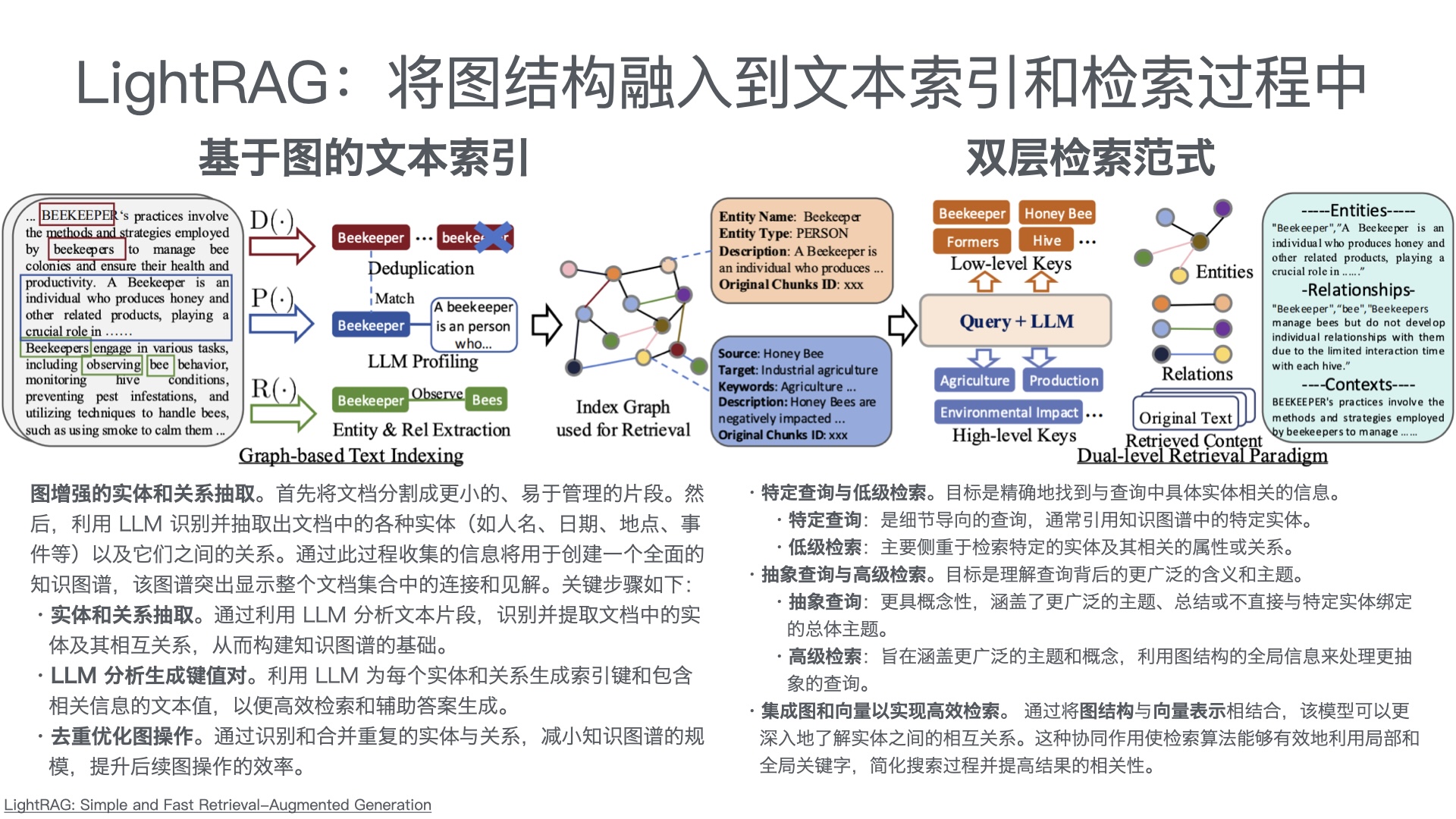
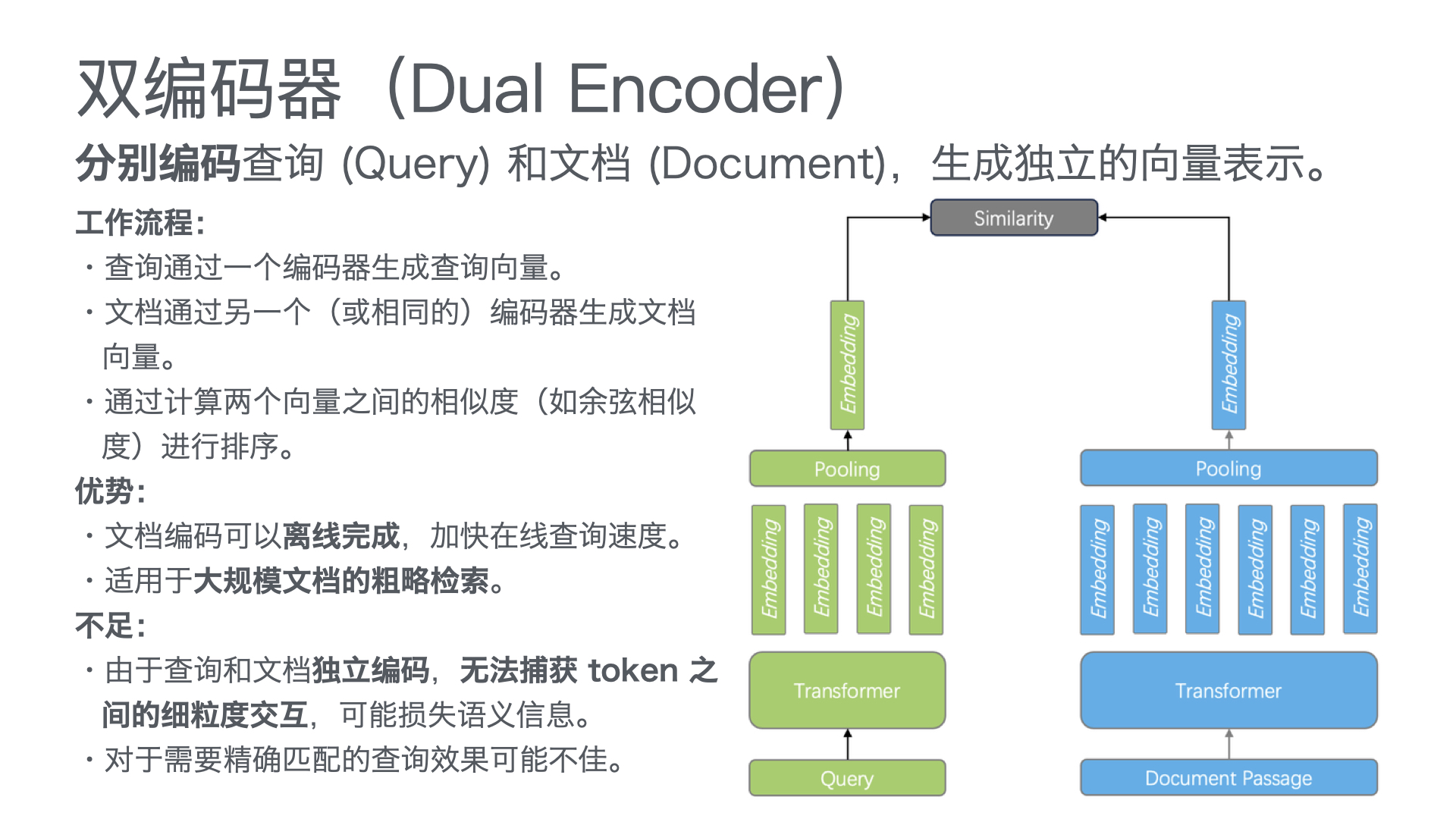
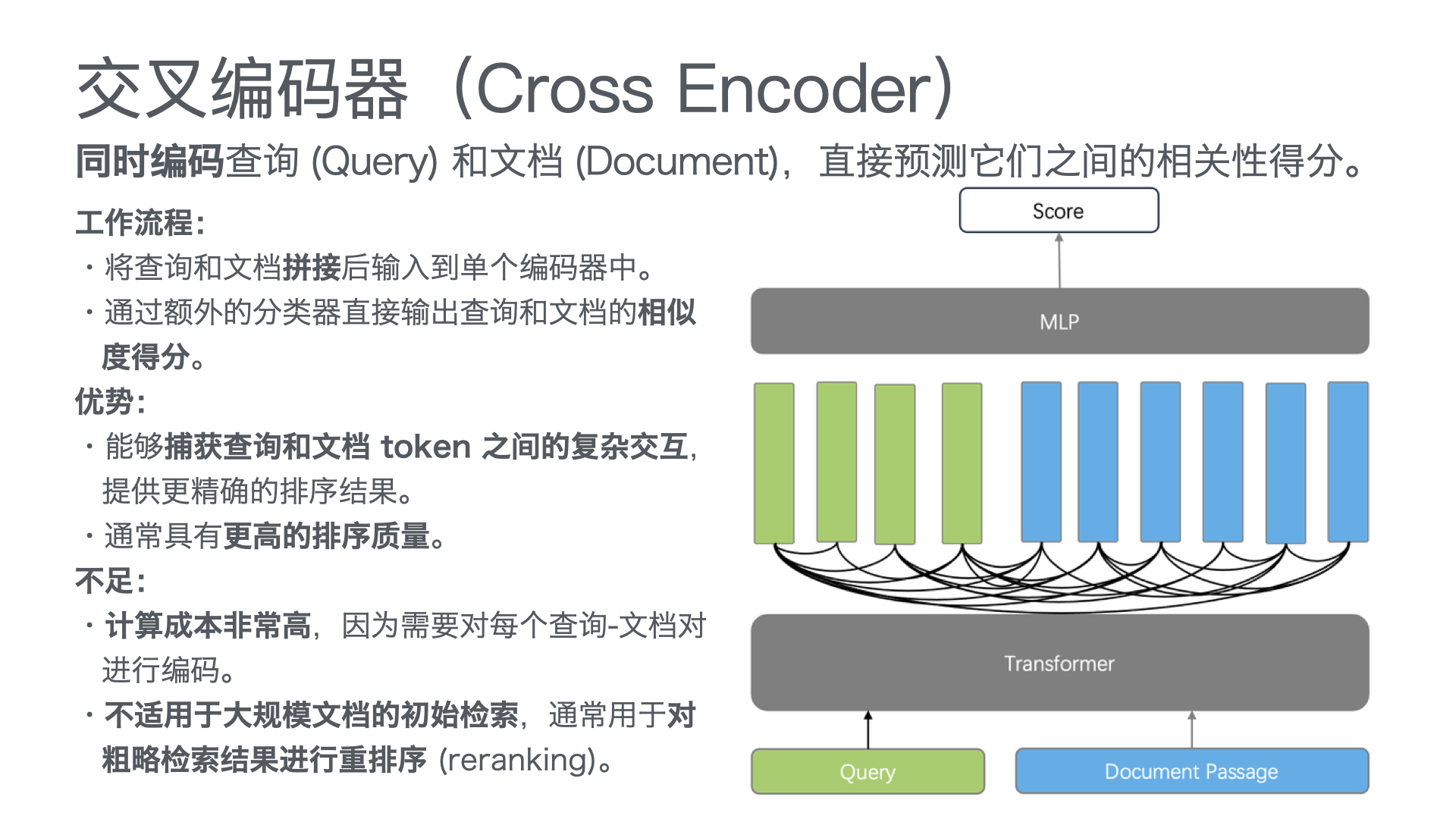
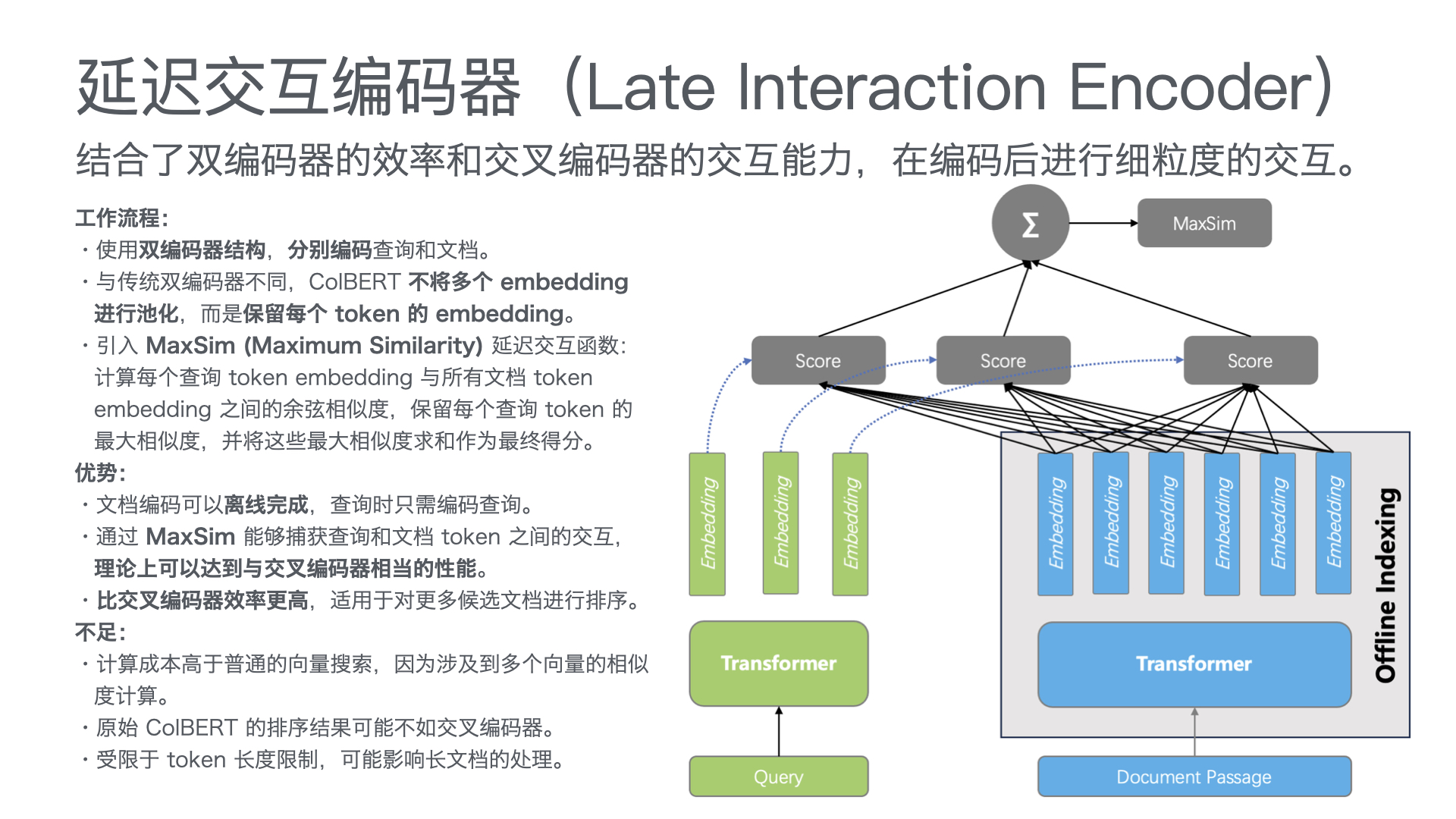
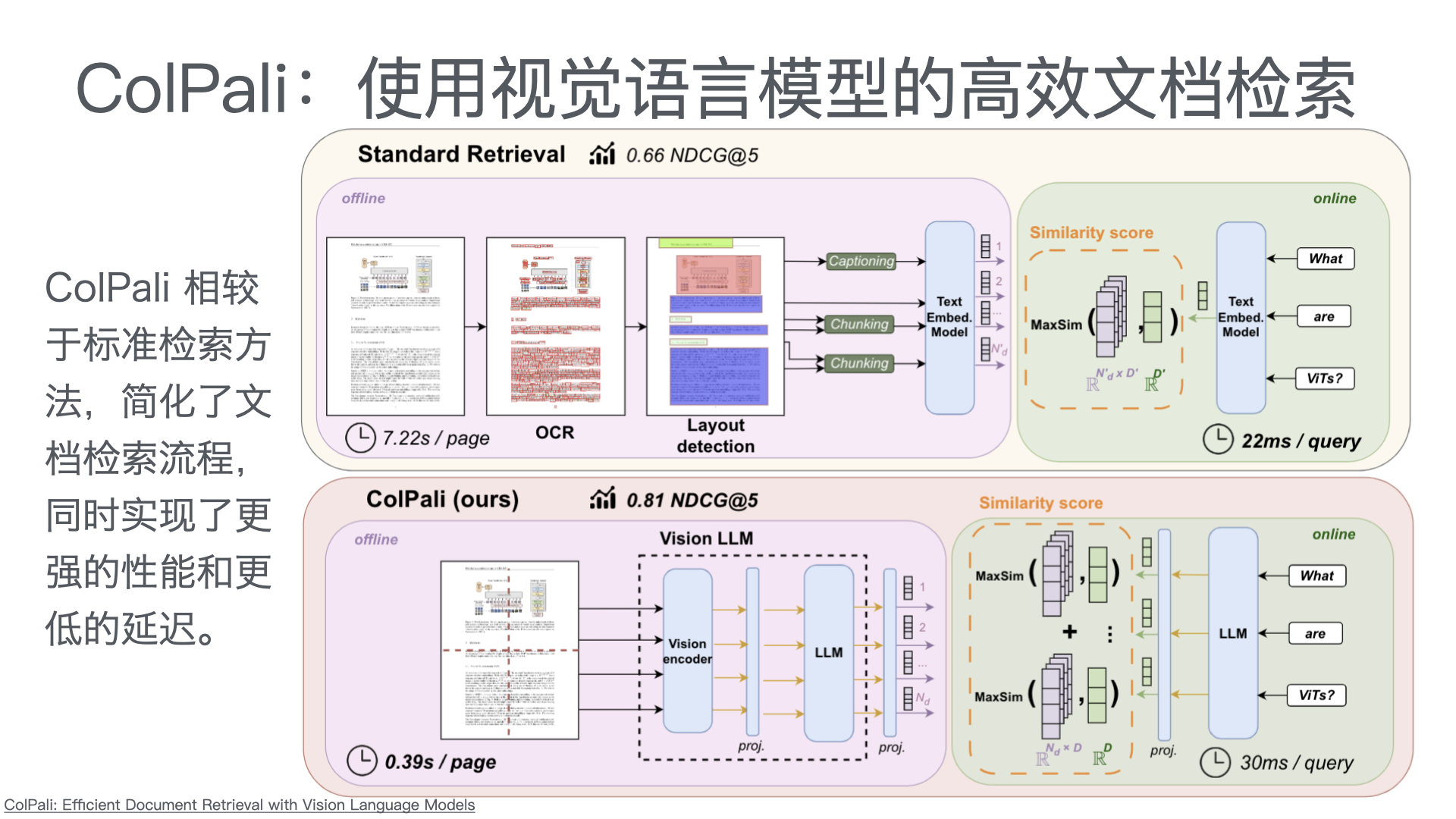
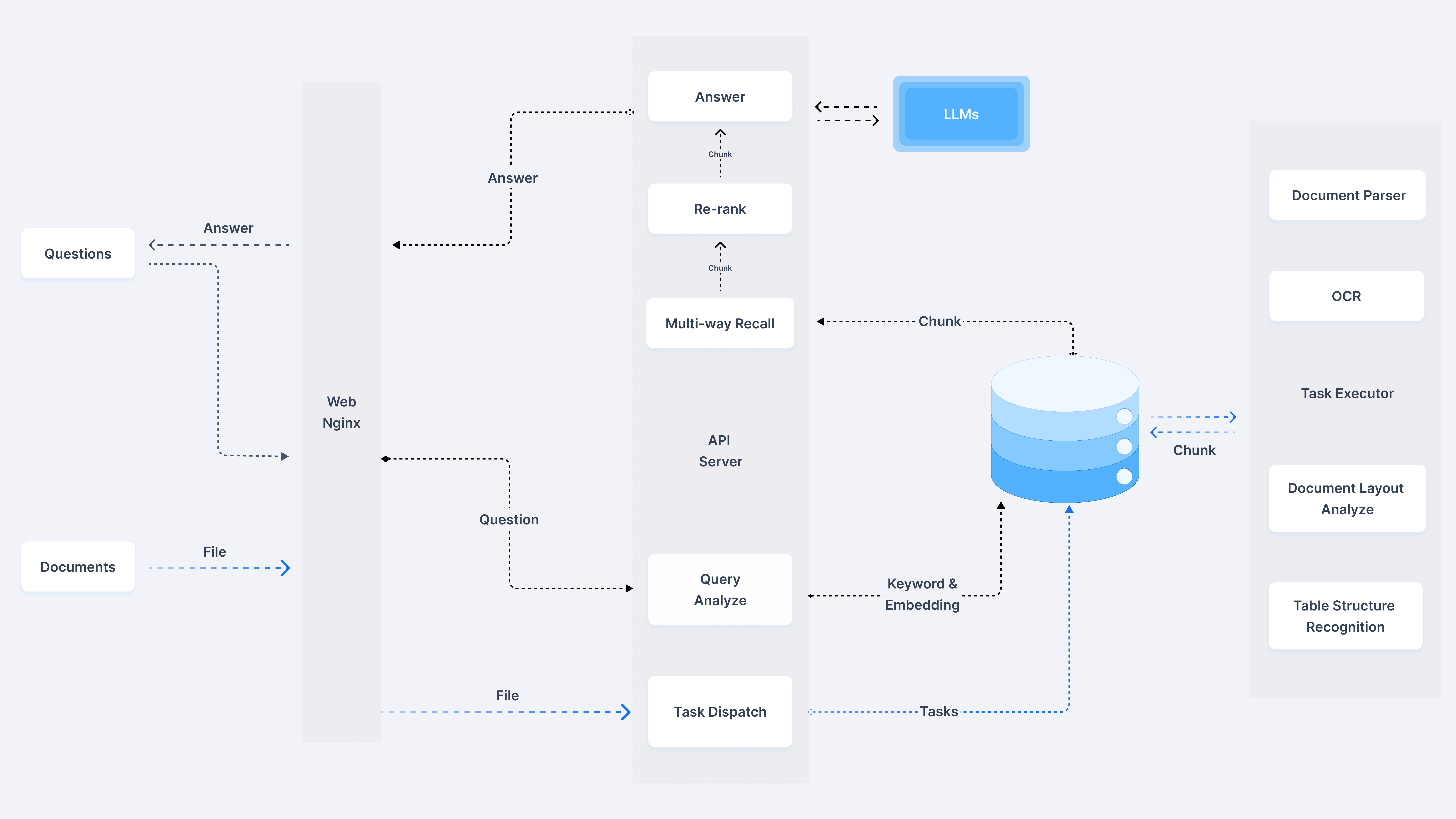
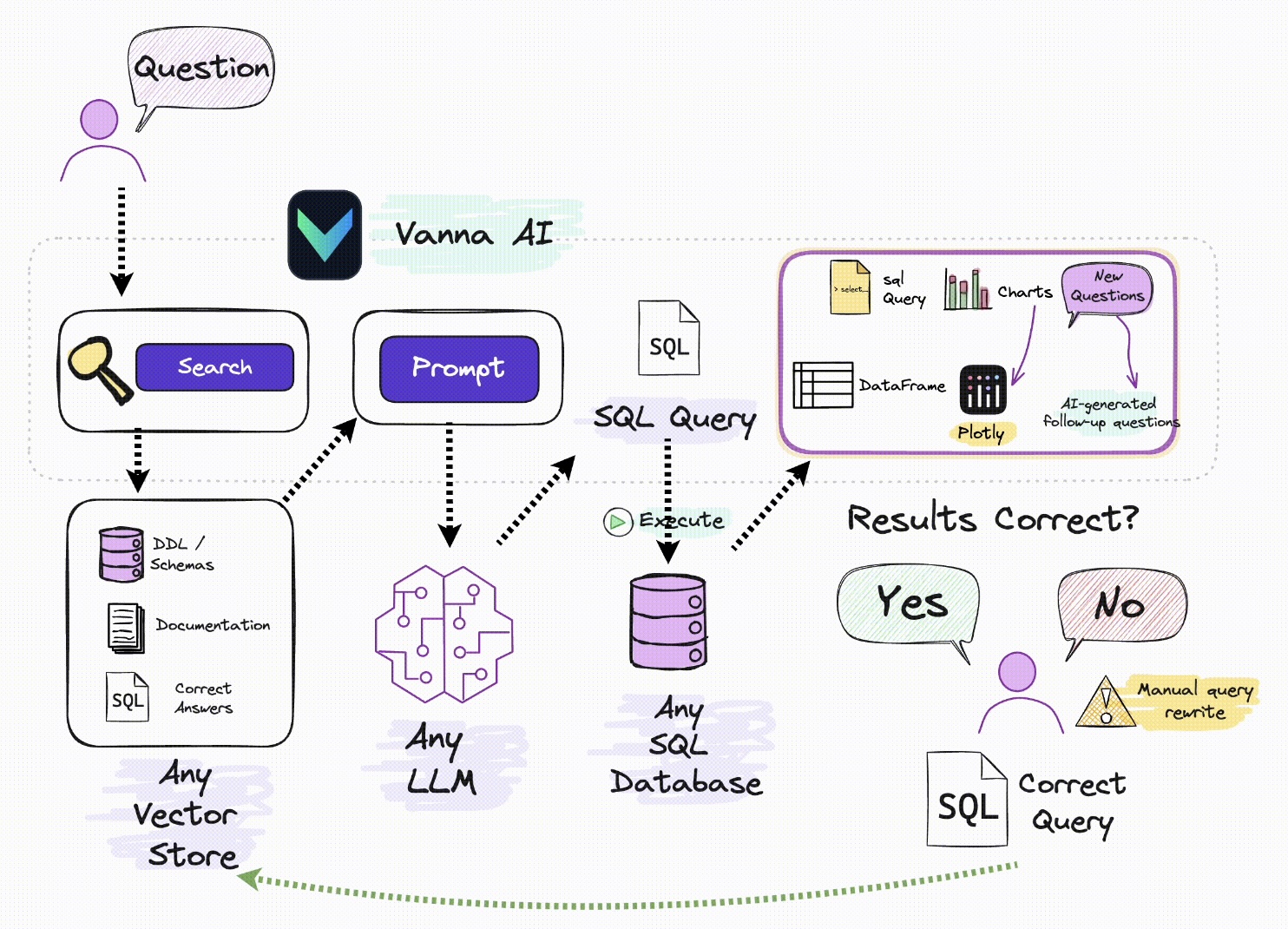
采用 “公众号前端 + 智能客服中台 + 知识库底座” 三层架构:
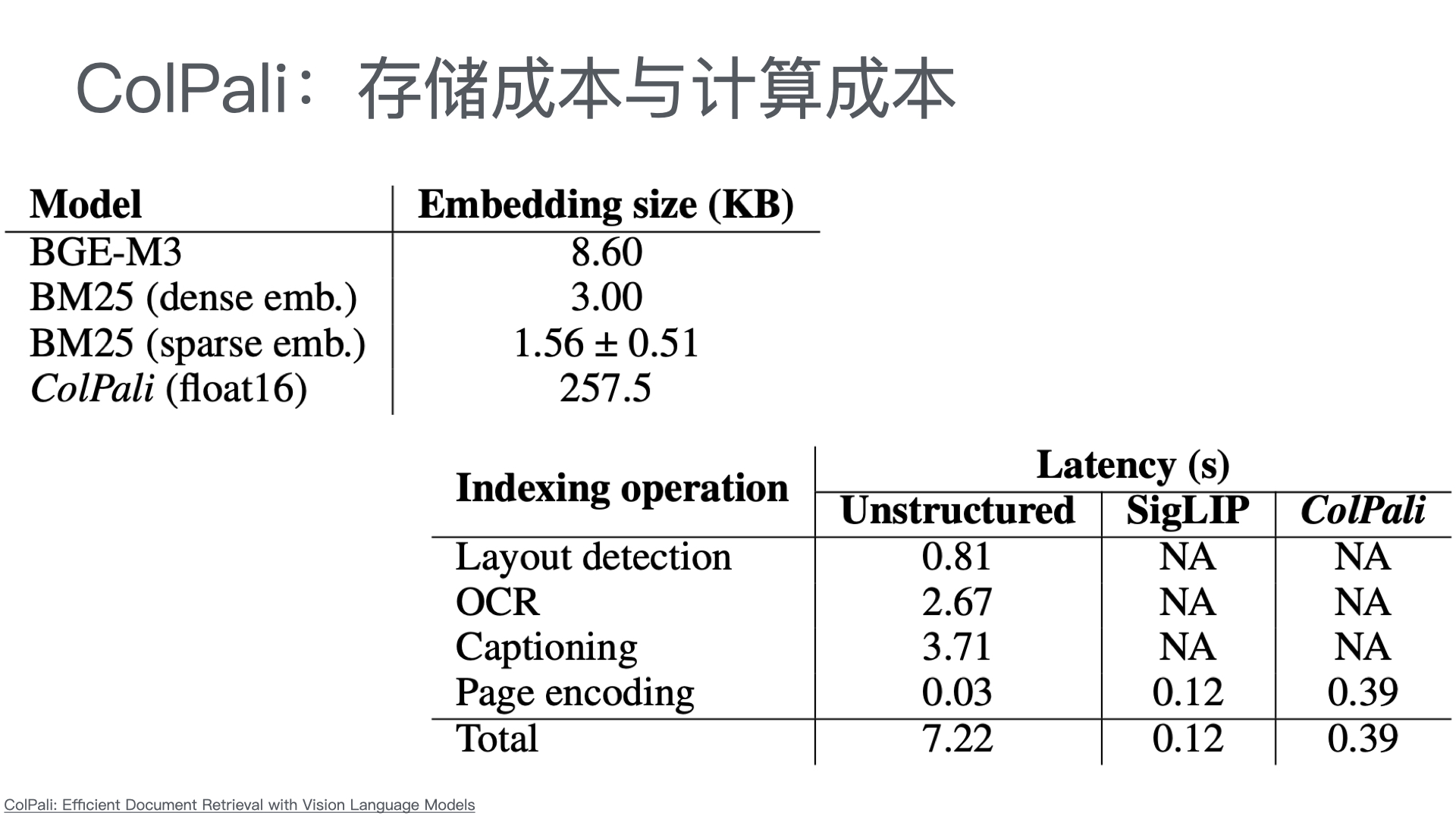
| 层级 | 功能 | 技术选型建议 |
|---|---|---|
| 接入层 | 公众号对话入口,支持文字、图片、视频等多模态输入 | 微信公众号开发接口 |
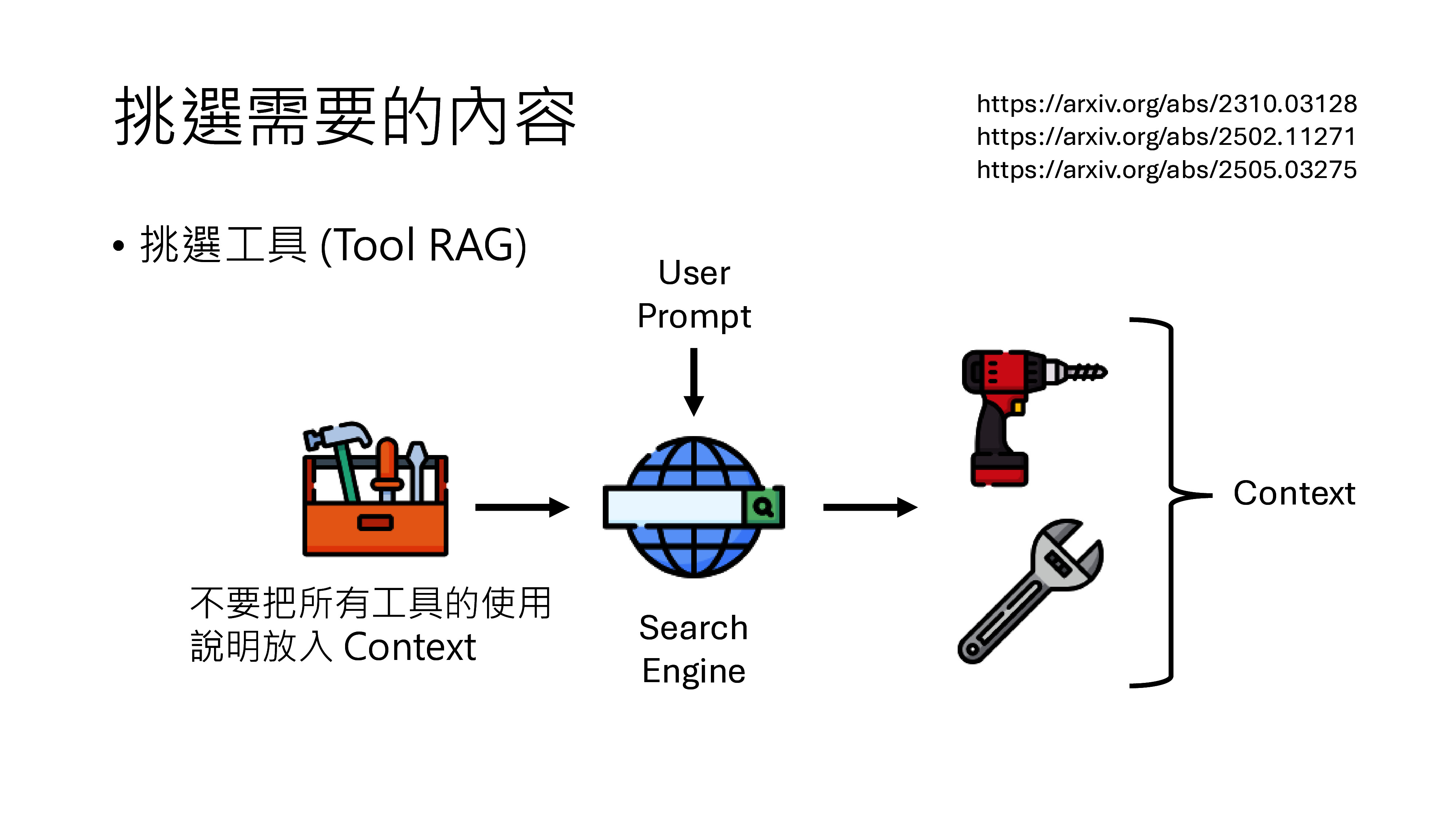
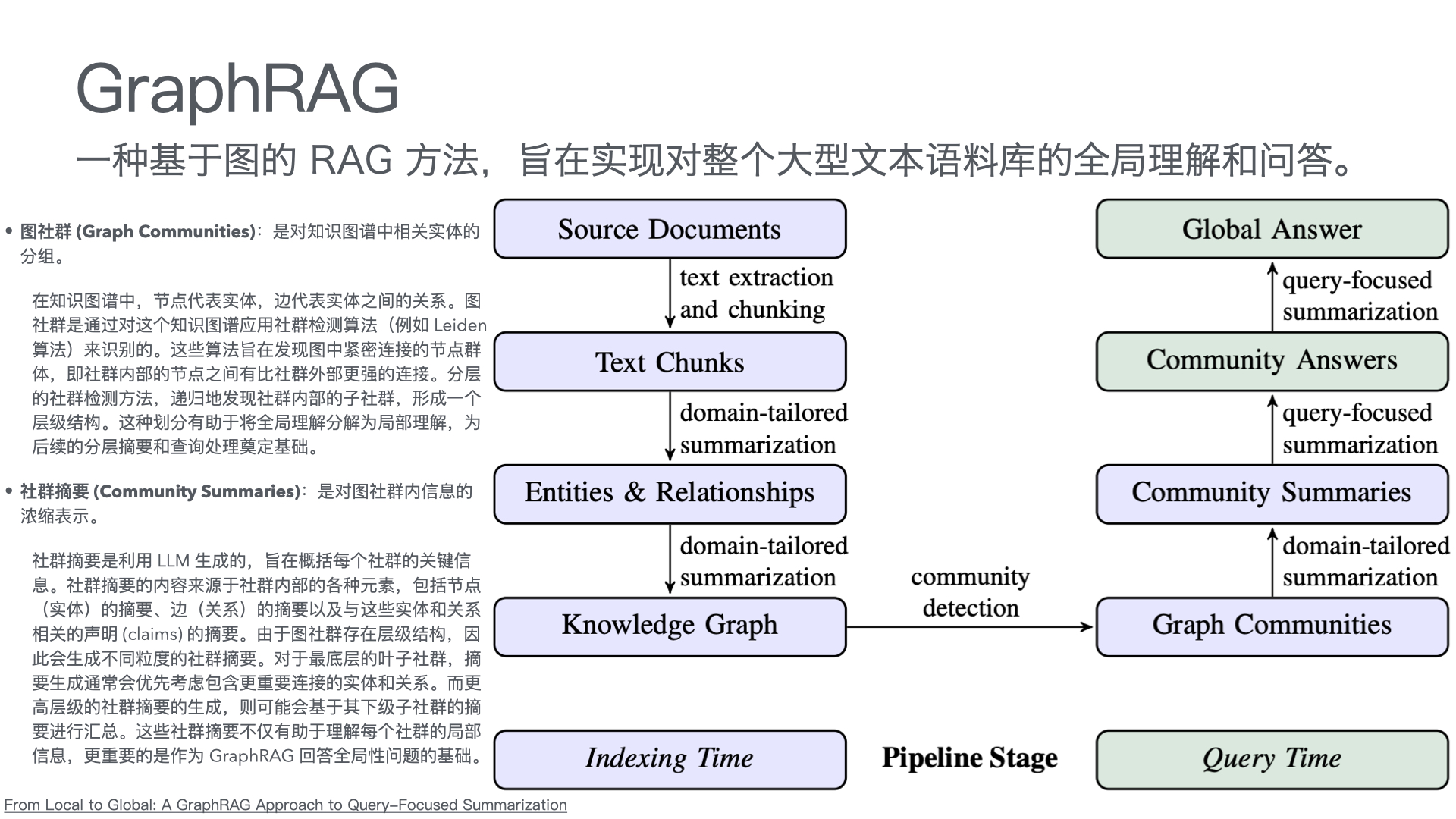
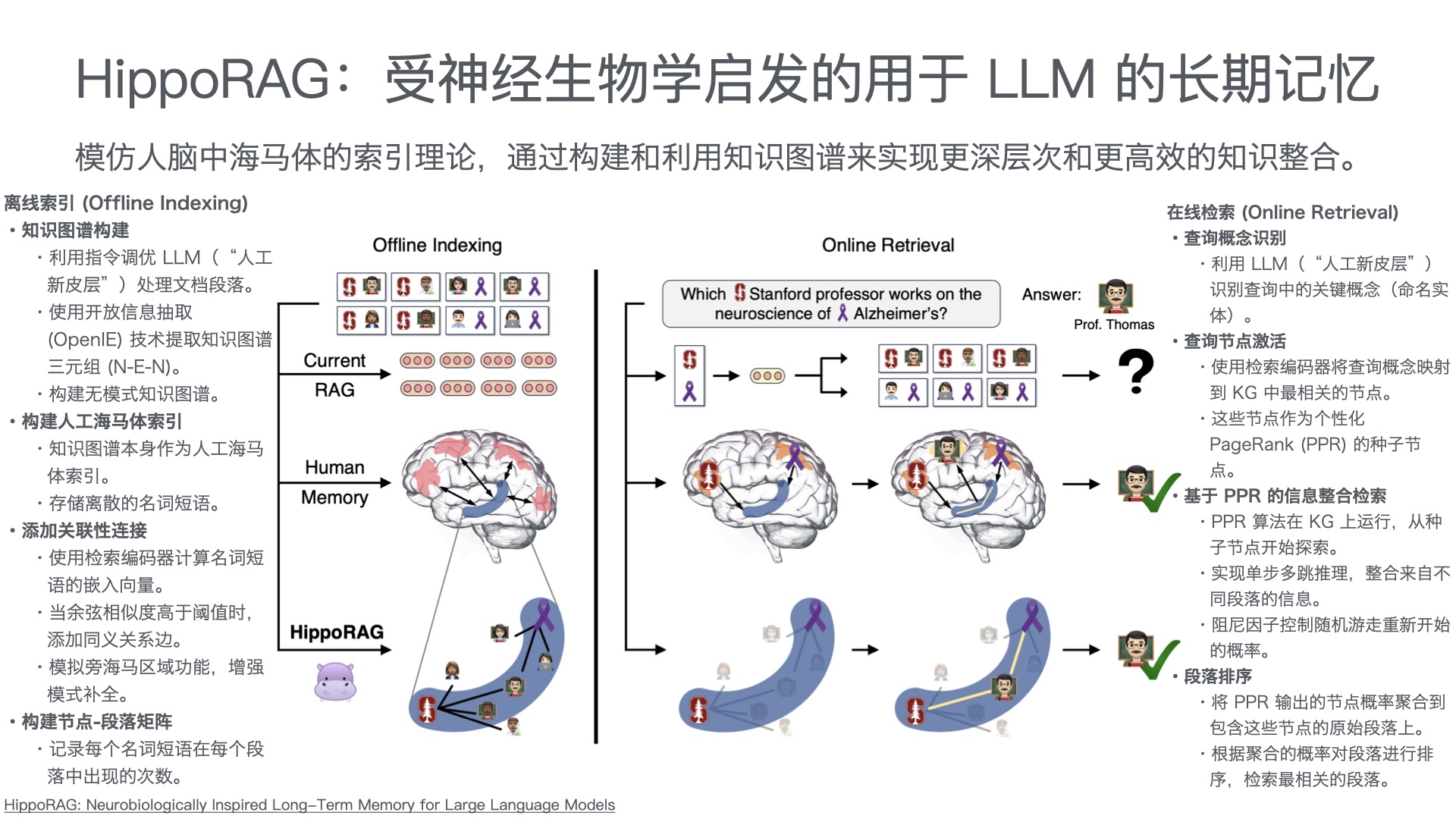
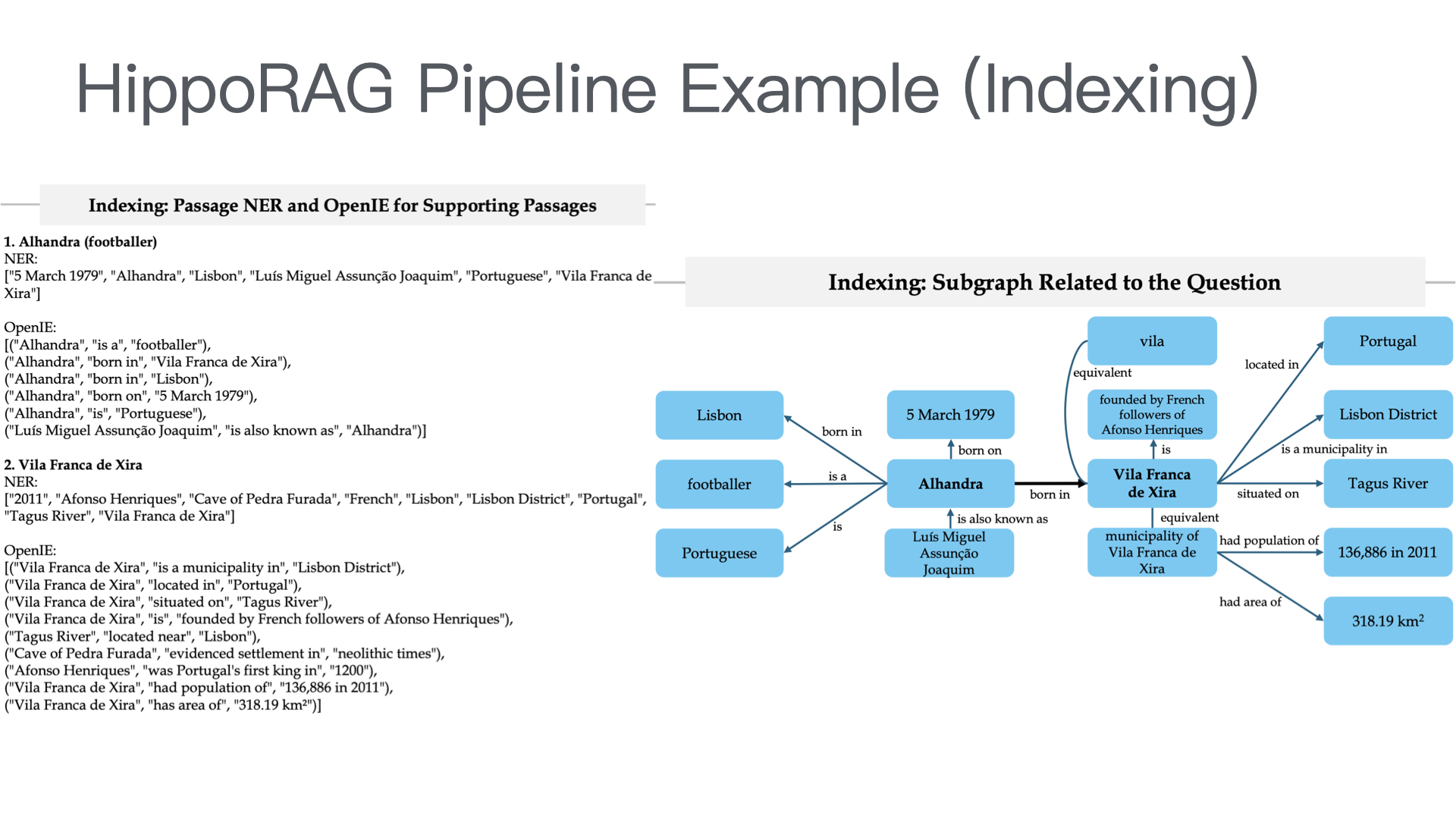
| 智能客服中台 | 意图识别、知识检索、问答生成、智能路由(AI/人工分流) | RAG架构 + 大模型API(通义千问/Qwen、文心一言等) |
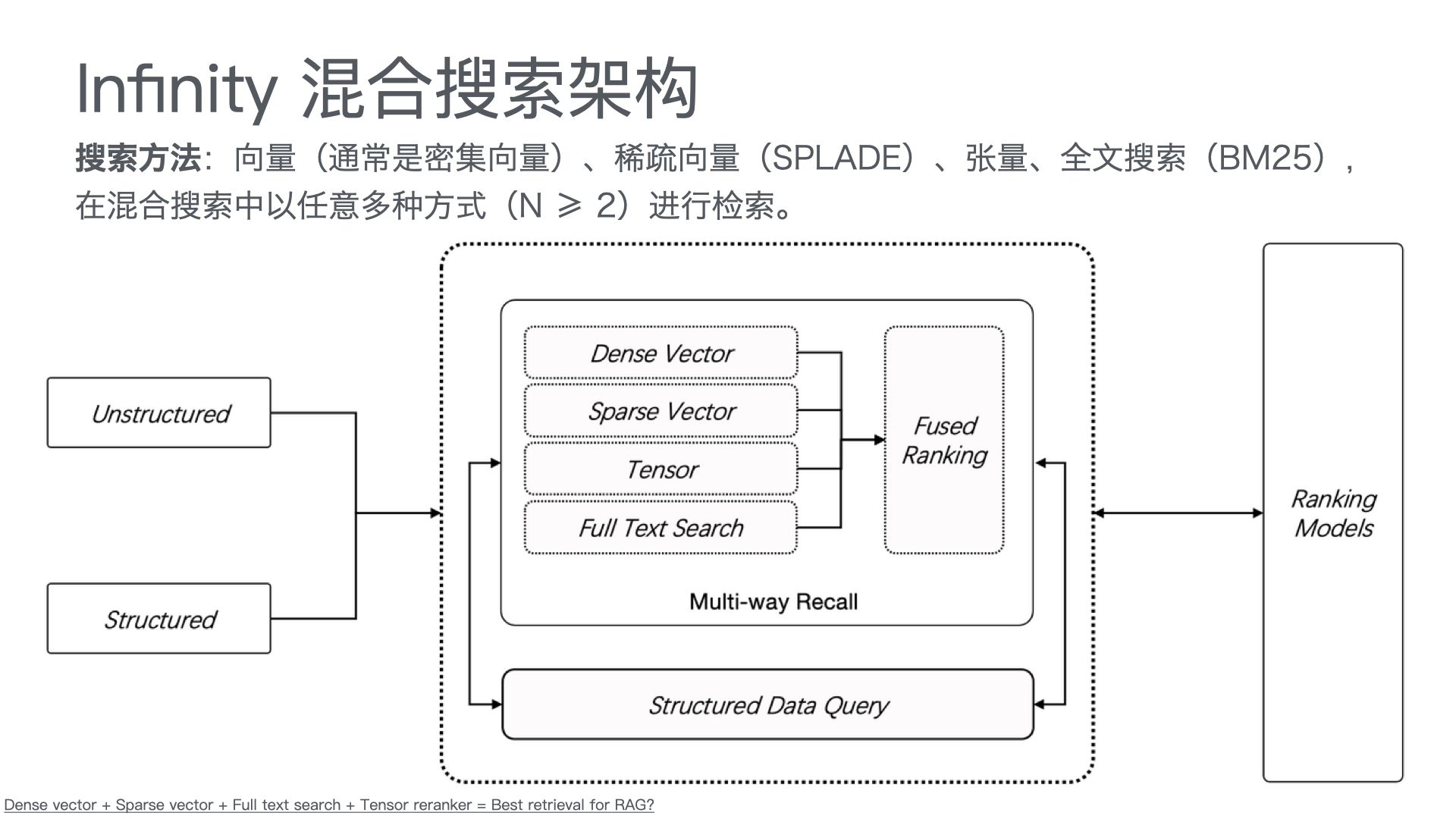
| 知识库底座 | 产品手册、FAQ、历史工单、维修案例的结构化存储与向量检索 | 向量数据库 + 结构化知识库 |
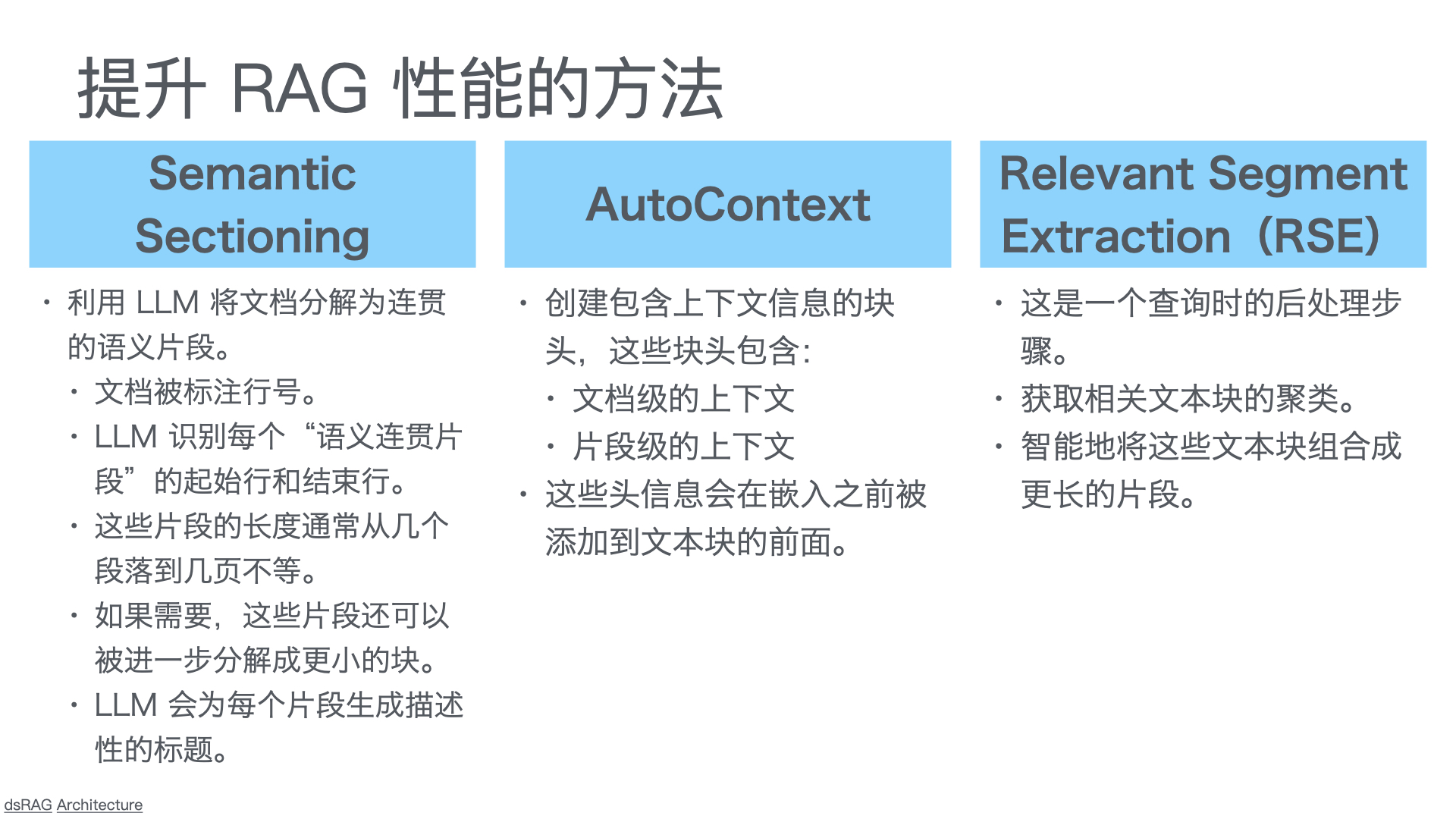
1.2 核心功能模块
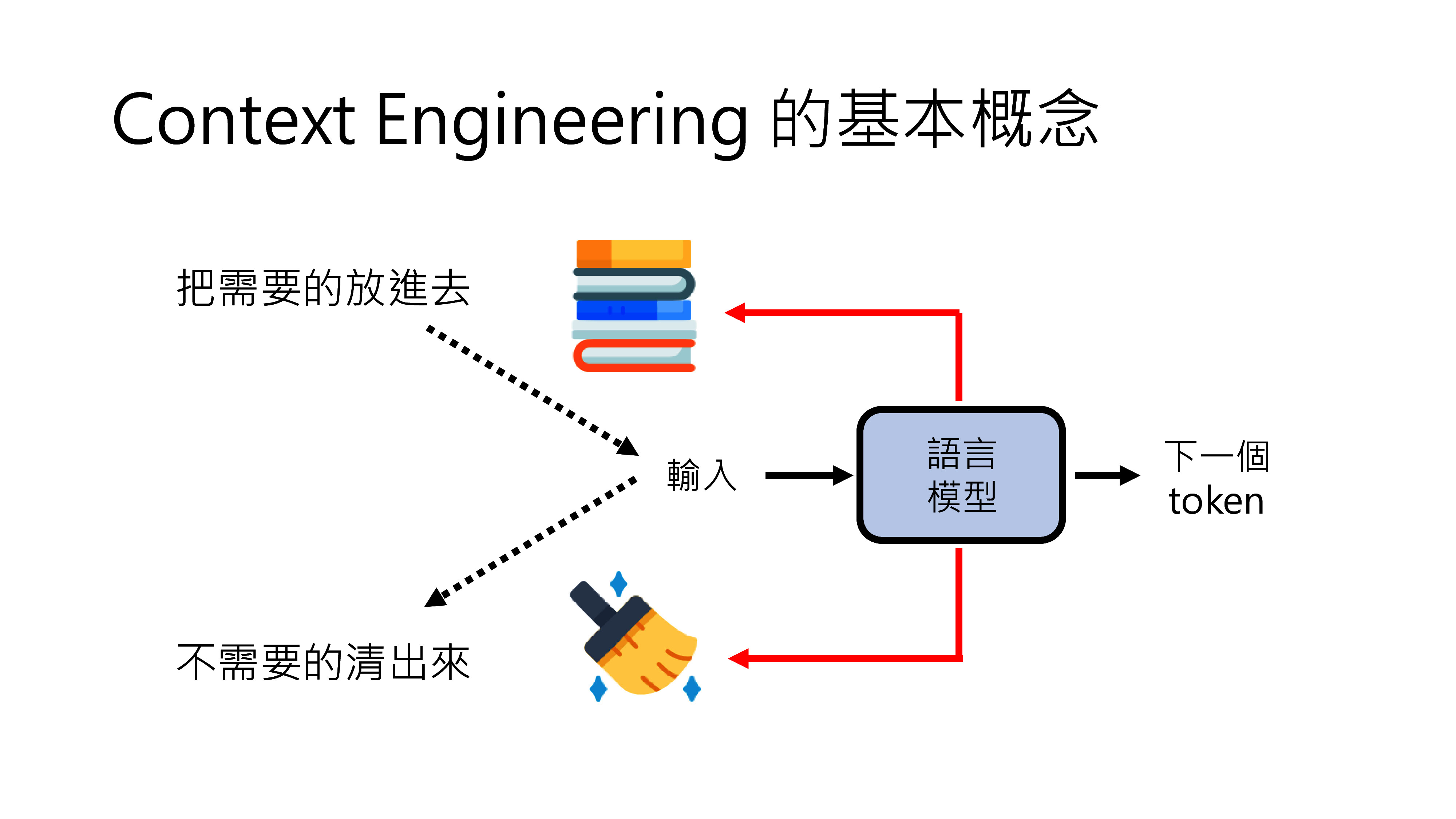
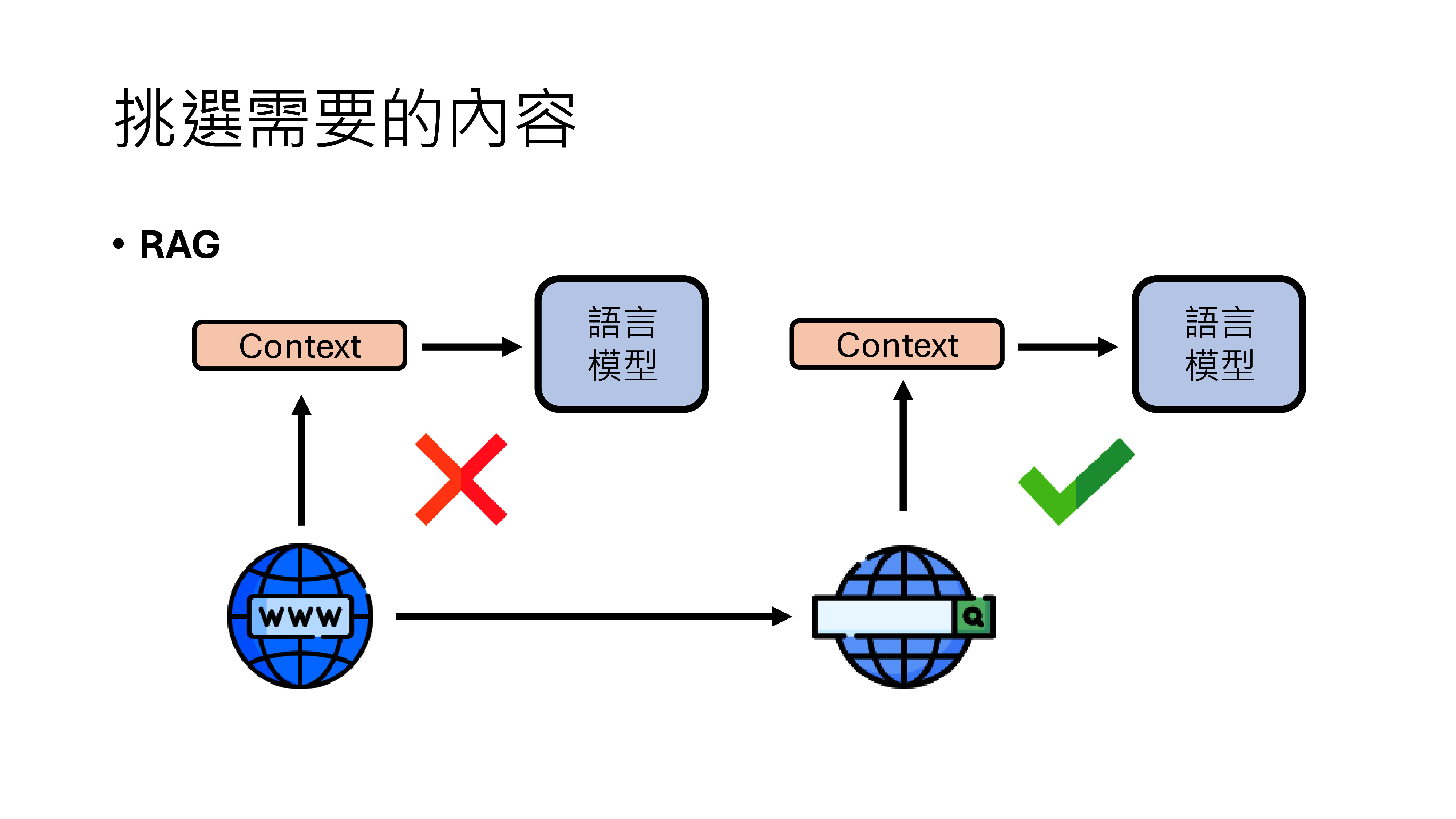
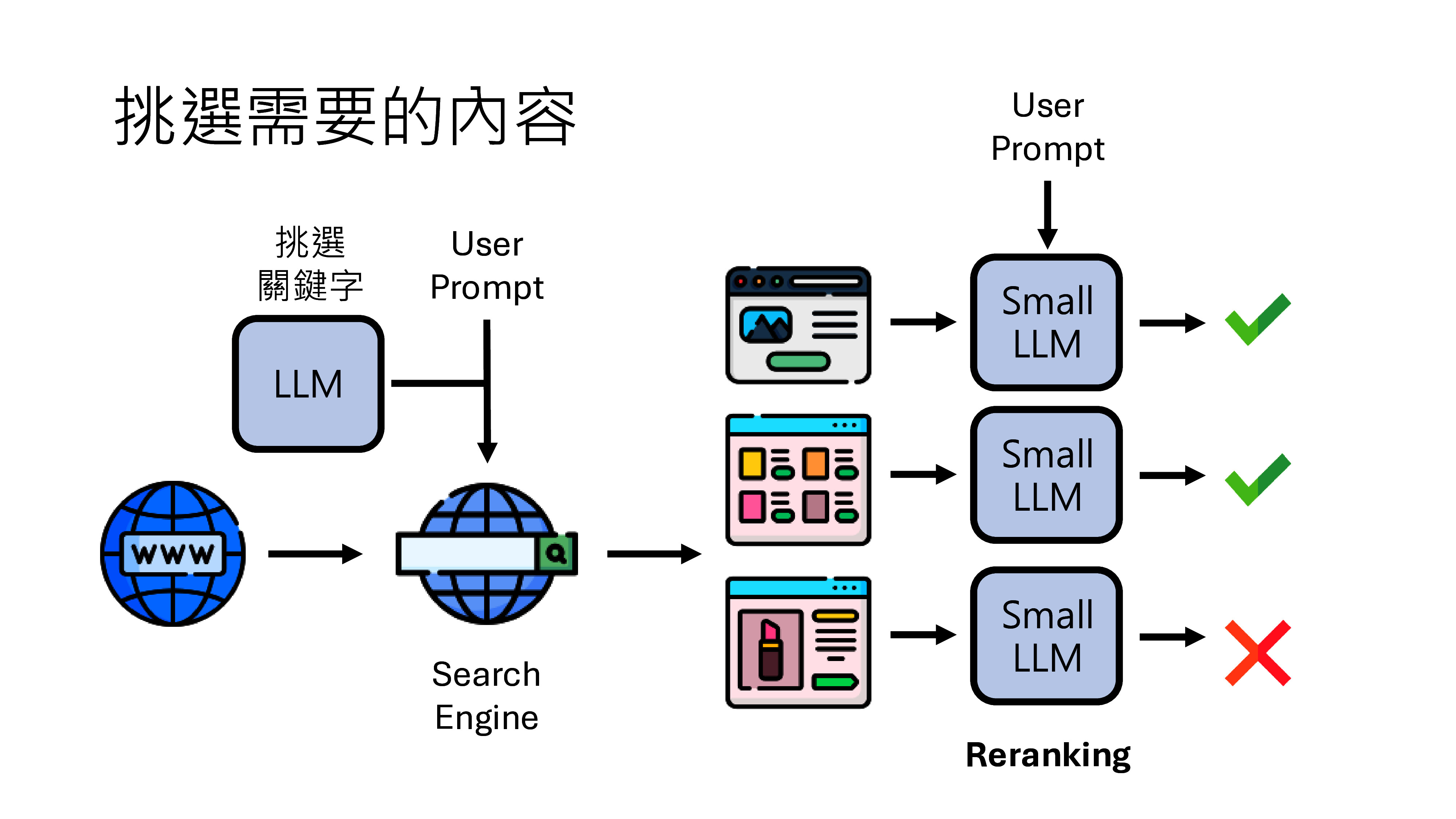
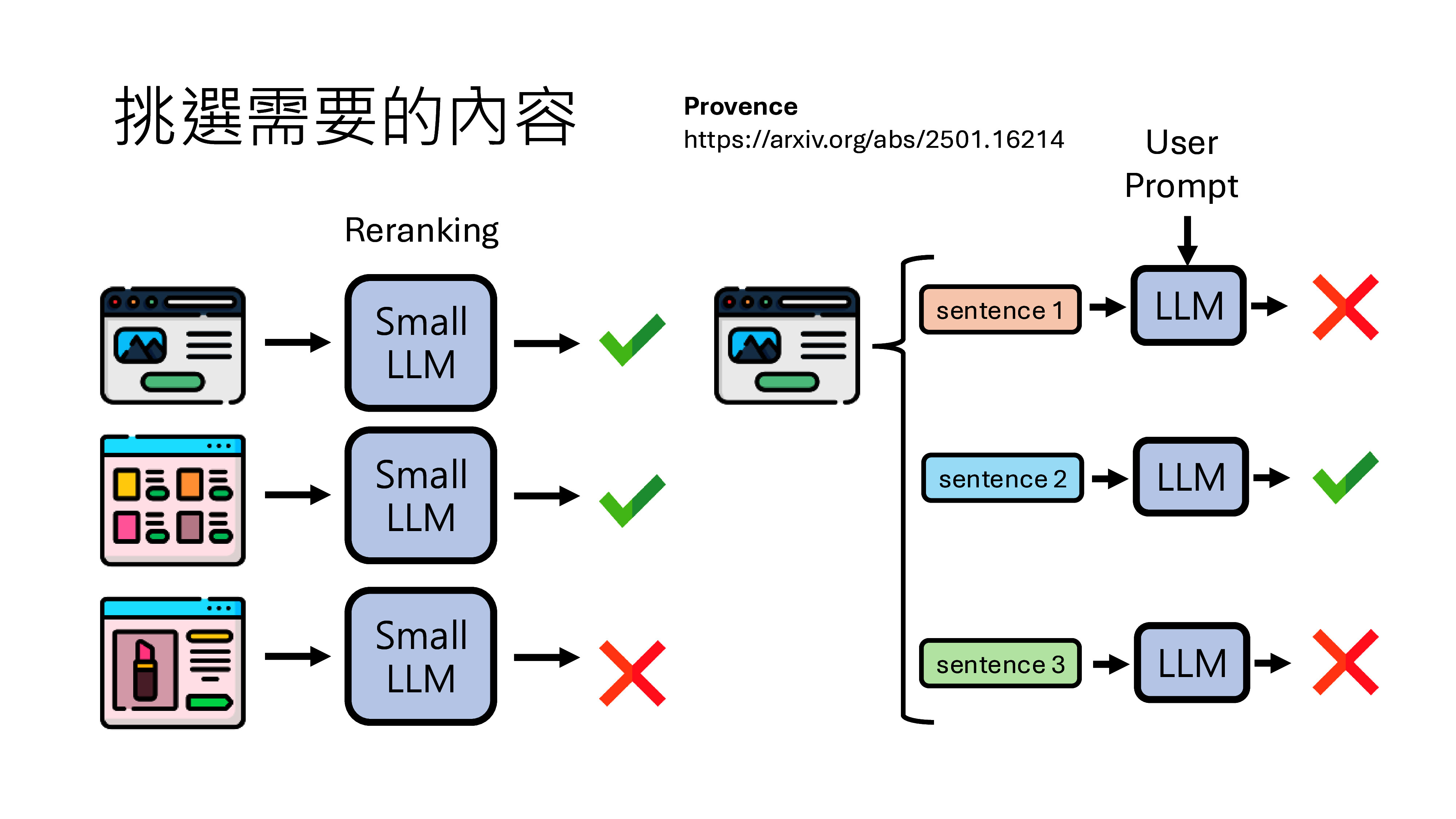
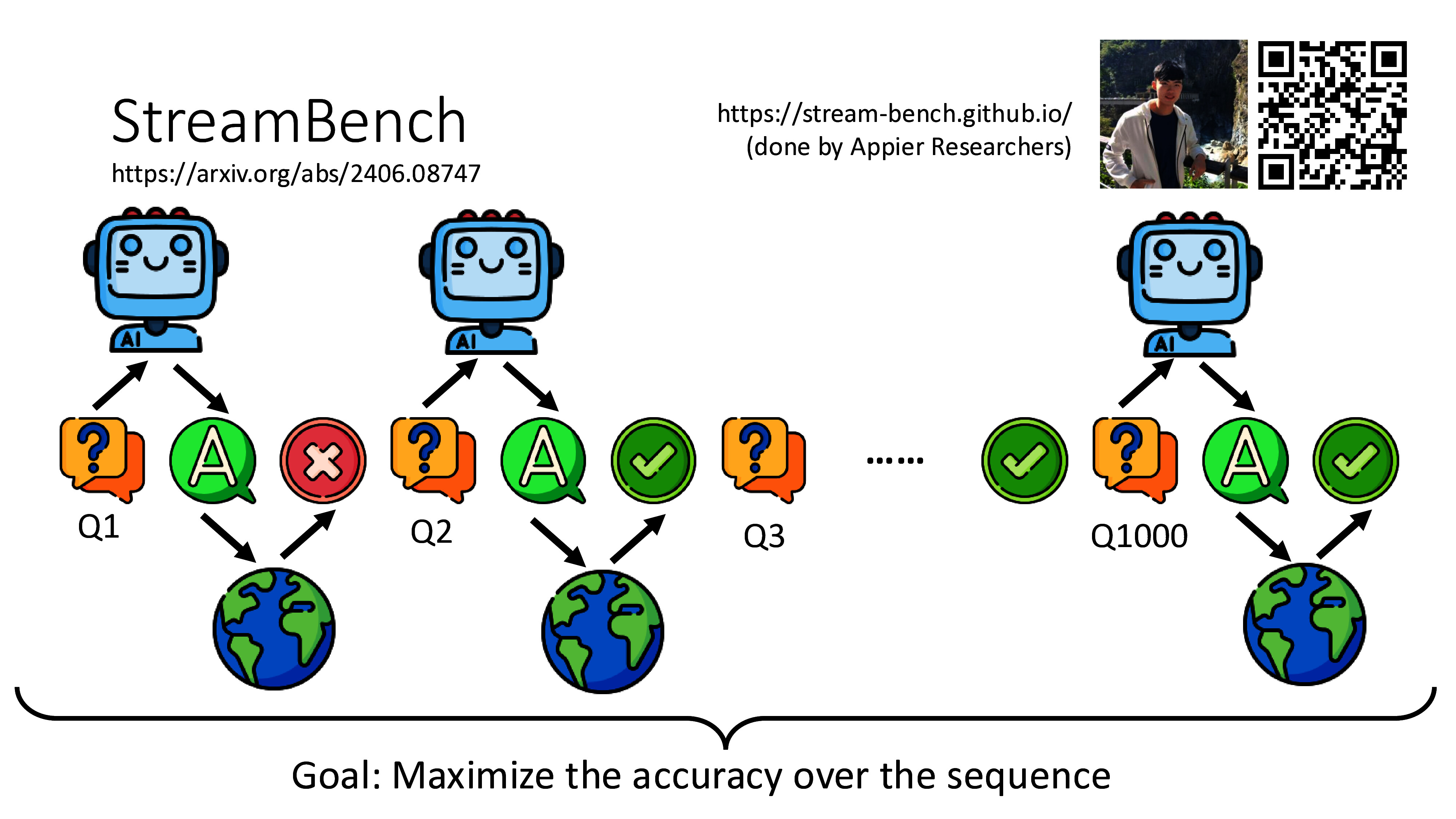
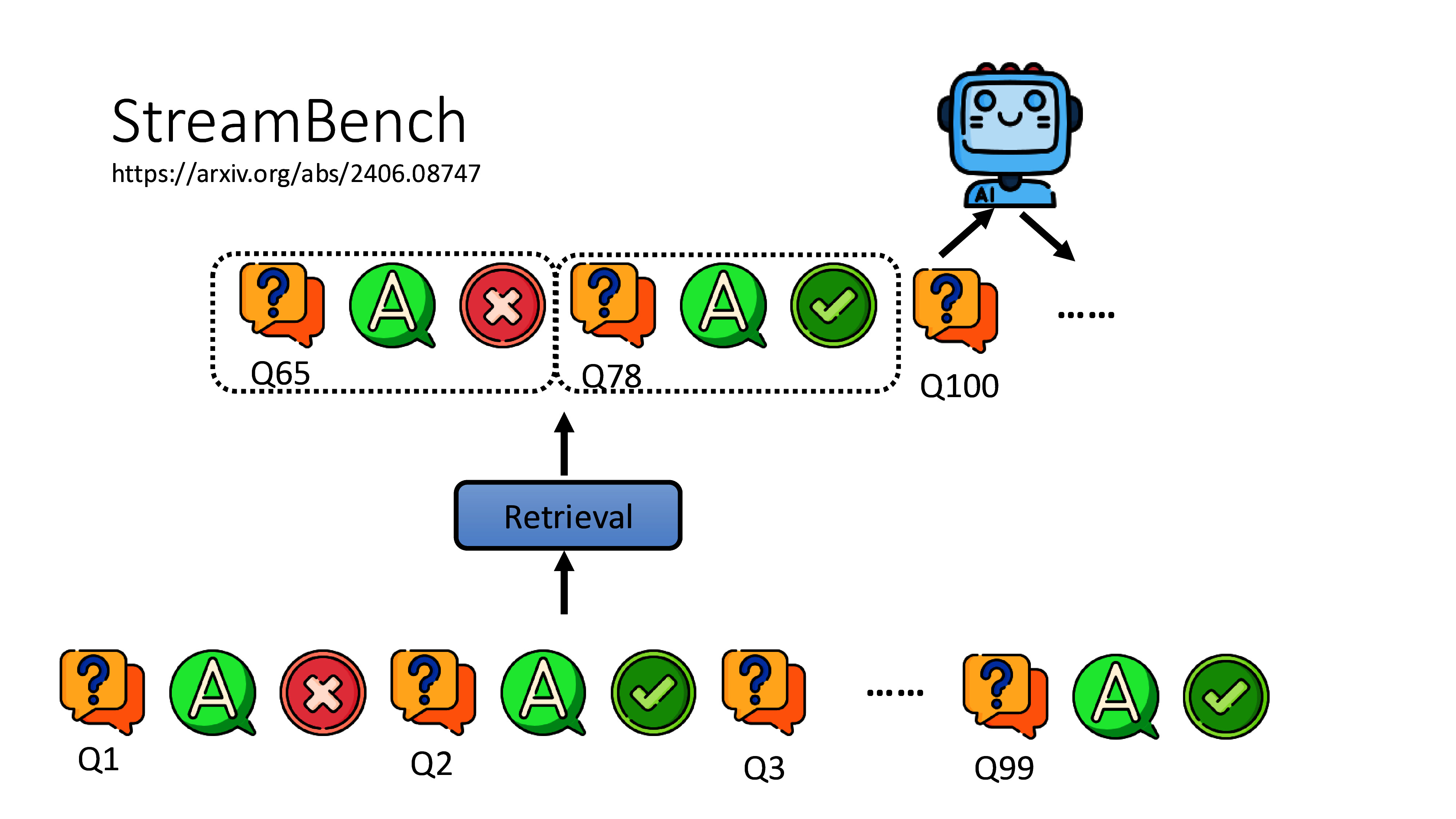
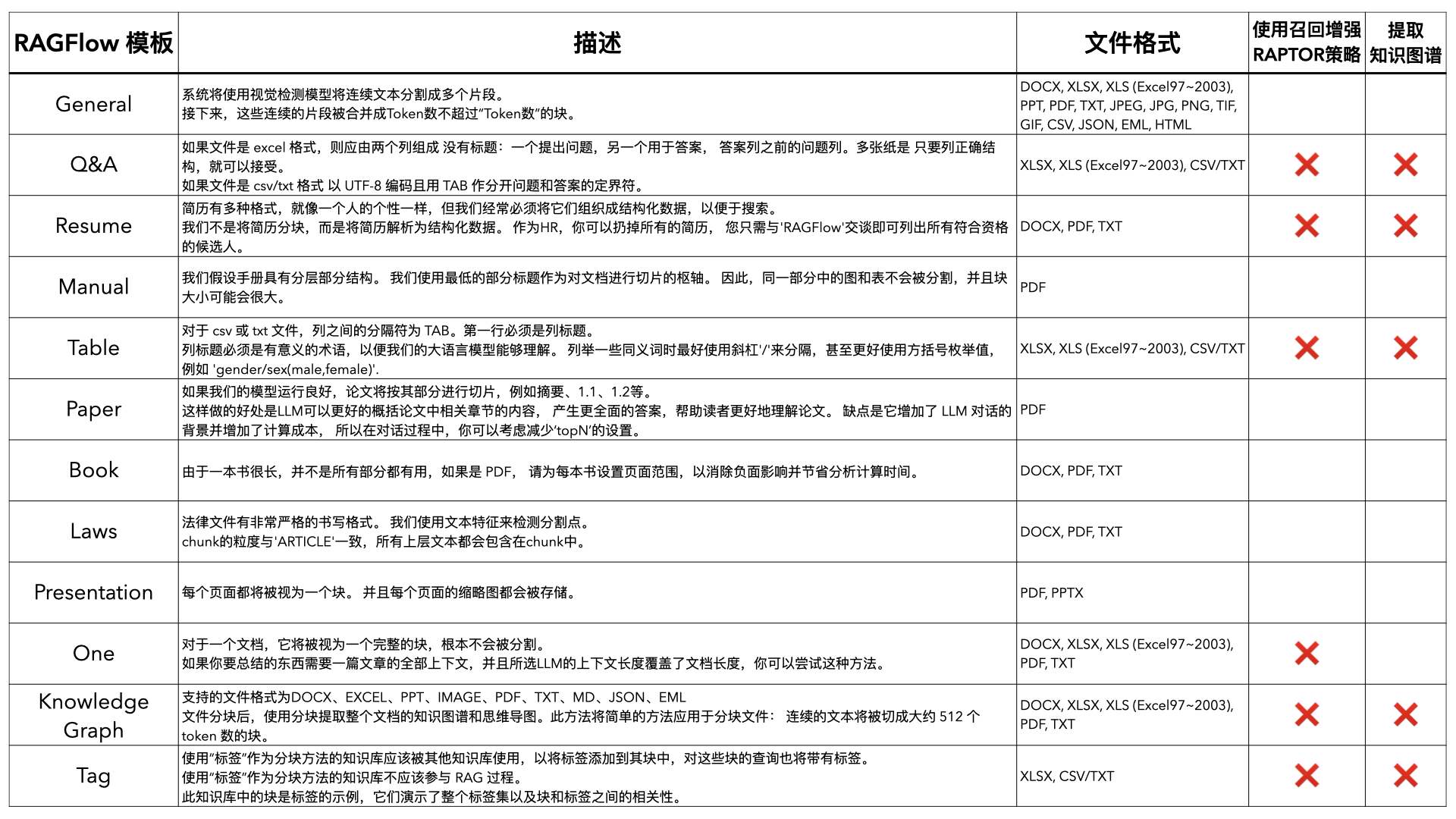
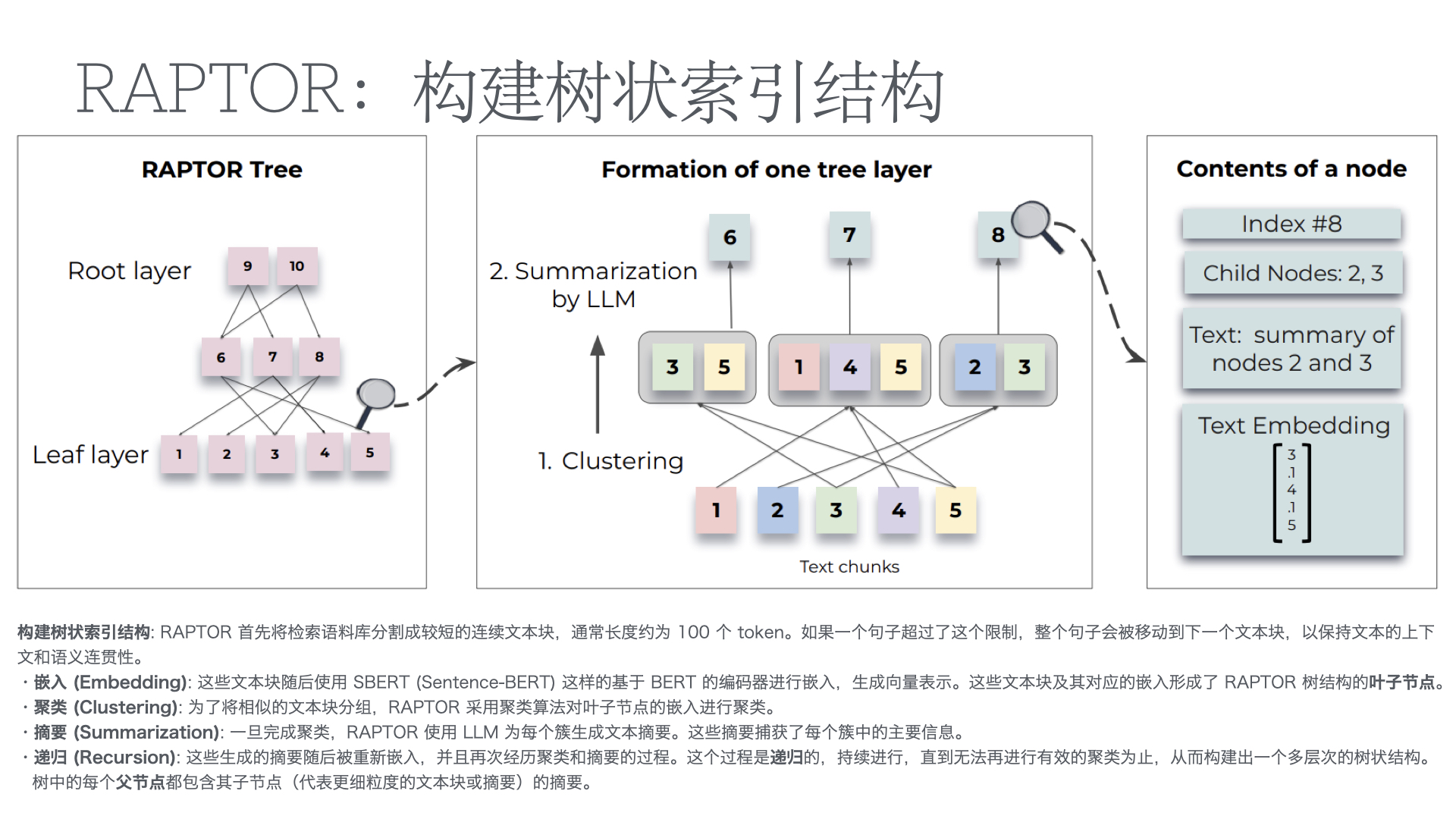
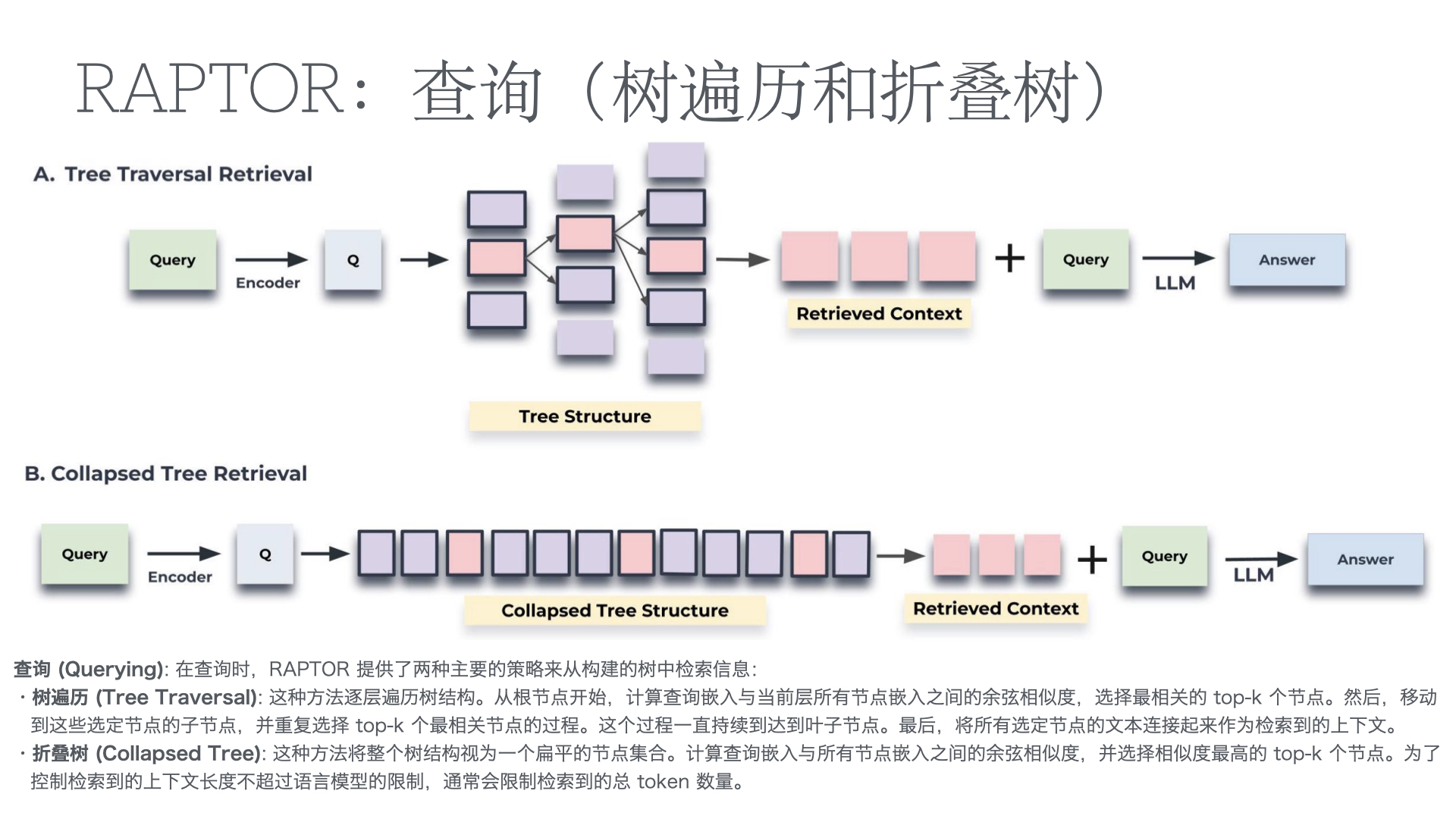
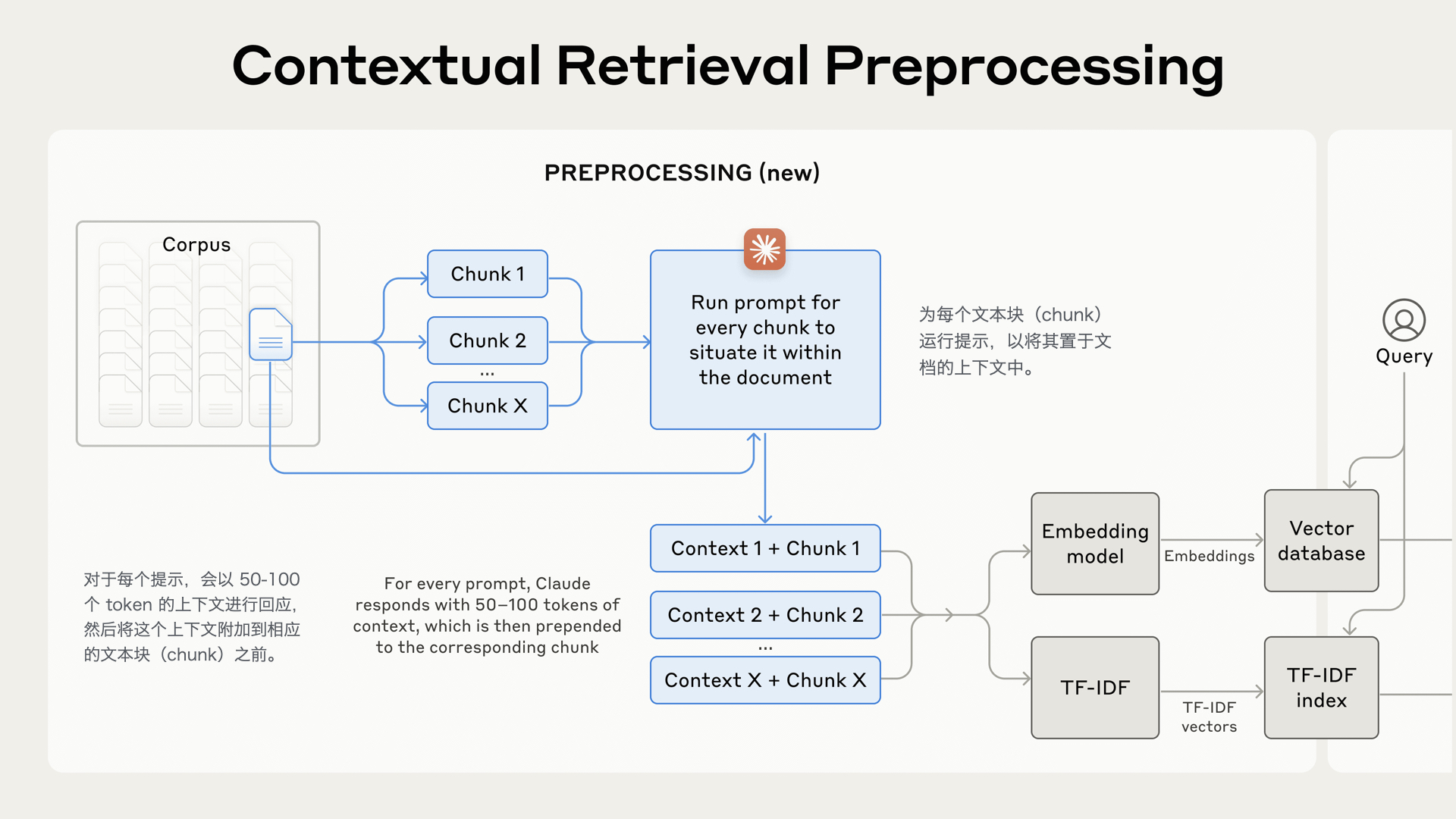
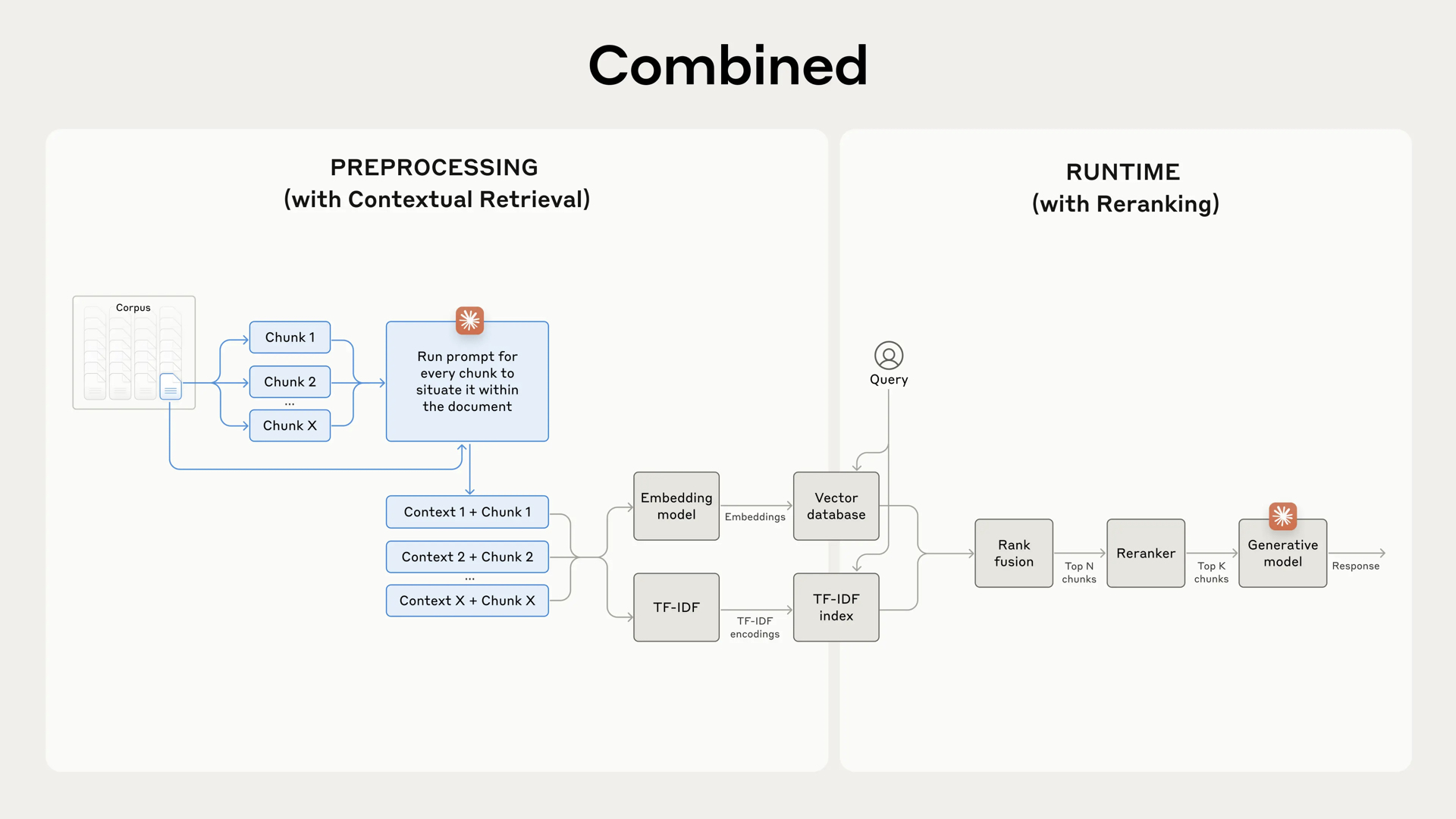
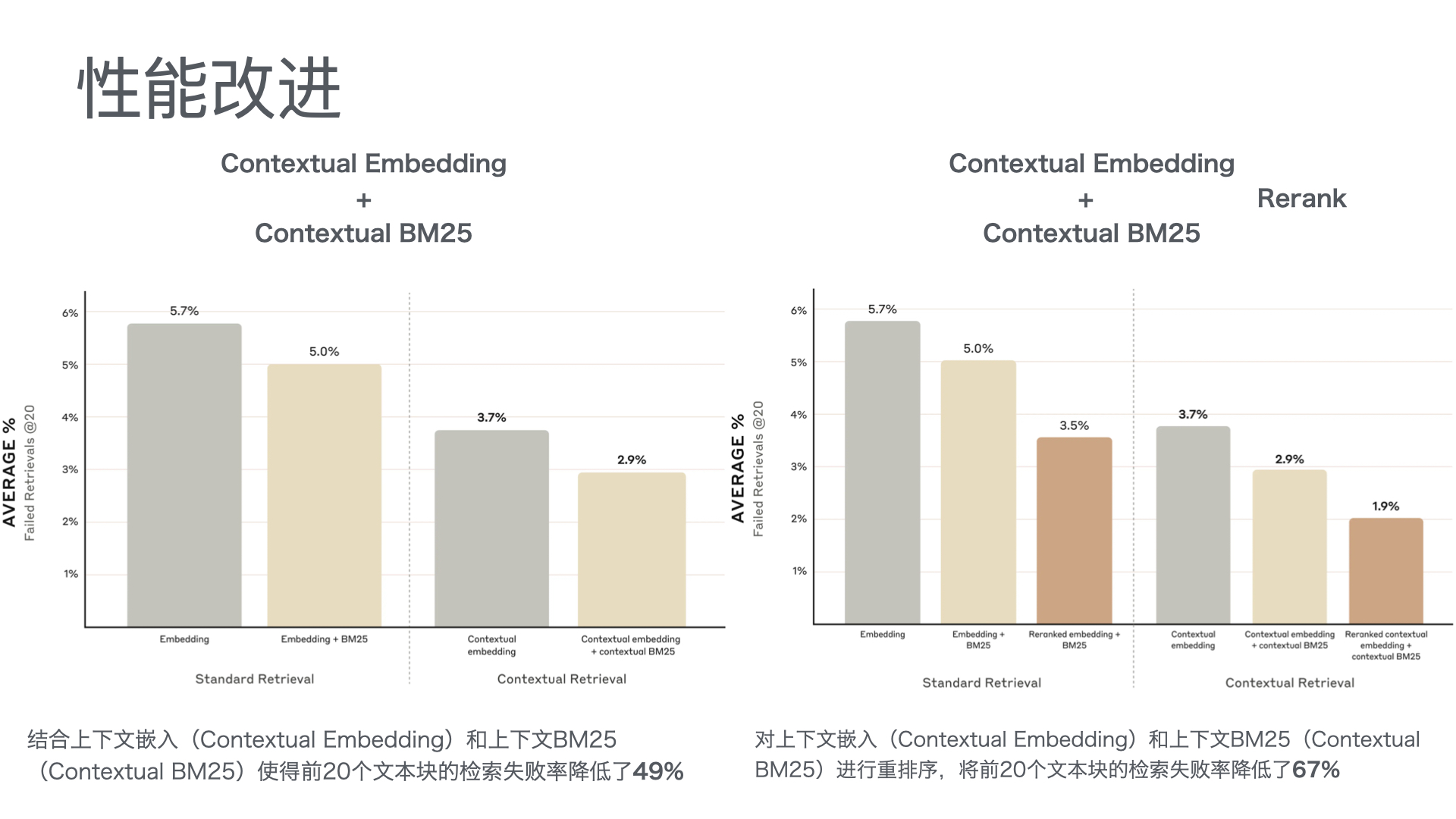
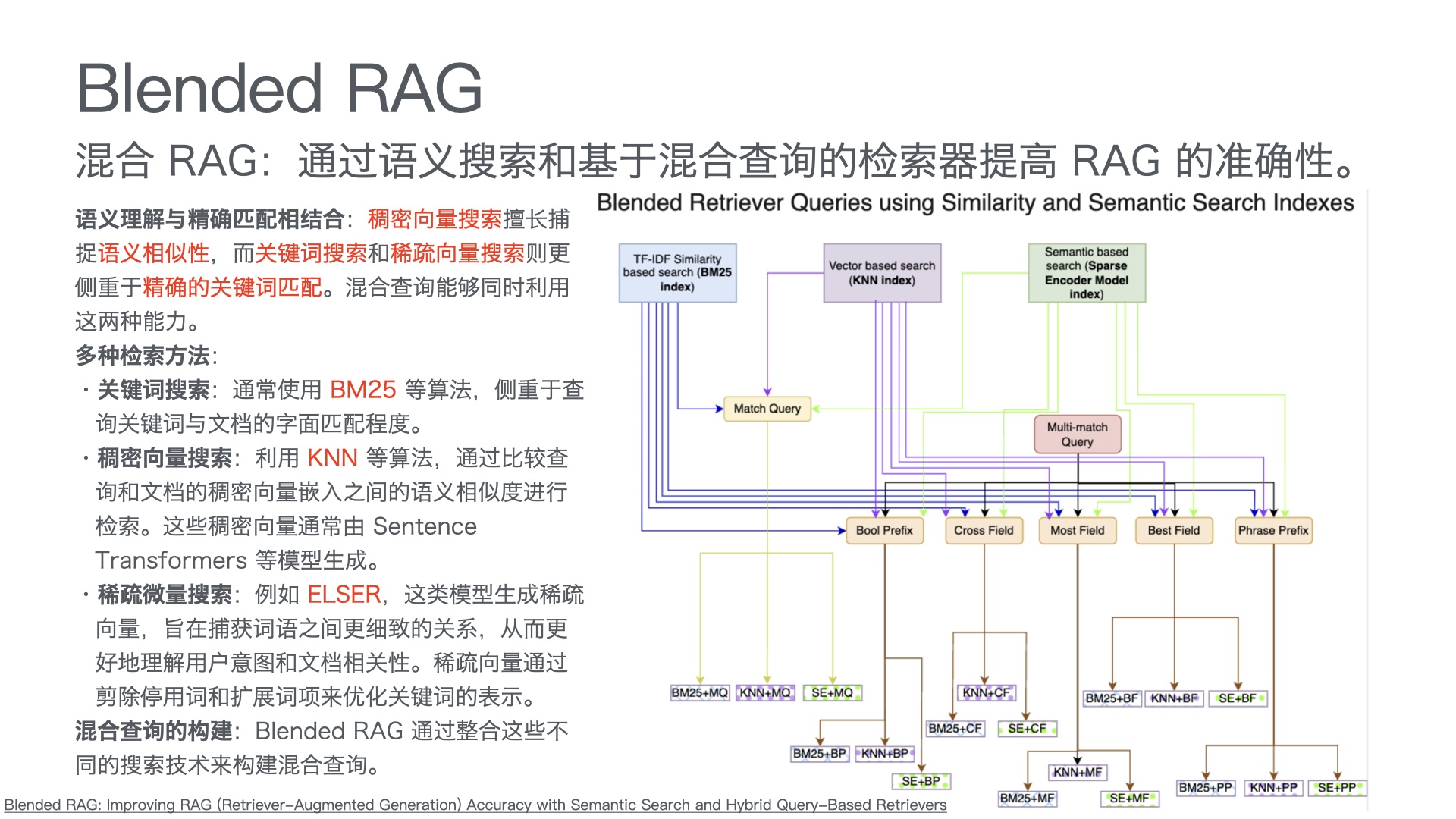
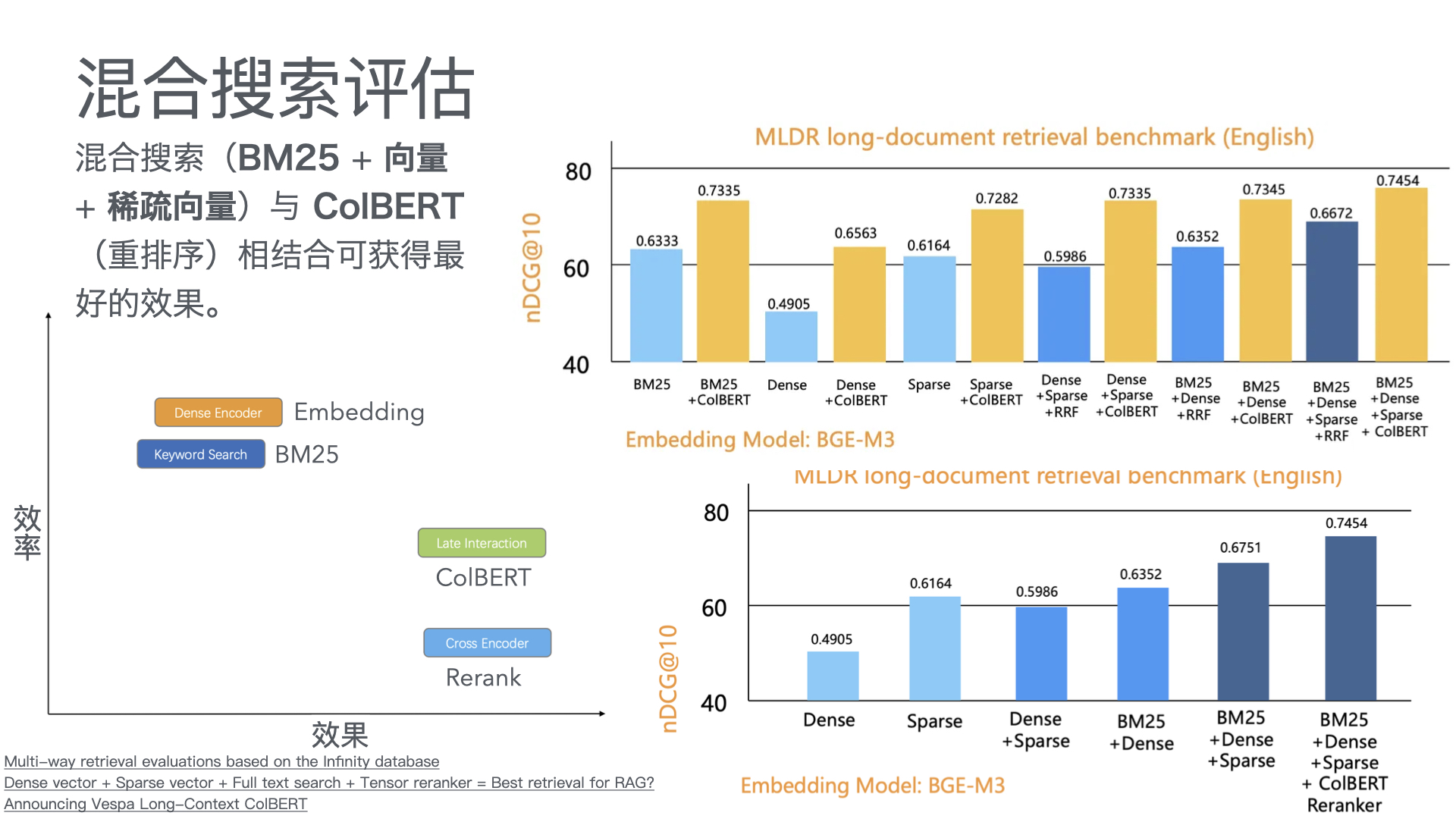
- 智能问答:基于RAG(检索增强生成)架构,系统从知识库中检索相关文档,再由大模型生成精准答案。方案匹配准确率可达92%以上。
- 多模态故障识别:支持客户上传故障图片/视频,利用多模态大模型进行图像识别与故障推理,自动推送处理建议。
- 智能路由与转人工:AI首轮处理常规问题,疑难问题自动转接人工客服,实现“AI首轮服务+人工兜底”的协同模式。
- 知识自进化:系统在问答过程中持续学习,客户采纳的答案自动整理为问答对,不断优化知识库。
1.3 实施路径(建议分三期)