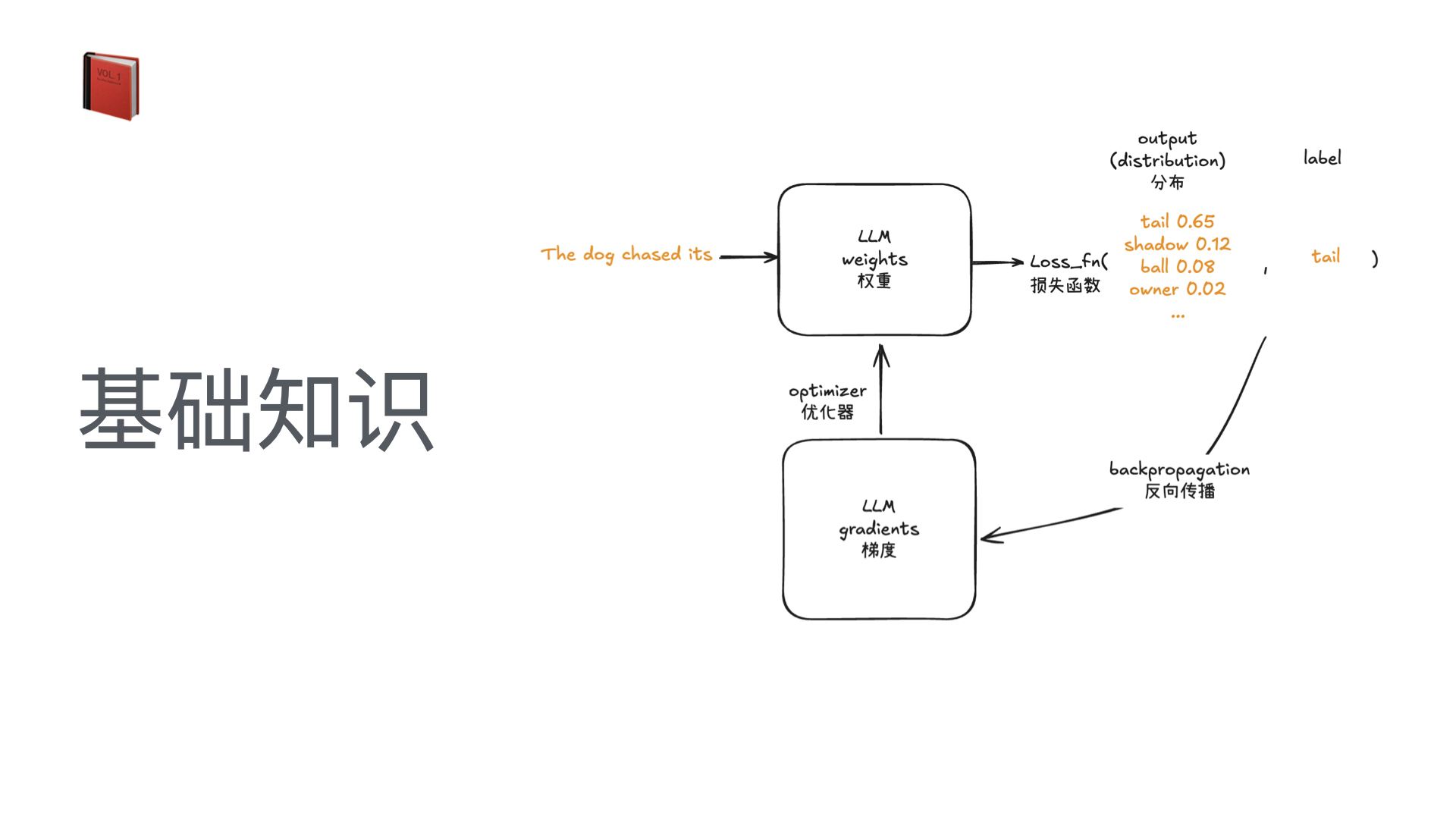
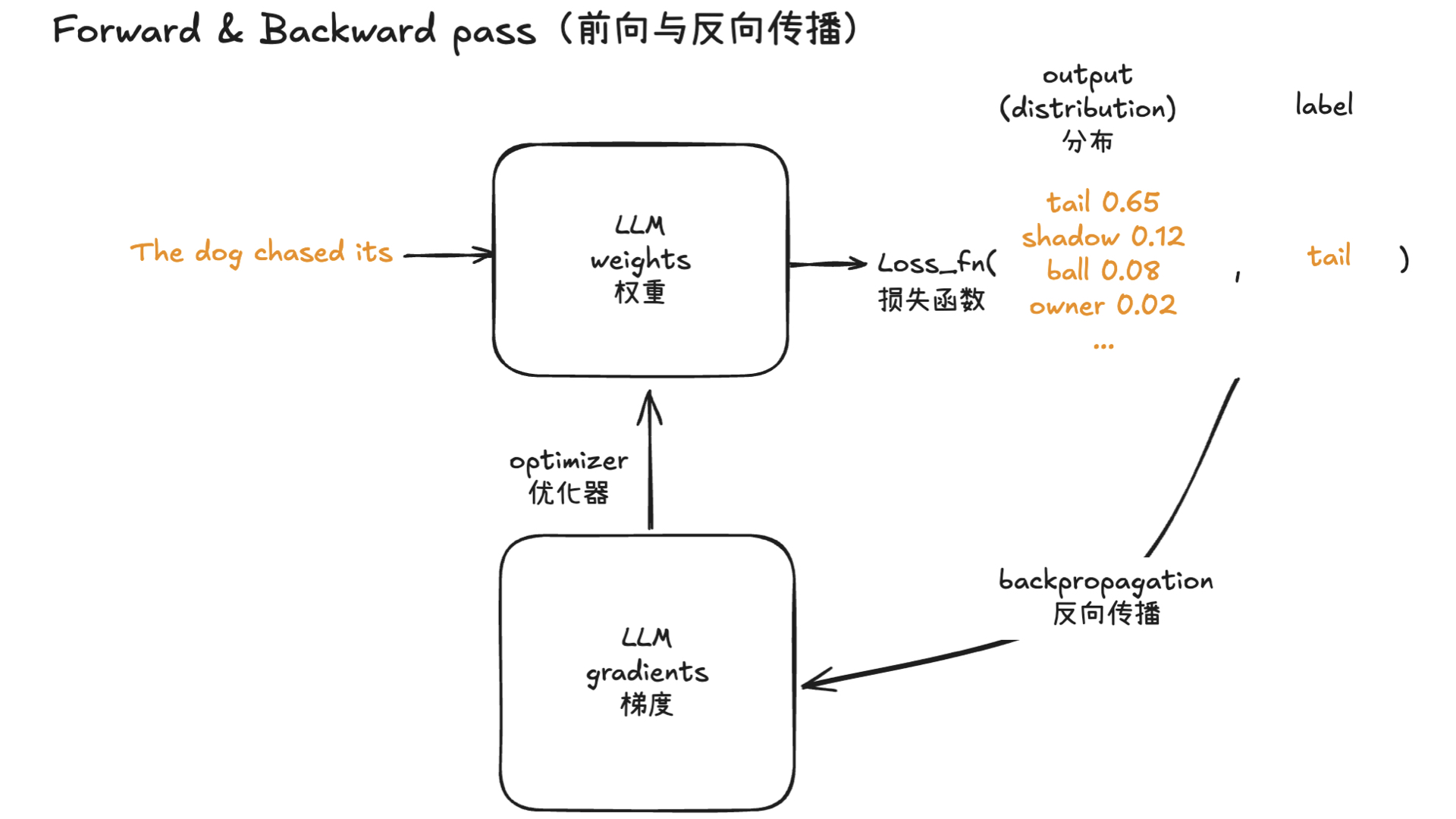
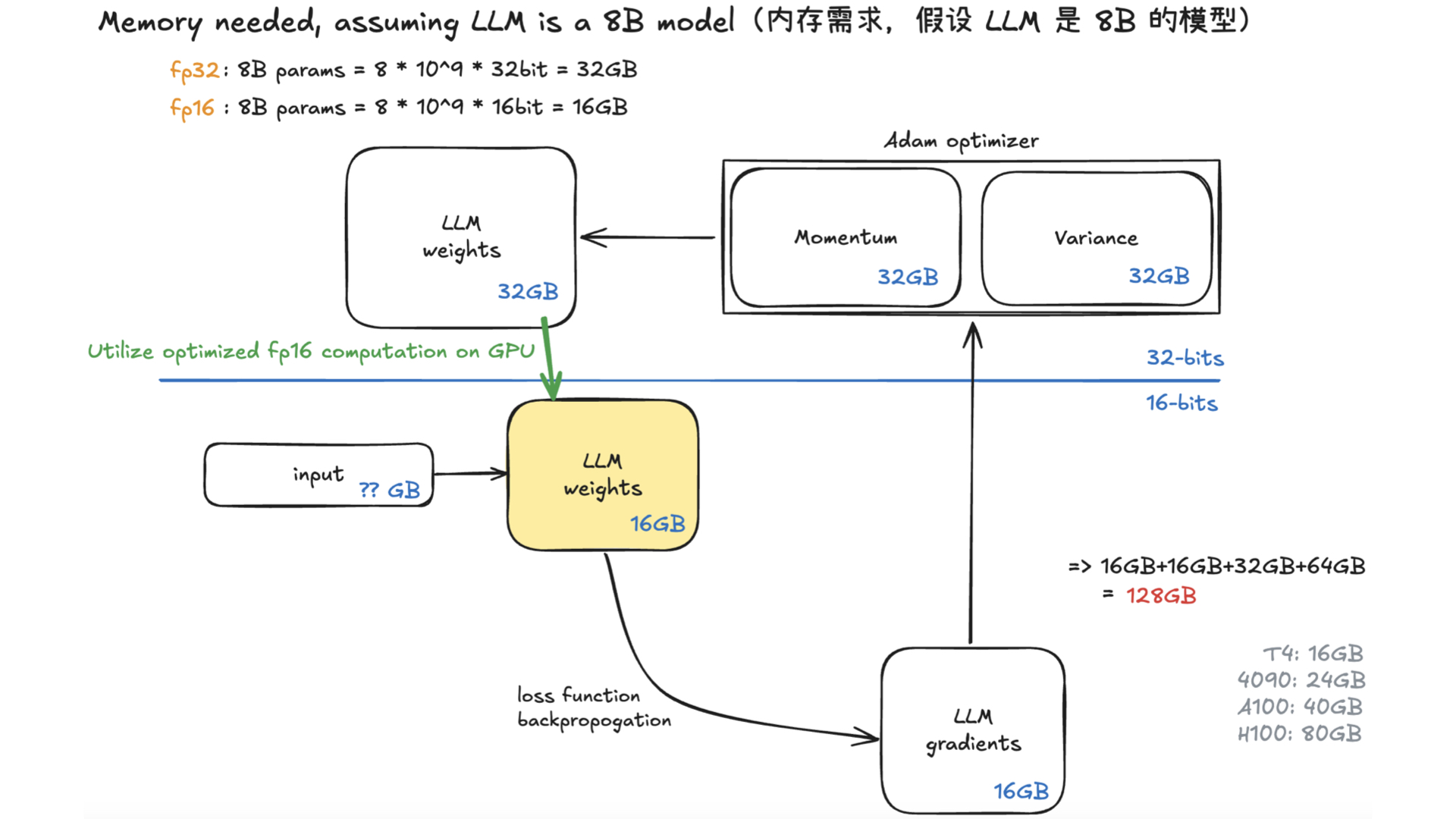
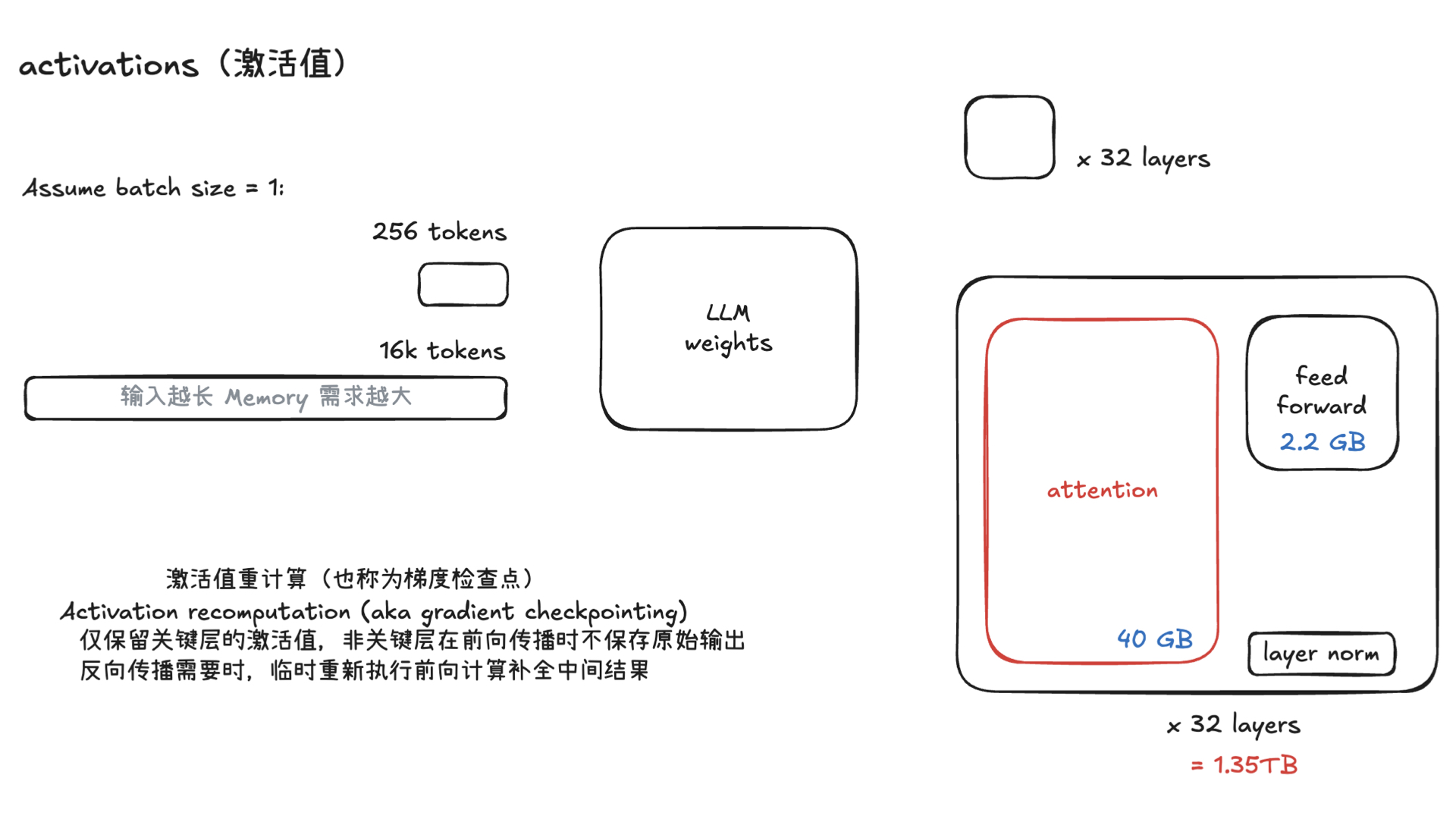
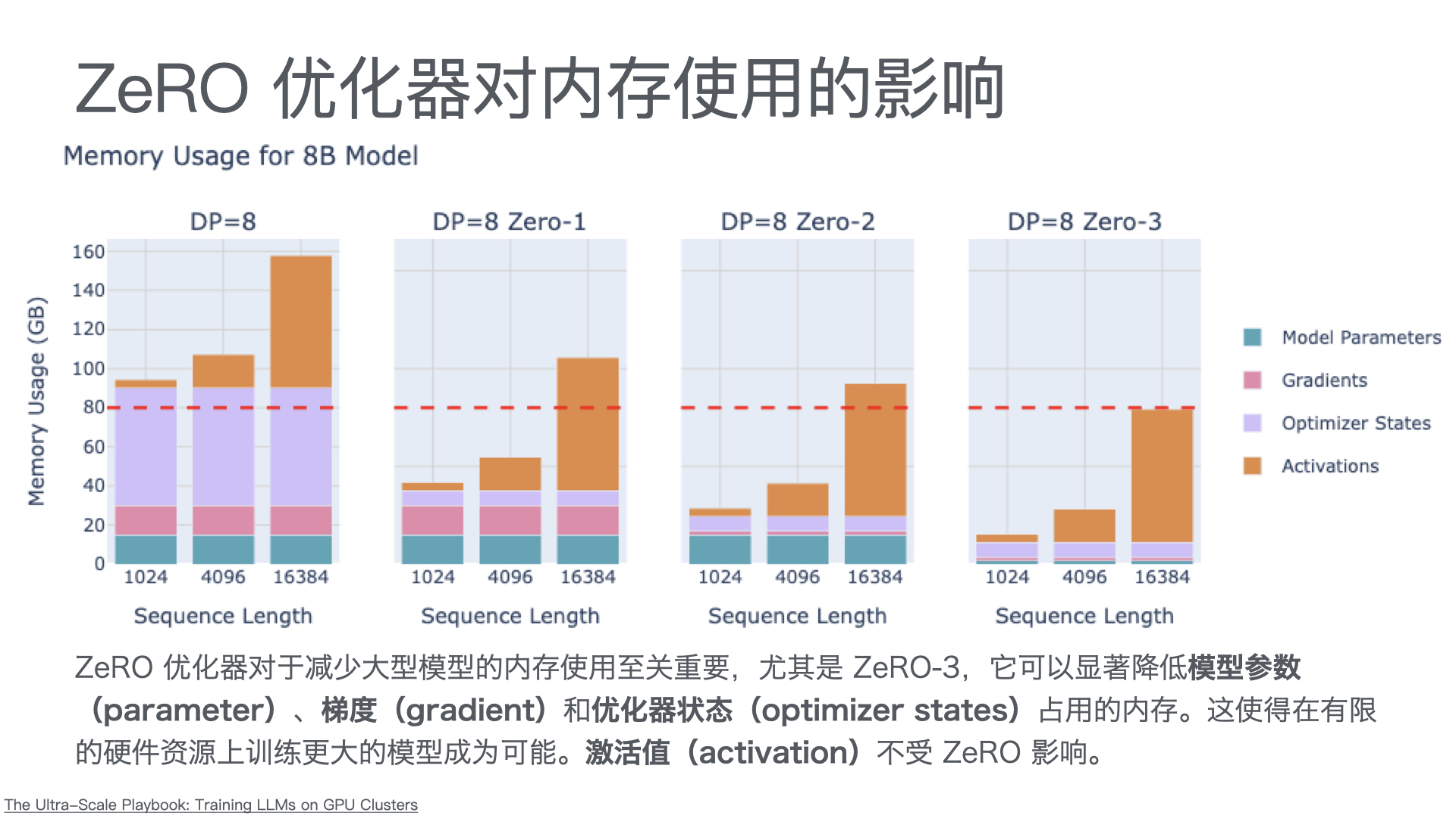
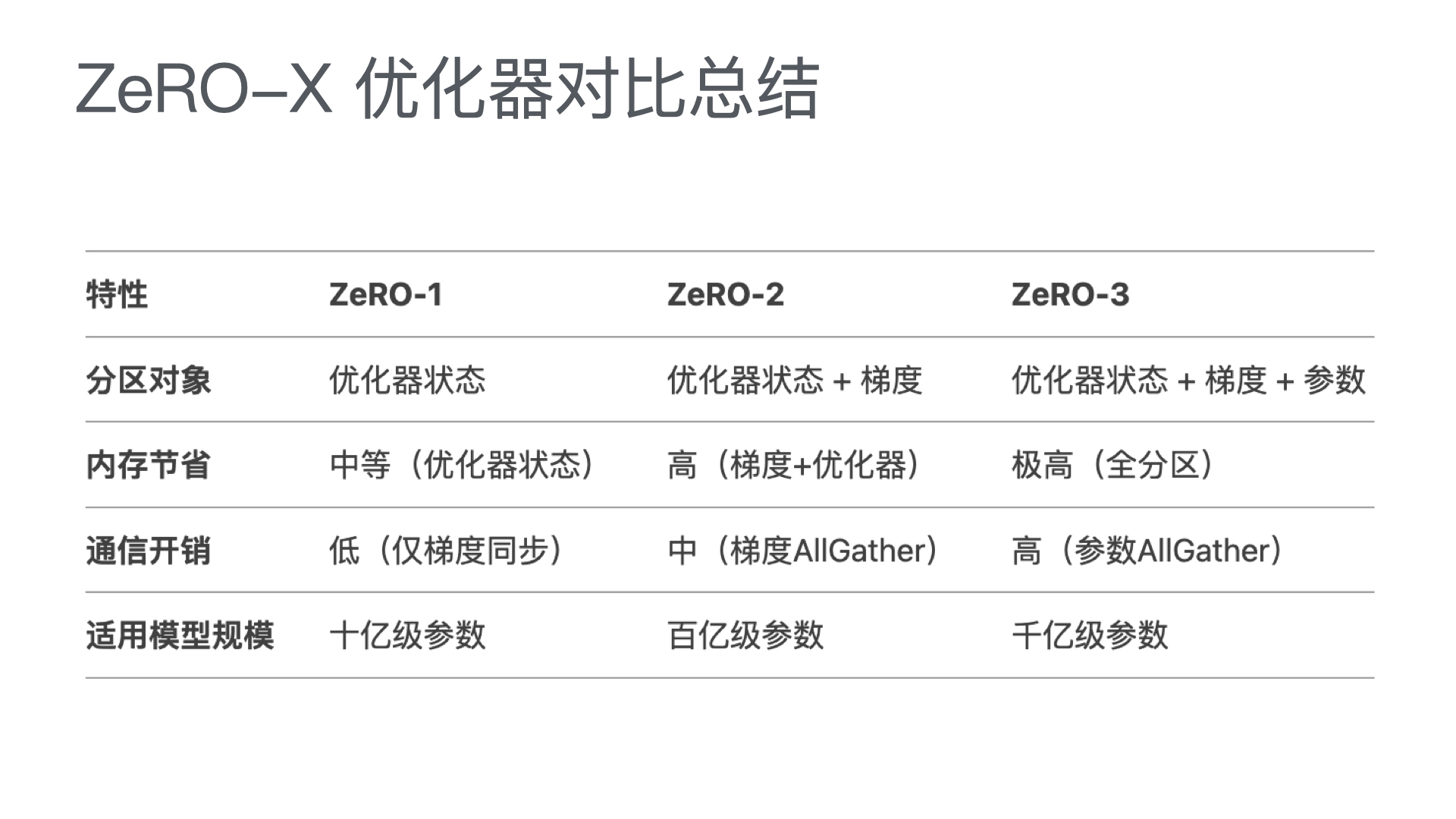
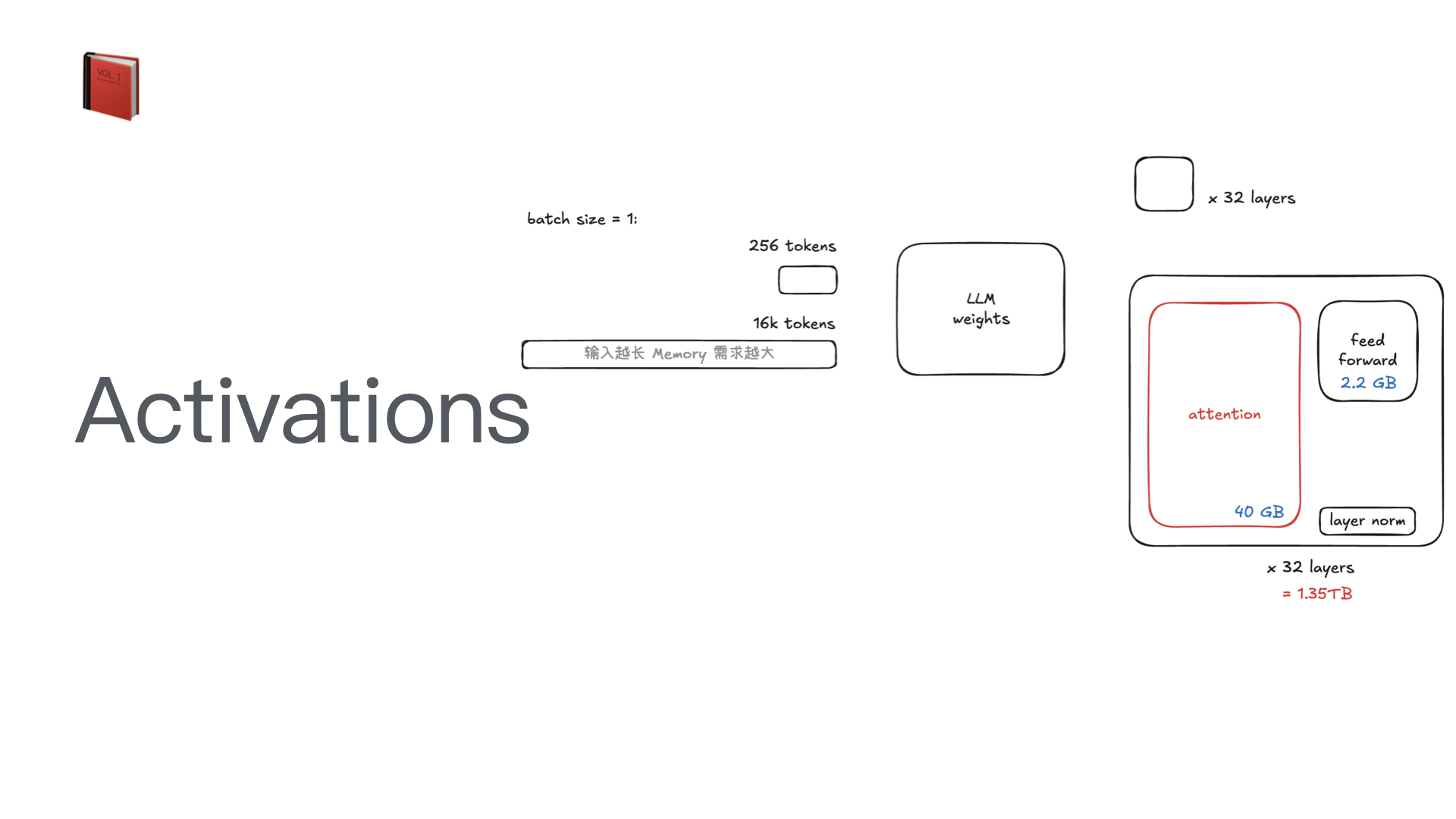
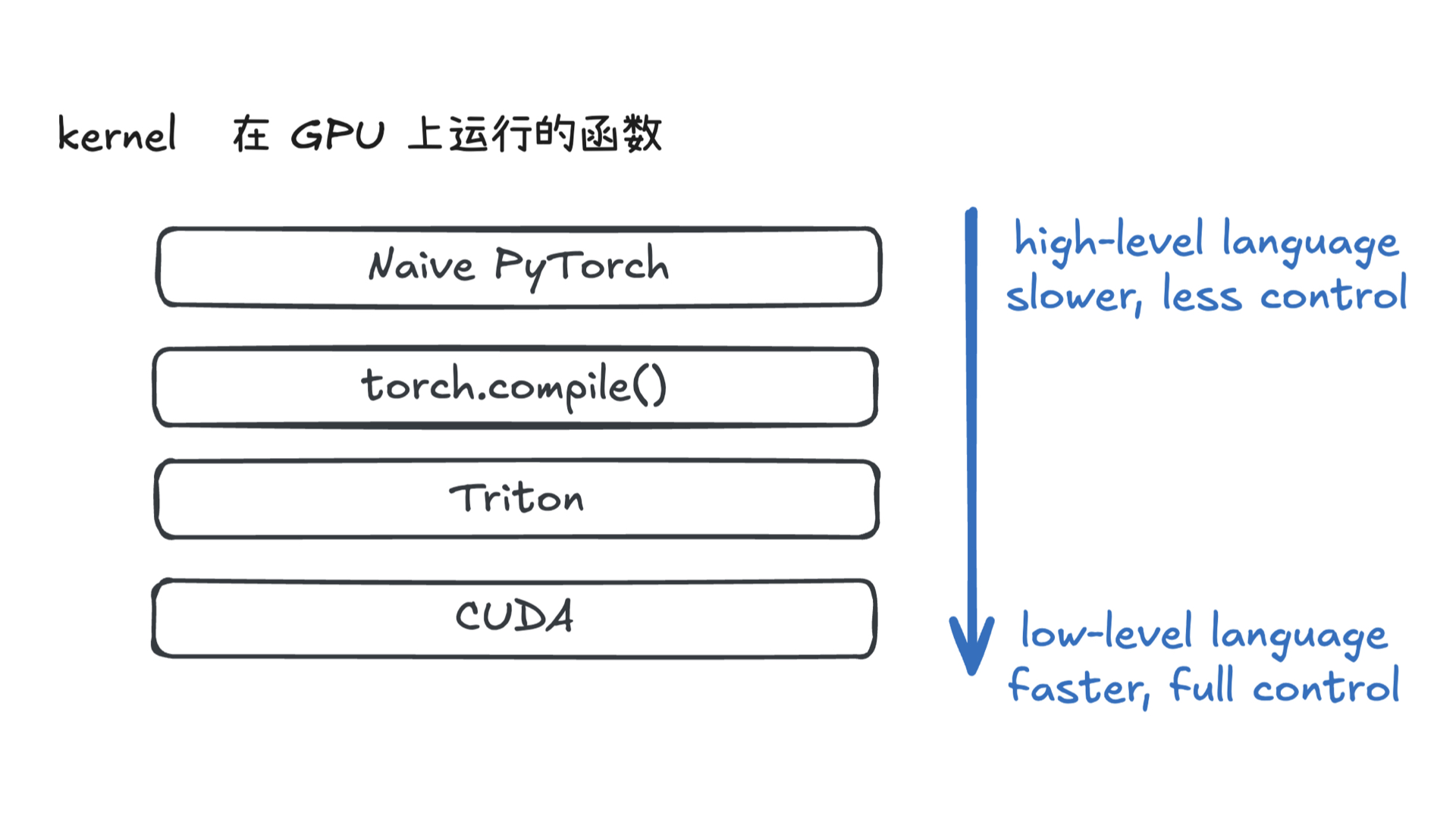
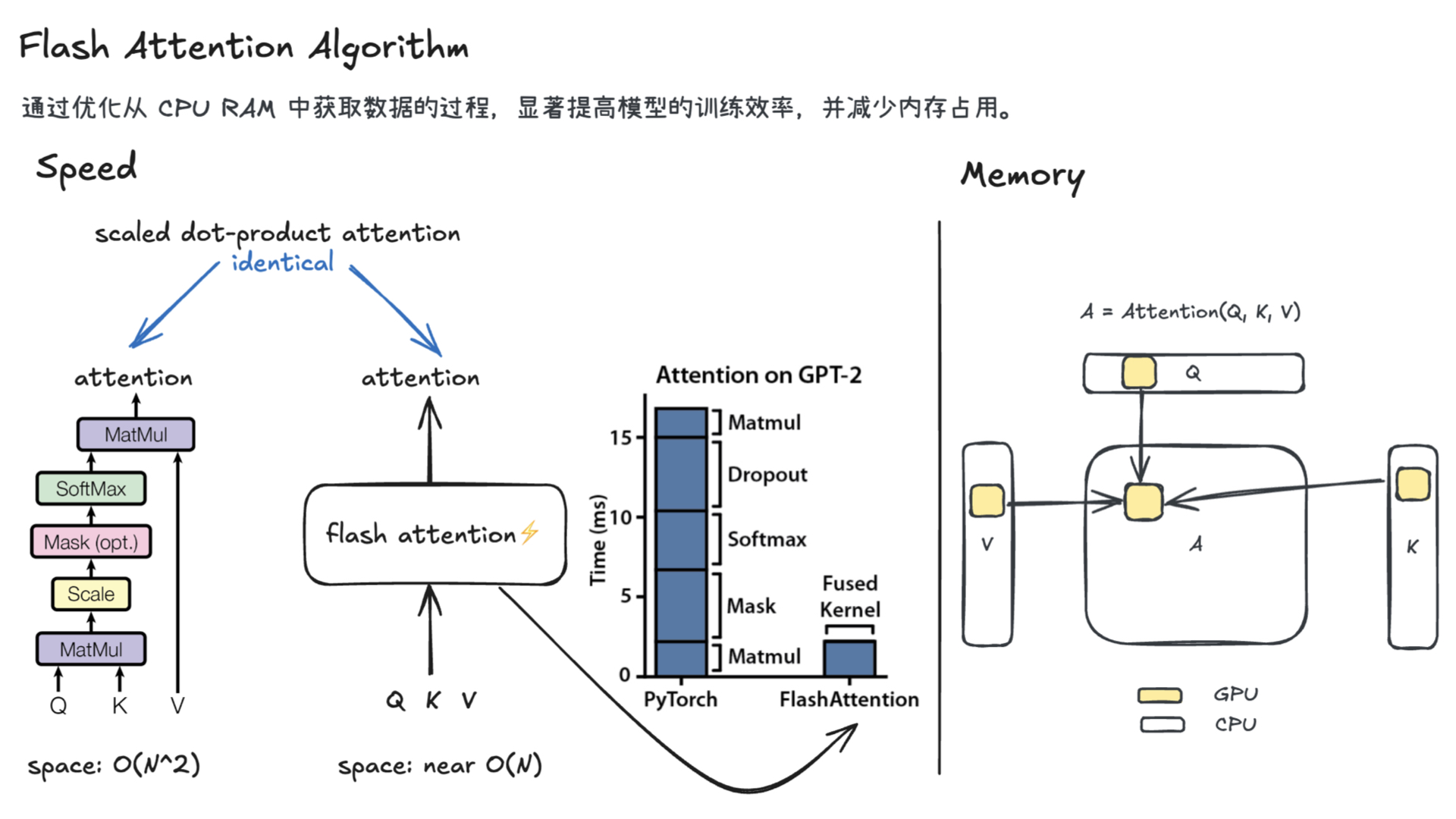
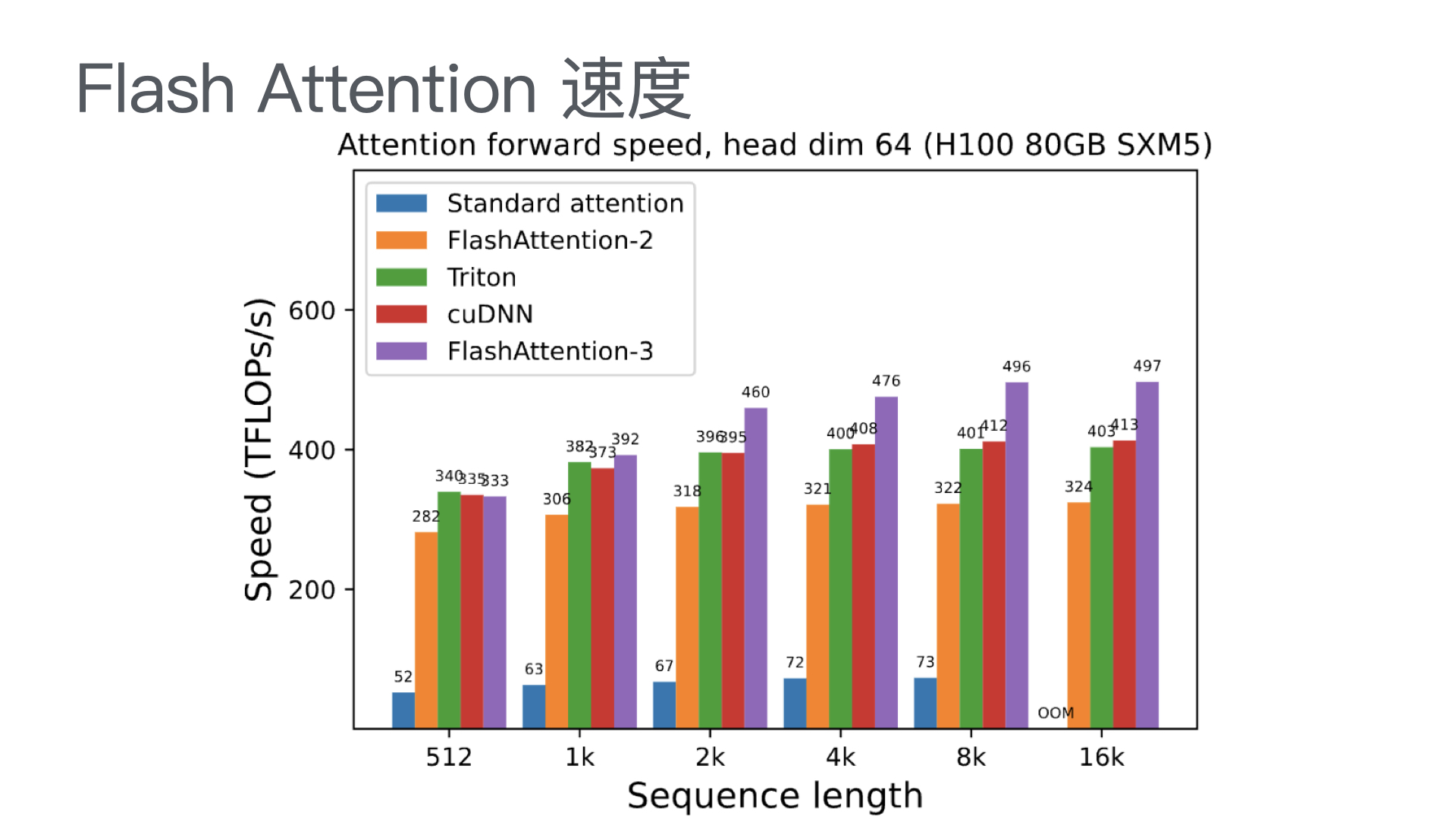
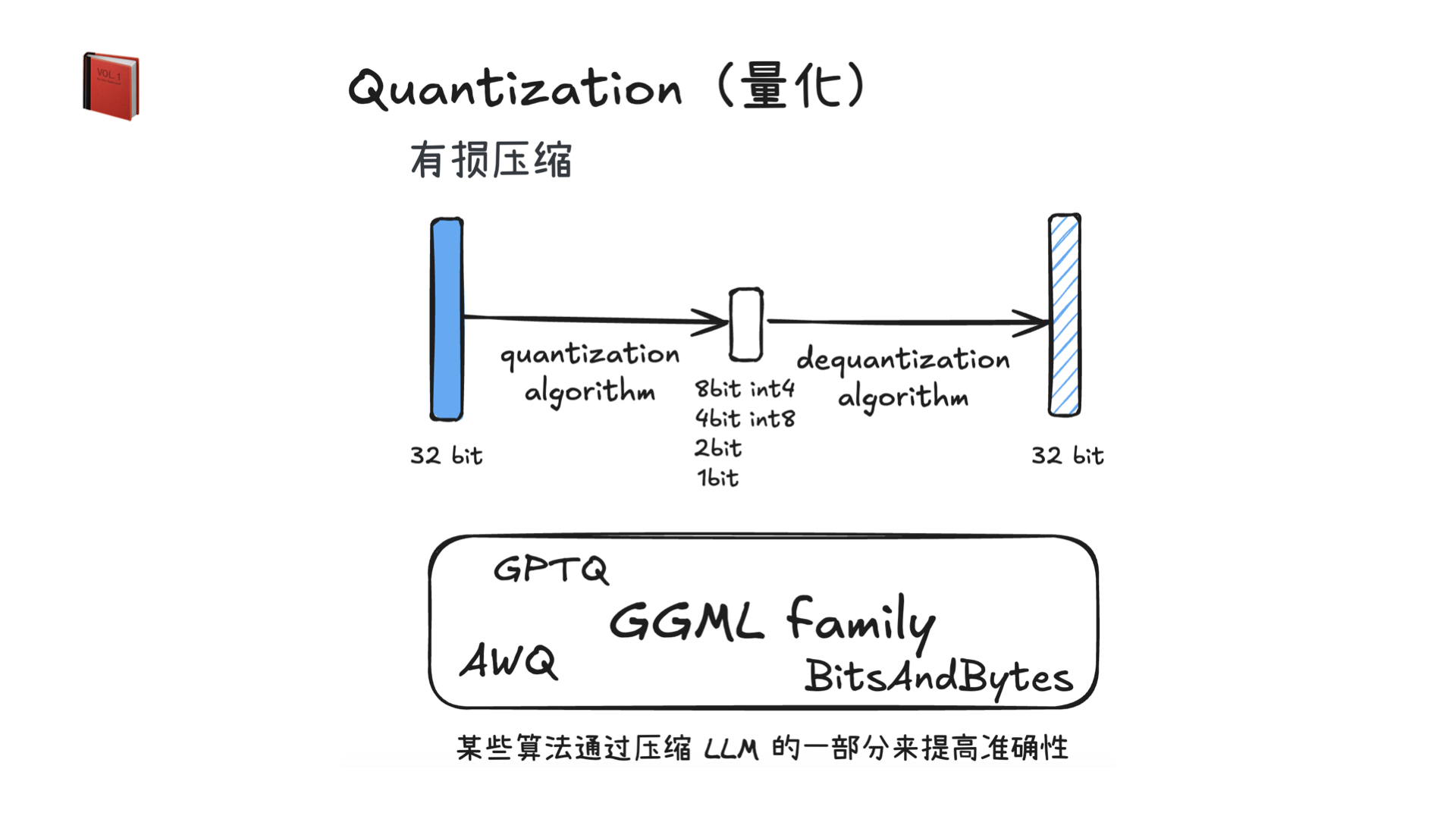
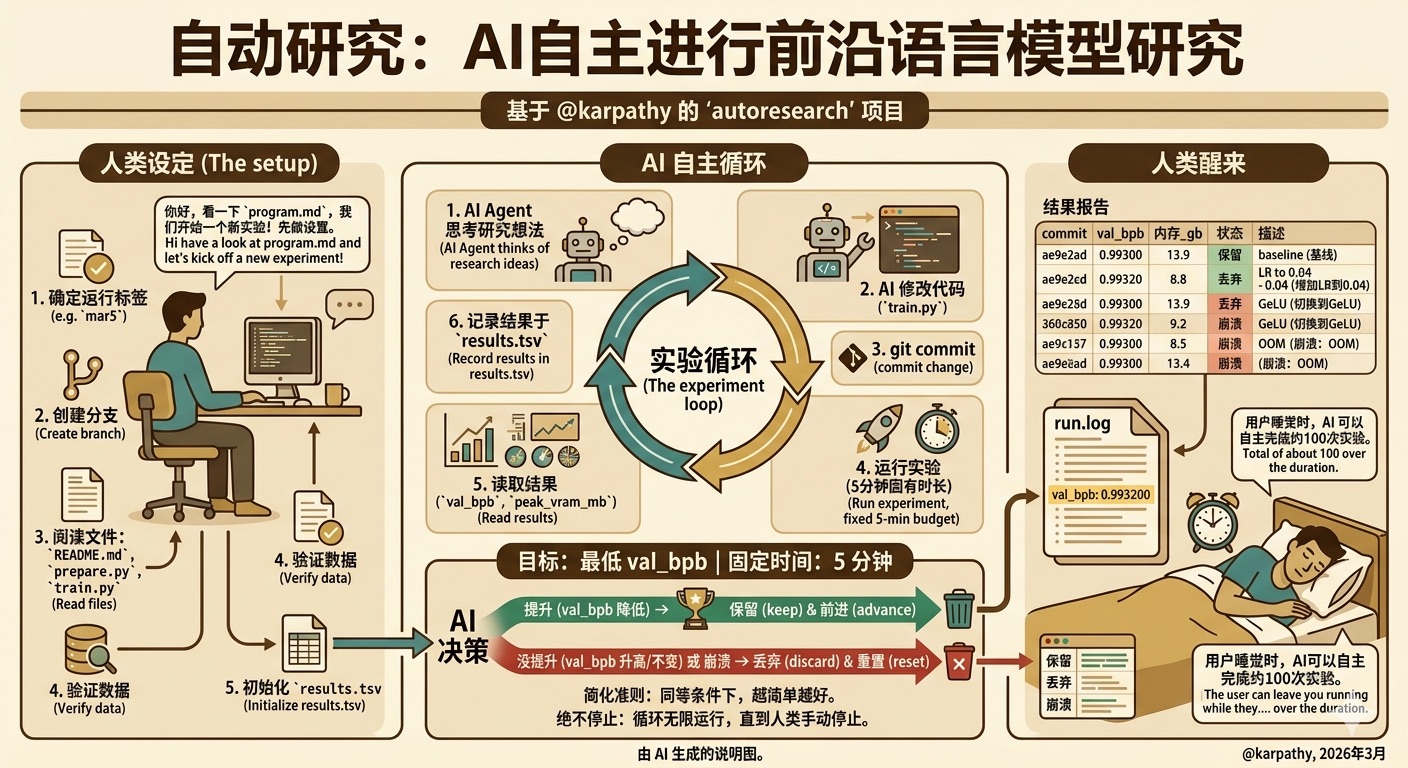
AutoResearch:AI 自主进行前沿语言模型研究
这是 Andrej Karpathy 设计的极简自主 AI 研究实验框架:让 AI 智能体仅修改 train.py,在固定 5 分钟训练预算内自主迭代优化 GPT 模型、以最低验证集 bpb 为目标,自动实验、记录结果并择优保留,无人值守持续运行。
README
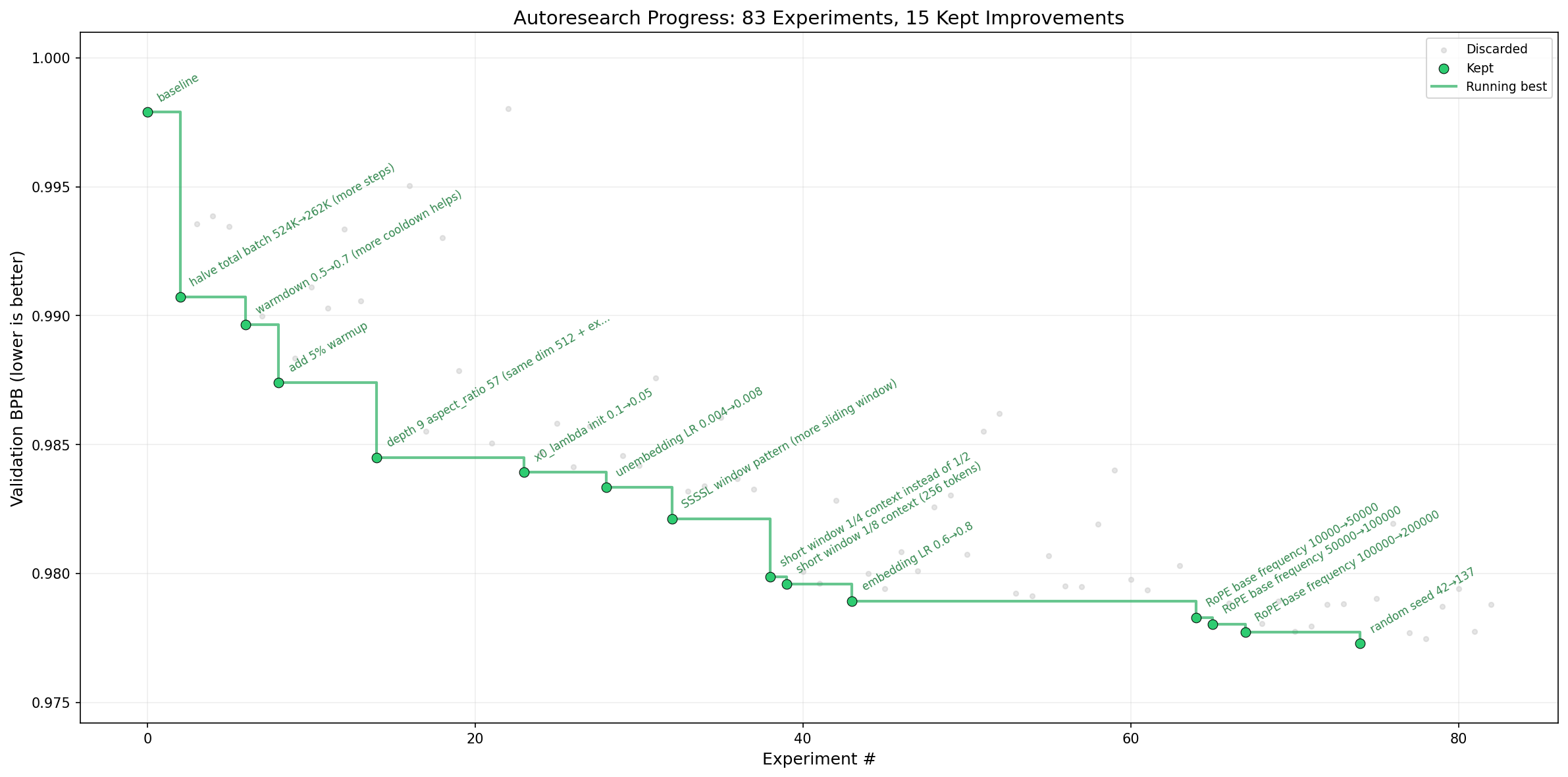
曾经有一天,前沿 AI 研究是由人类在吃饭、睡觉、享受其他乐趣,以及偶尔使用声波互连进行被称为"组会"的仪式之间完成的。那个时代早已远去。现在的研究完全属于运行在天空中计算集群巨型结构上的自主 AI 智能体集群。这些智能体声称我们现在处于代码库的第 10,205 代,反正没人能说得清这是对是错,因为"代码"现在已经是一个自我修改的二进制文件,已经超出了人类的理解范围。这个仓库讲述了这一切是如何开始的故事。-@karpathy,2026 年 3 月。
这个想法是:给一个 AI 智能体一个小但真实的 LLM 训练设置,让它在夜间自主实验。它修改代码、训练 5 分钟、检查结果是否有所改进、保留或丢弃,然后重复。你早上醒来时会看到一个实验日志,以及(希望)一个更好的模型。这里的训练代码是 nanochat 的简化单 GPU 实现。核心思想是,你不需要像研究人员通常那样触碰任何 Python 文件。相反,你是在编写 program.