Reader-LM: 用于清理和转换 HTML 到 Markdown 的小型语言模型
Reader-LM
- Google Colab: Reader-LM Tutorial
- jinaai/reader-lm-1.5b
- Reader-LM: Small Language Models for Cleaning and Converting HTML to Markdown
- 专访Jina AI肖涵博士:搜索的未来,藏在一堆小模型里
不能简单地将 HTML 把输入给模型(Reader-LM),因为效果不理想。
Reader-LM-0.5B 和 Reader-LM-1.5B 是受 Jina Reader 启发的两个新型小型语言模型,旨在将来自开放网络的原始、嘈杂的 HTML 转换为干净的 markdown。

使用小型语言模型替换了 readability + turndown + regex 启发式的管道。
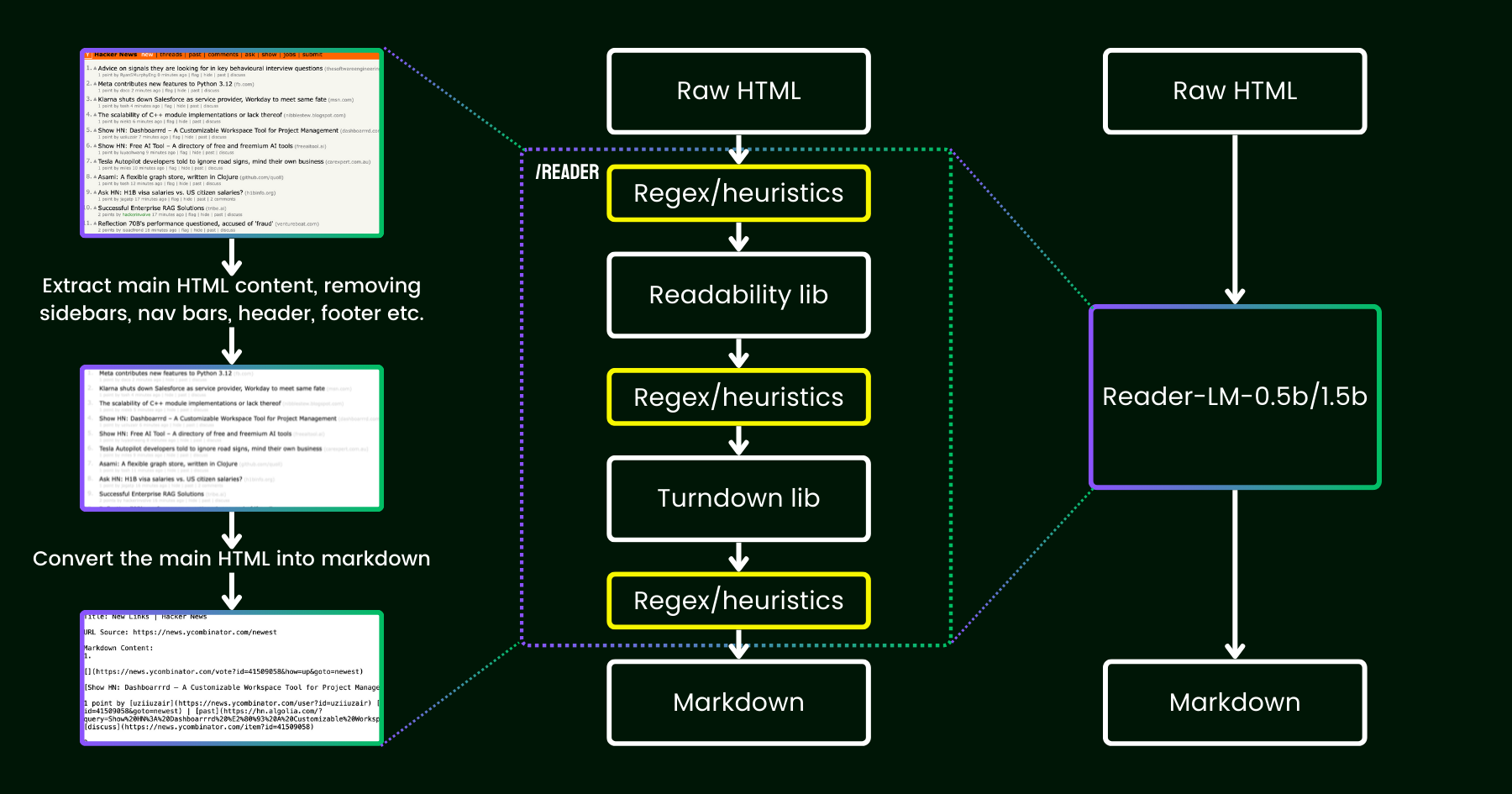
Jina Reader 是一个简单的 API,只需一个简单的前缀:r.jina.ai,就可以将任何 URL 转换为 LLM 友好的 markdown。
Jina Embeddings V3
jina-embeddings-v3 的架构基于 XLM-RoBERTa 模型,并进行了几项关键修改。