🦞 本地 AI 助手 OpenClaw 的架构与记忆系统
🦞 OpenClaw 是一个本地优先(Local-First)、高度自治、基于 Markdown 记忆管理的 AI Agent(智能体)系统。
它的核心亮点在于:
- 数据主权 (Local-First): 记忆和配置都在本地 Markdown 文件中,用户完全掌控。
- 拟人化设计: 通过心跳机制 (
HEARTBEAT) 和分层记忆,试图构建一个有“长期记忆”和“自主行为”的 AI,而不仅仅是一个聊天机器人。 - 工程化落地: 考虑了多端接入、混合检索 RAG、上下文压缩以及安全沙盒,这是一个生产力级别的架构。
架构系统
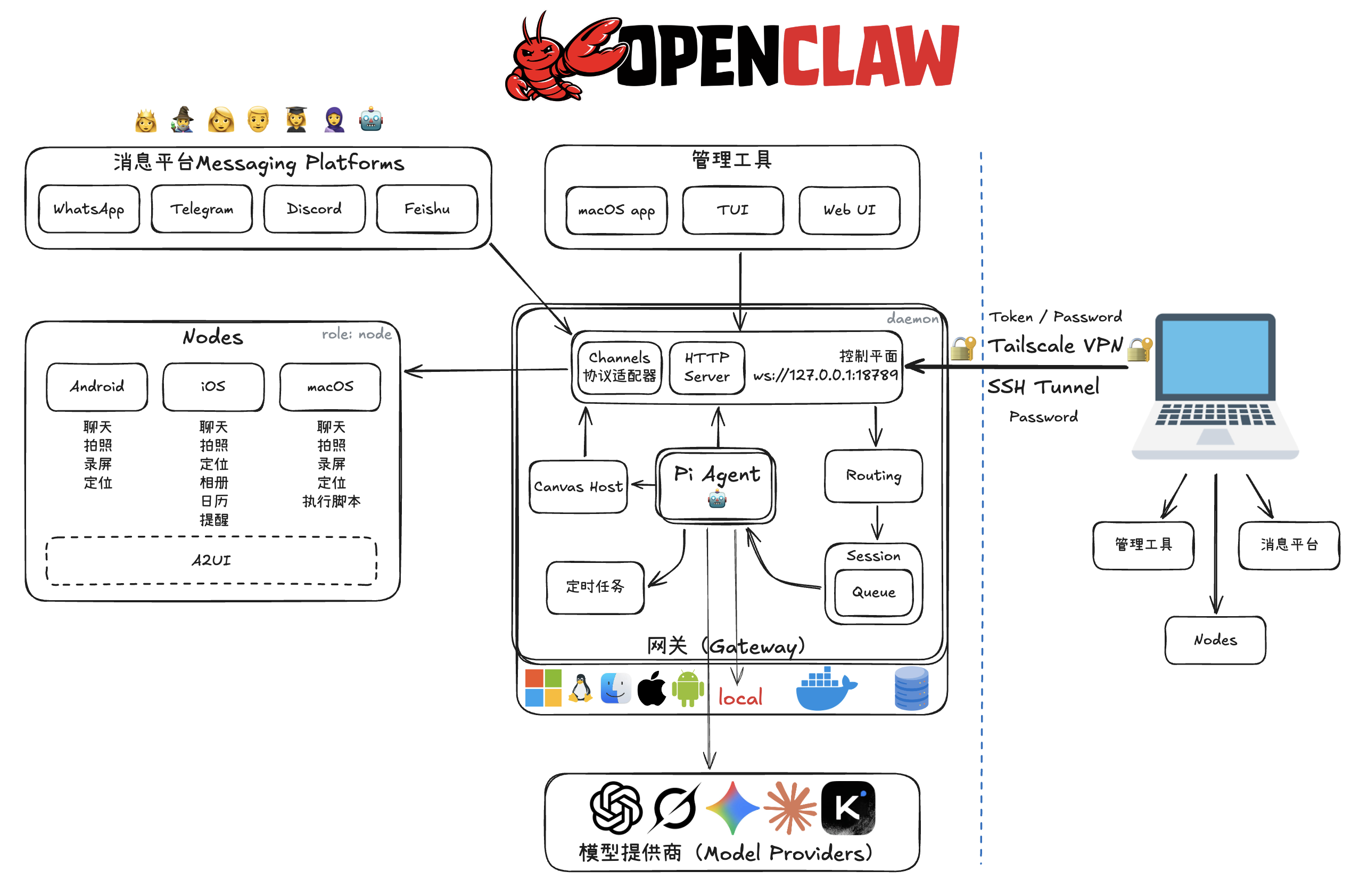
- 多端接入 (Messaging & Nodes):
- 消息平台: 支持 WhatsApp, Telegram, Discord, 飞书等主流通讯软件,意味着用户可以在这些 App 里直接与 Agent 对话。
- 客户端节点 (Nodes): 覆盖 Android, iOS, macOS。这些节点不仅是聊天窗口,还能调用设备能力(如拍照、定位、录屏、执行脚本),让 AI 拥有“手”和“眼”。
- 核心网关 (Gateway):
- 运行在本地(支持 Windows, Linux, macOS, iOS, Android, Docker 等)。
- 包含控制平面、HTTP Server、路由、会话管理和任务队列。
- Pi Agent: 是核心大脑,负责处理逻辑。
- 远程管理: 通过 Tailscale VPN 或 SSH Tunnel 进行安全的远程连接,保障了数据传输的安全性(无需暴露公网 IP)。