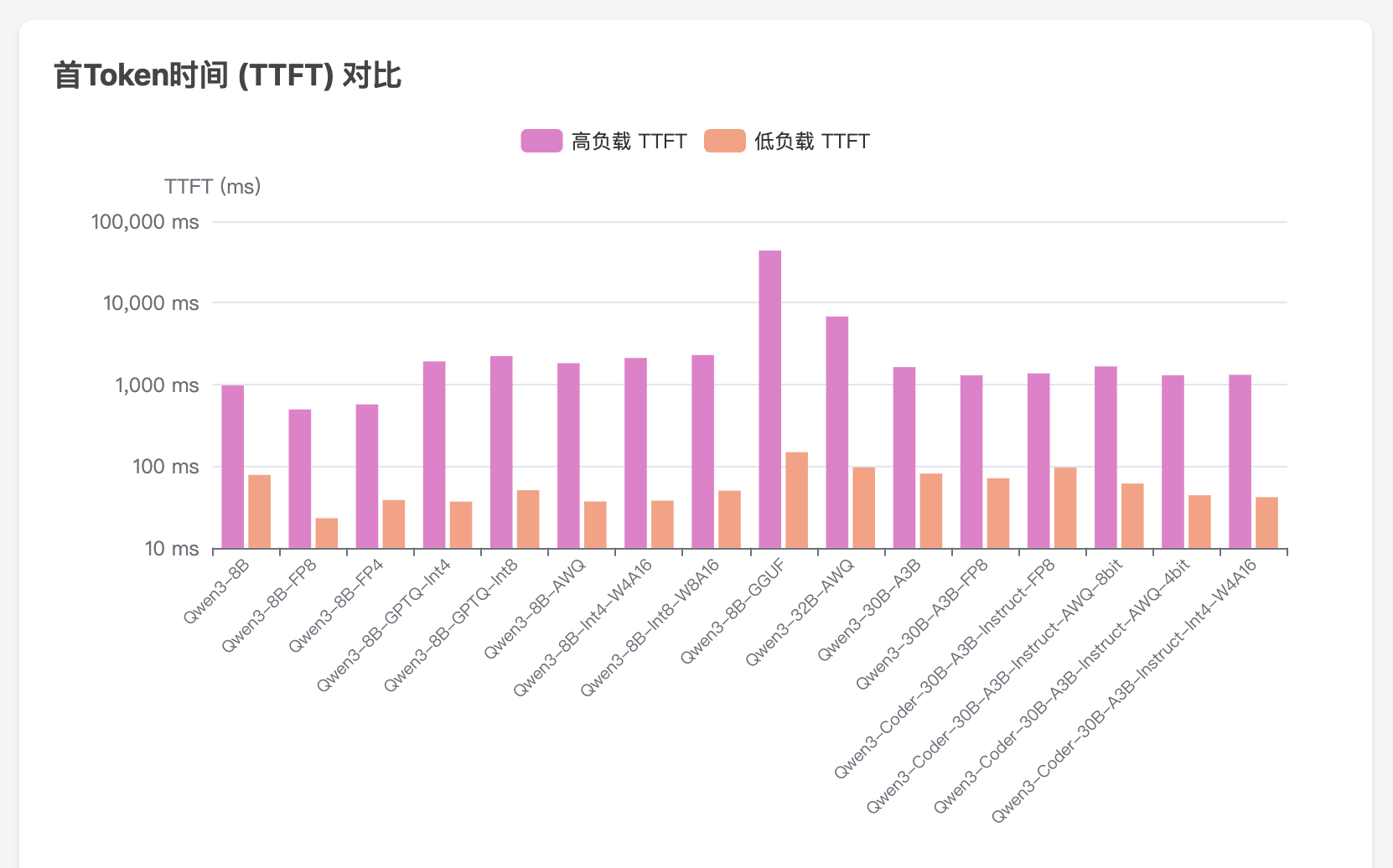
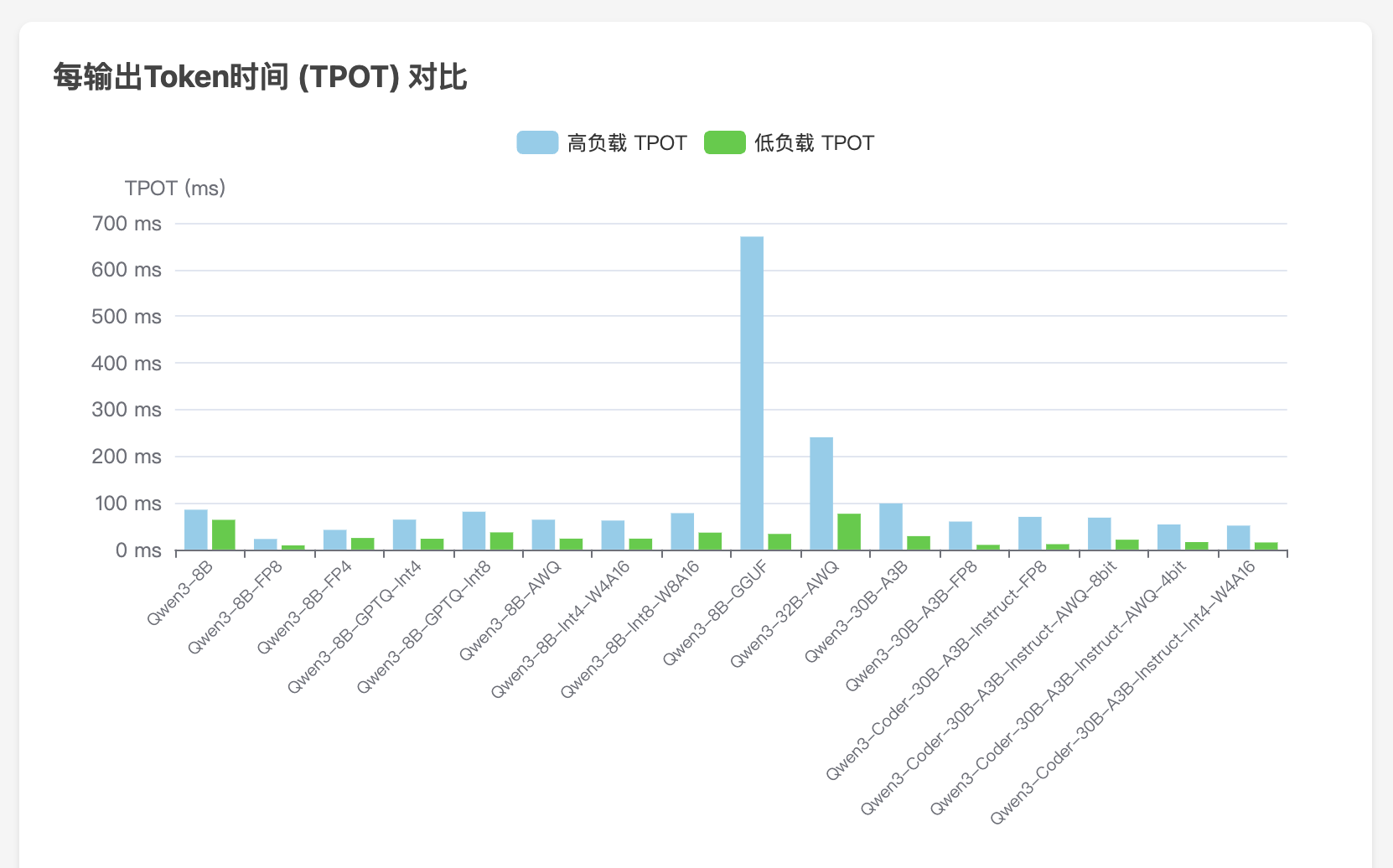
llama.cpp 实战指南(Jetson Thor 平台):从源码编译到 GGUF 模型部署与性能基准测试
本文将介绍如何在 Jetson Thor 平台上编译、部署和测试 llama.cpp 项目中的 GGUF 格式的大模型。
克隆 llama.cpp
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
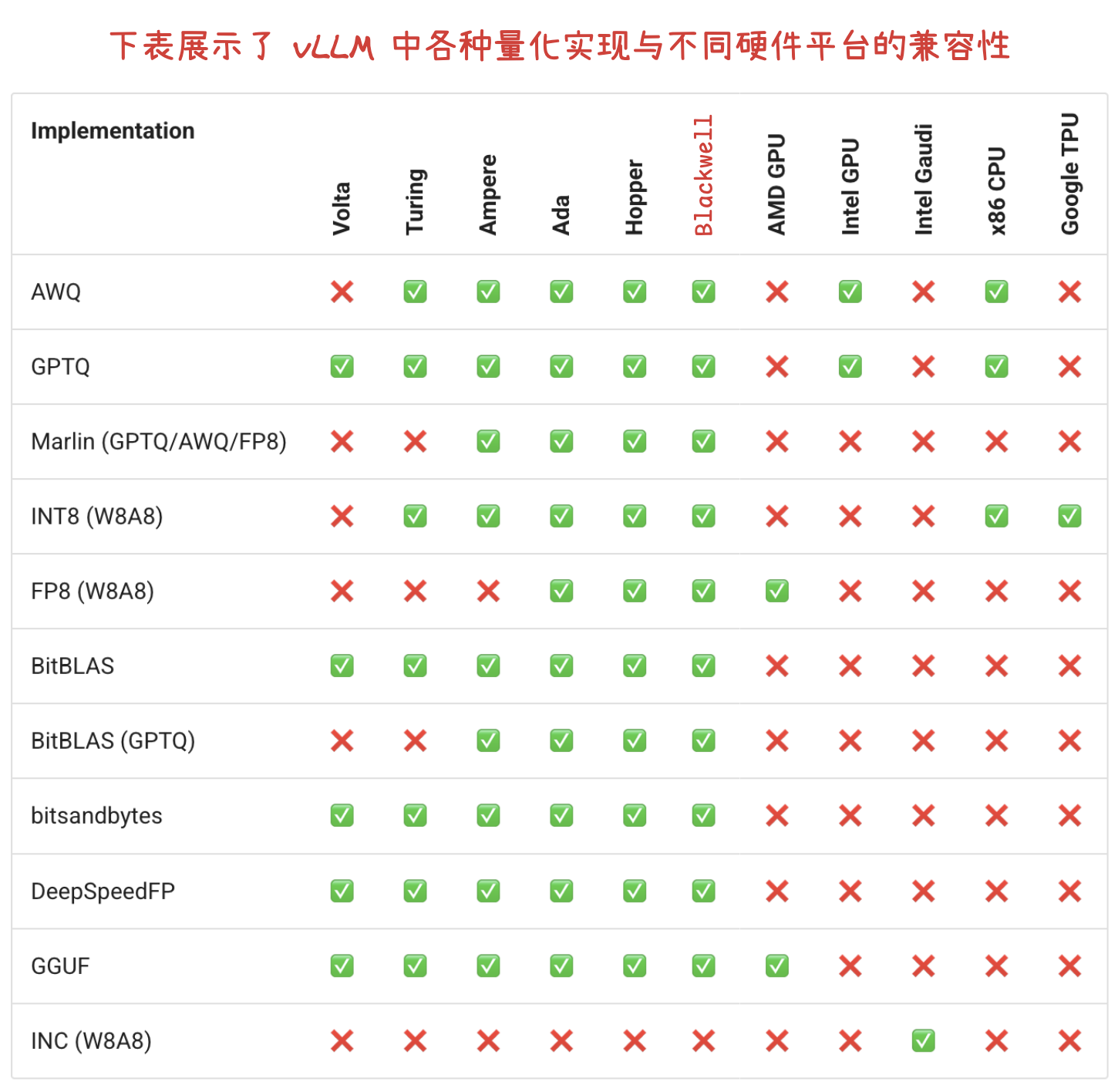
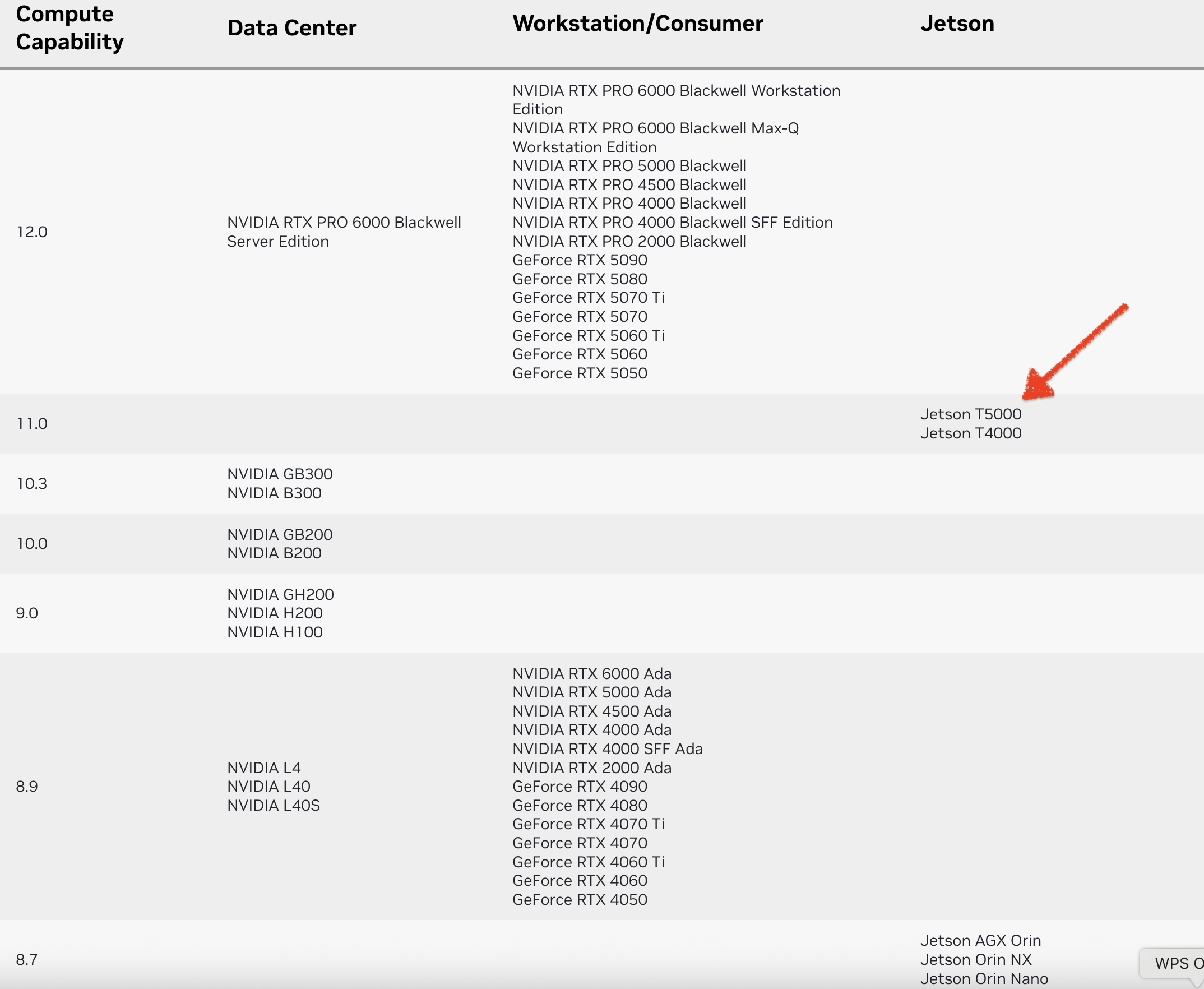
CUDA GPU Compute Capability(计算能力)
计算能力(CC)定义了每种 NVIDIA GPU 架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。
编译
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="110"
cmake --build build --config Release -j $(nproc)
模型部署
运行 llama-server