Bloop 使用指南
bloop
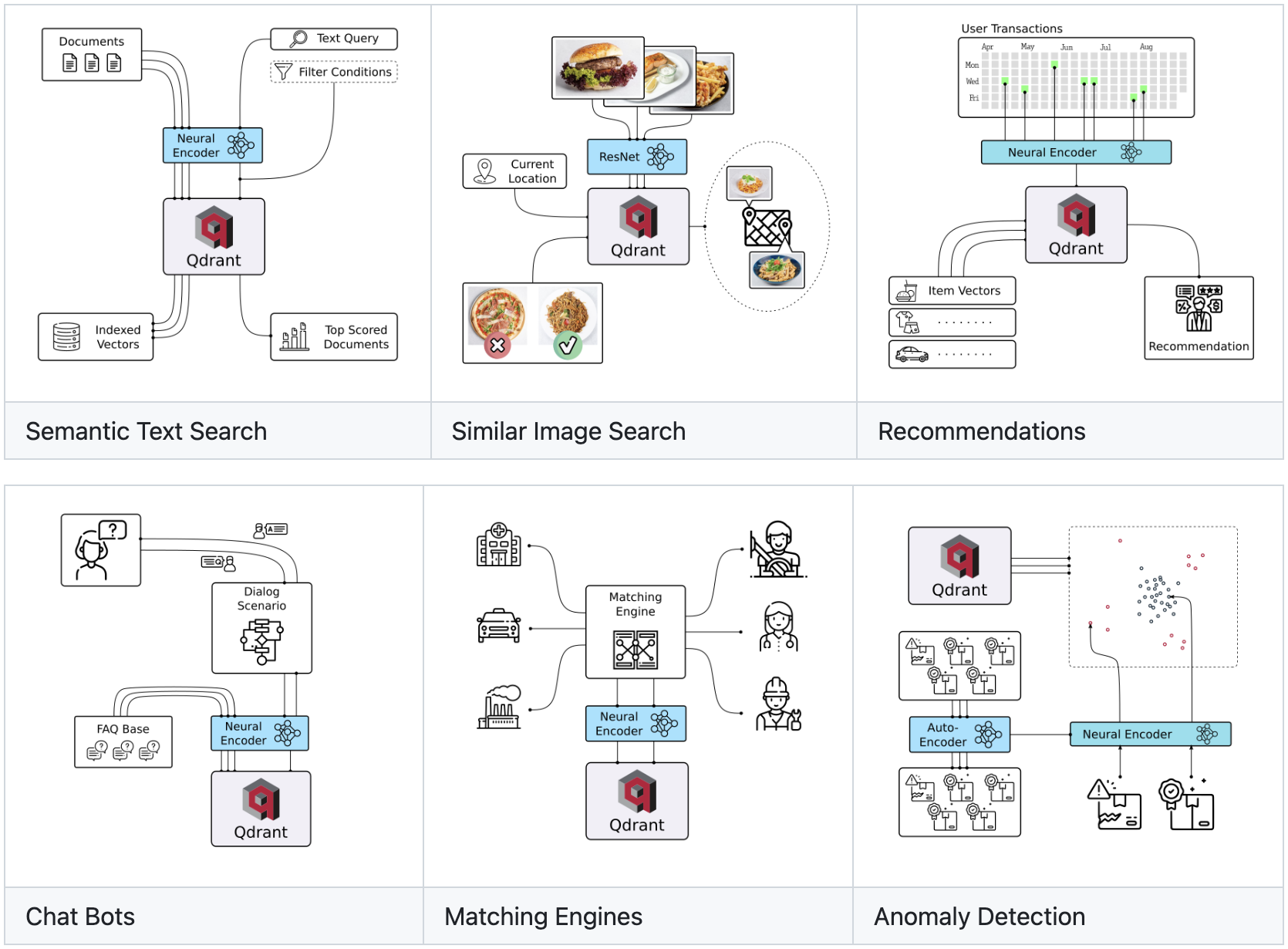
bloop 是用 Rust 编写的快速代码搜索引擎
克隆代码
git clone https://github.com/BloopAI/bloop
cd bloop
指定依赖库版本
cargo update -p qdrant-client --precise 1.5.0
cargo update -p reqwest --precise 0.11.20
编译
cargo build -p bleep --release
部署 Qdrant 服务
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage_1_5_0:/qdrant/storage:z \
qdrant/qdrant:v1.5.0
运行
mkdir codes
RUST_BACKTRACE=1 cargo run -p bleep --release -- --source-dir /Users/junjian/GitHub/BloopAI/bloop/codes
安装依赖
- ONNX Runtime
brew install onnxruntime
brew install tauri
brew install vips