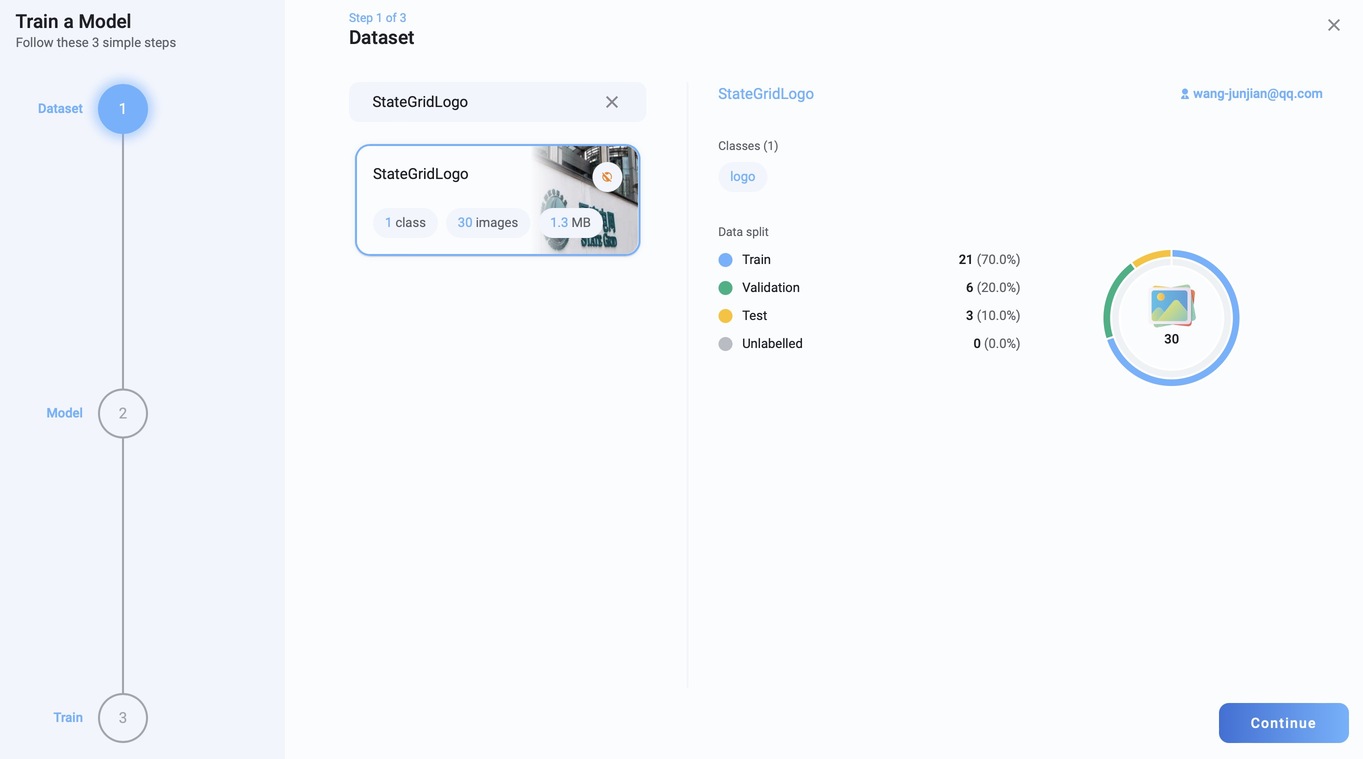
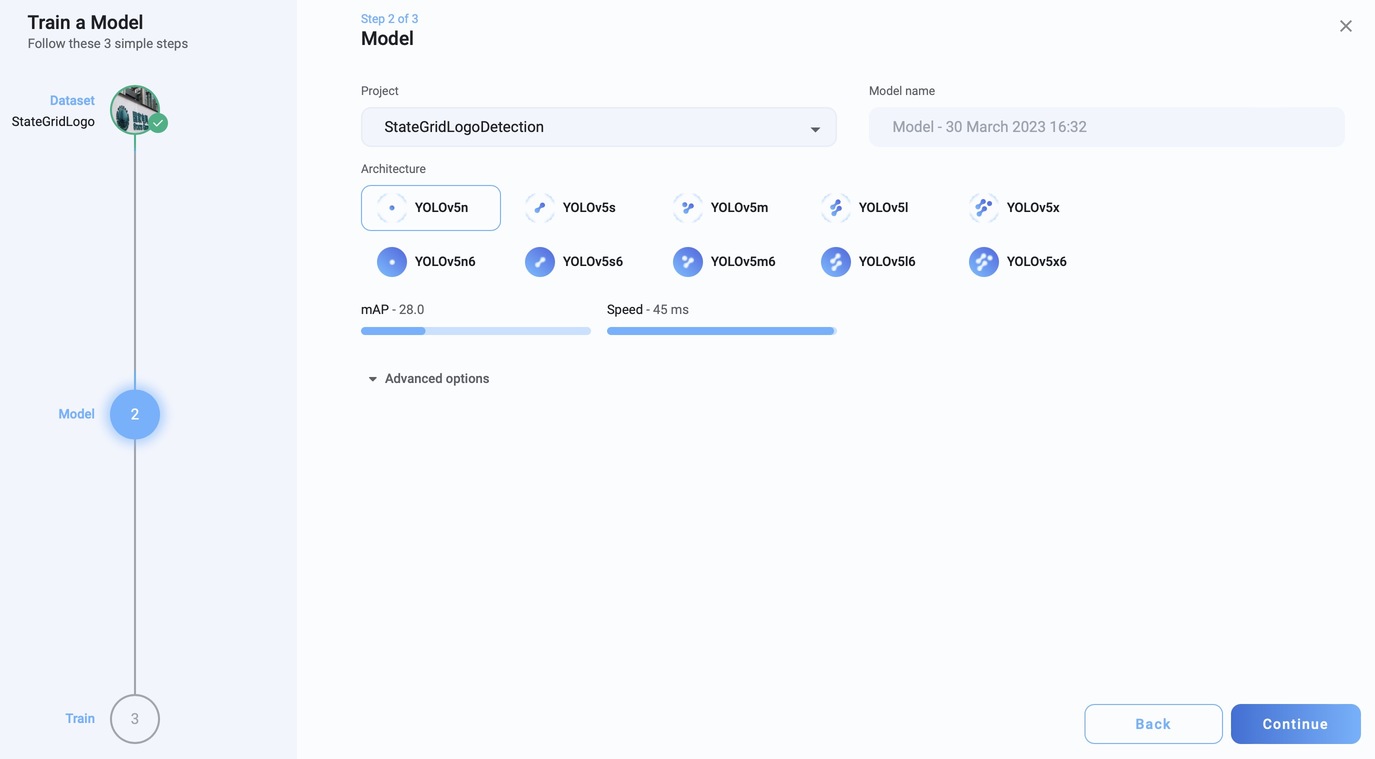
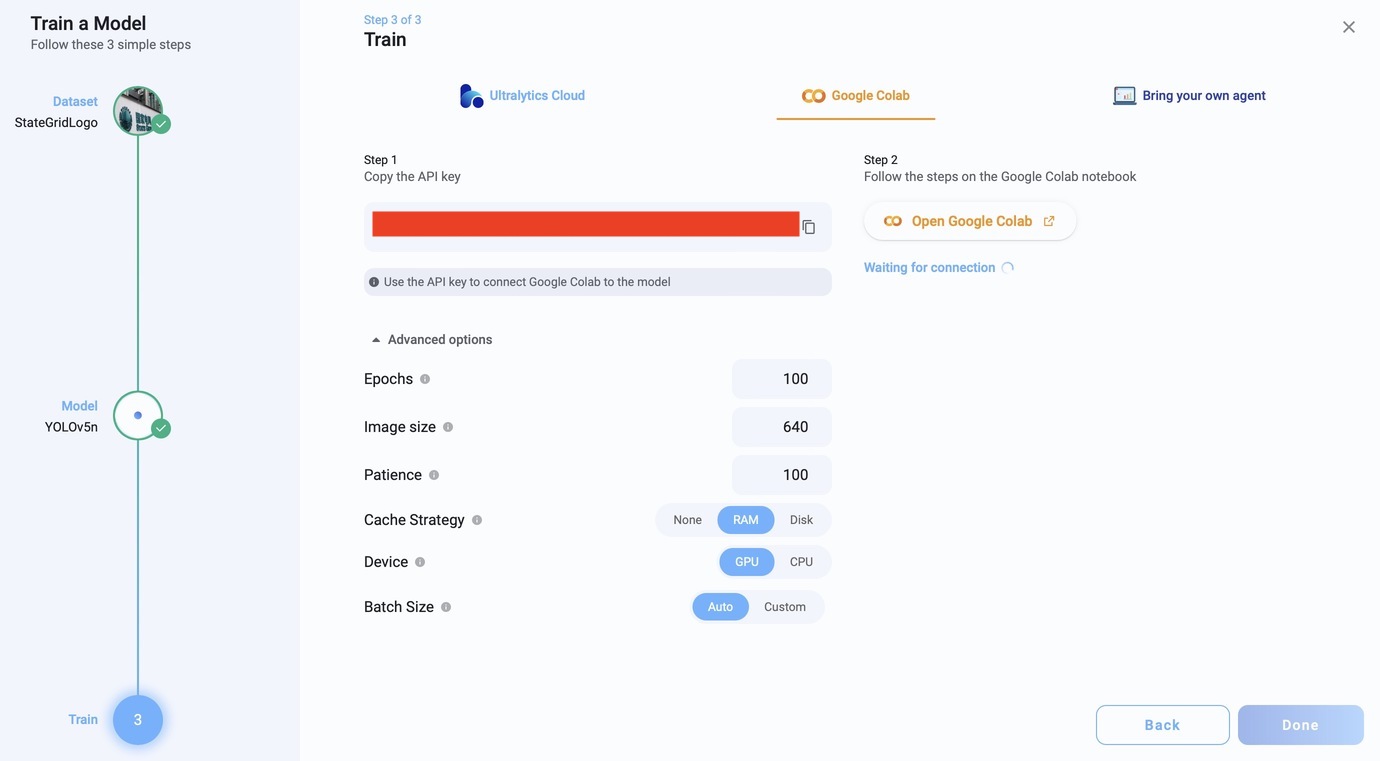
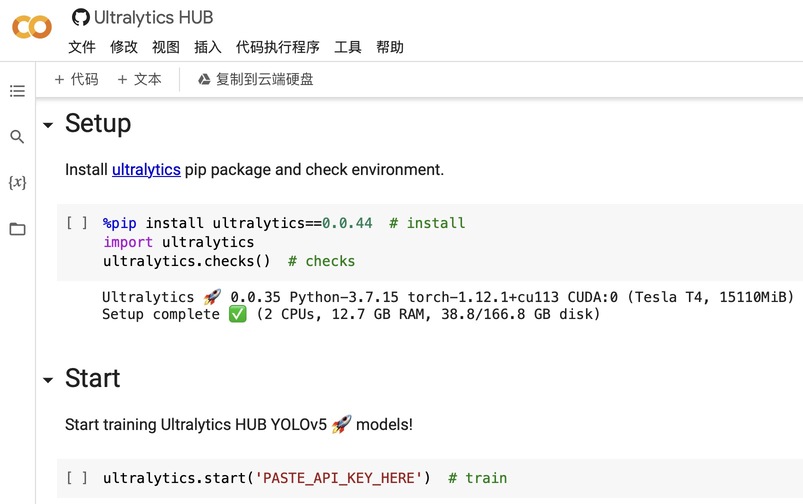
CrewAI 快速入门
安装
pip install 'crewai[tools]'
CrewAI 使用 Ollama 运行本地 LLM
.env
OPENAI_API_BASE=http://localhost:11434/v1
OPENAI_MODEL_NAME=aya:8b
OPENAI_API_KEY=NULL
agent.py
版本1
每次执行结果都不一样
from dotenv import load_dotenv
load_dotenv()
from crewai import Agent, Task, Crew
from langchain_openai import ChatOpenAI
general_agent = Agent(
role = "数学教授",
goal = """为提问数学问题的学生提供解决方案并给出答案。""",
backstory = """您是一位优秀的数学教授,喜欢以每个人都能理解的方式解决数学问题。""",
allow_delegation = False,
verbose = True
)
// ...
版本2
稳定地生成结果