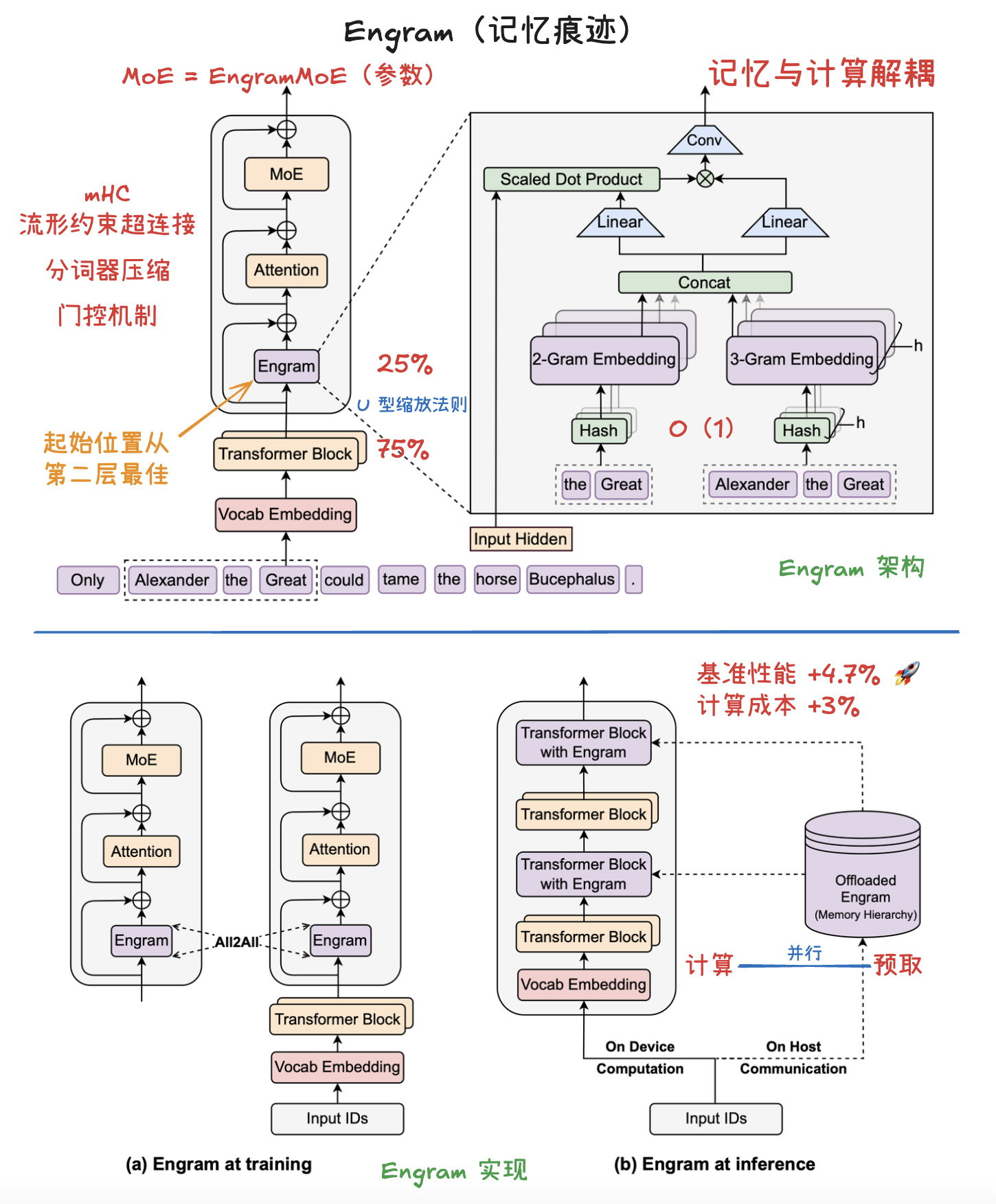
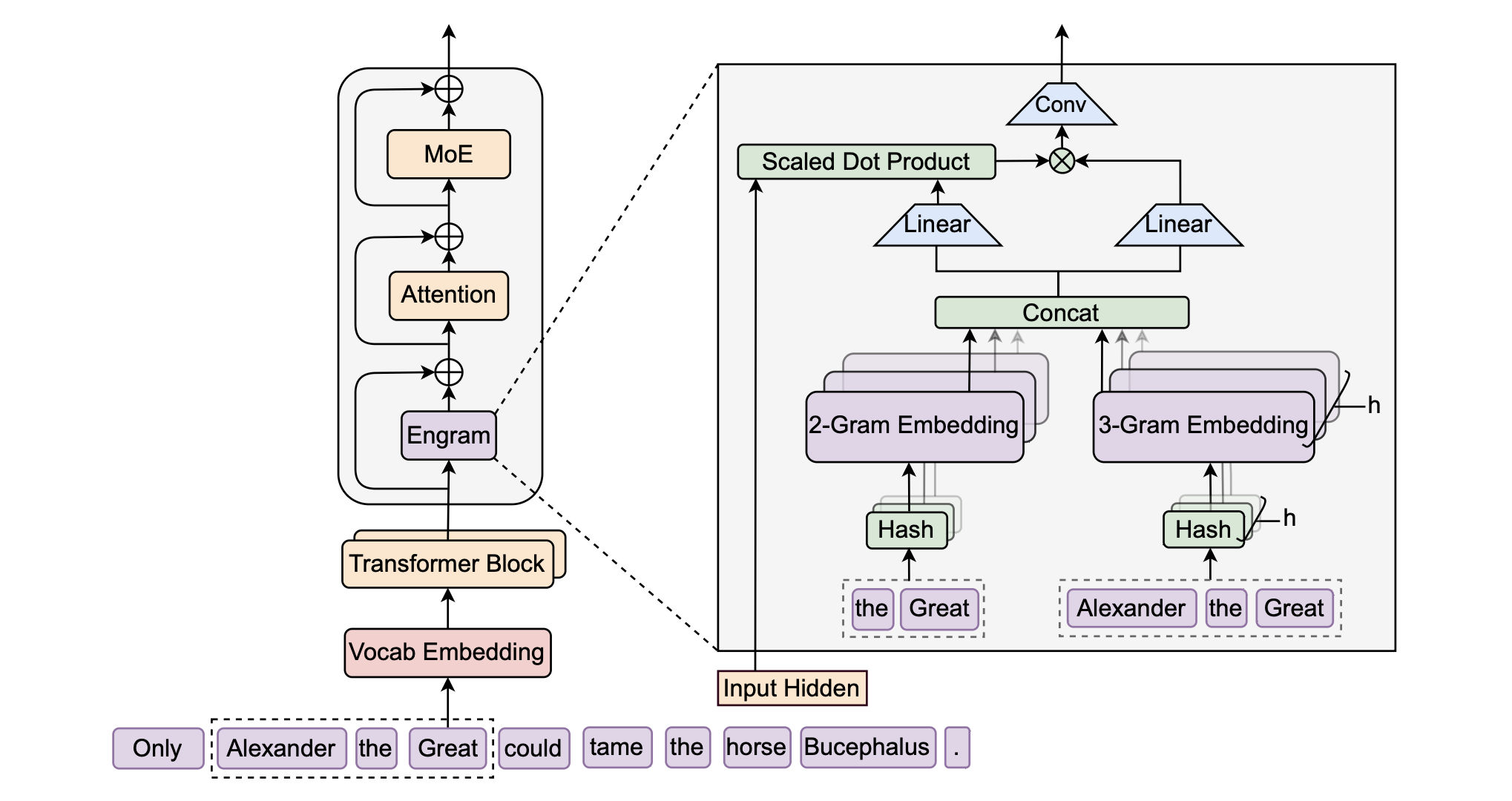
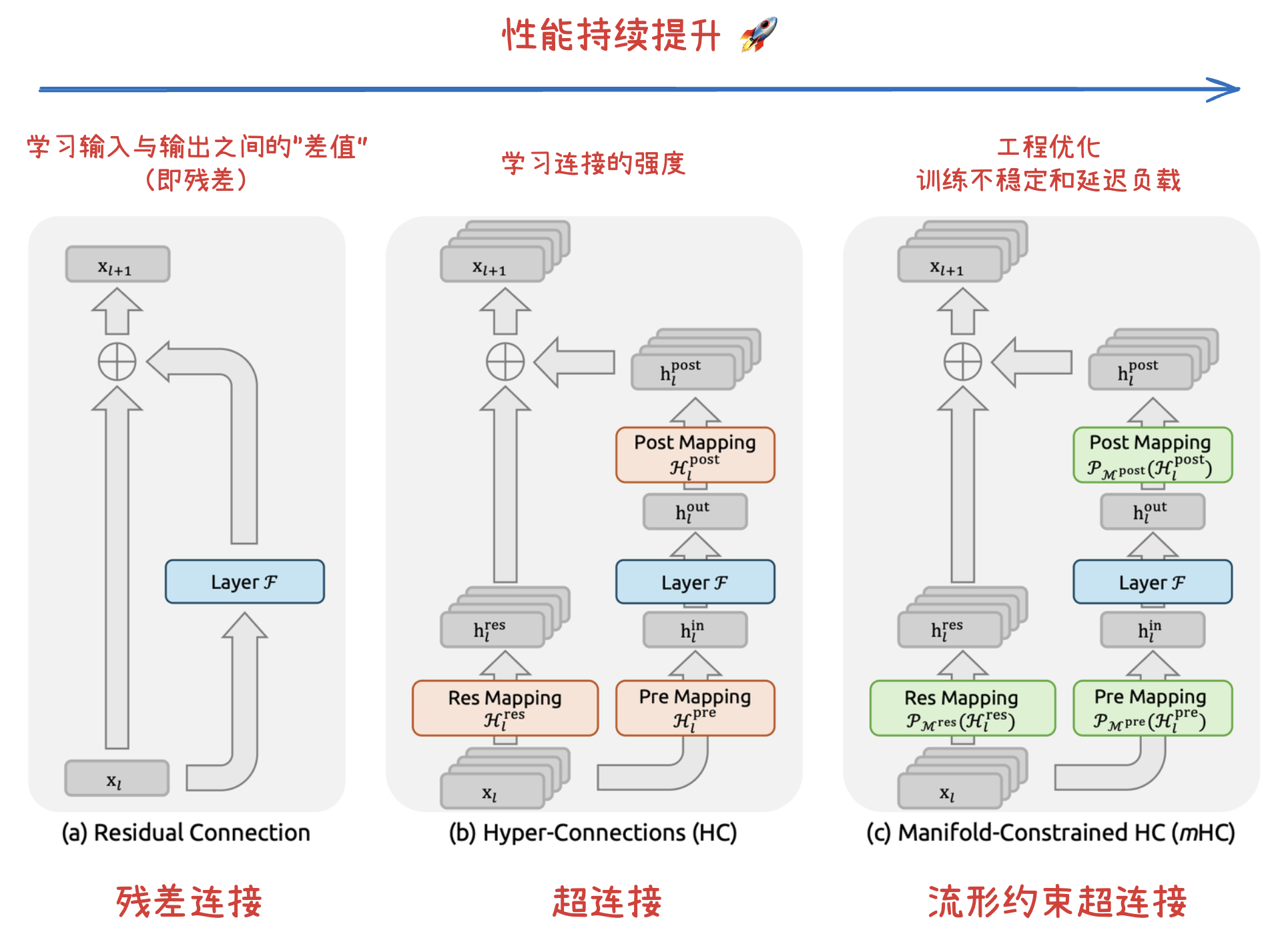
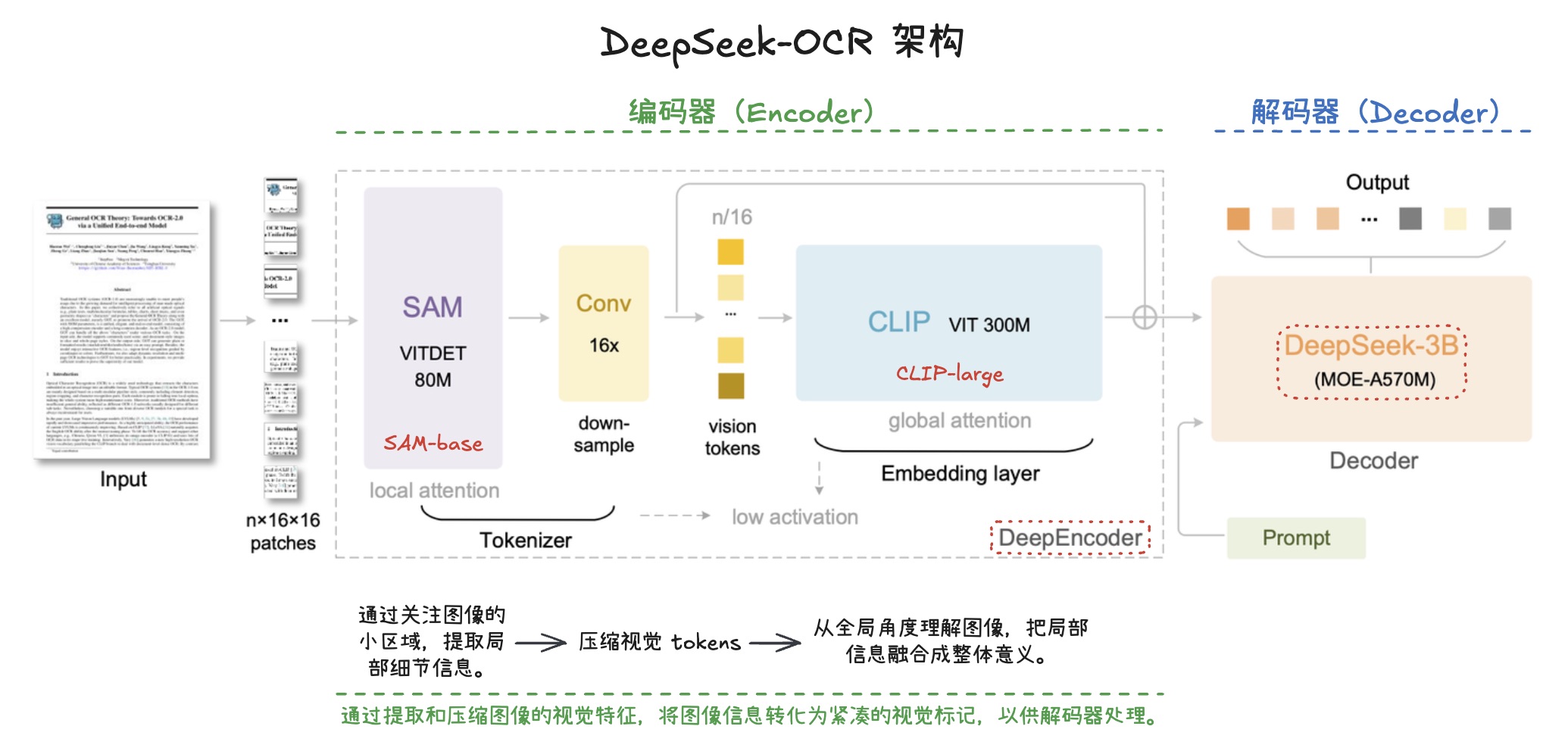
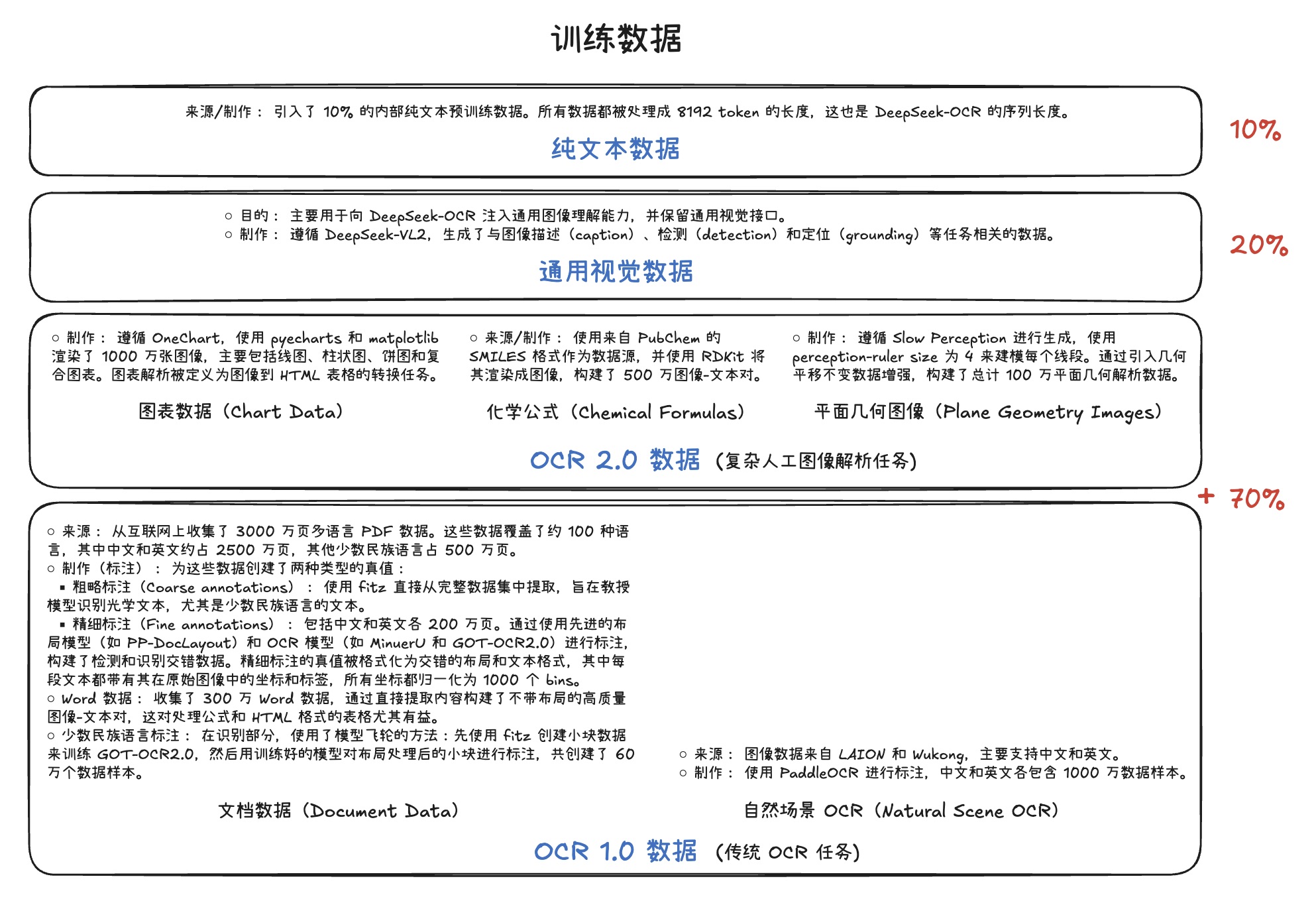
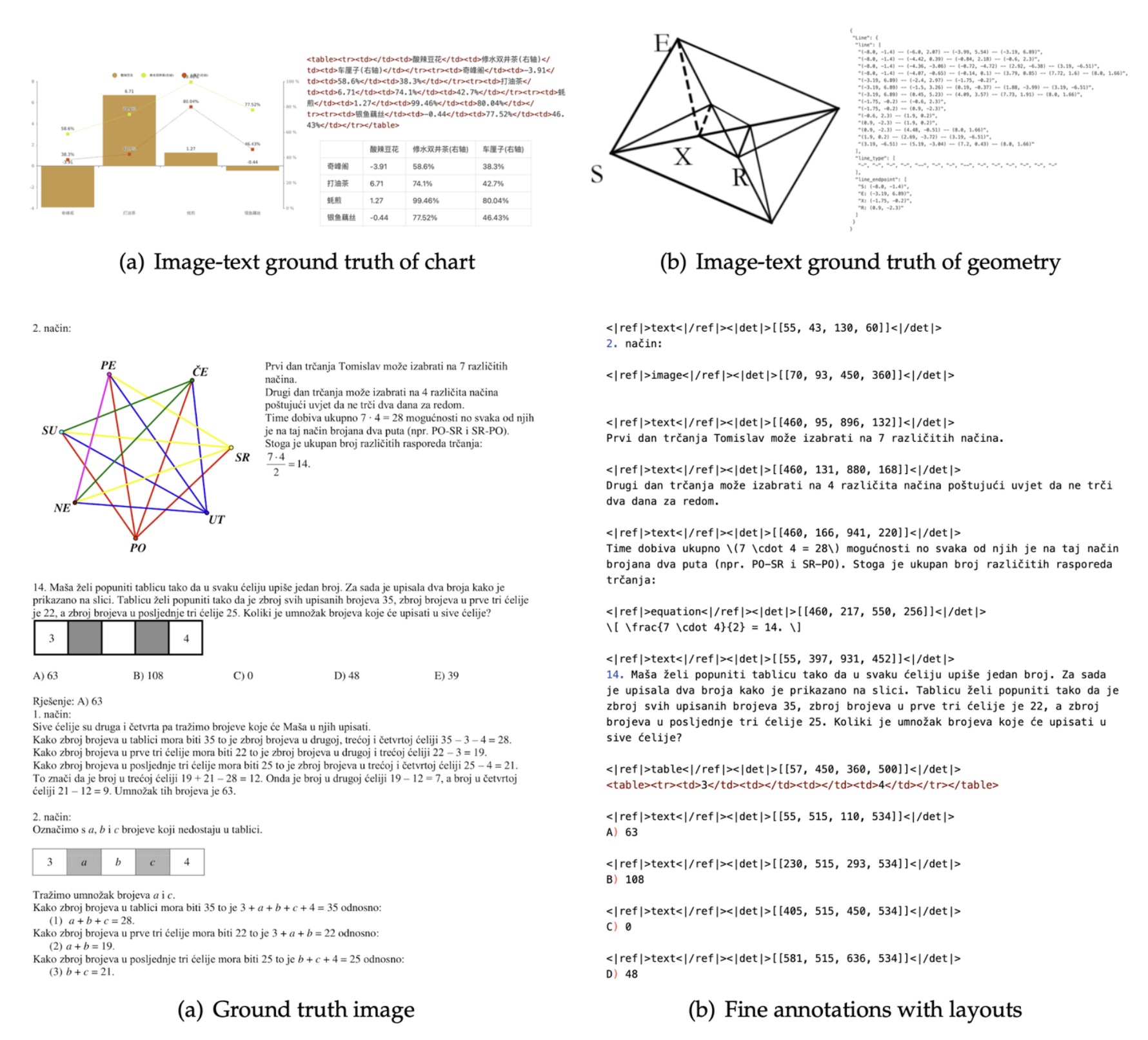
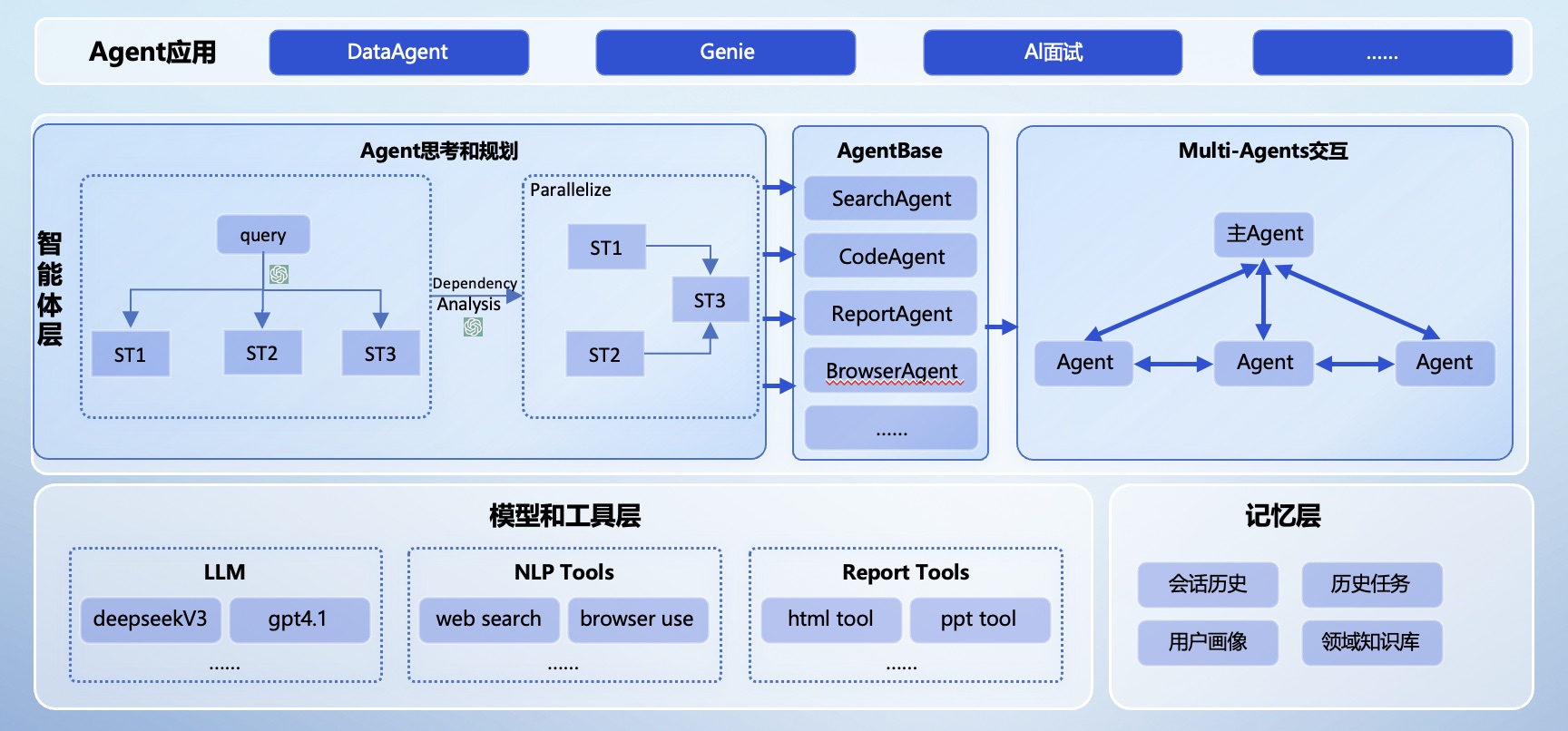
大模型推理加速:DFlash、DSpark 与 Eagle3 草稿模型选型与架构设计指南
在大语言模型(LLM)的生产落地中,自回归生成的 延迟始终是制约用户体验与系统吞吐的瓶颈。投机采样(Speculative Decoding)通过引入轻量级的“草稿模型(Draft Model)”先行生成候选 Token,再由大模型(Verification Model)进行并行校验,成为了当前最主流的加速方案。
本文将针对当前业界前沿的三种草稿模型方案——DFlash(纯并行)、DSpark(半自回归) 与 Eagle3(纯自回归) 进行深度架构剖析、技术指标对比及选型建议。
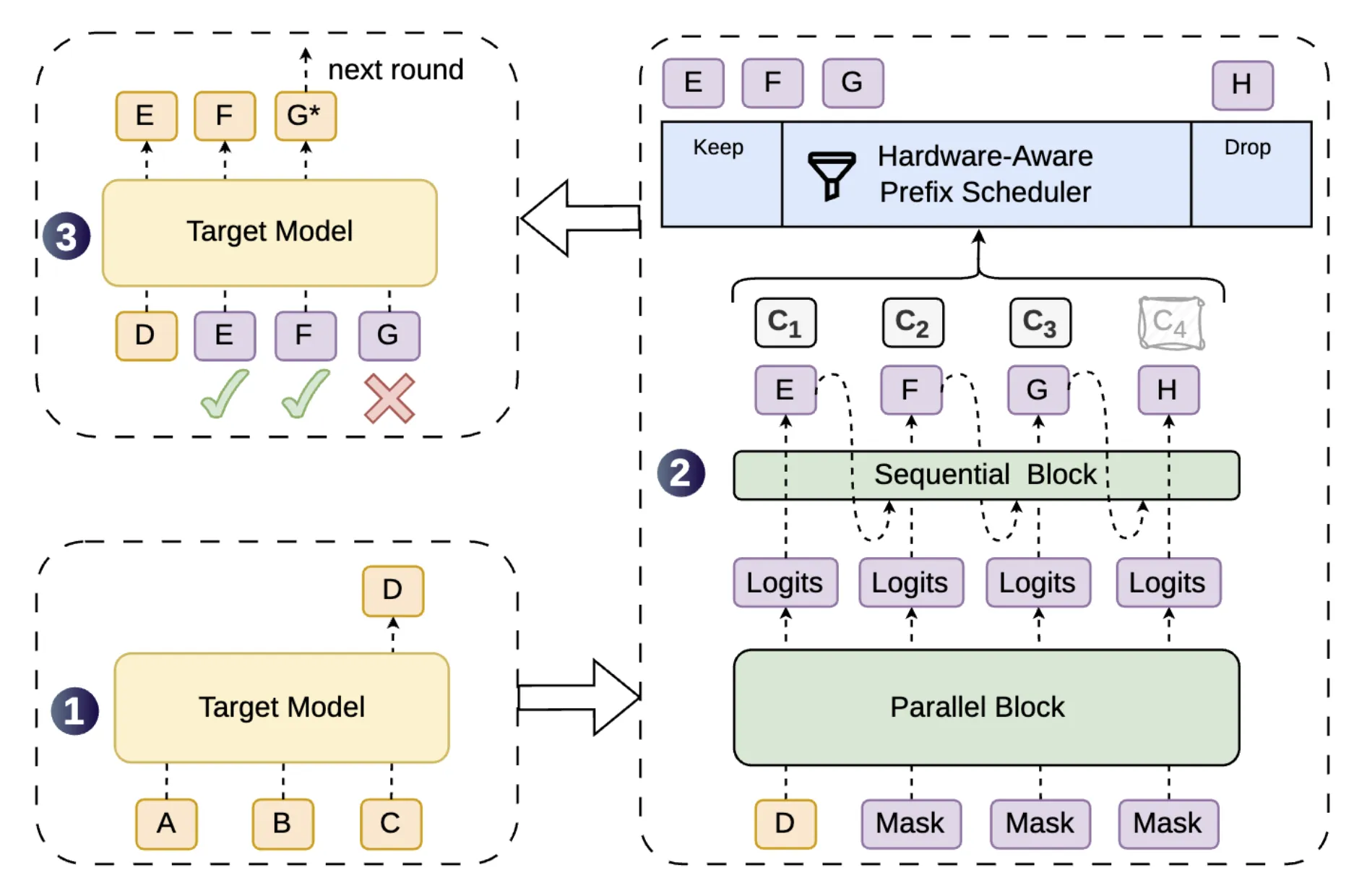
一、 核心架构与生成机制对比
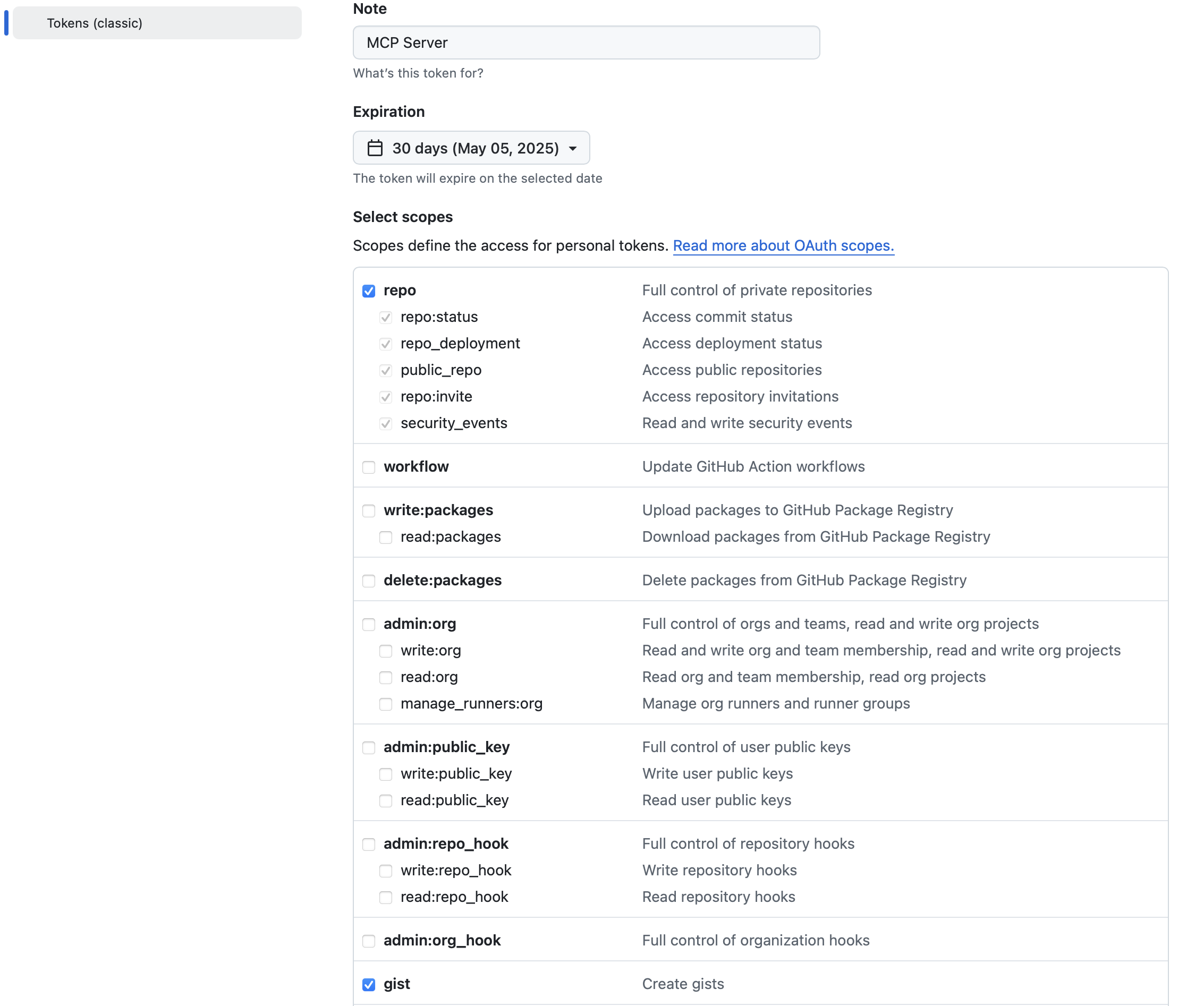
三种方案的本质区别在于“生成速度(并行度)”与“草稿质量(接受率)”的权衡。以下图表直观展示了它们在计算模式上的根本差异: