搭建 Reachy Mini 语音对话智能体
部署 Reachy Mini 语音智能体
安装 reachy_mini_conversation_app 到 Reachy Mini
在 MacBook 上运行 Reachy Mini Control,单击 Start 按钮。
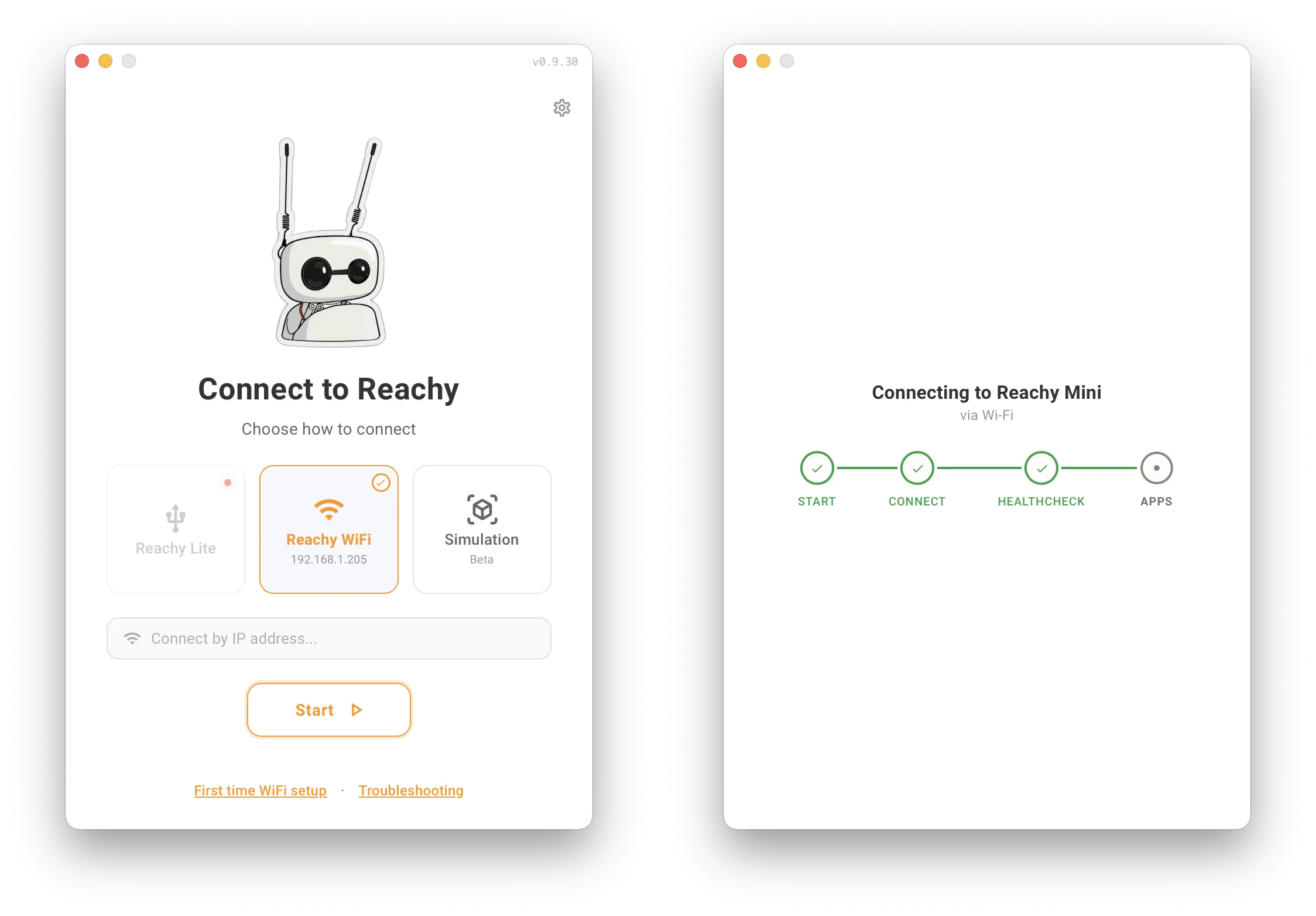
在 Applications 页面,单击 Discover apps 后,搜索 reachy_mini_conversation_app。

单击 Install 按钮安装 reachy_mini_conversation_app。
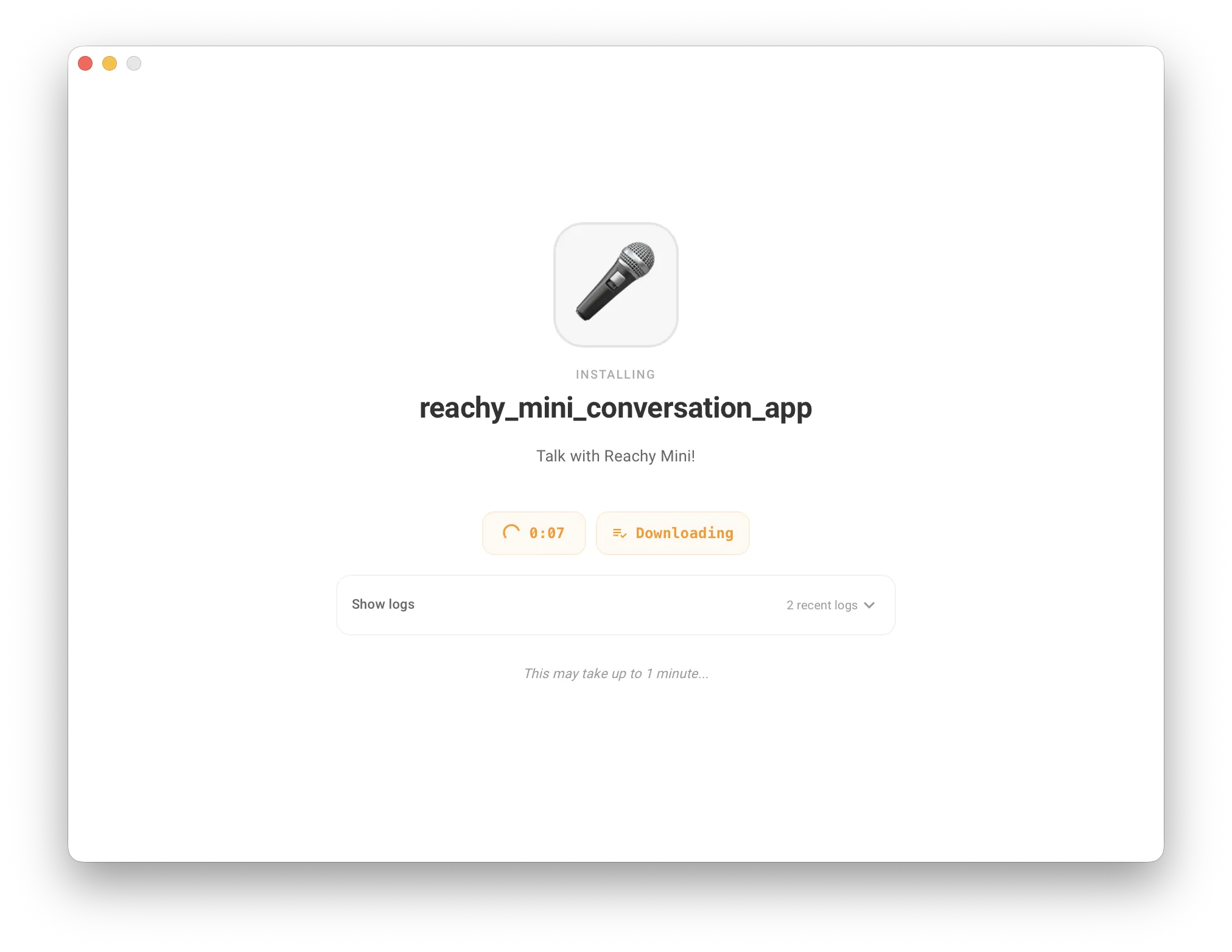
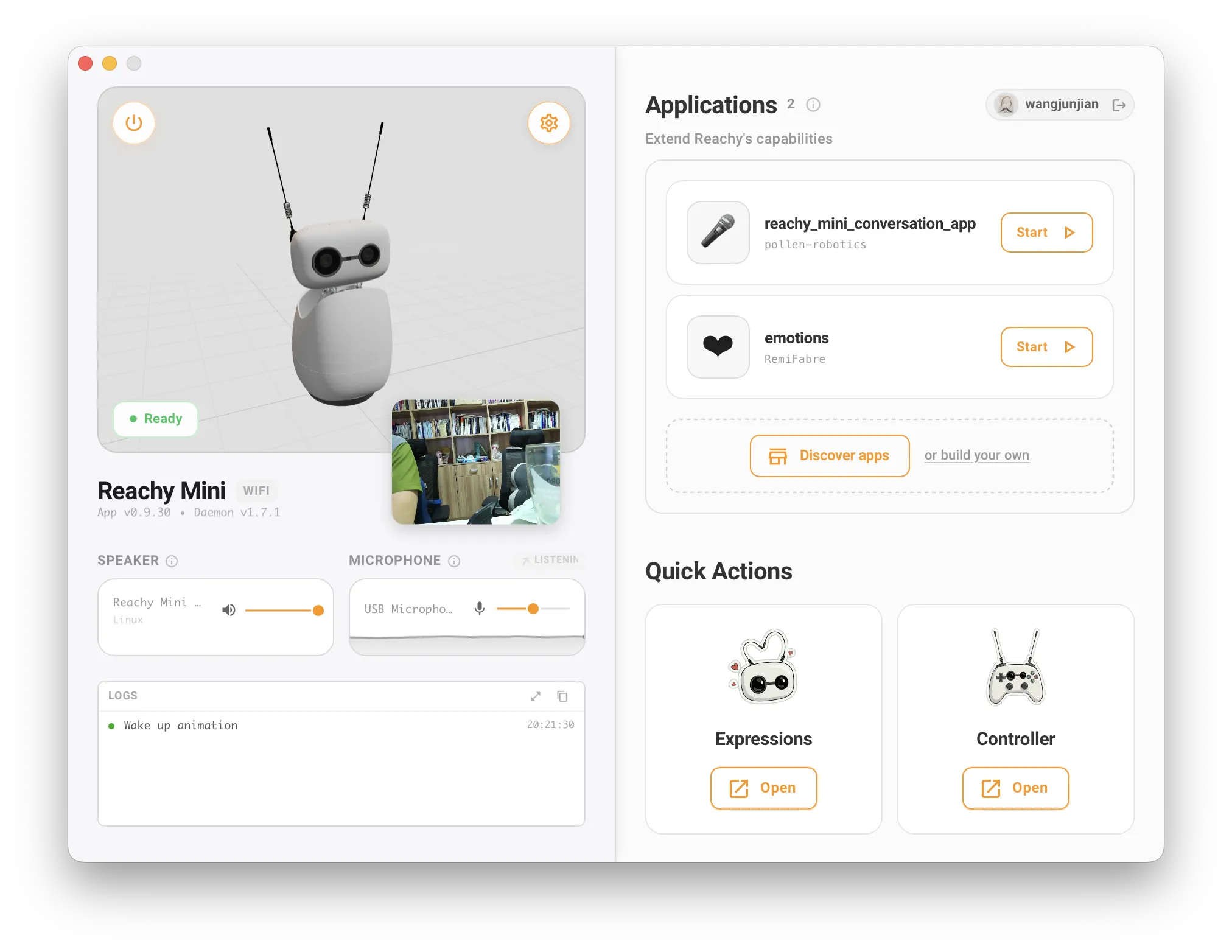
MacBook 上实时模式运行 Speech To Speech
安装 Speech To Speech
uv venv --python 3.12
source .venv/bin/activate
uv pip install speech-to-speech
uv pip install "speech-to-speech[faster-whisper]"
中文