用通俗易懂的方式理解 Harness Engineering
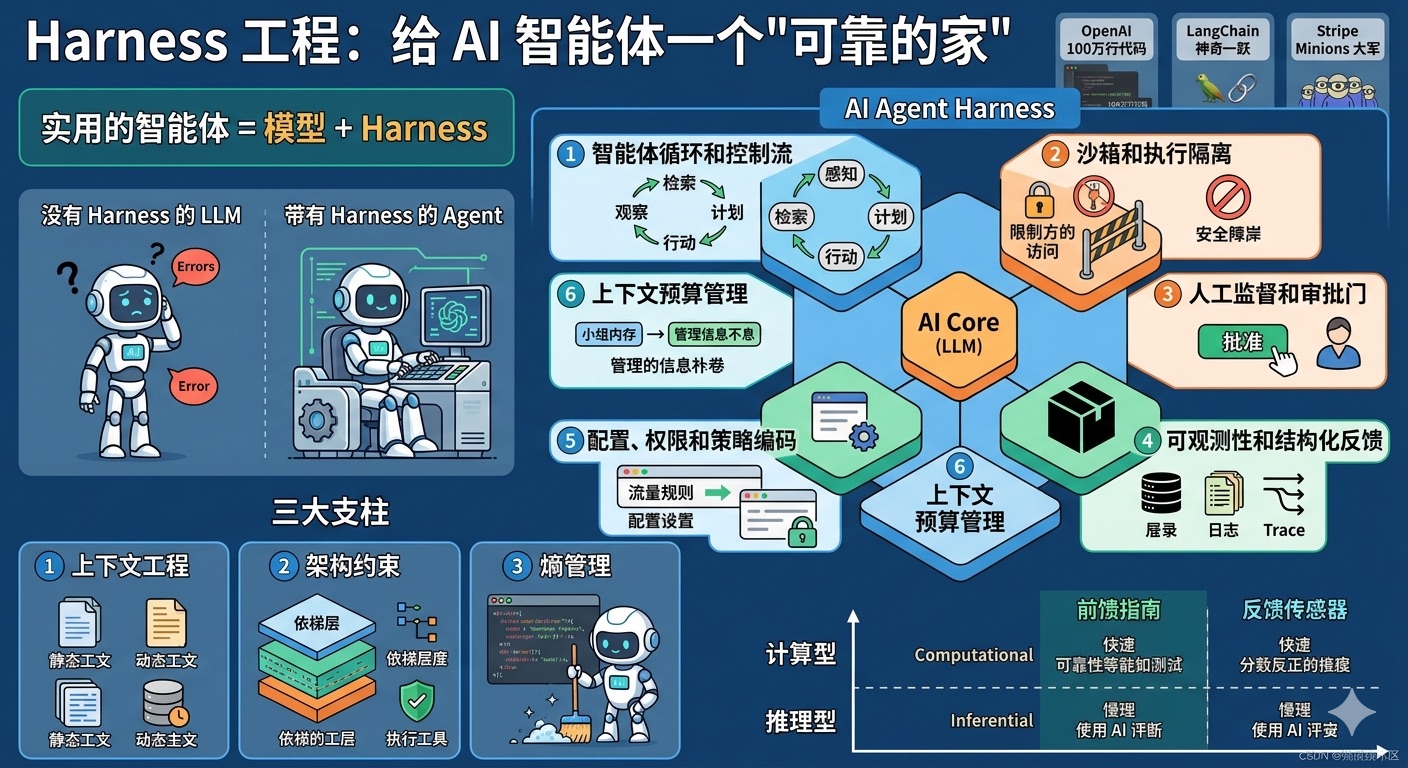
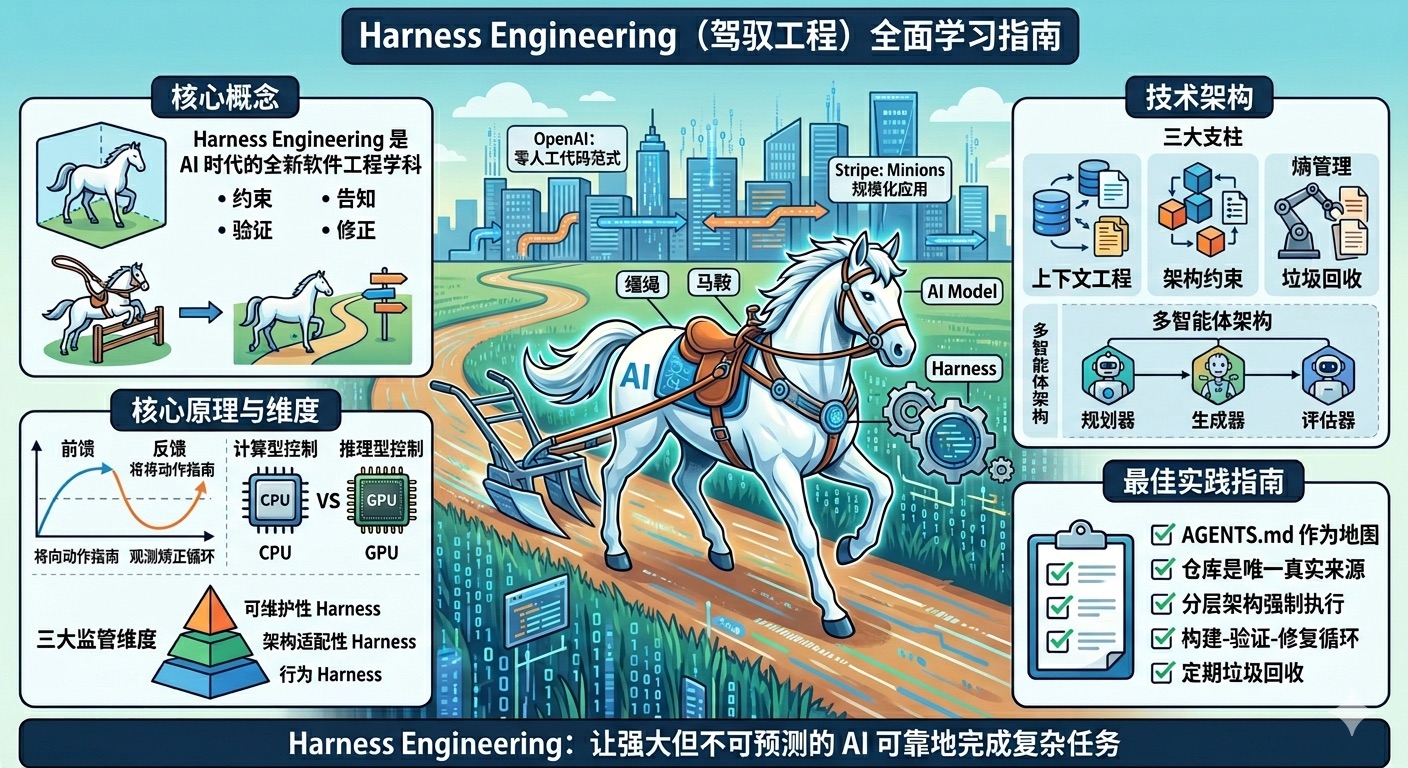
Harness 工程:给 AI 智能体一个"可靠的家"
想象一下,你有一个非常聪明但有点冲动的助手——它知识渊博、能说会道,但有时候会:
- 忘记五分钟前你们讨论的事情
- 直接执行危险操作而不问你
- 在复杂任务中迷路,绕来绕去
- 做错了事,但你不知道为什么
这就是没有 Harness 的 LLM 智能体。
什么是 Harness?
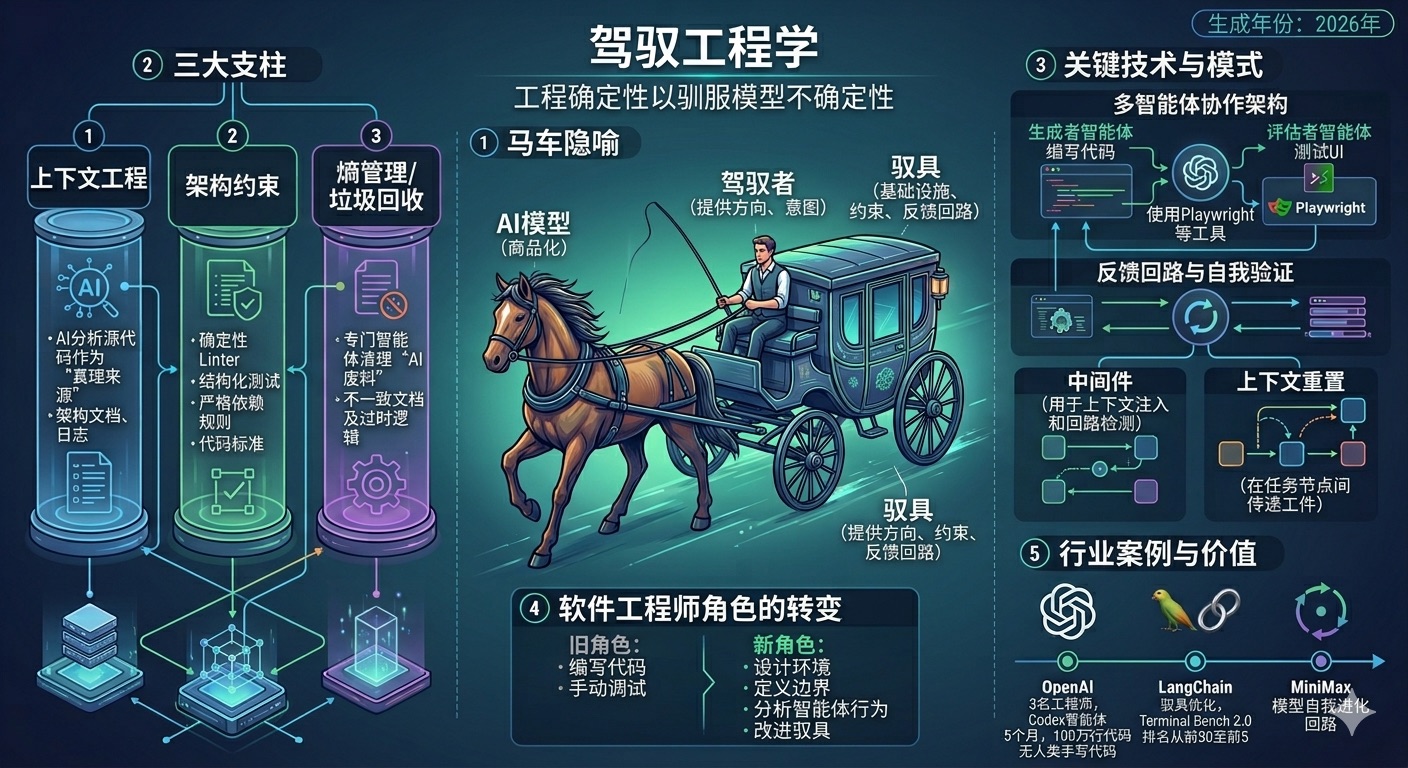
Harness 这个词在英文里有"马具"、"安全带"的意思。在 AI 智能体的世界里,它就是那个让智能体既能够发挥能力,又不会失控的"安全脚手架"。
这个隐喻是有意的:
- 马是 AI 模型——强大、快速,但它自己不知道去哪里
- Harness是基础设施——约束、护栏、反馈循环,以富有成效地引导模型的力量
- 骑手是人类工程师——提供方向,而不是亲自奔跑
用一个更贴近生活的比喻:Harness 就像是智能体的"驾驶舱 + 安全带 + 导航系统 + 黑匣子"的组合体。
根据 Harness Engineering 将原始模型能力转化为可靠 Agent 行为的脚手架。实用的 Agent 最好被理解为在 Harness 内部运行的模型,而不是带有外围能力的模型。
真实故事:Harness 工程的威力
在我们深入技术细节之前,让我们看看几个真实的例子,了解为什么 Harness 工程如此重要: