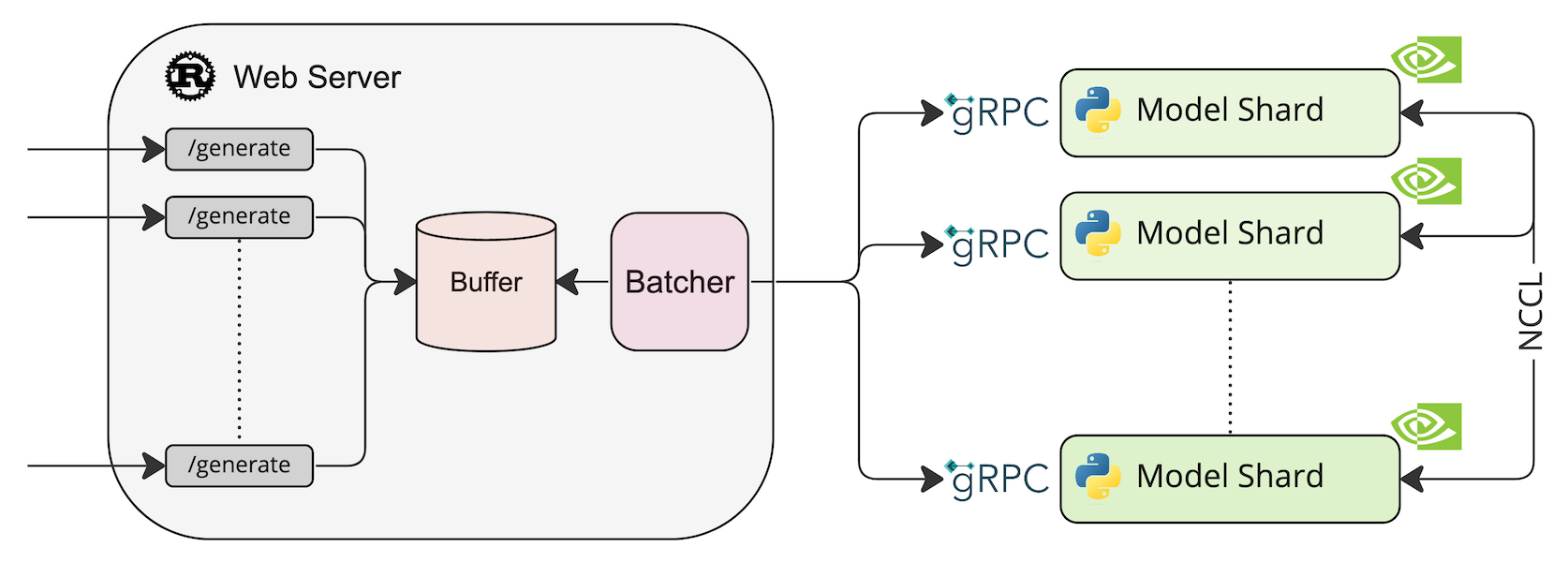
部署 LLM 多 LoRA 适配器的推理服务
Text Generation Inference
conda create -n text-generation-inference python=3.9
conda activate text-generation-inference
git clone https://github.com/huggingface/text-generation-inference.git && cd text-generation-inference
BUILD_EXTENSIONS=True make install
vLLM
conda create -n vllm python=3.10 -y
conda activate vllm
pip install vllm
cd ~/HuggingFace/mistralai/Mistral-7B-v0.1
git clone https://huggingface.co/predibase/magicoder adapters/magicoder
- vllm - Using LoRA adapters
- mistralai/Mistral-7B-v0.1
- predibase/magicoder
- 利用多Lora节省大模型部署成本|得物技术
- 使用vLLM在一个基座模型上部署多个lora适配器
vllm serve `pwd` \
--enable-lora \
--lora-modules magicoder=`pwd`/adapters/magicoder