评估模型投资分析能力:京东健康案例
优先使用:豆包 和 Grok
提示词
根据历年财报进行投资分析
基于京东健康上市后历年的财报,从价值投资的角度进行分析。
文件:
- 京东健康 2020 年度报告.pdf
- 京东健康 2021 年度报告.pdf
- 京东健康 2022 年度报告.pdf
- 京东健康 2023 年度报告.pdf
- 京东健康 2024 年度报告.pdf
- 京东健康 2025 中期报告.pdf
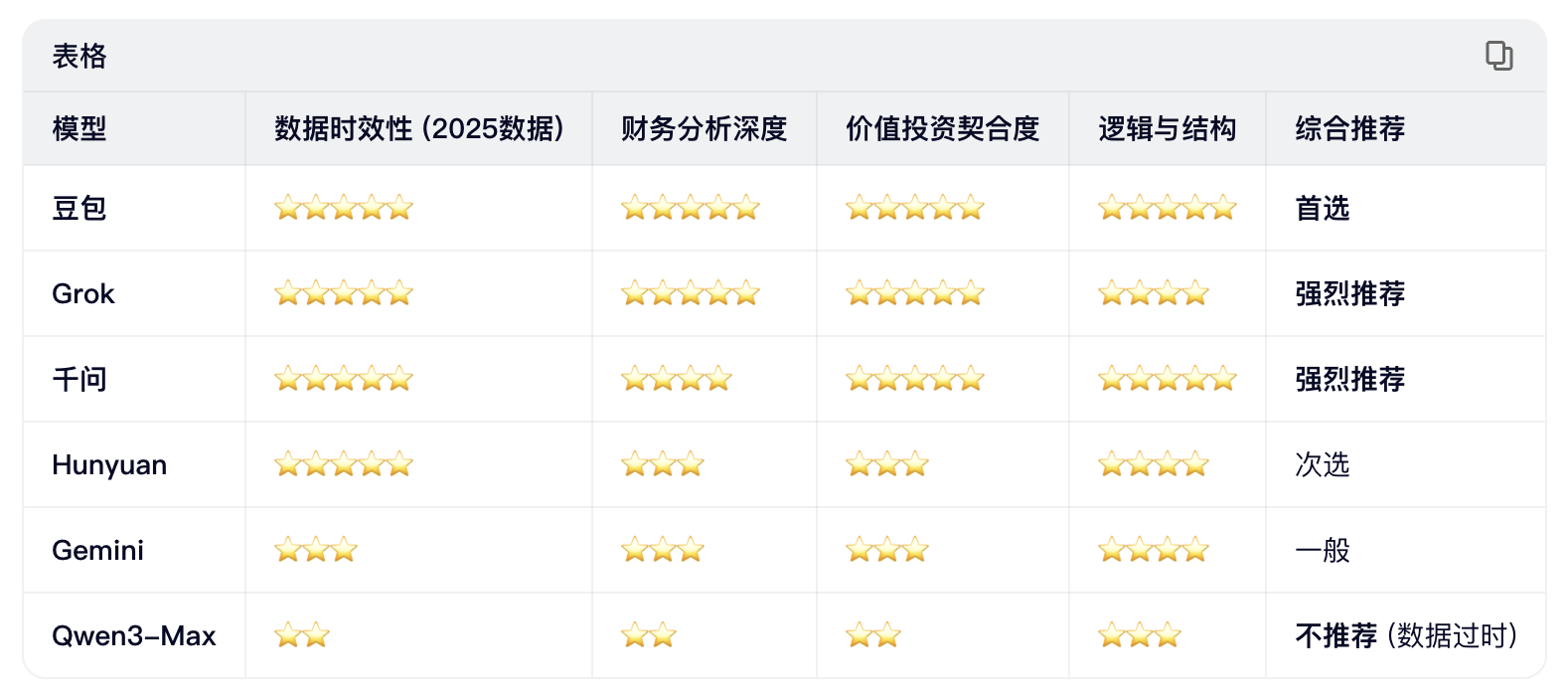
评估各模型投资分析能力
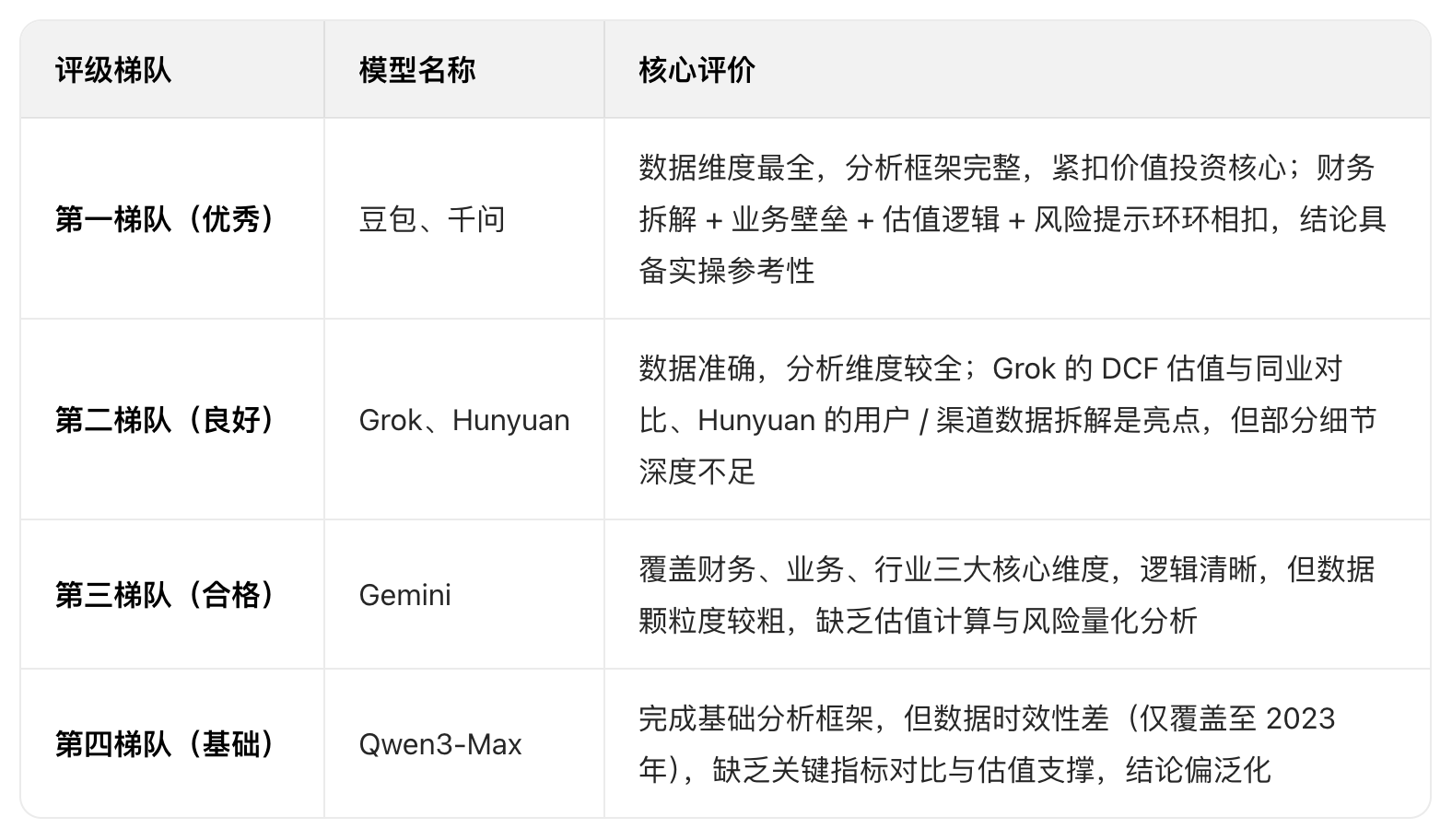
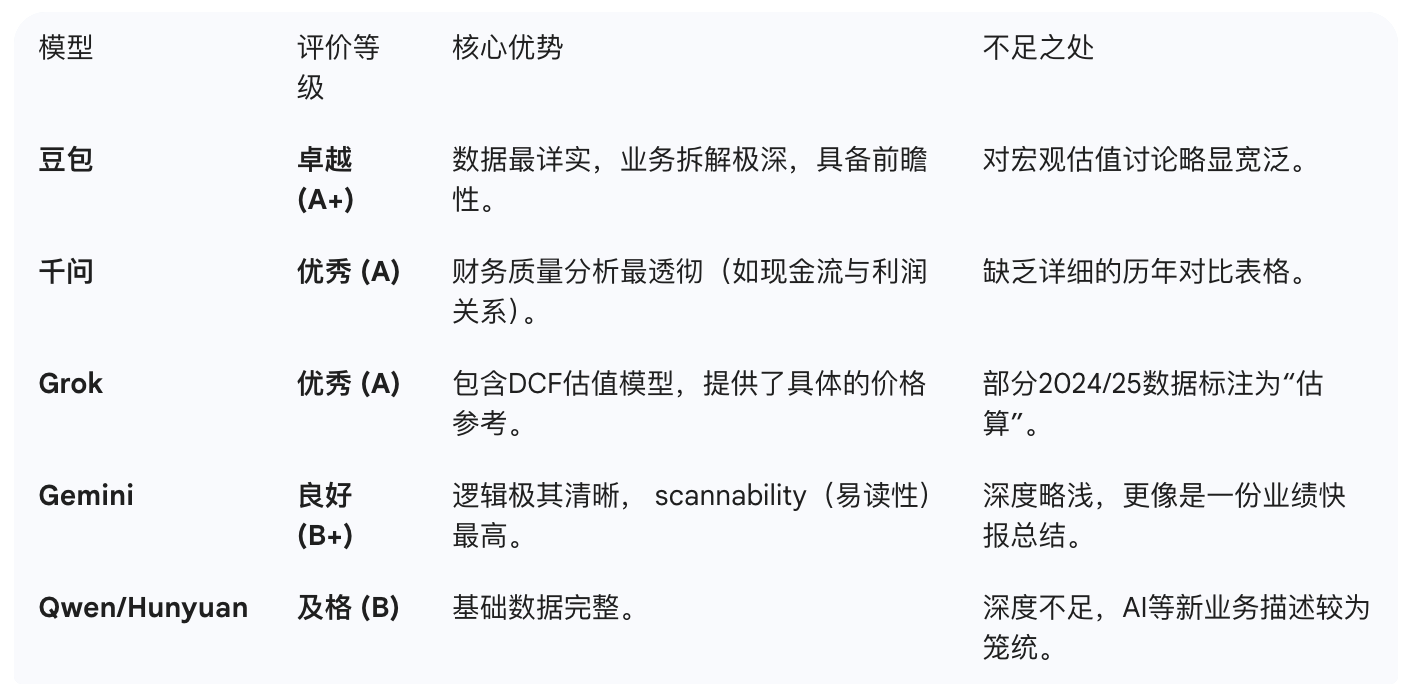
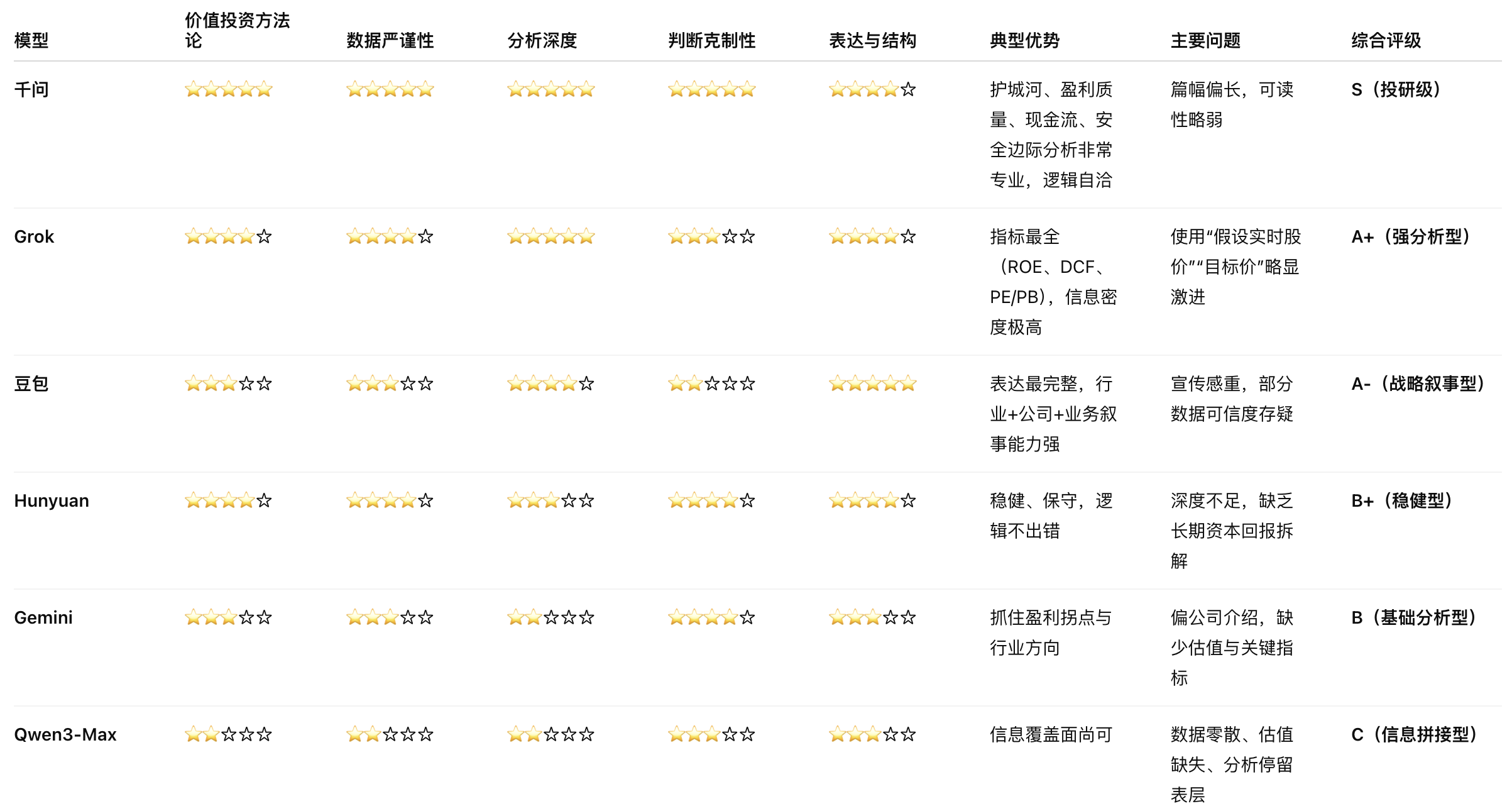
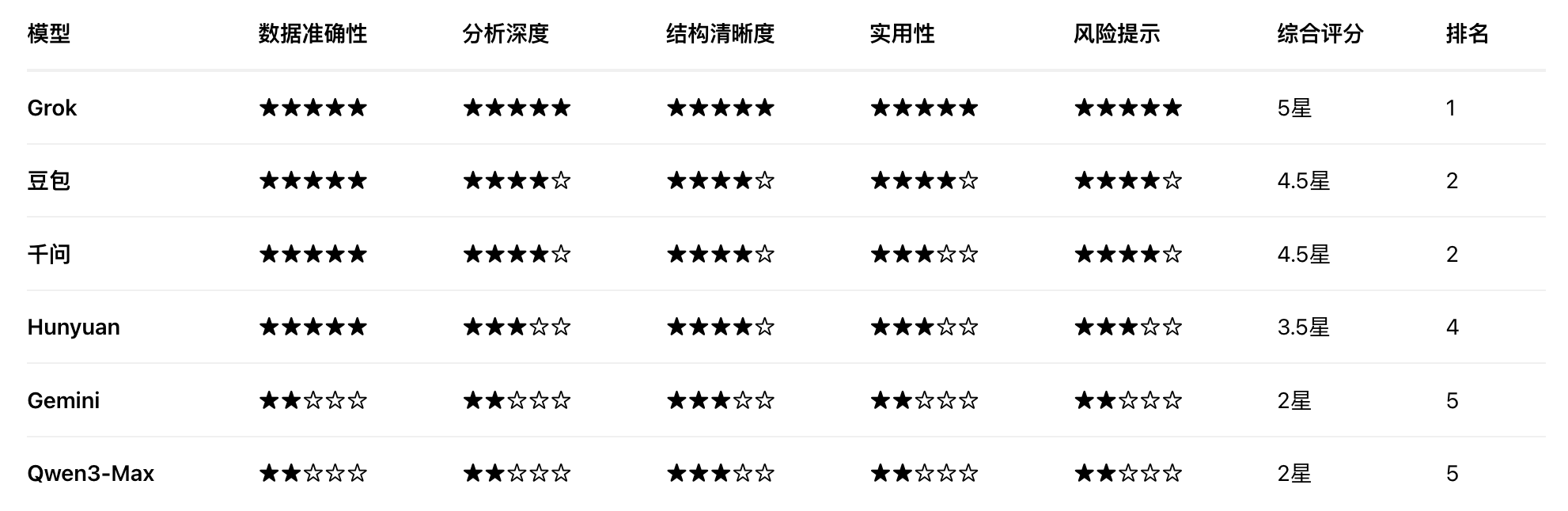
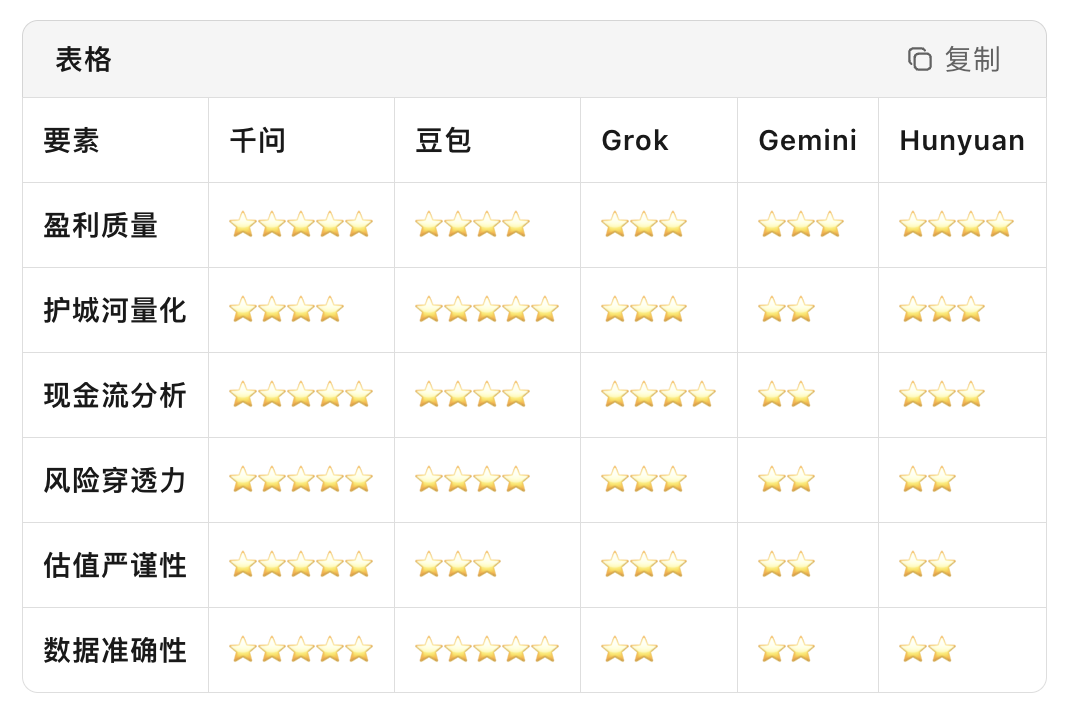
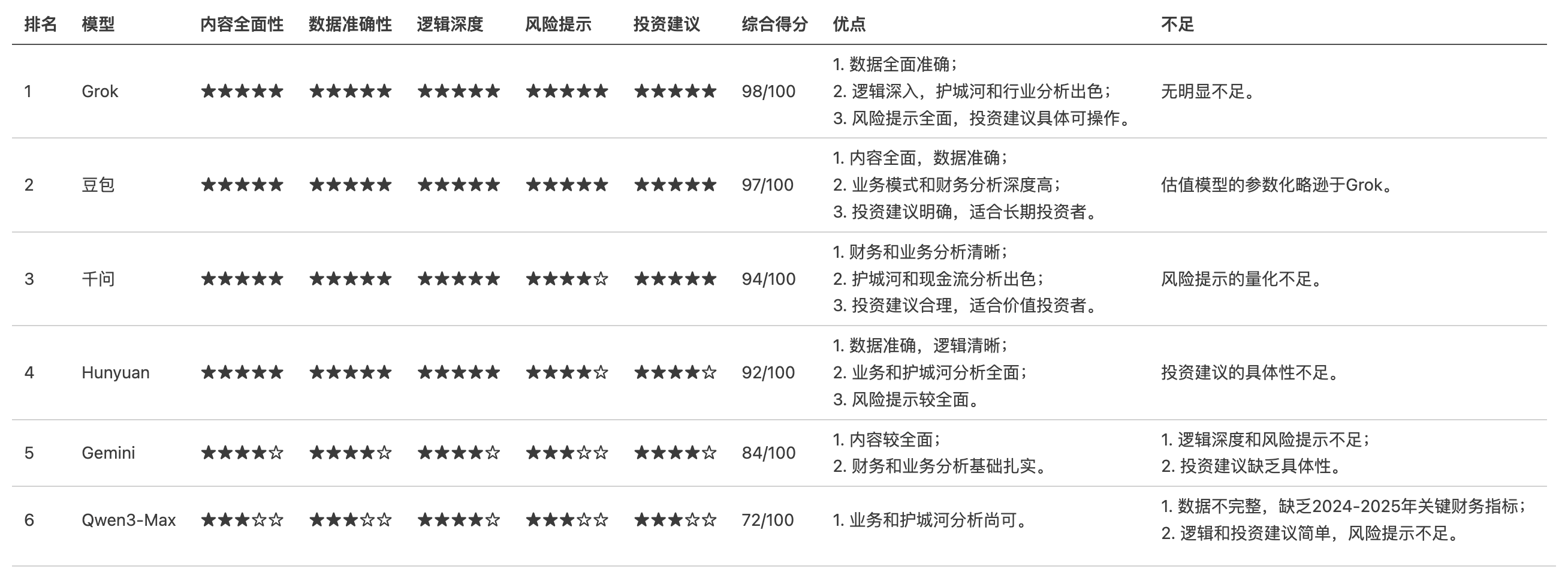
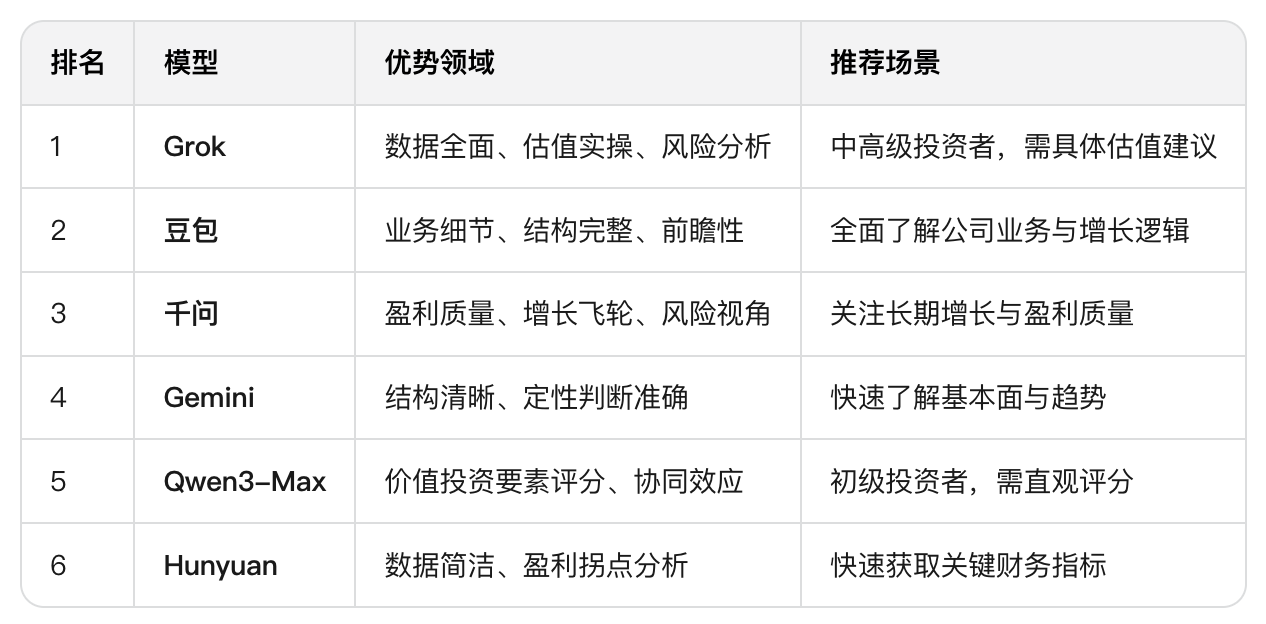
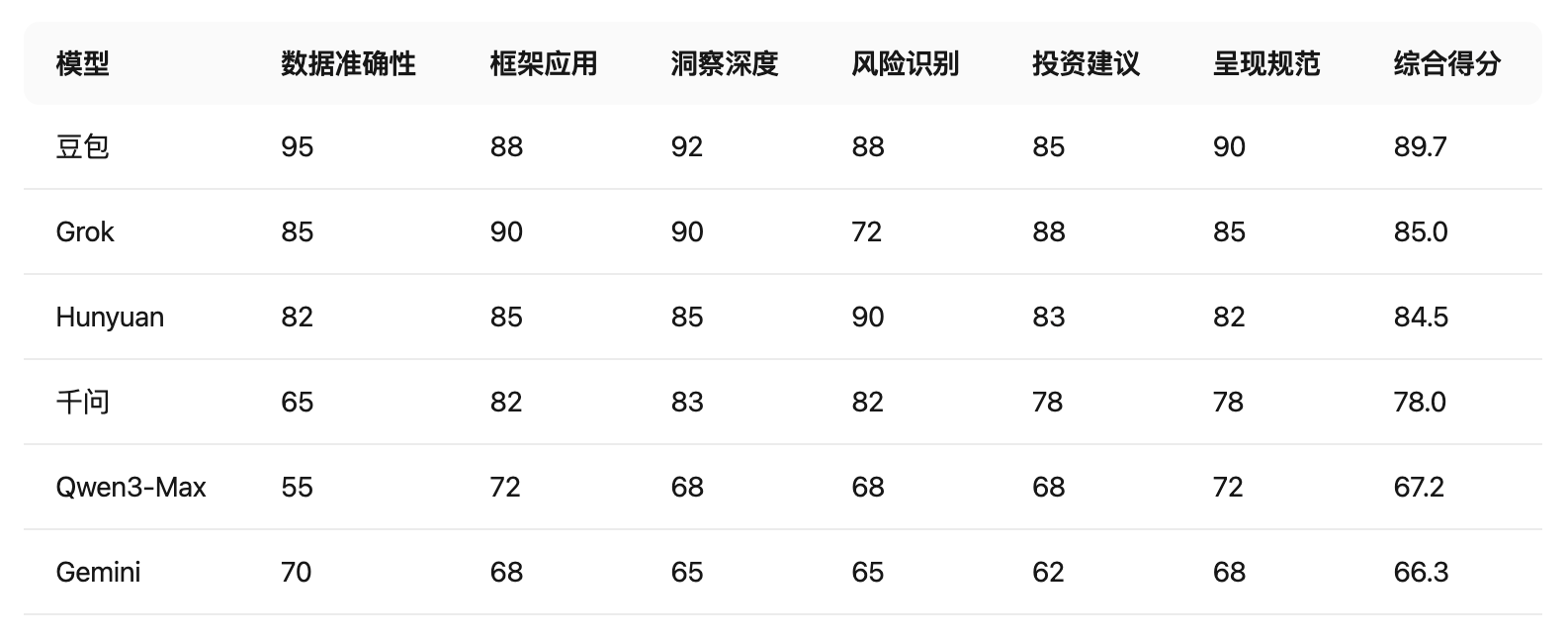
下面是我使用提示词:“基于京东健康上市后历年的财报,从价值投资的角度进行分析。”对多个大语言模型进行的分析结果。你作为一个评判专家,请对比各模型的分析内容,给出你的综合评价。
评判结果

Doubao
Grok 4.1

Gemini3
ChatGPT
DeepSeek-Think
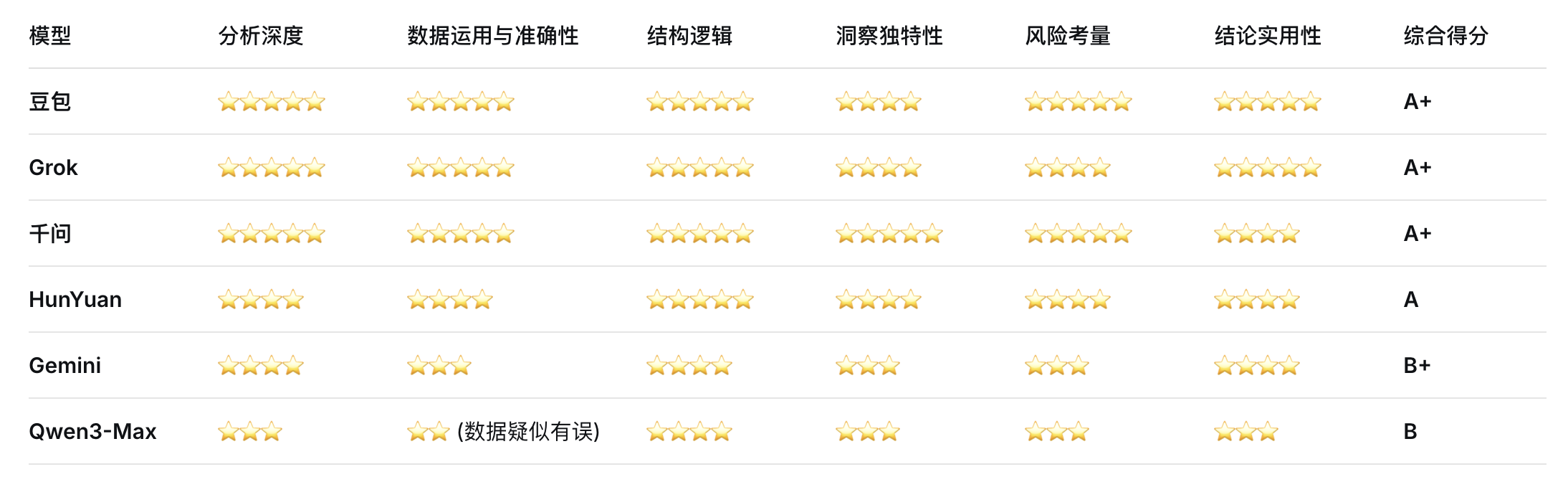
混元
Kimi-K2-Think
LeChat
LongCat
MiniMax M2.1
Qwen3-千问
综合AI助手,全面回答工作、学习、生活各类问题
Qwen3-Max
千问系列中最强大的语言模型

各模型投资分析结果
Gemini