端侧AI:Gemma 4 12B 创新架构与 LiteRT-LM 本地部署指南
- Introducing Gemma 4 12B: a unified, encoder-free multimodal model
- Gemma 4 12B: The Developer Guide
- Accelerating Gemma 4: faster inference with multi-token prediction drafters
- A Visual Guide to Gemma 4 12B
- Gemma 4: Byte for byte, the most capable open models
- Ollama Gemma 4
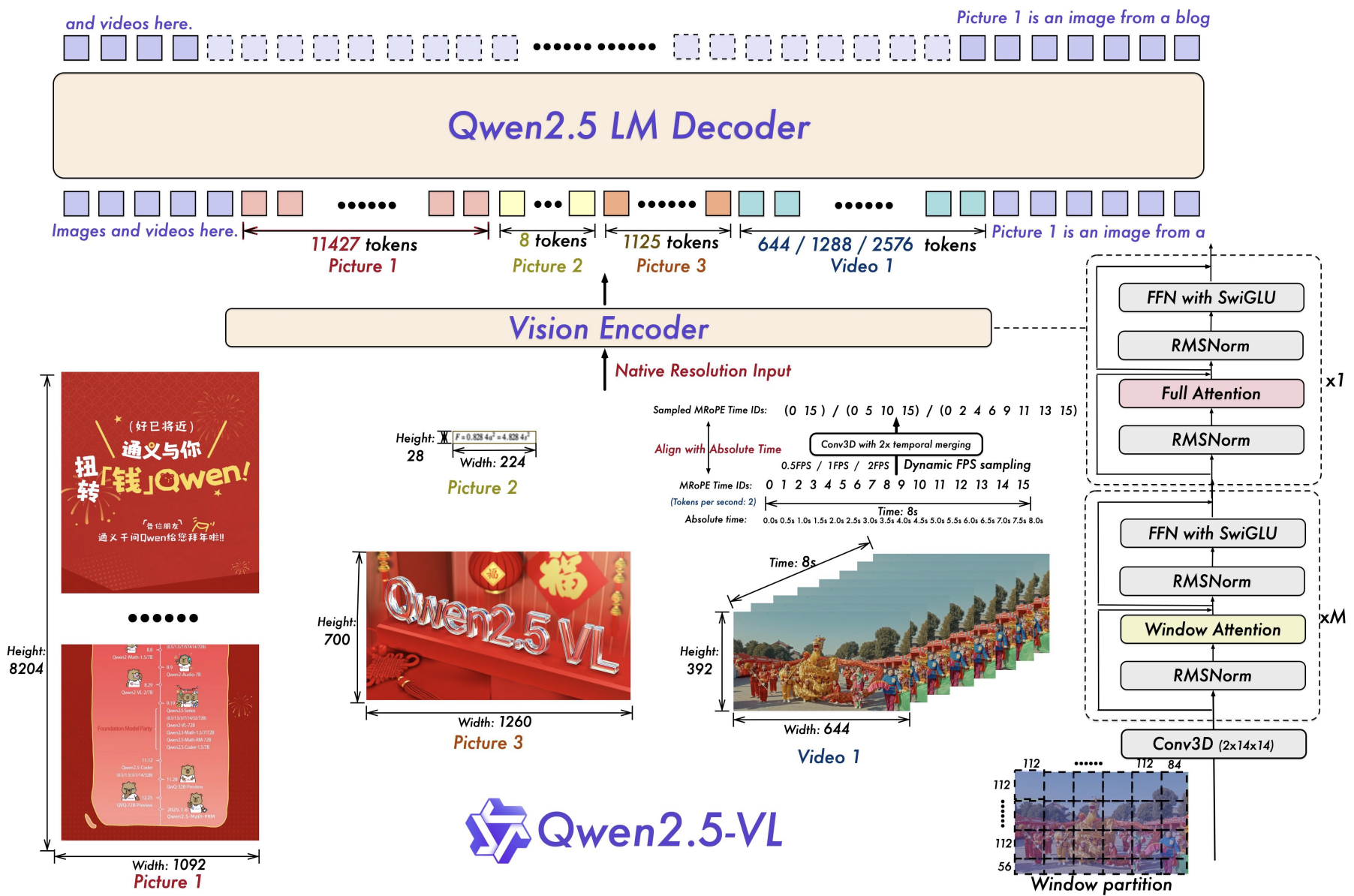
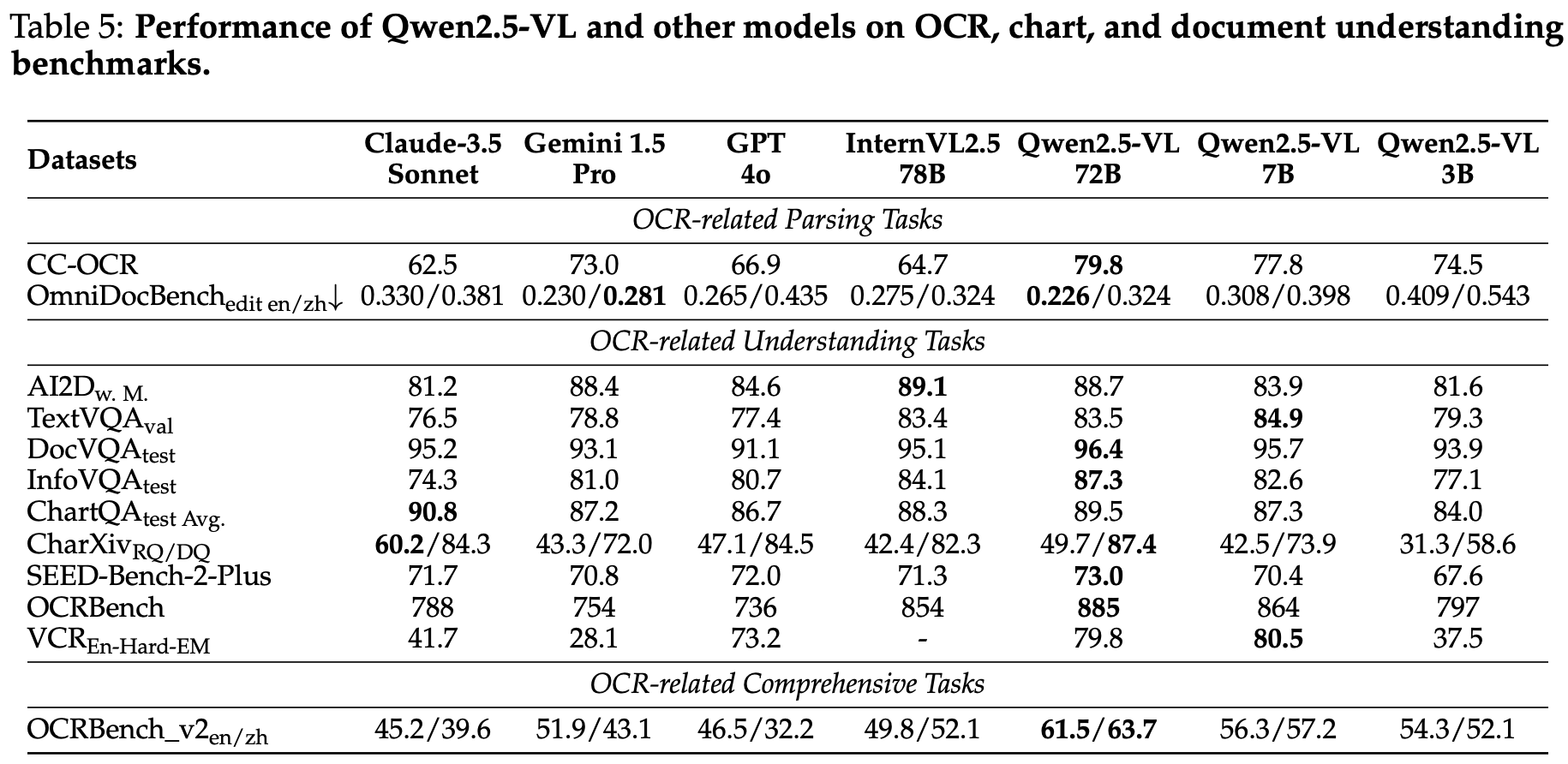
Gemma 4 12B 是谷歌最新推出的一款原生、无编码器(Encoder-free)的统一多模态大模型。它的核心定位是将高水平的“智能体(Agentic)”和多模态能力直接带到用户的笔记本电脑等日常消费级硬件上。
以下是对 Gemma 4 12B 大模型的详细介绍:
1. 创新的统一架构:无编码器设计(Encoder-free)
与传统的多模态模型(通常需要使用独立的、冻结的视觉或音频编码器将数据转化为文本格式)不同,Gemma 4 12B 采用了统一的、仅解码器(Decoder-only)的 Transformer 架构。
- 视觉嵌入器(Vision Embedder):仅有 35M 参数,取代了传统复杂的视觉 Transformer 层。它将 48x48 像素的原始图像块(Patches)通过单次矩阵乘法直接投影到大语言模型(LLM)的隐藏维度中,并利用 X 和 Y 矩阵的坐标查找技术,直接将空间位置信息附带在输入中。
- 音频波形投影(Audio Wave Projection):完全取消了独立的音频编码器。它直接将 16 kHz 的原始音频信号切片为 40ms 的帧(每帧包含 640 个浮点数),并通过线性投影无缝输入到 LLM 的空间中。