DeepSeek-V4 全面解读:架构设计与 inference/encoding 源码深度解析
DeepSeek-V4

简介
我们在此发布 DeepSeek-V4 系列的预览版本,包括两个强大的混合专家(MoE)语言模型 —— 总参数量 1.6T(激活 49B)的 DeepSeek-V4-Pro,以及总参数量 284B(激活 13B)的 DeepSeek-V4-Flash,两者均支持长达 一百万 token 的上下文。
DeepSeek-V4 系列在架构与优化方面引入了多项关键升级:
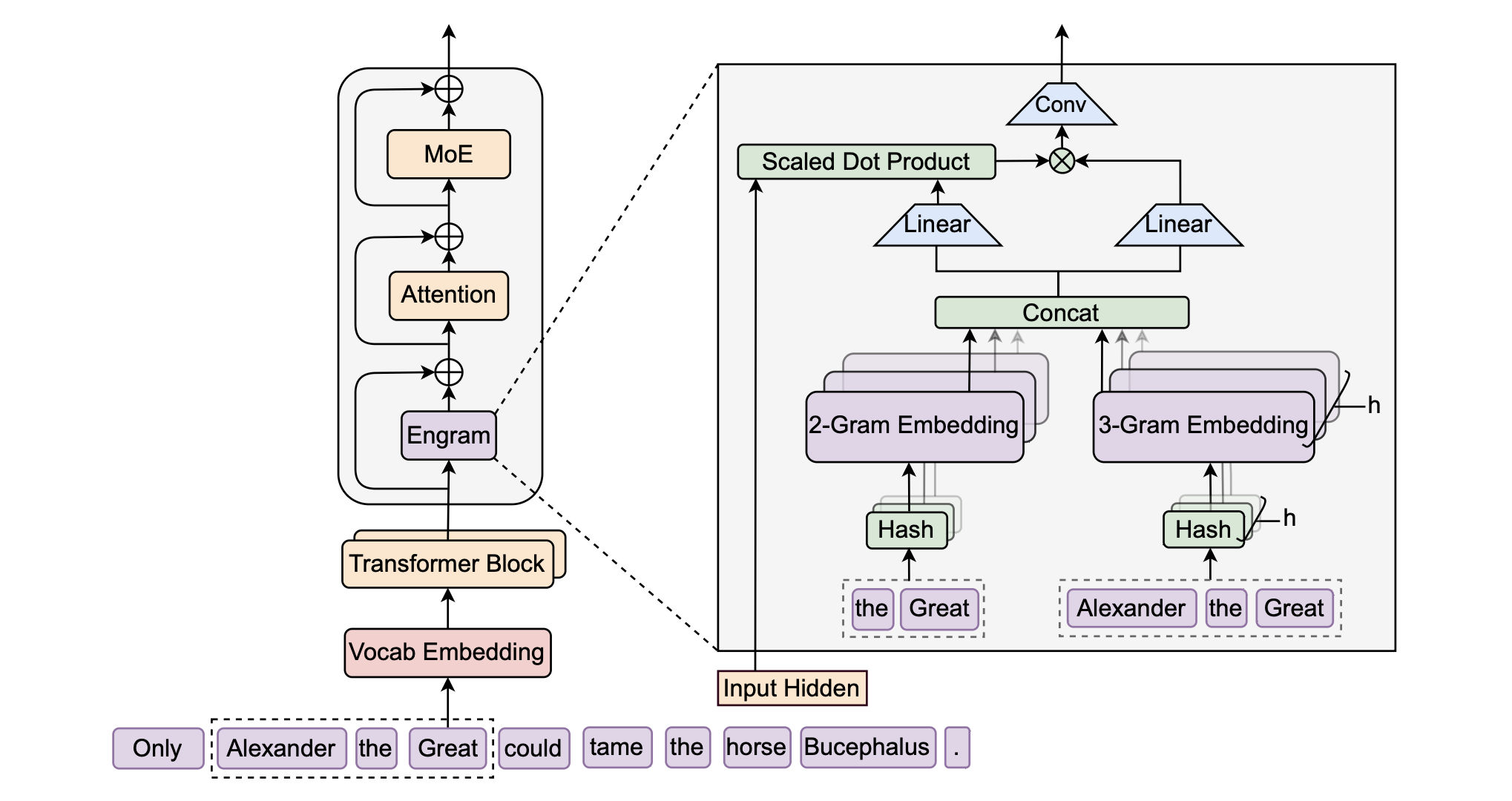
- 混合注意力架构:我们设计了一种结合压缩稀疏注意力(CSA)与重度压缩注意力(HCA)的混合注意力机制,大幅提升长上下文处理效率。在 1M token 上下文设定下,DeepSeek-V4-Pro 的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV 缓存仅占其 10%。
- 流形约束超连接(mHC):我们引入 mHC 来增强传统的残差连接,在保留模型表达能力的同时,提升信号跨层传播的稳定性。
- Muon 优化器:我们采用 Muon 优化器以实现更快的收敛速度和更高的训练稳定性。
两款模型均在大于 32T 的多样化高质量 token 上进行了预训练,并随后执行了全面的后训练流程。后训练采用两阶段范式:首先独立培养领域专属专家(通过 SFT 与基于 GRPO 的强化学习),随后通过 on-policy 蒸馏将不同领域的专长整合至单一模型中。
DeepSeek-V4-Pro-Max 作