DeepSeek-Coder 论文解读
论文
- DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- LLaMA: Open and Efficient Foundation Language Models
- Llama 2: Open Foundation and Fine-Tuned Chat Models
模型的性能
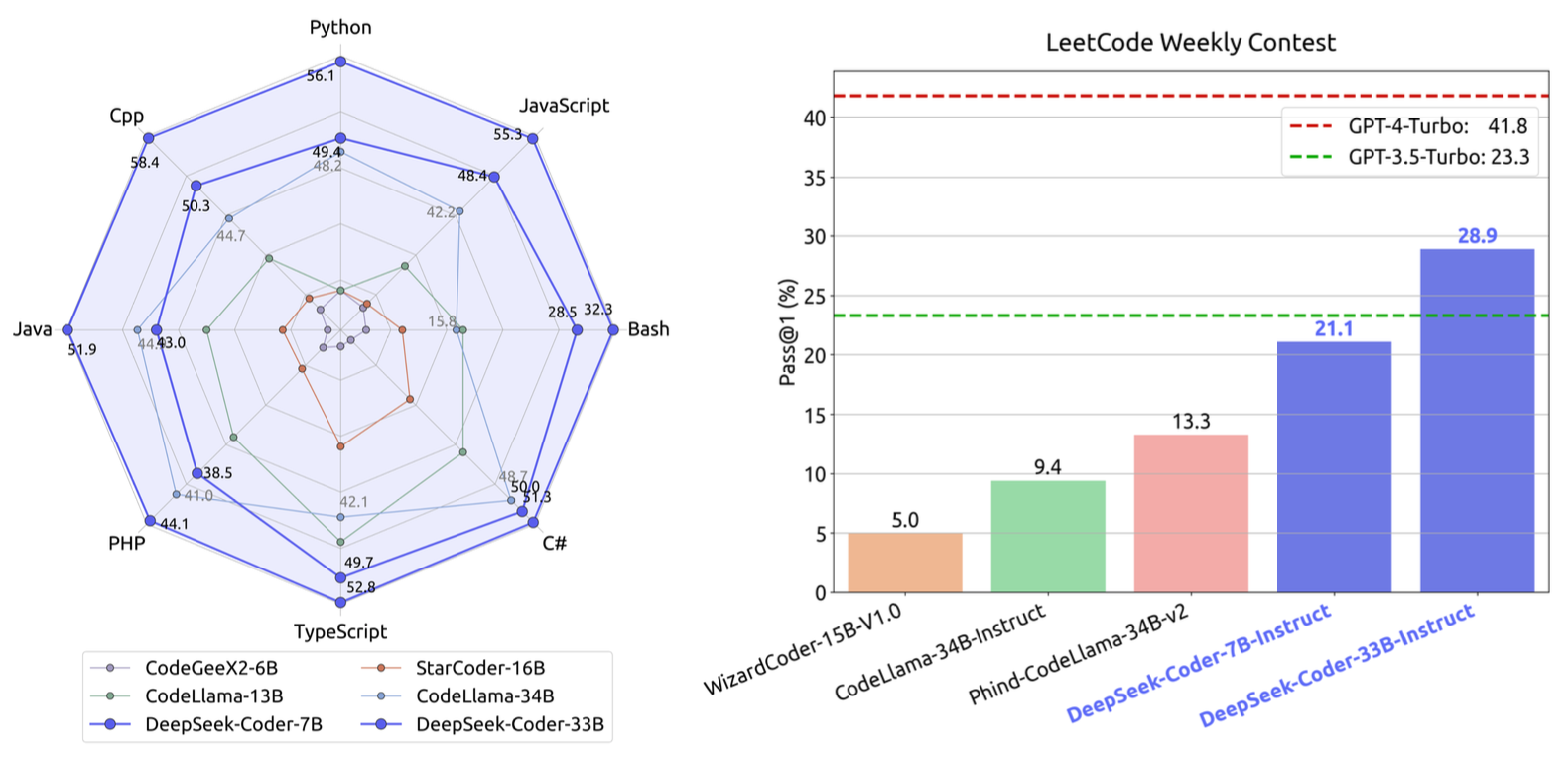
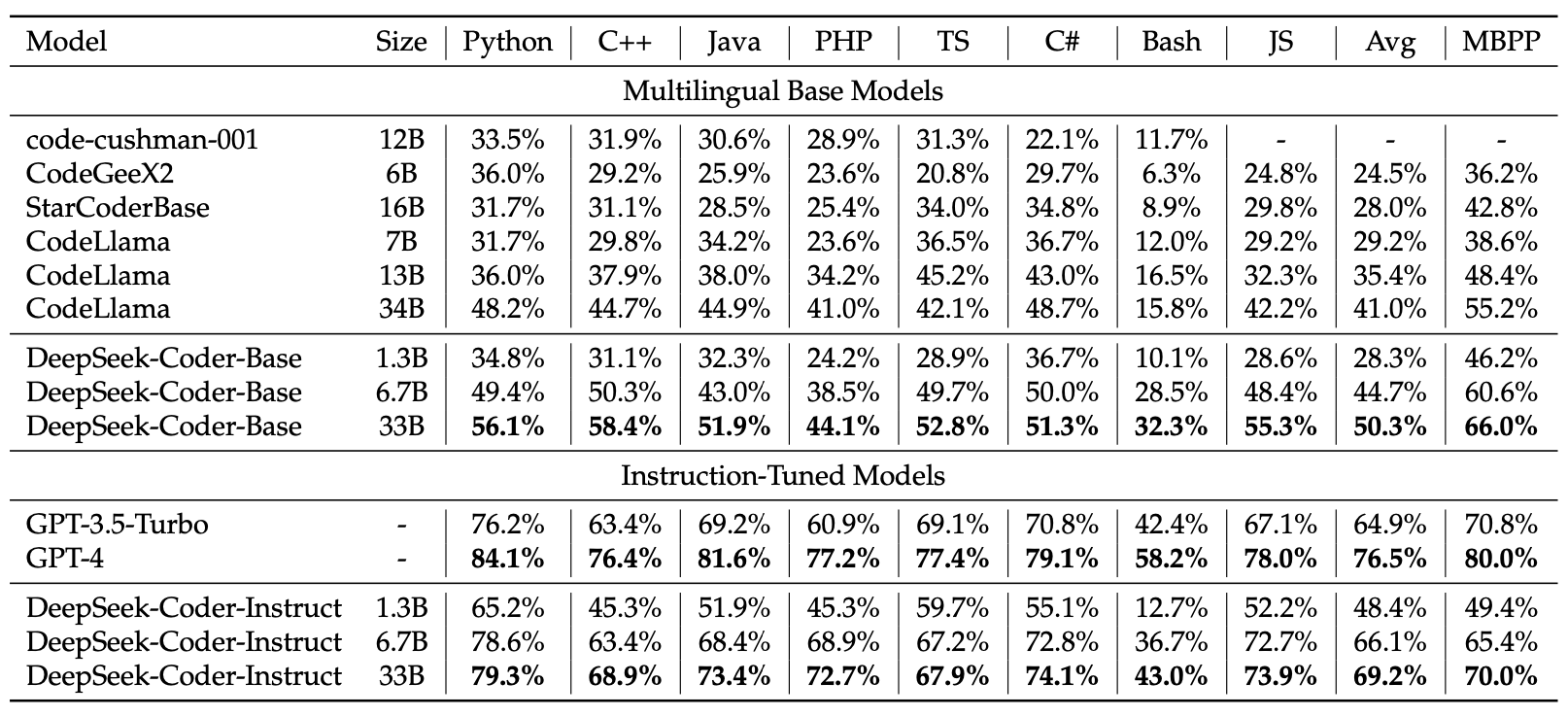
多语言基准性能
训练数据集
数据来源:2023年2月之前在GitHub上创建的公共仓库。
数据集创建过程
- GitHub数据抓取
- 规则过滤
- 依存分析
- 仓库级重复数据删除
- 质量筛选
规则过滤 过滤掉平均行长度超过100个字符或最大行长度超过1000个字符的文件。 移除了字母字符少于25%的文件。 除了XSLT编程语言外,过滤掉在前100个字符中出现字符串 "<?xml_version=" 的文件。 对于HTML文件,考虑可见文本与HTML代码的比例,保留可见文本占代码至少20%且不少于100个字符的文件。 对于包含更多数据的JSON和YAML文件,只保留字符计数在50到5000个字符范围内的文件。