3 篇文章带有标签 “flash-attention”


使用 FastChat 在 CUDA 上部署 LLM
安装 FastChat & vLLM
安装 FastChat
pip install "fschat[model_worker,webui]"
Turing GPU T4不支持 FlashAttention 2,需要使用 FlashAttention 1.x 。Turing GPU T4不支持bf16,需要使用fp16。
安装 vLLM
pip install vllm -i https://mirrors.aliyun.com/pypi/simple/
升级 FastChat & vLLM
git pull
pip install -e ".[model_worker,webui]"
pip install -U vllm
部署 LLM
运行 Controller
python -m fastchat.serve.controller
运行 OpenAI API Server
python -m fastchat.serve.openai_api_server
运行 Model Worker Qwen-1_8B-Chat export CUDA_VISIBLE_DEVIC
Text Generation Inference
TGI 是一个用于部署和服务大型语言模型(LLM)的工具包。 TGI 为最流行的开源 LLM 提供高性能文本生成,包括 Llama、Falcon、StarCoder、BLOOM、GPT-NeoX 和 T5 。
- 张量并行性,可在多个 GPU 上进行更快的推理
- 批处理连续传入的请求,以增加总吞吐量
- 在最流行的架构上使用 [Flash Attention][Flash-Attention] 和 [Paged Attention][Paged-Attention] 优化 Transformers 代码进行推理
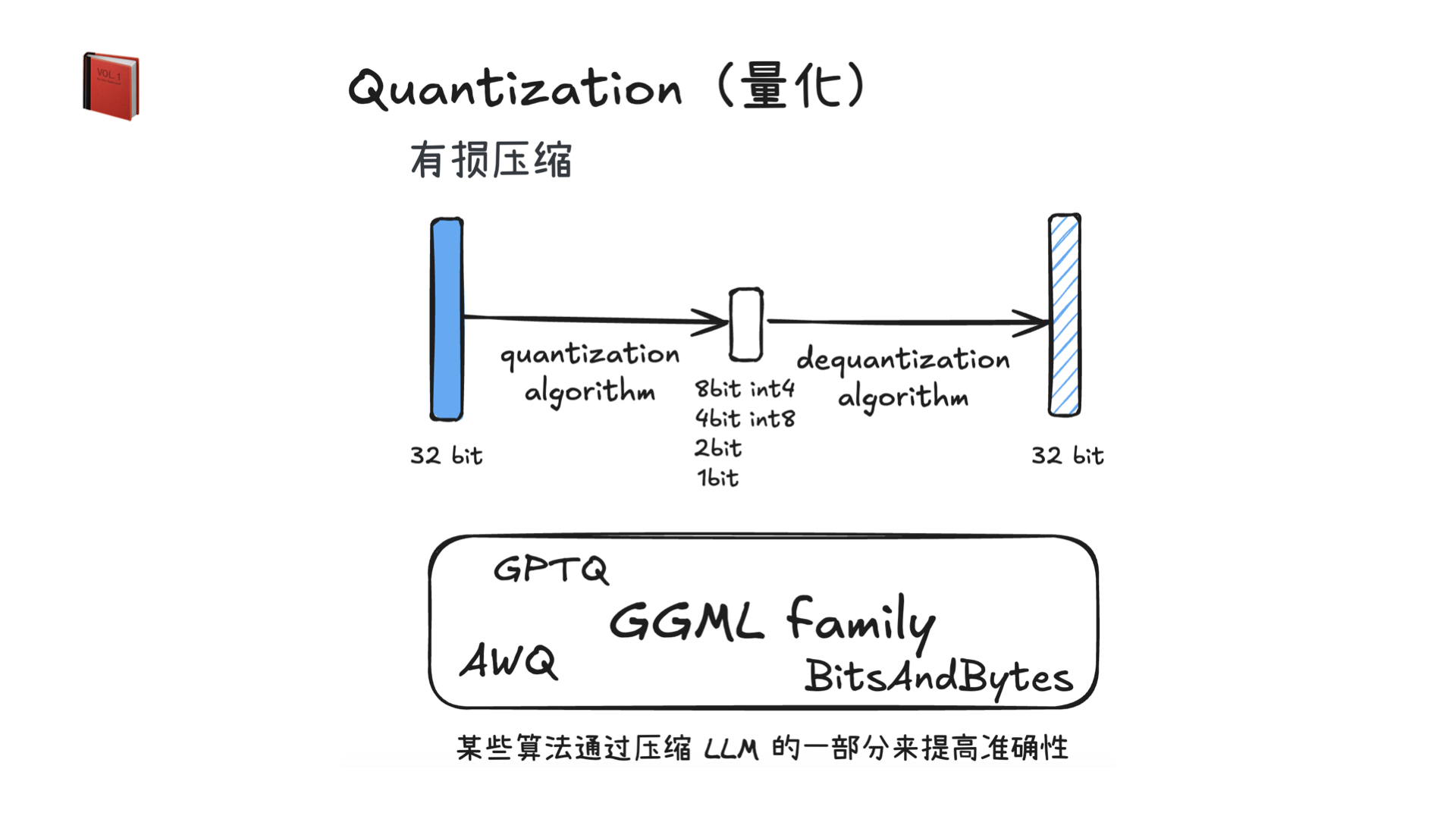
- 使用 [bitsandbytes][bitsandbytes] 和 [GPT-Q][GPT-Q] 进行量化
- [safetensors][safetensors] 权重加载
- 给模型输出加水印(Watermark)
- 微调支持:定制针对特定任务的微调模型来实现更高的准确性和性能
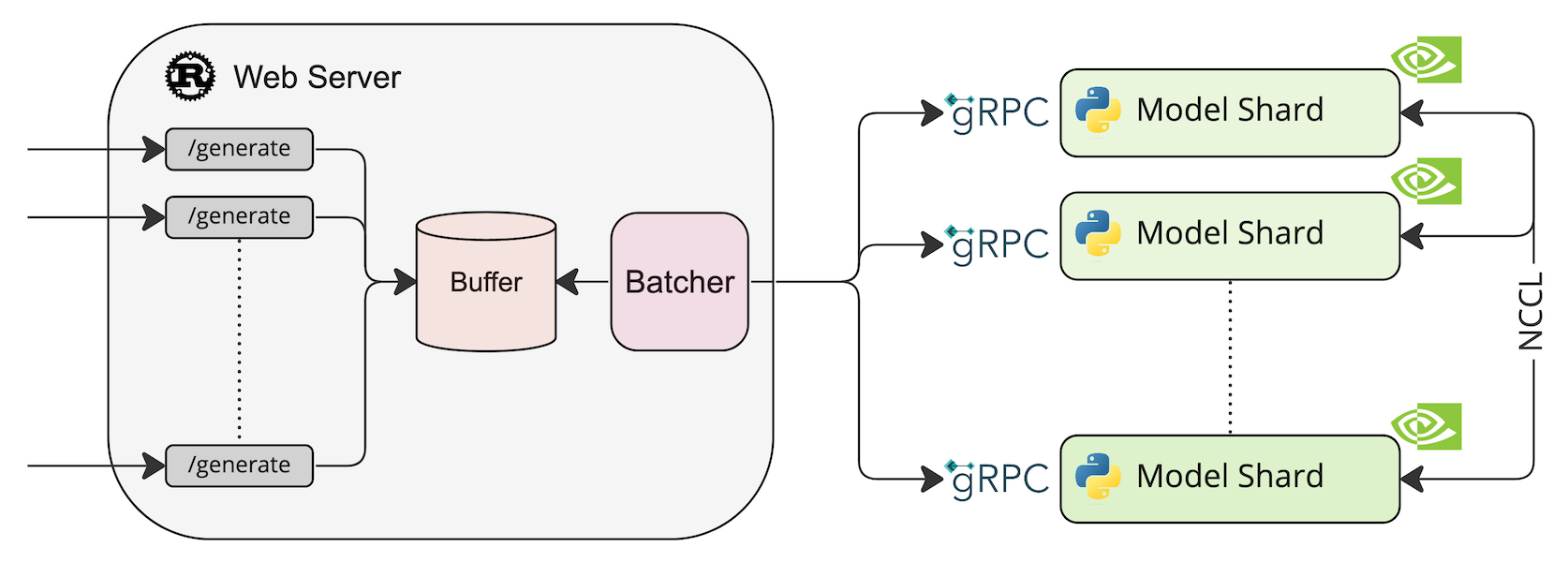
系统架构
部署模型 HuggingFaceH4/zephyr-7b-beta model=HuggingFaceH4/zephyr-7b-beta volume=$PWD/data # Avoid downloading weights every run docker run --