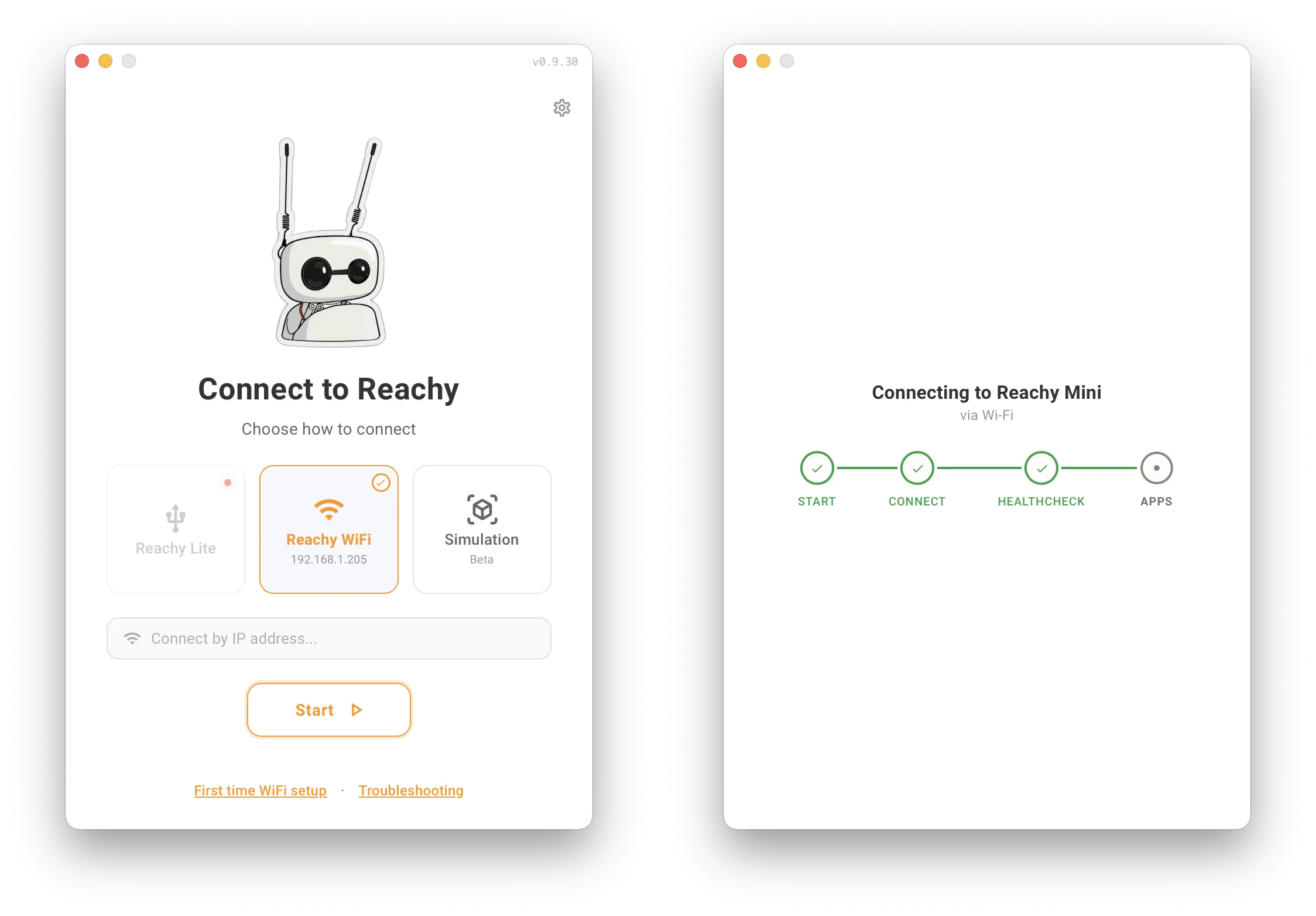
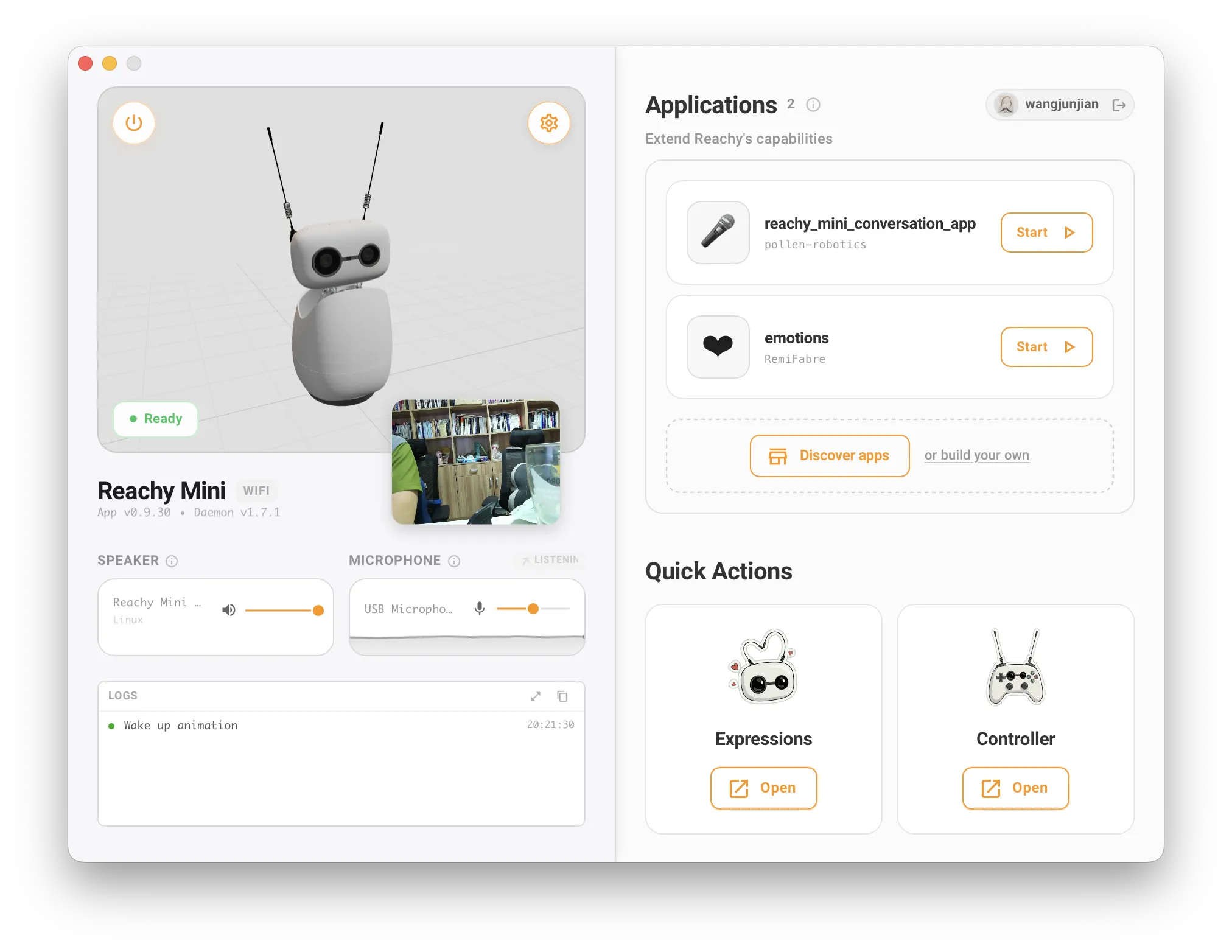
Reachy Mini Conversation App
源码安装
克隆 Reachy Mini Conversation App
git clone https://github.com/wang-junjian/reachy_mini_conversation_app
cd reachy_mini_conversation_app
创建虚拟环境并安装依赖
uv venv --python 3.12
source .venv/bin/activate
uv sync
⚠️ 注意:要完全复现此仓库 uv.lock 文件中的依赖关系,请运行 uv sync --frozen 命令。这将确保 uv 直接从 lock 文件安装依赖项,而无需重新解析或更新任何版本。
安装可选功能
uv sync --extra local_vision # Local PyTorch/Transformers vision
uv sync --extra yolo_vision # YOLO face-detection backend for head tracking
uv sync --extra mediapipe_vision # MediaPipe-based head-tracking
uv sync --extra all_vision # All vision features
合并额外功能或包含开发依赖项: