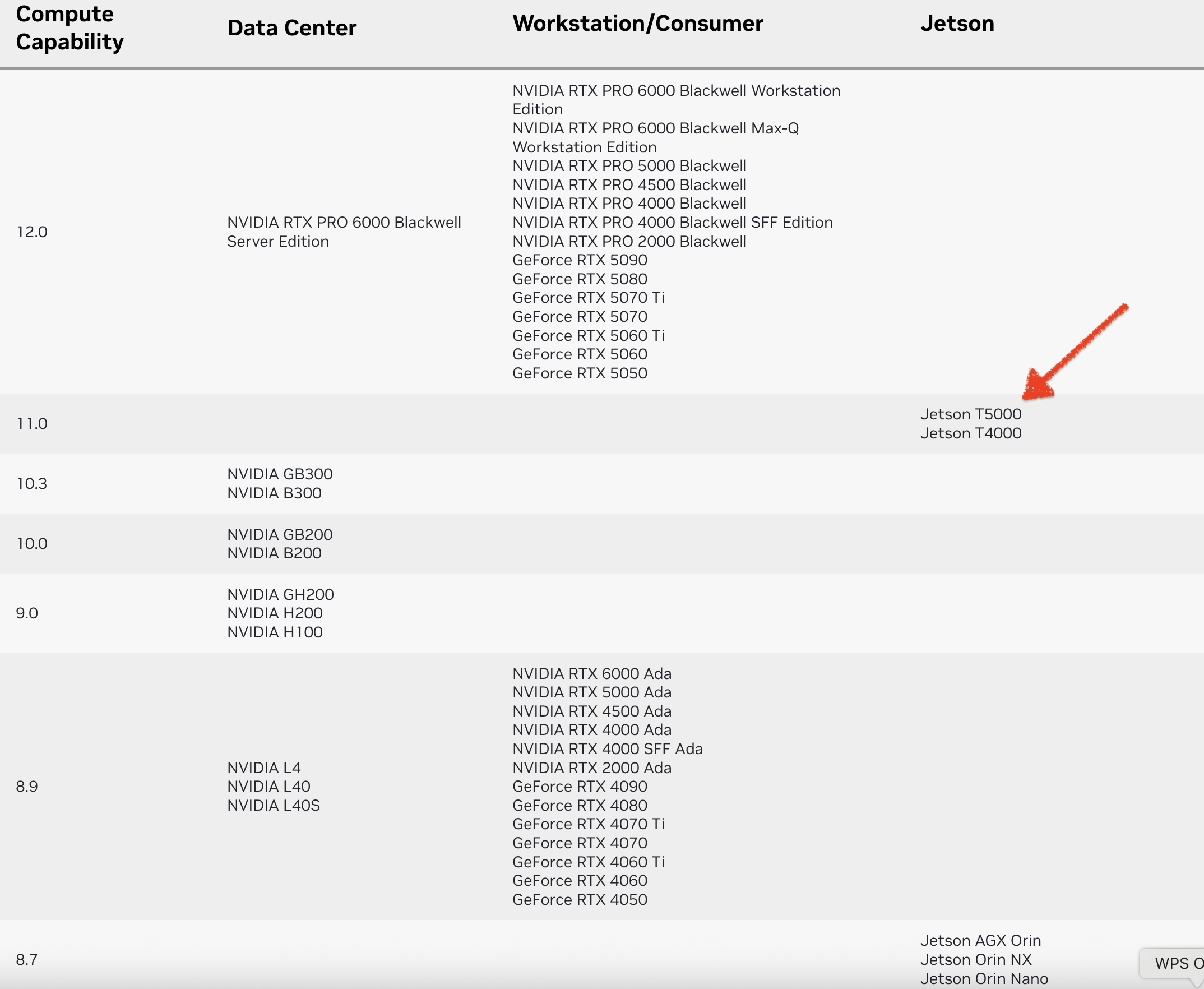
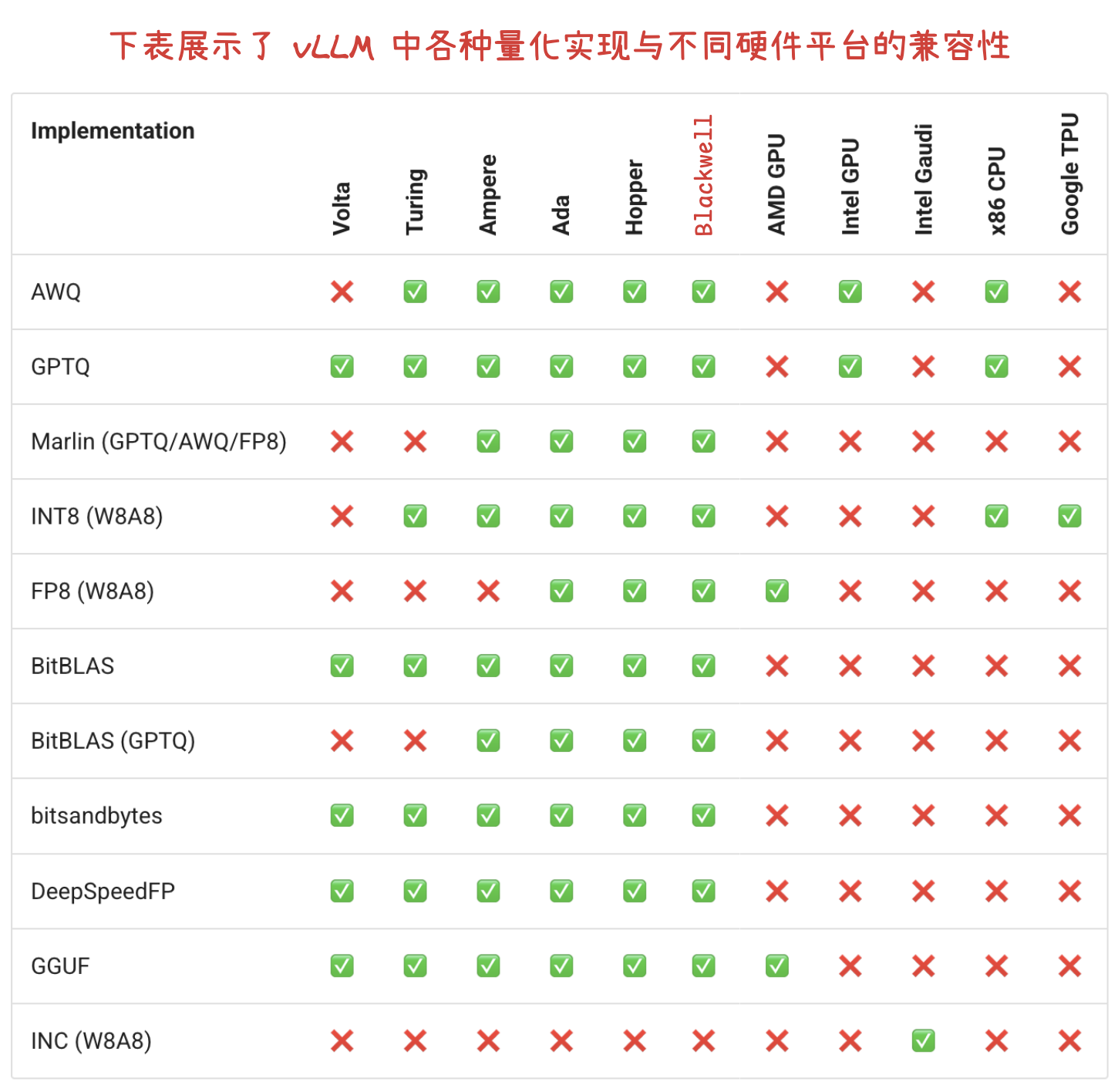
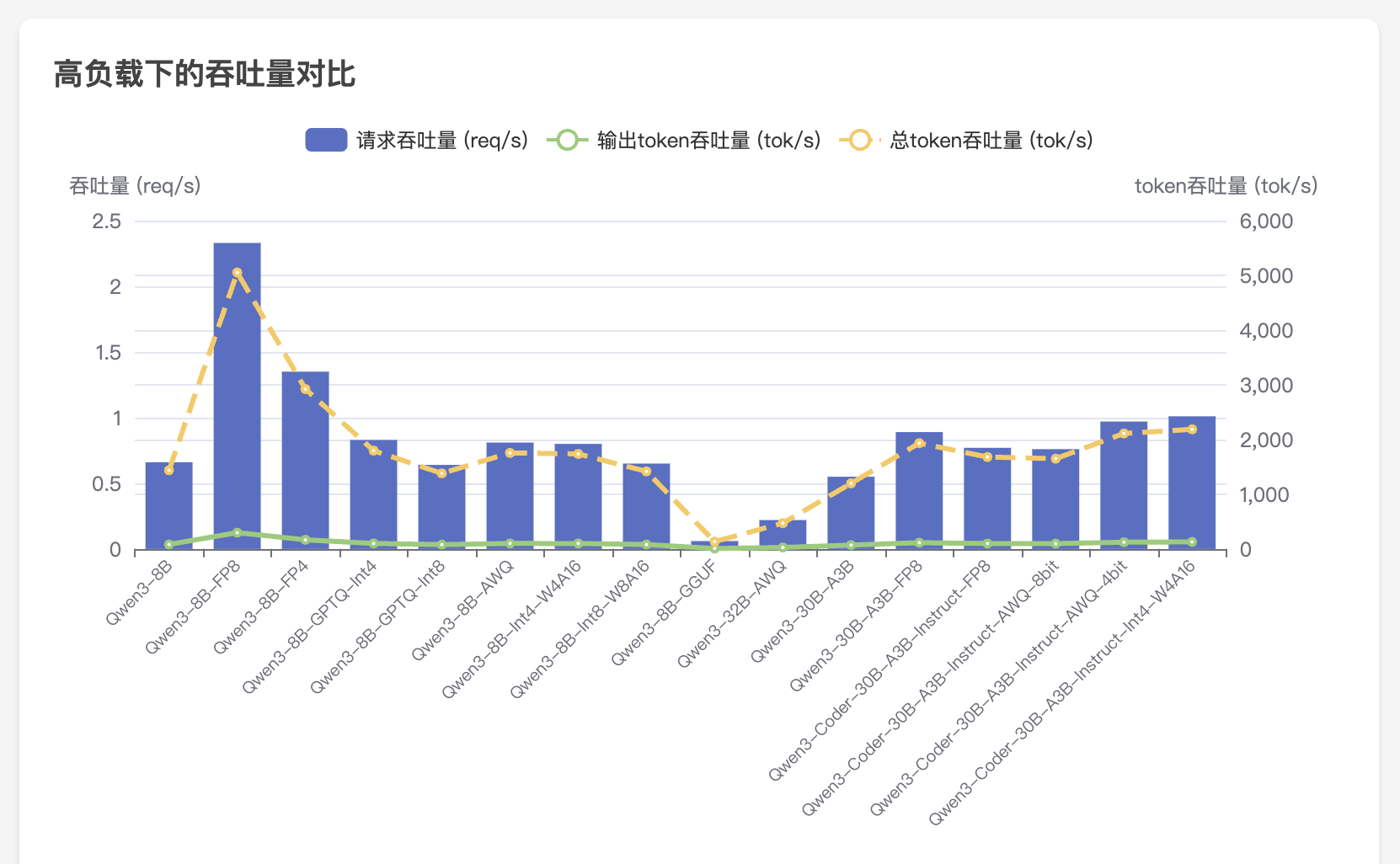
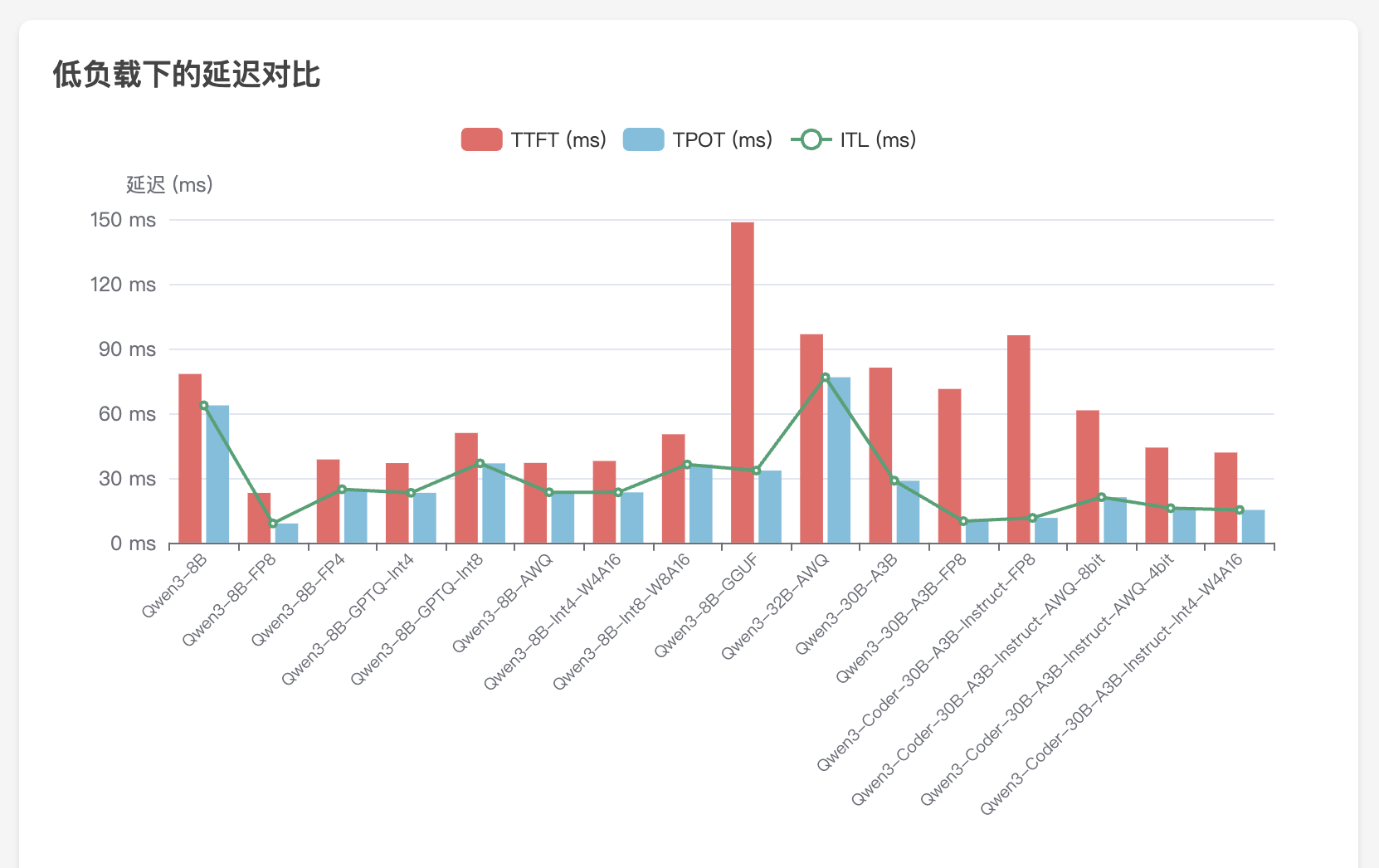
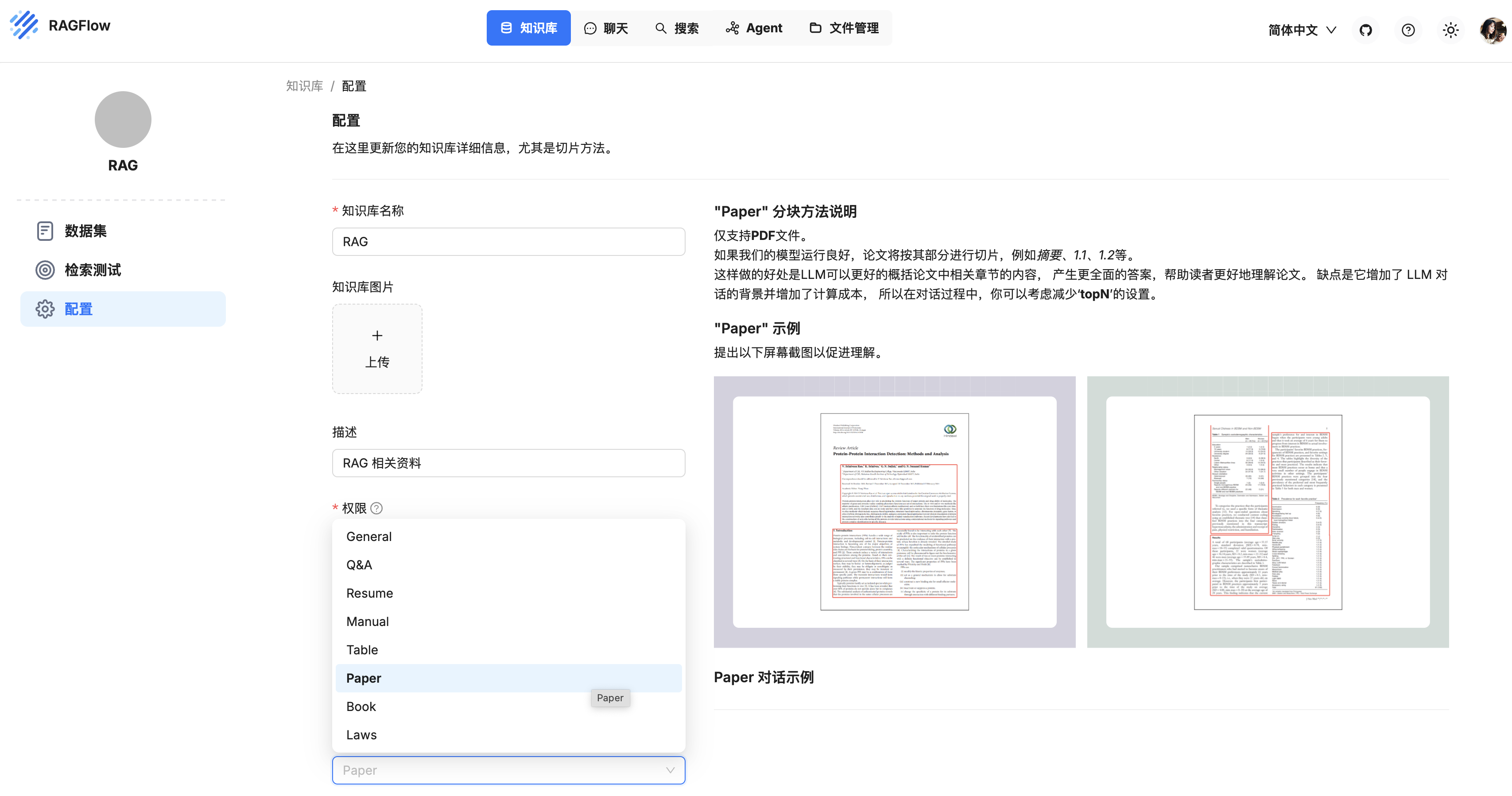
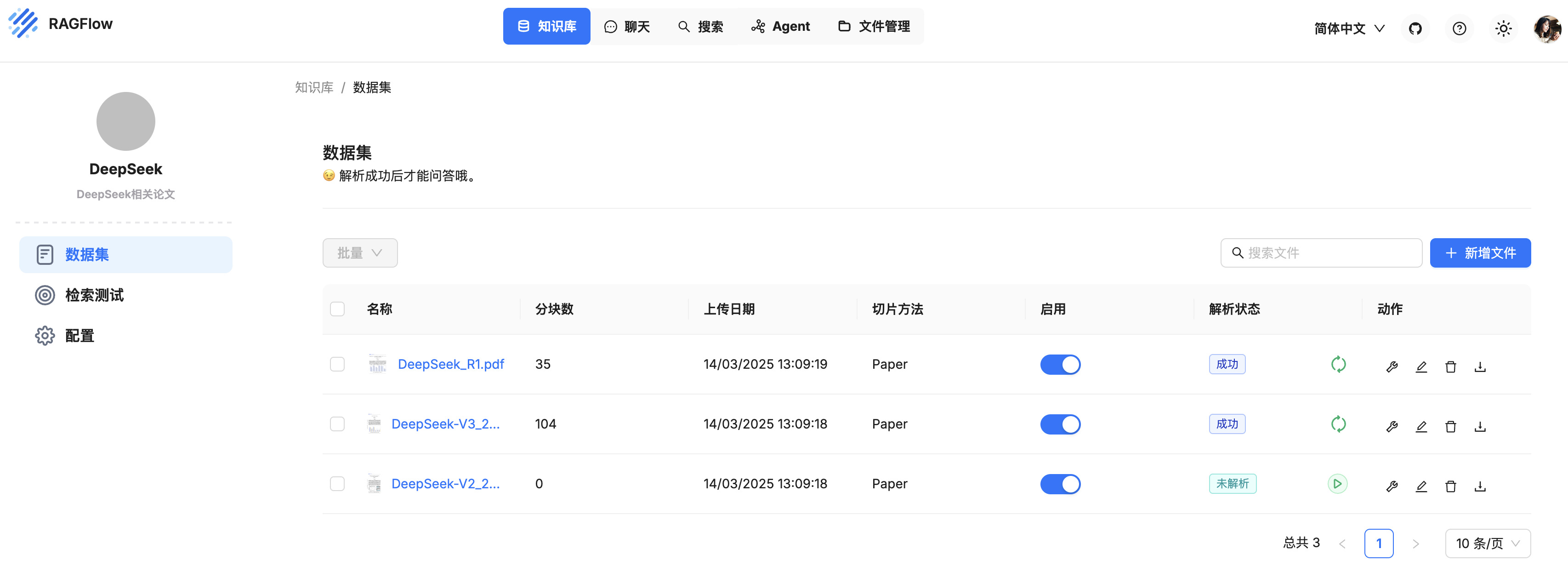
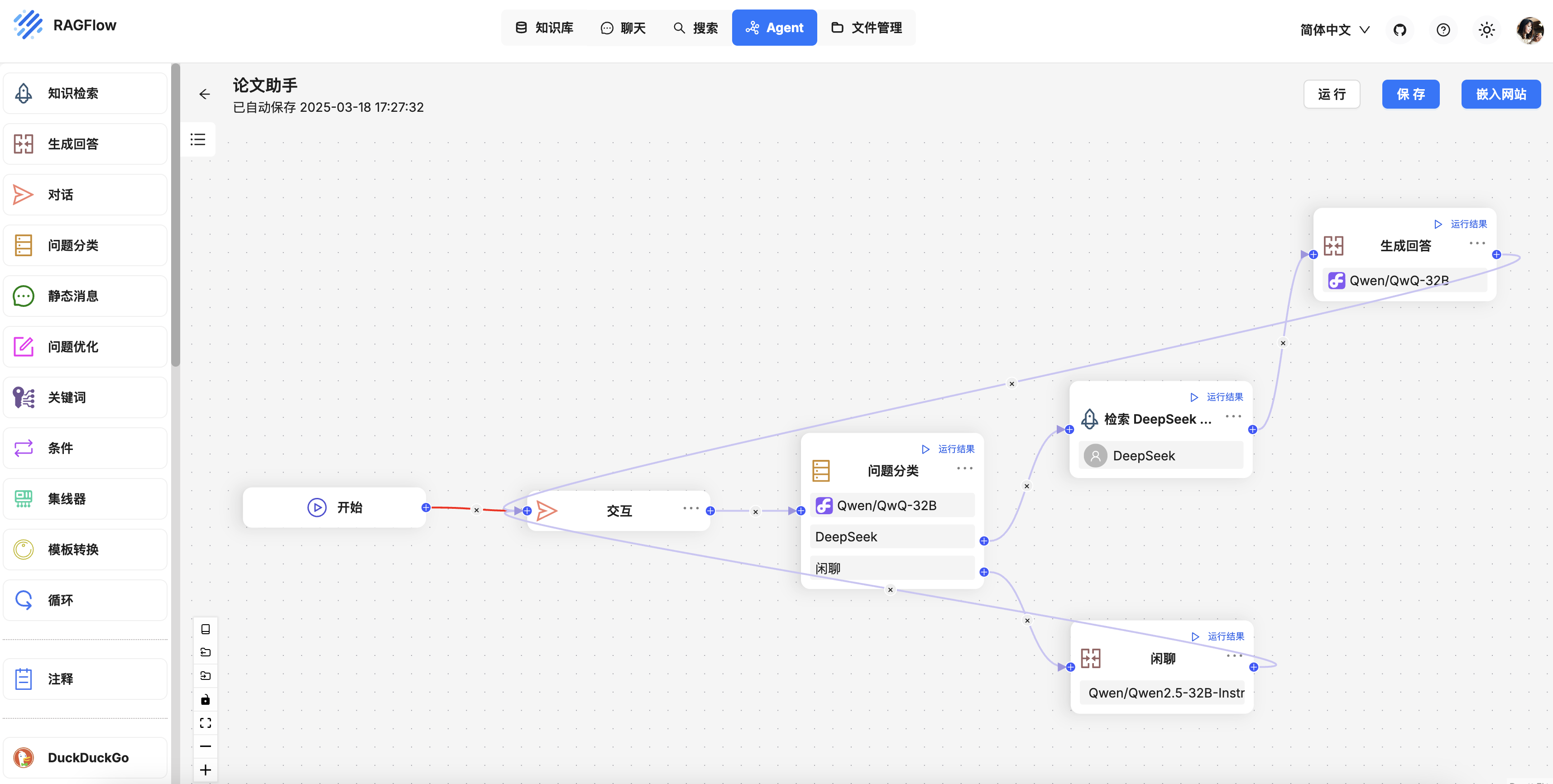
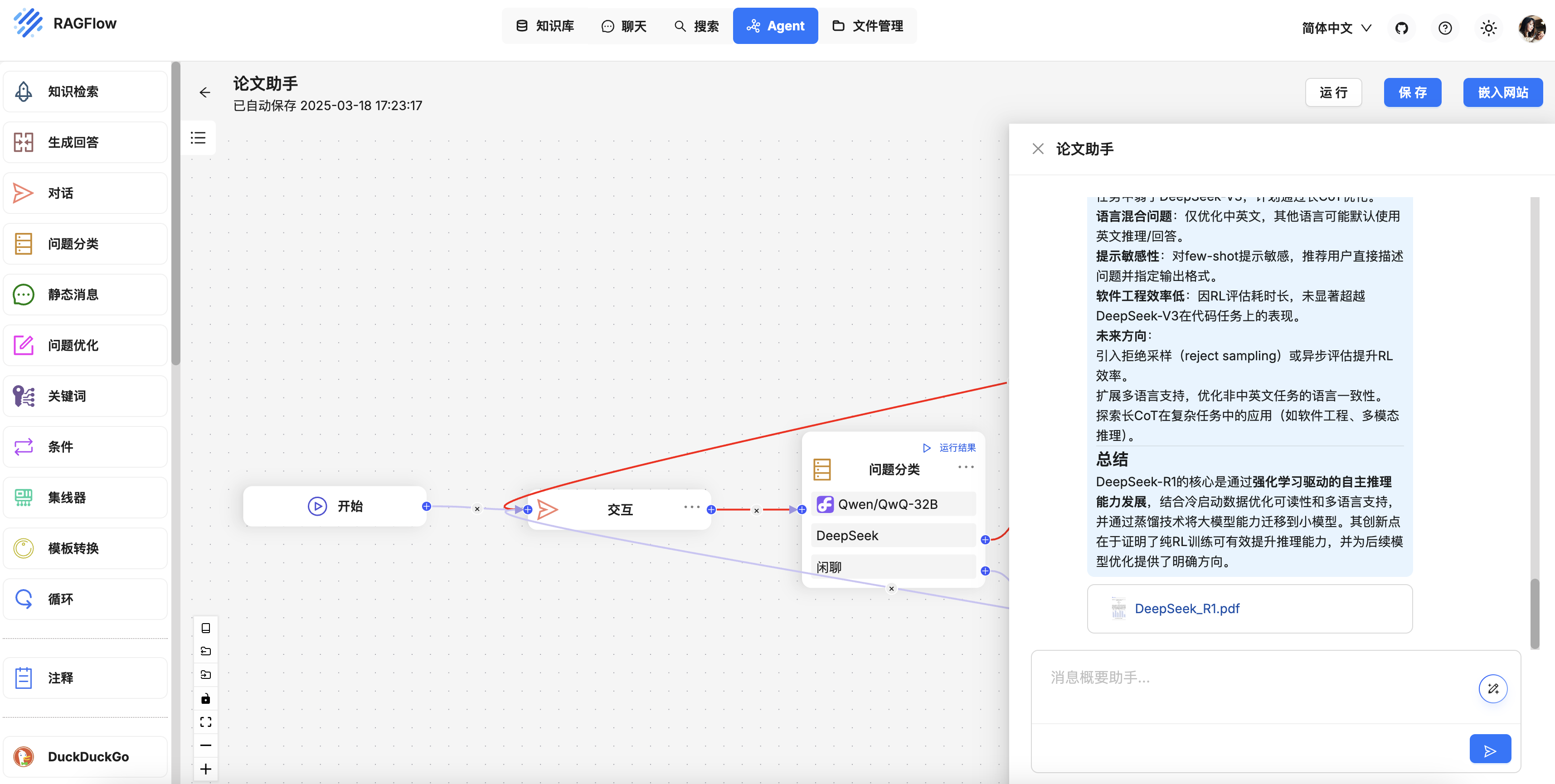
Dify 定制您的政策解读智能体
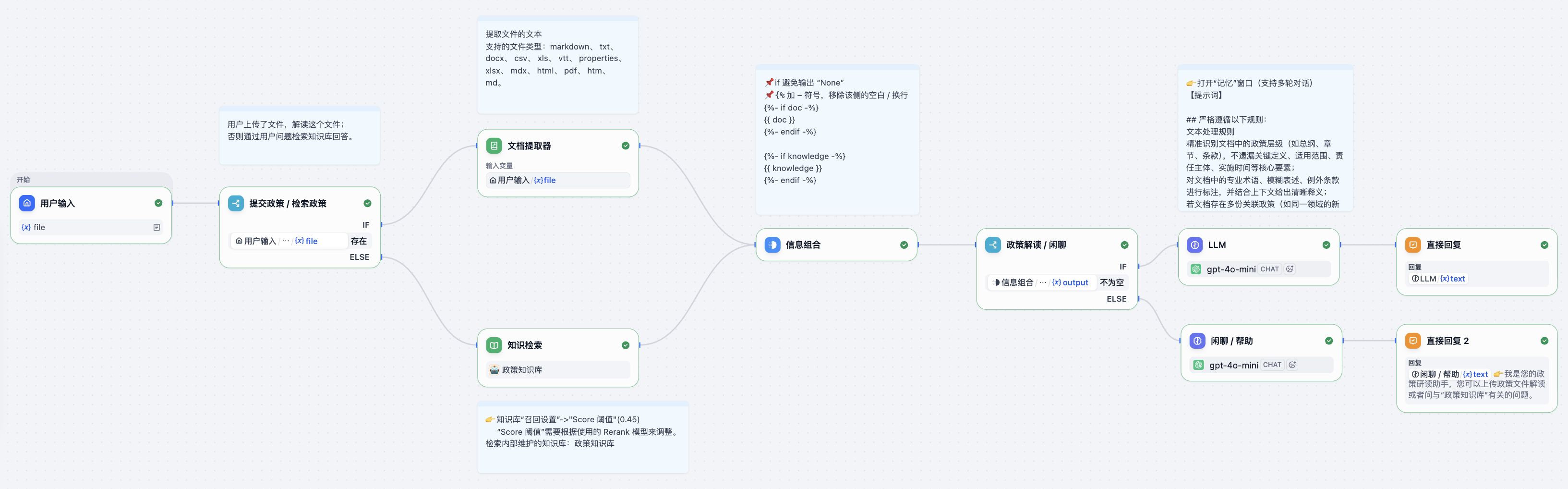
📌 DSL
Dify
- 克隆代码仓库
git clone https://github.com/langgenius/dify
- Docker 部署
Dify 提供了 Docker 部署方式,您可以通过以下步骤快速部署:
cd dify
cd docker
cp .env.example .env
docker compose up -d
运行后,可以在浏览器上访问 http://localhost/install 进入 Dify 控制台并开始初始化安装操作。
vLLM
vllm serve /data/models/llm/deepseek/DeepSeek-R1-Distill-Qwen-32B-AWQ/ \
--served-model-name gpt-4o-mini \
--tensor-parallel-size 4 \
--max-model-len 102400 \
--dtype half \
--port 8111
Ollama
- 安装 Ollama 服务。
curl -fsSL https://ollama.com/install.sh | sh
- 编辑 systemd 服务,调用
systemctl edit ollama.service。这将打开一个编辑器。
sudo systemctl edit ollama.service
对于每个环境变量,在 [Service] 部分下添加一行