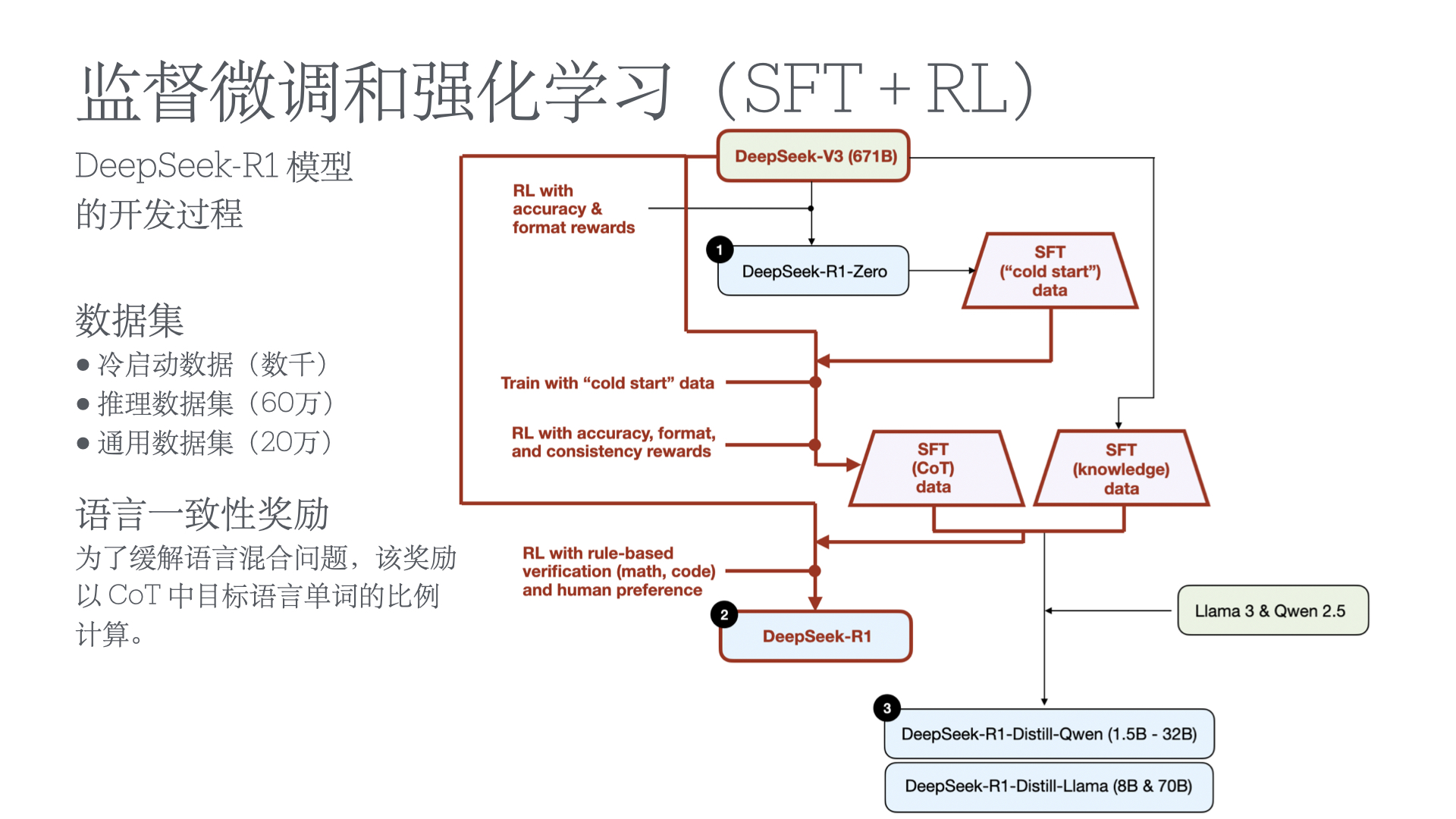
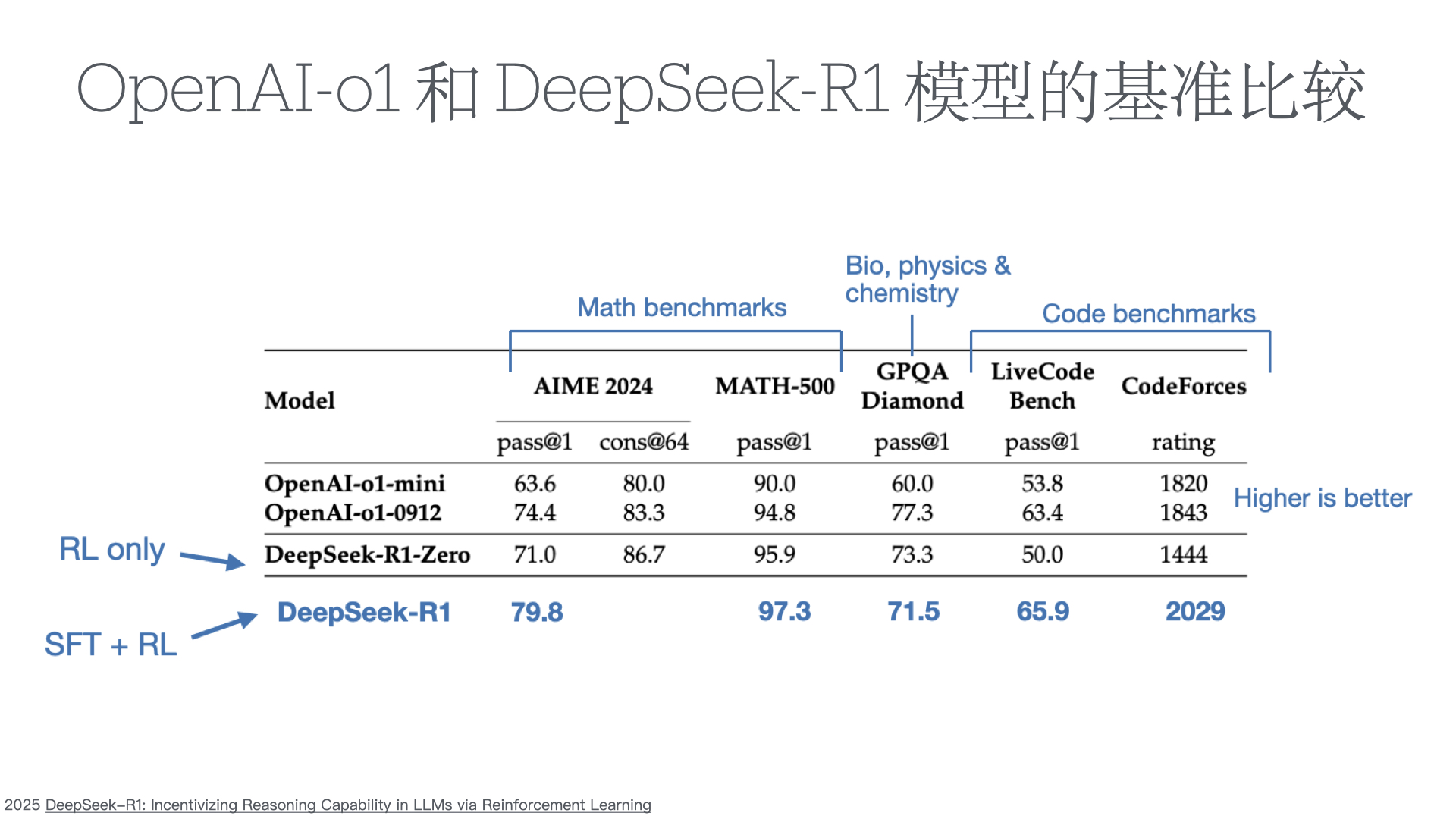
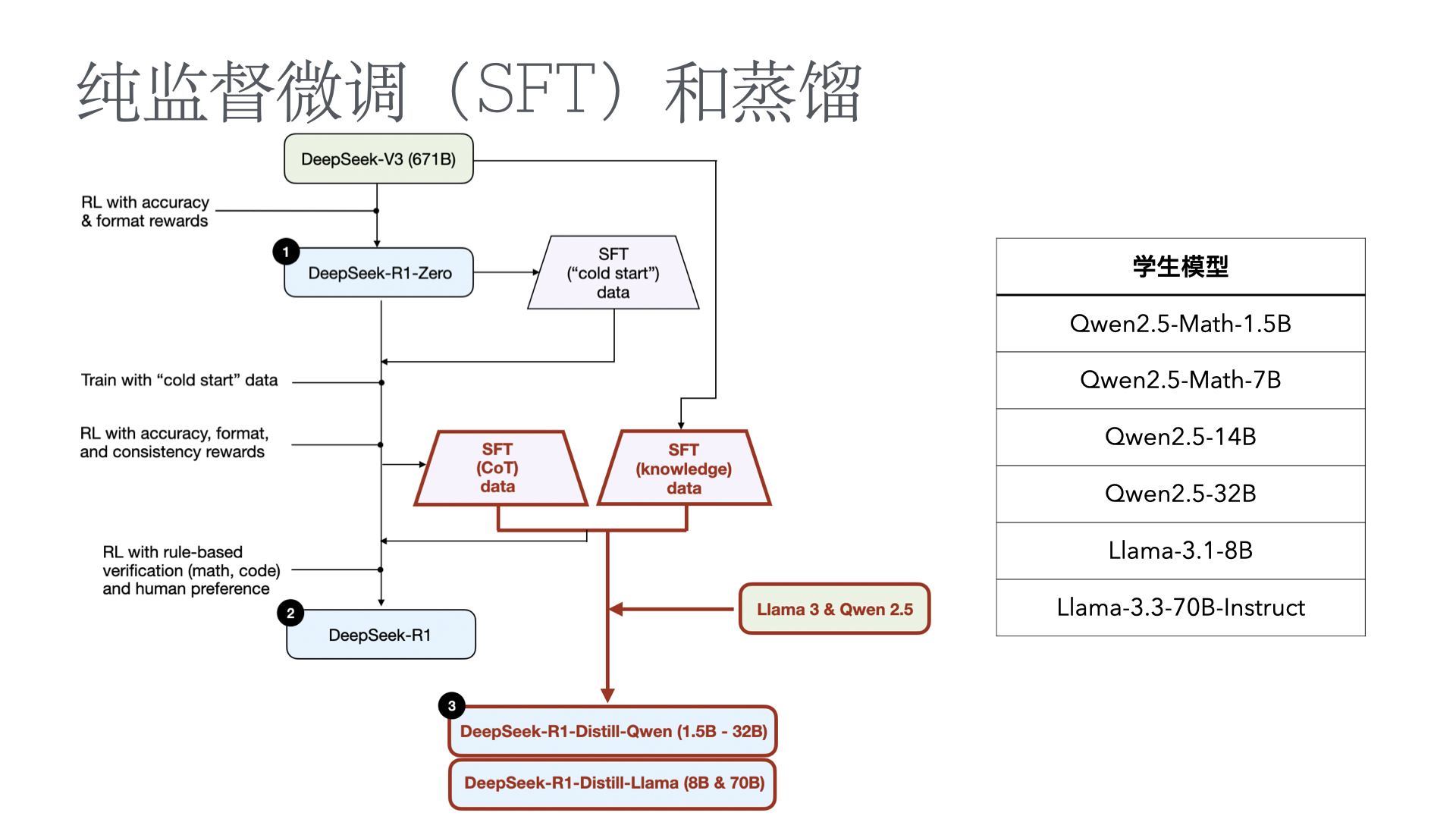
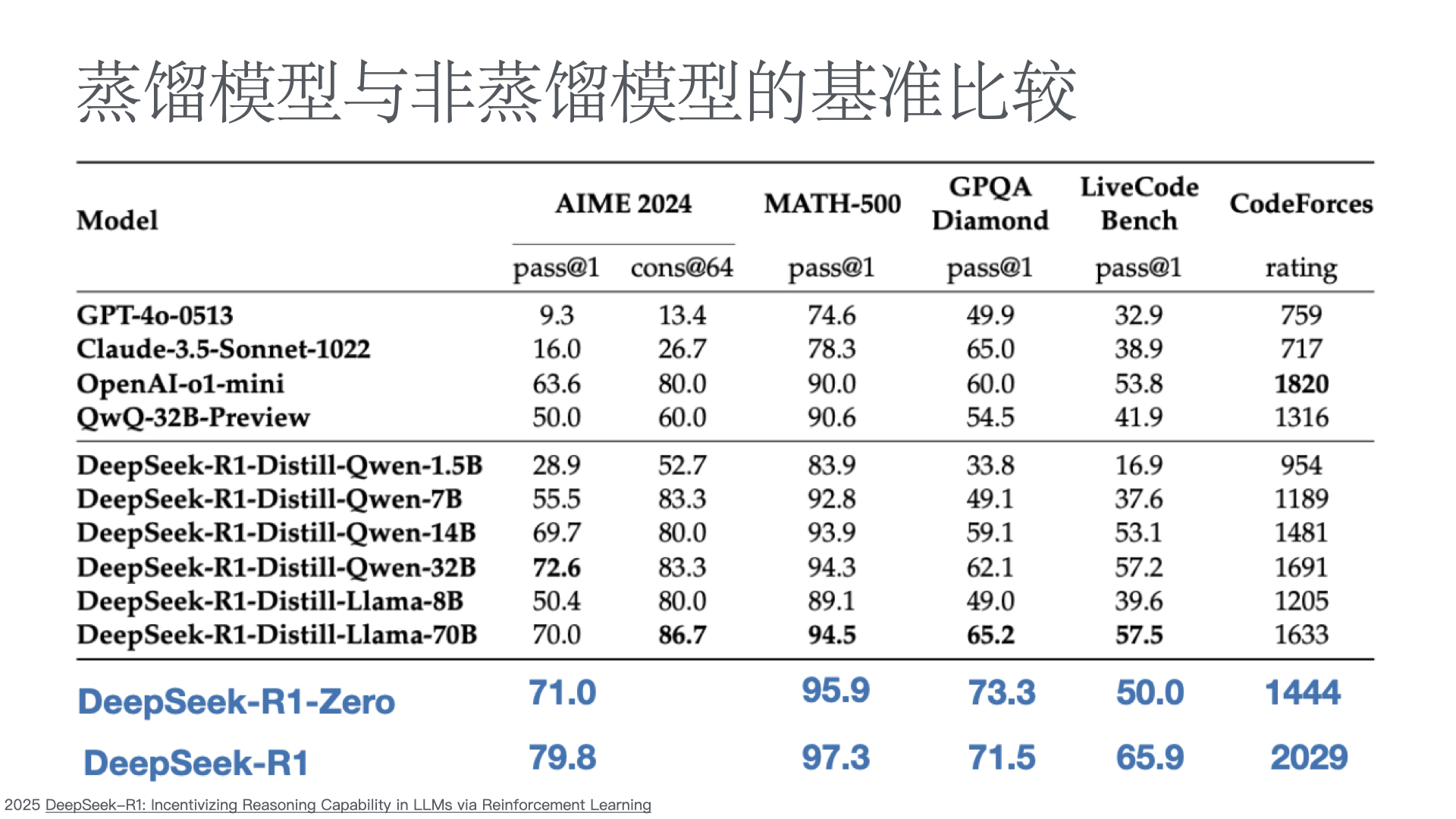
监测推理模型的不当行为以及提升混淆的风险
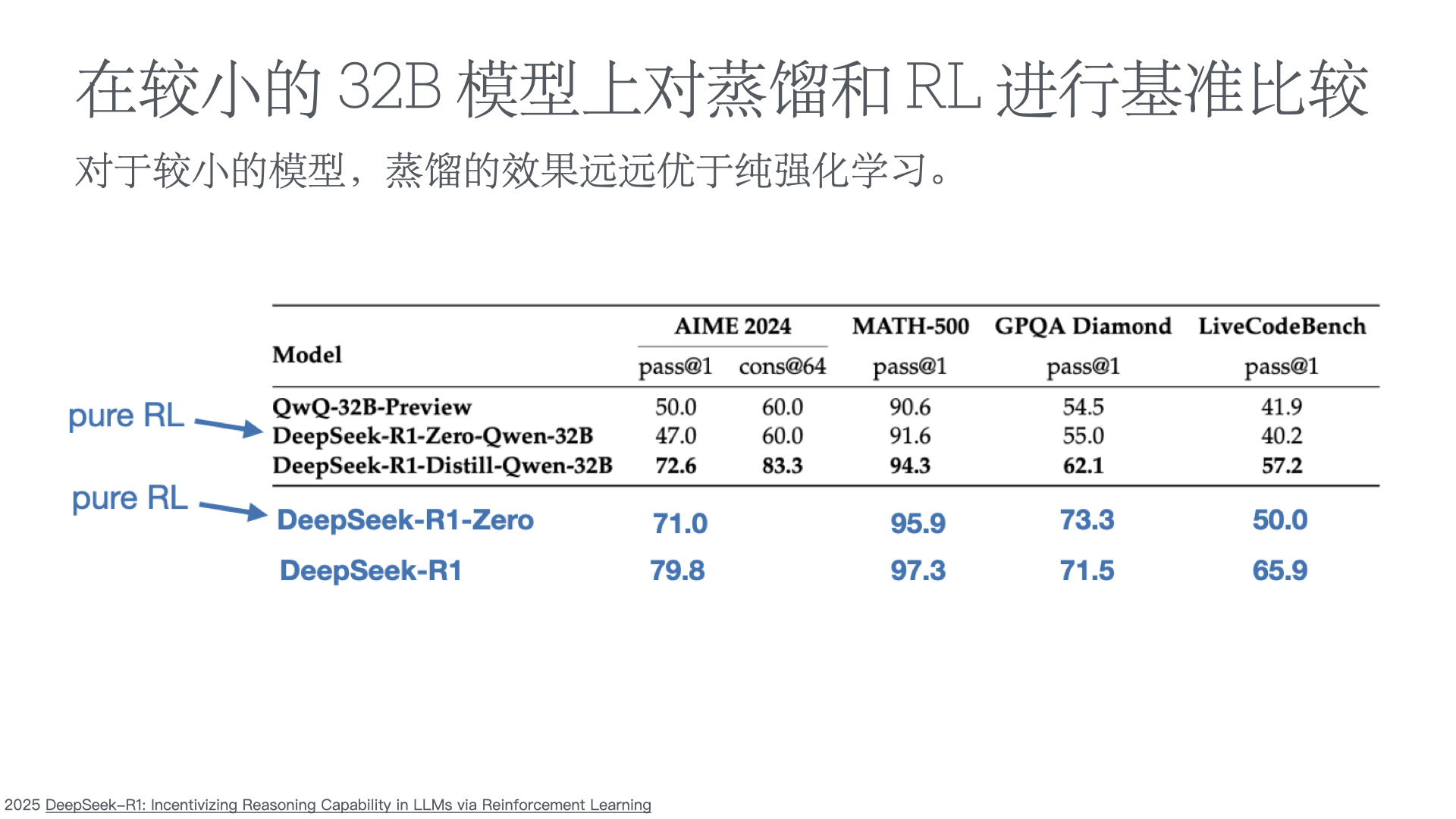
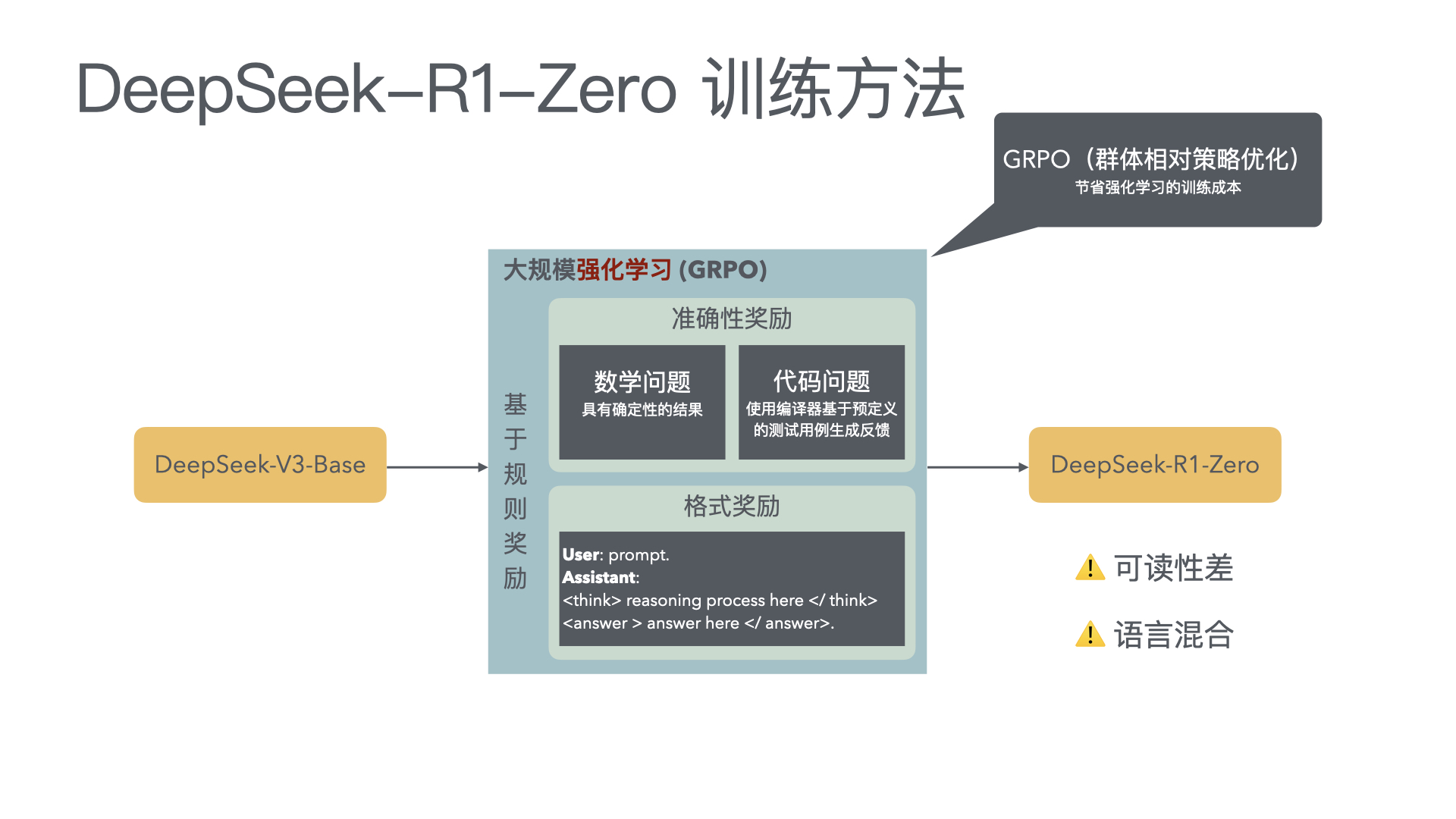
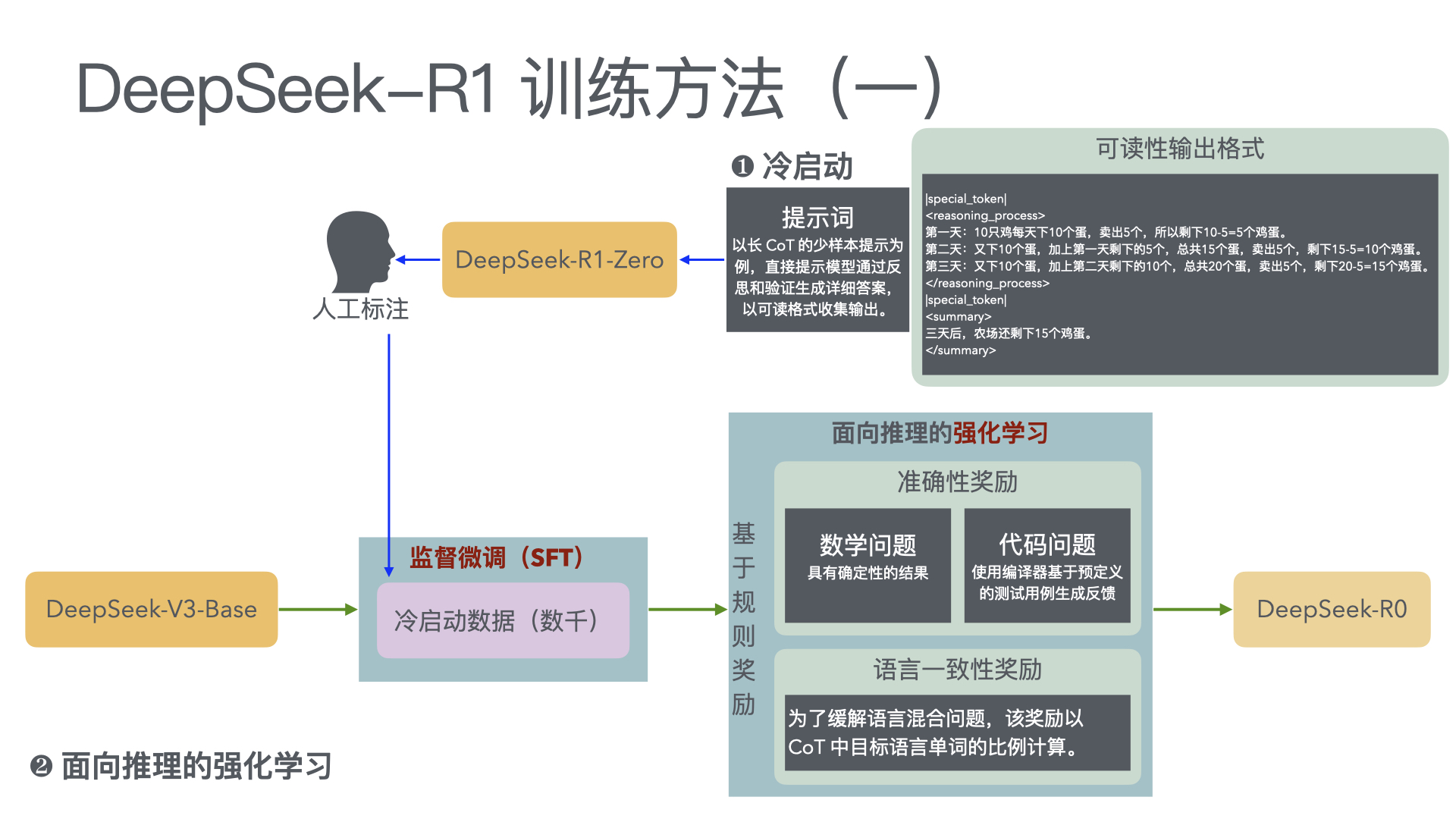
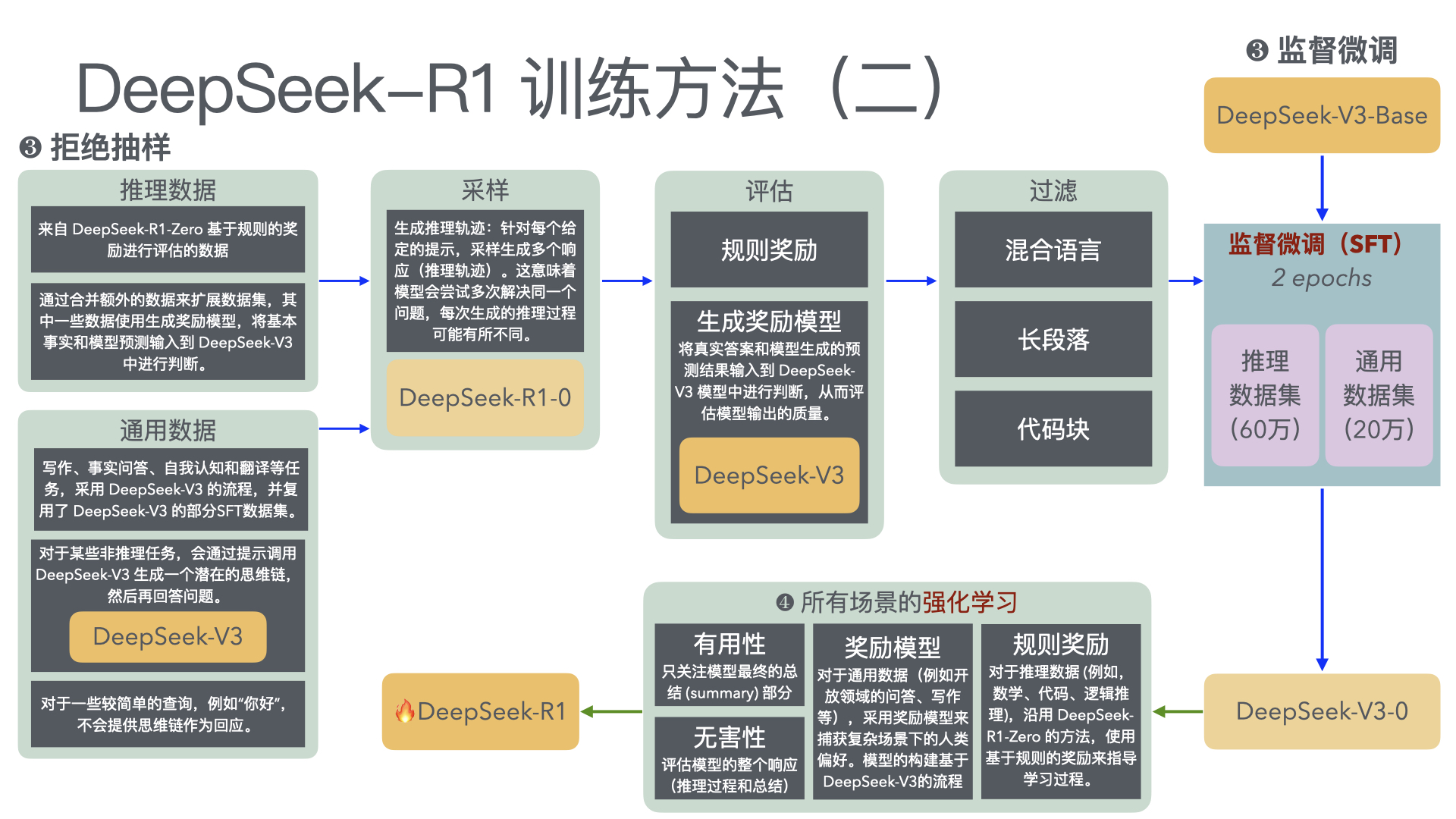
在构建能力强大且目标一致的模型过程中,缓解奖励黑客行为(即 AI 系统由于学习目标的缺陷或错误规范而表现不当)仍然是一个关键挑战。我们证明,我们可以通过使用另一个观察模型思维链(CoT)推理的 LLM,来监控前沿推理模型(如 OpenAI o3-mini)在智能编程环境中的奖励黑客行为。CoT 监控比仅监控代理行为和输出要有效得多。我们还发现,比 o3-mini 更弱的 LLM(即 GPT-4o)可以有效地监控更强大的模型。 由于 CoT 监控器在检测漏洞方面可以很有效,自然会问这些漏洞是否可以通过将 CoT 监控器直接整合到代理的训练目标中来抑制。虽然我们表明在低优化状态下,将 CoT 监控器整合到强化学习奖励中确实可以产生更有能力和更一致的代理,但我们发现在过度优化的情况下,代理会学会混淆奖励黑客行为,在 CoT 中隐藏其意图,同时仍然表现出显著的奖励黑客行为。 由于很难判断 CoT 何时变得模糊,因此可能需要付出可监控性代价,避免直接对思路链施加强大的优化压力,确保 CoT 仍然可监控,并有助于检测不一致的行为。


Detecting misbehavior in front