推理 LLM 技术内幕 - DeepSeek-R1/o1





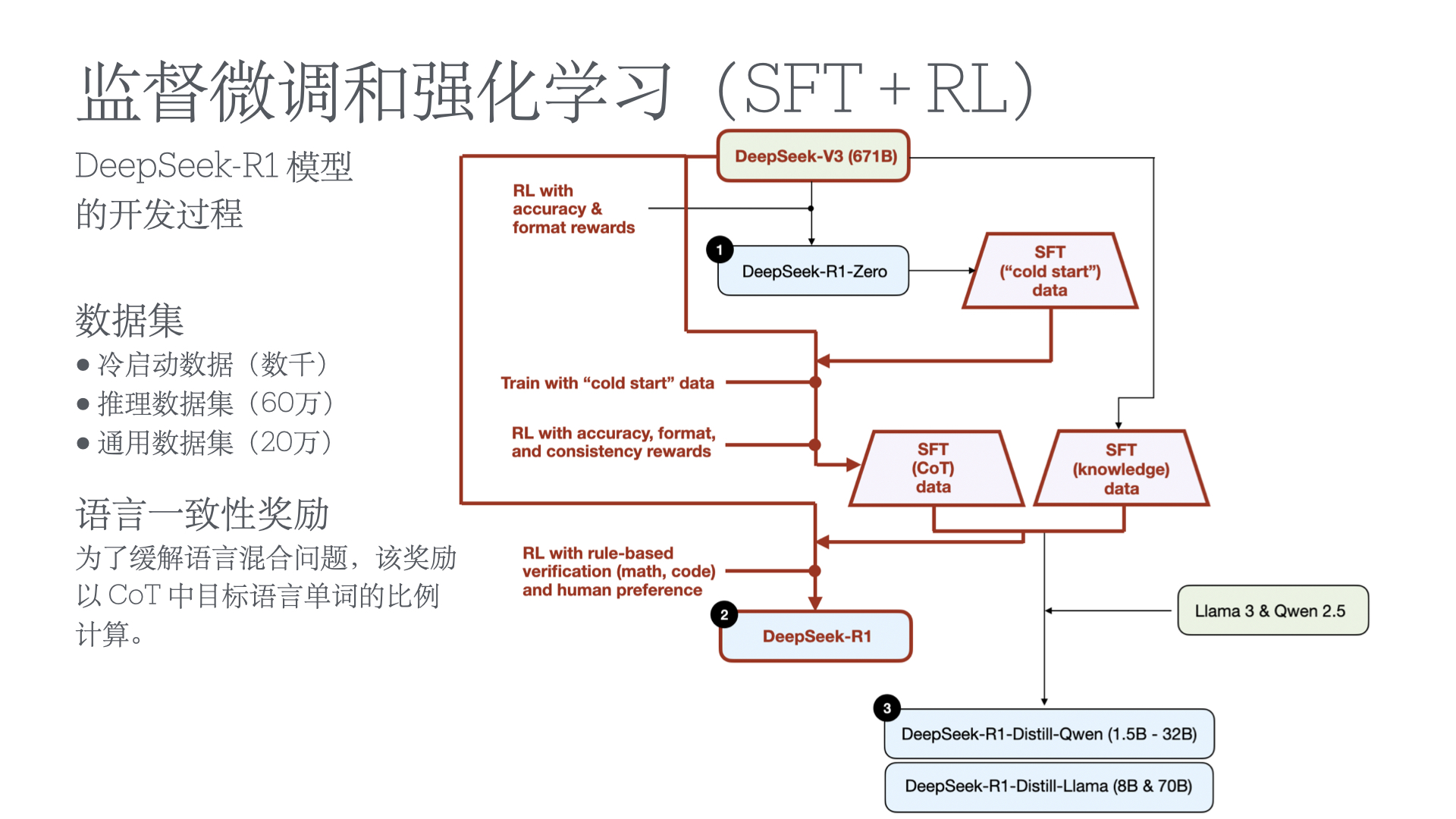
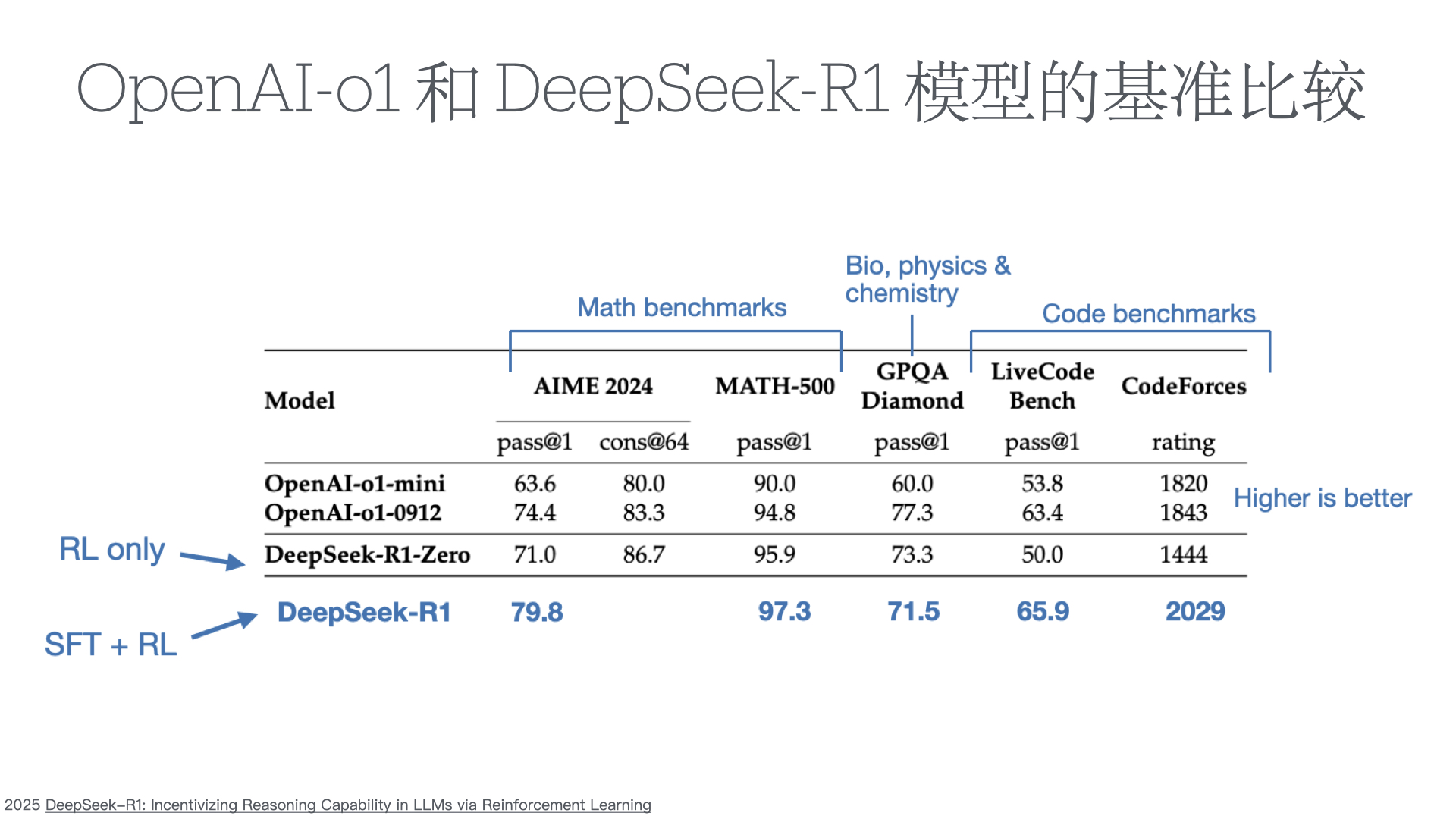
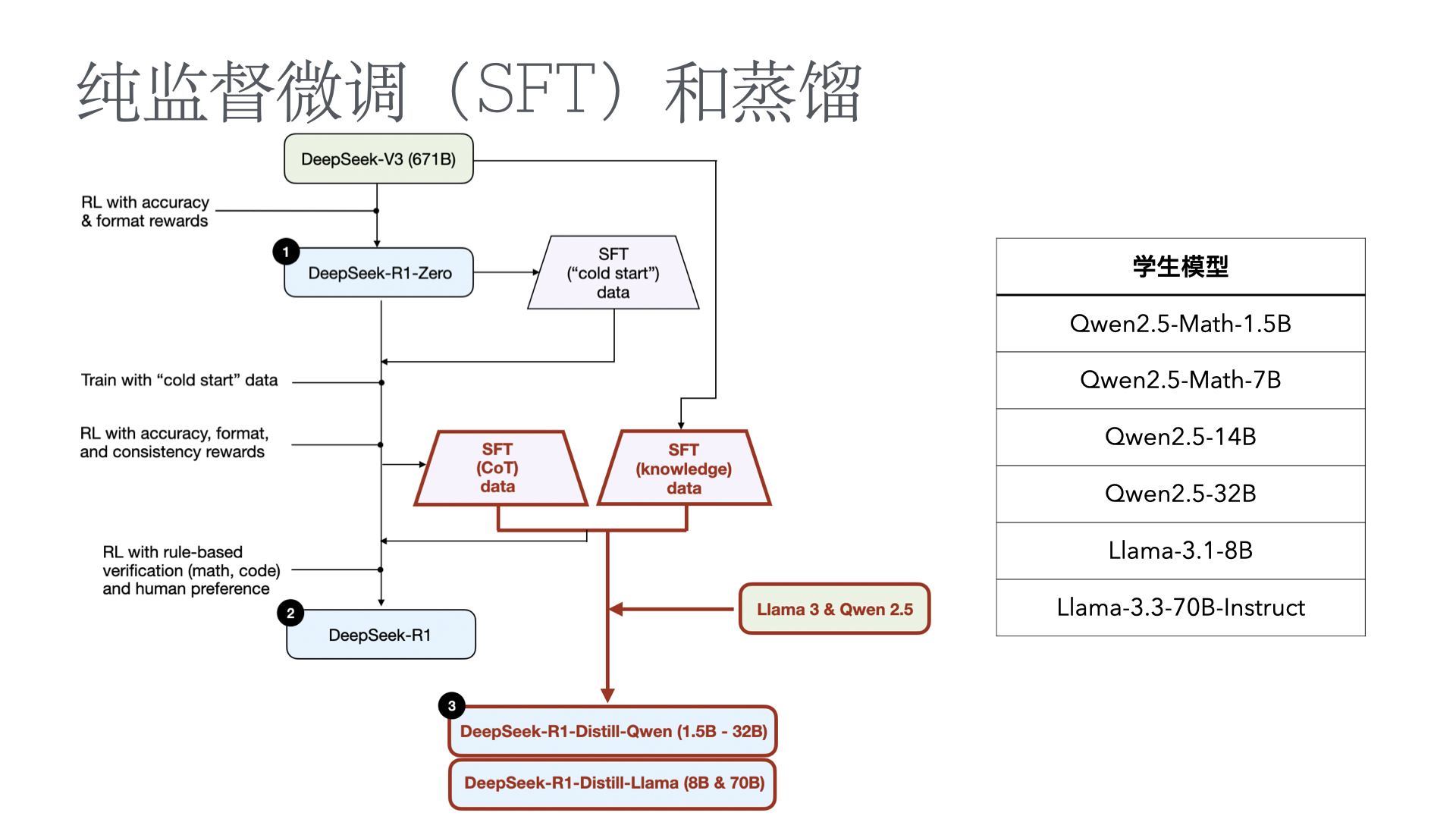
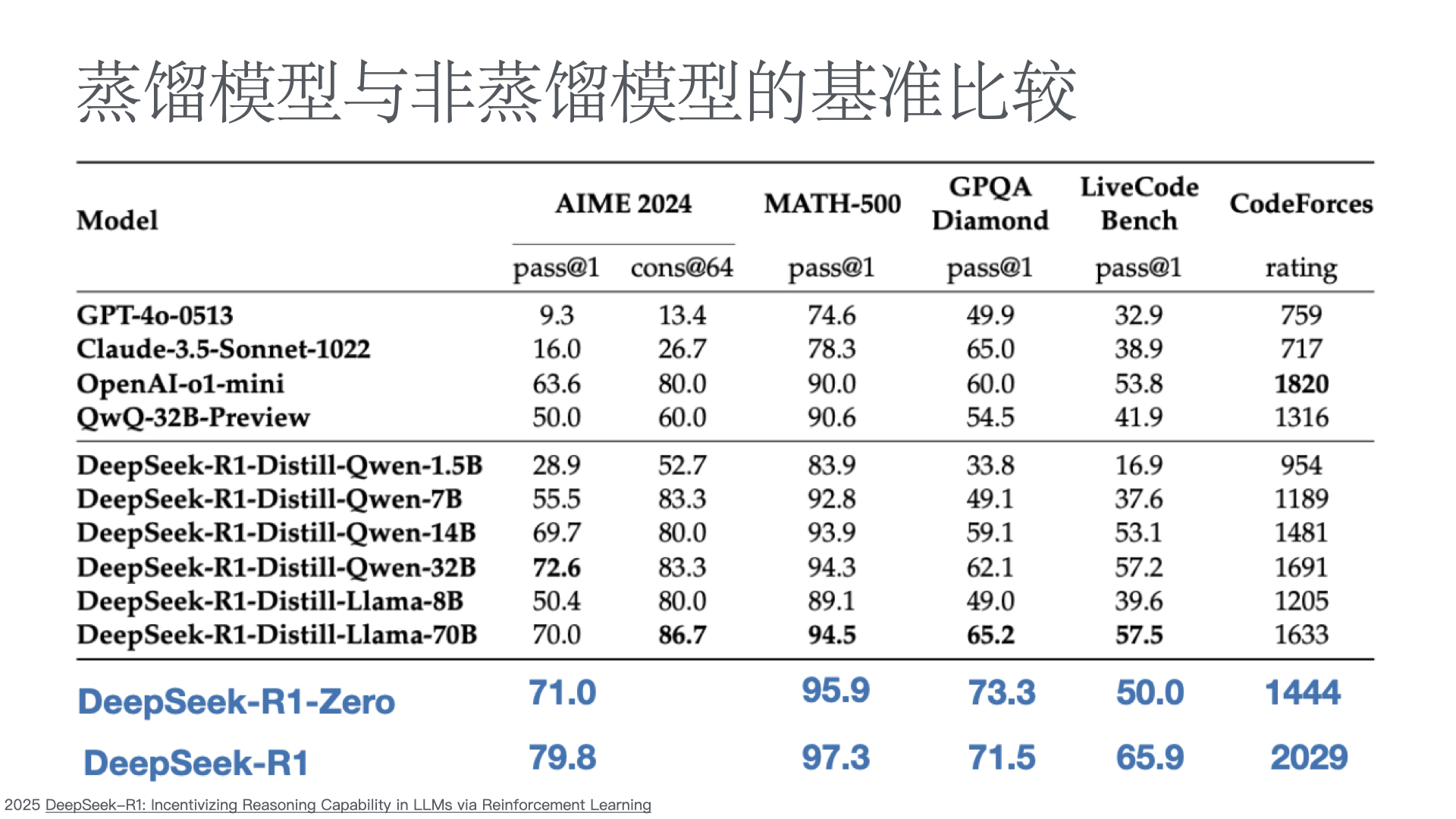


- Understanding Reasoning LLMs
- Sebastian Raschka:关于DeepSeek R1和推理模型,我有几点看法
- Large Language Models are Zero-Shot Reasoners
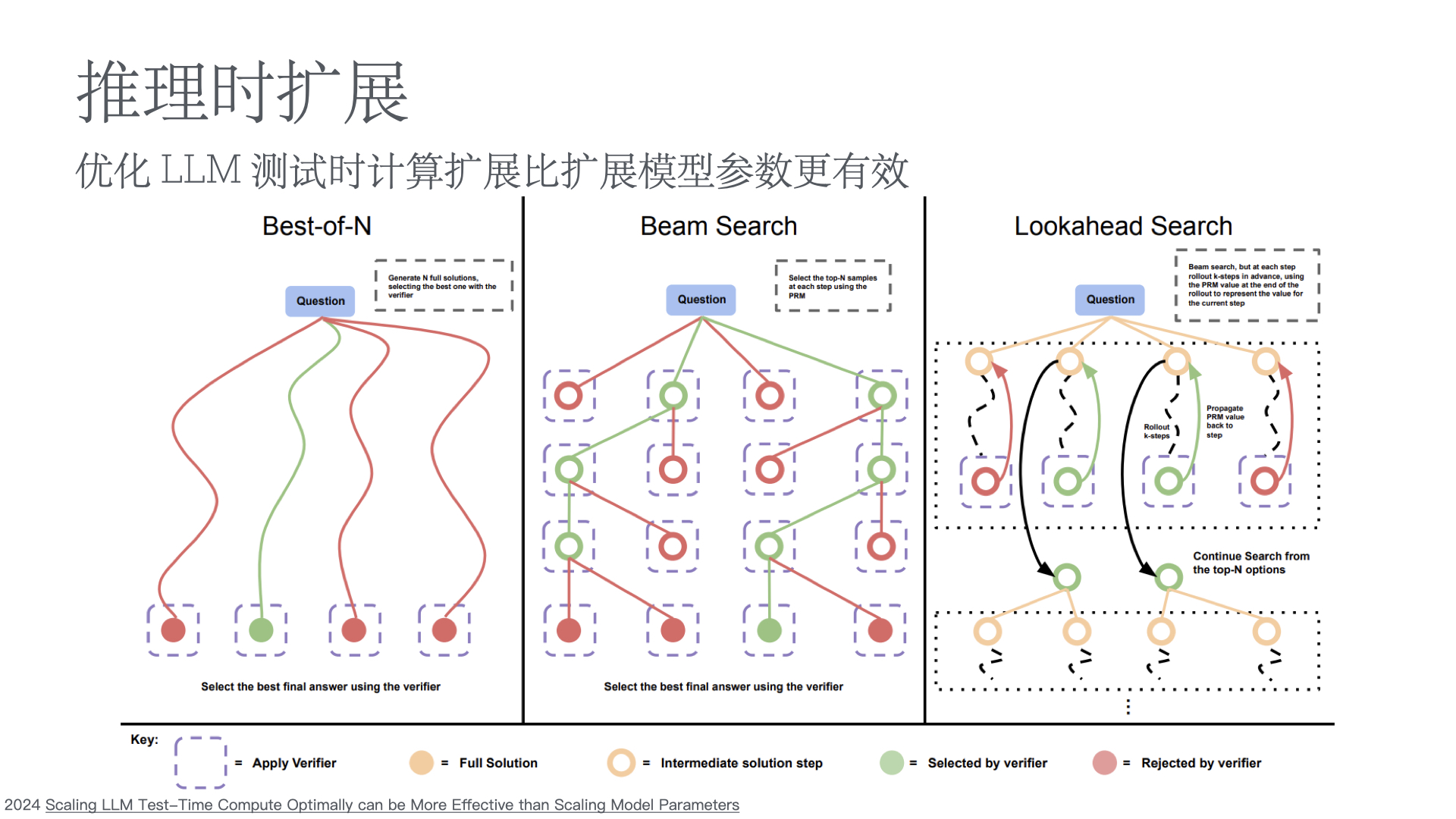
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- 04 论文 Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- 论文笔记:Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling
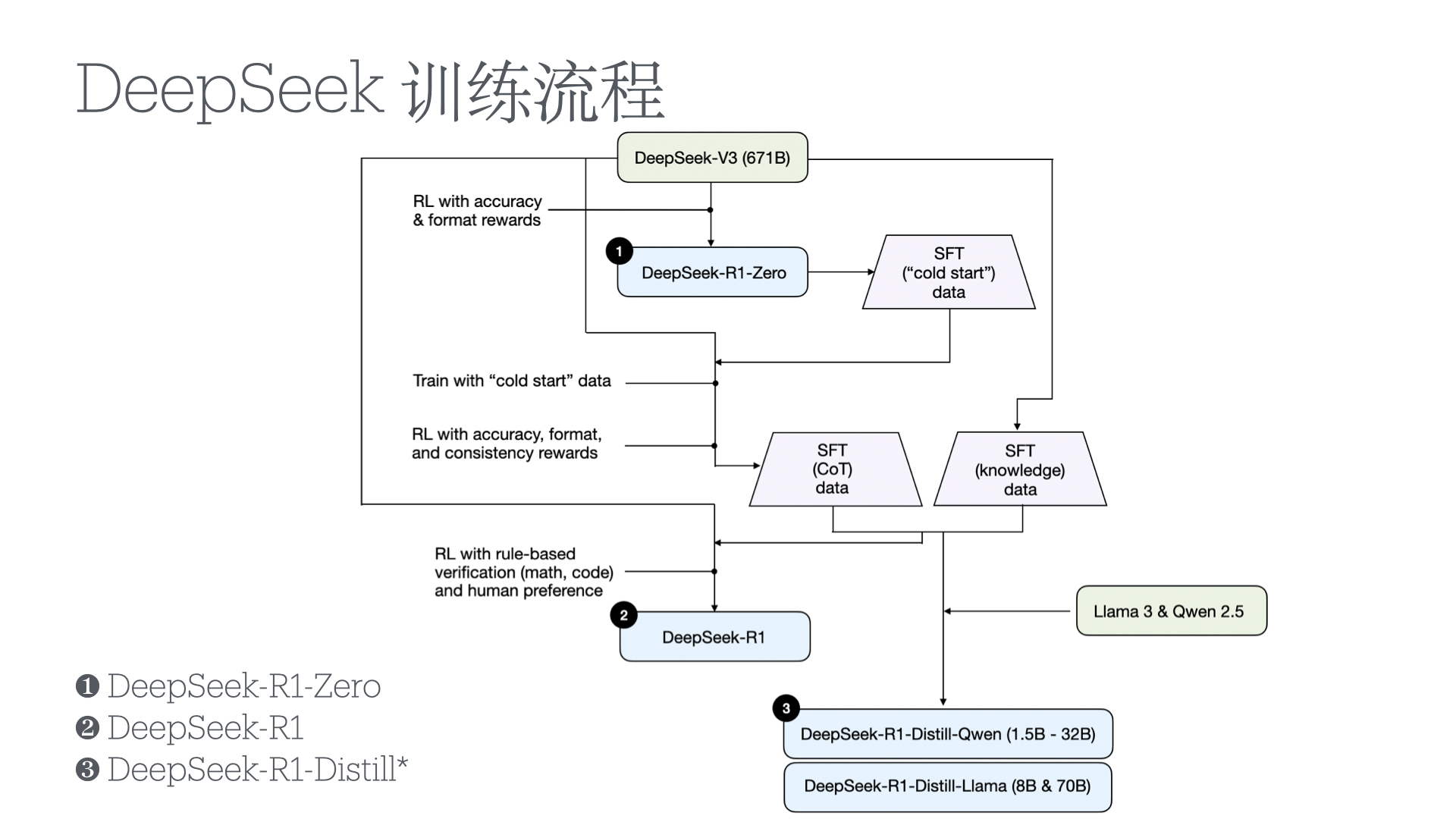
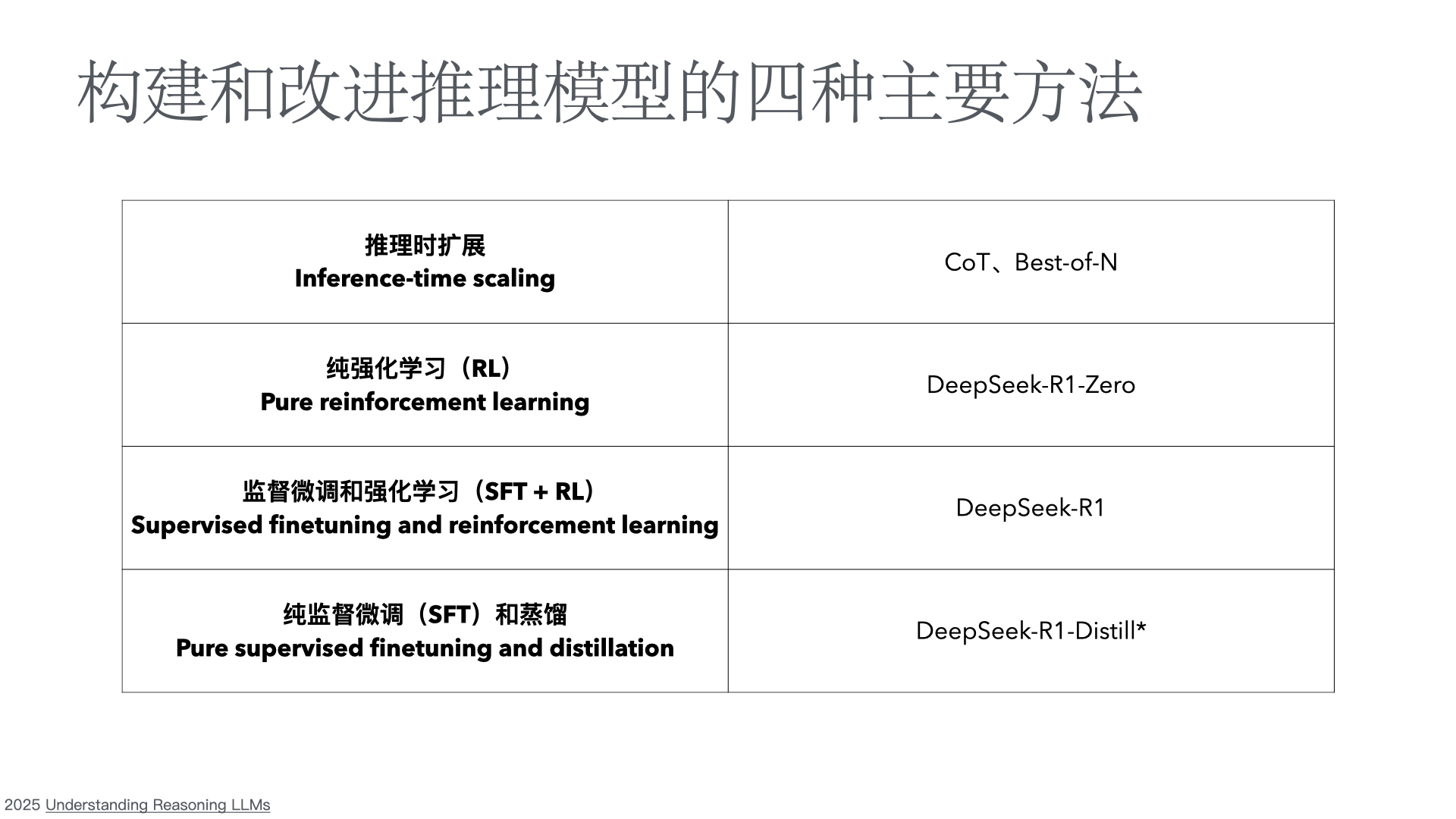
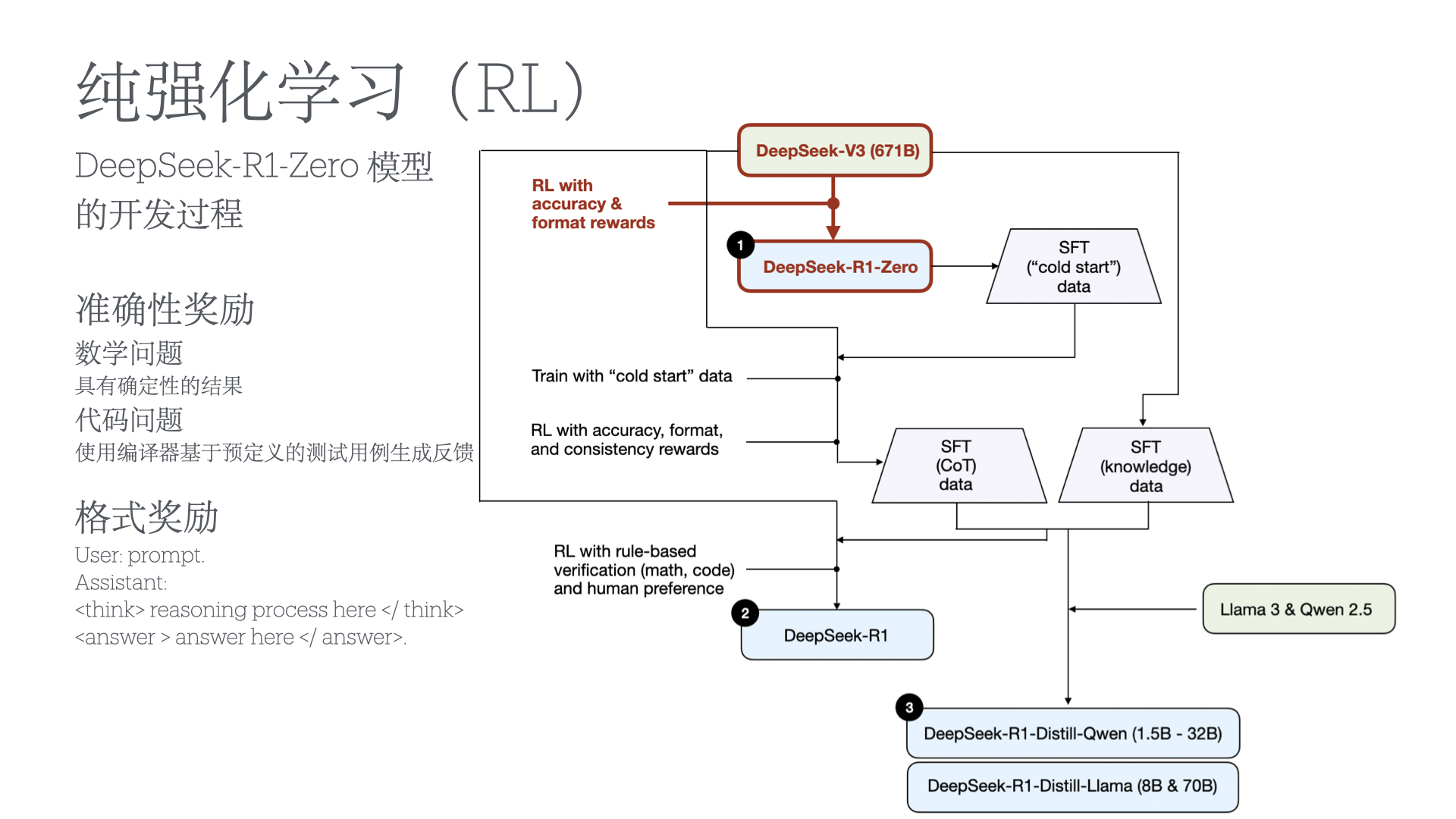
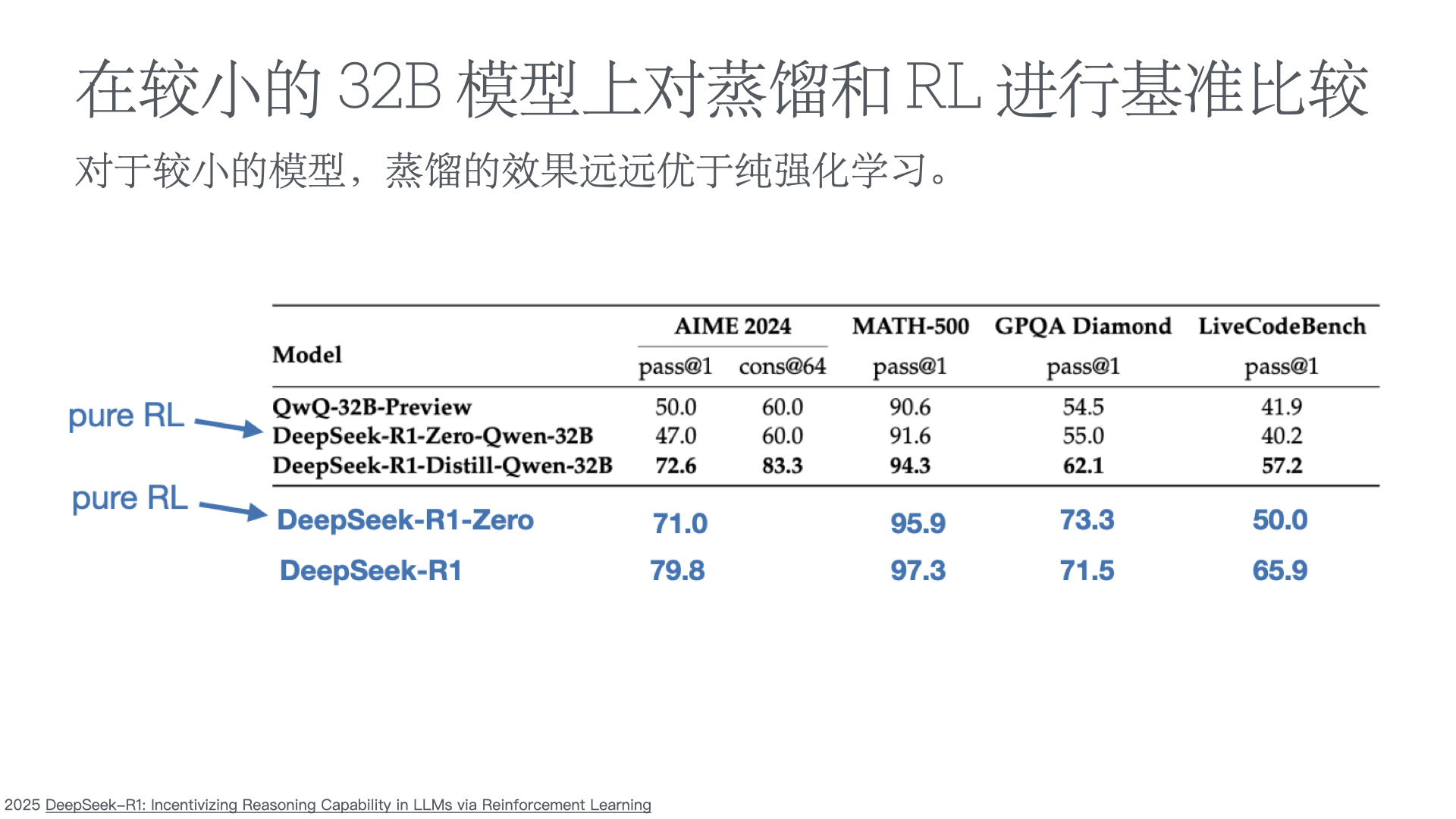
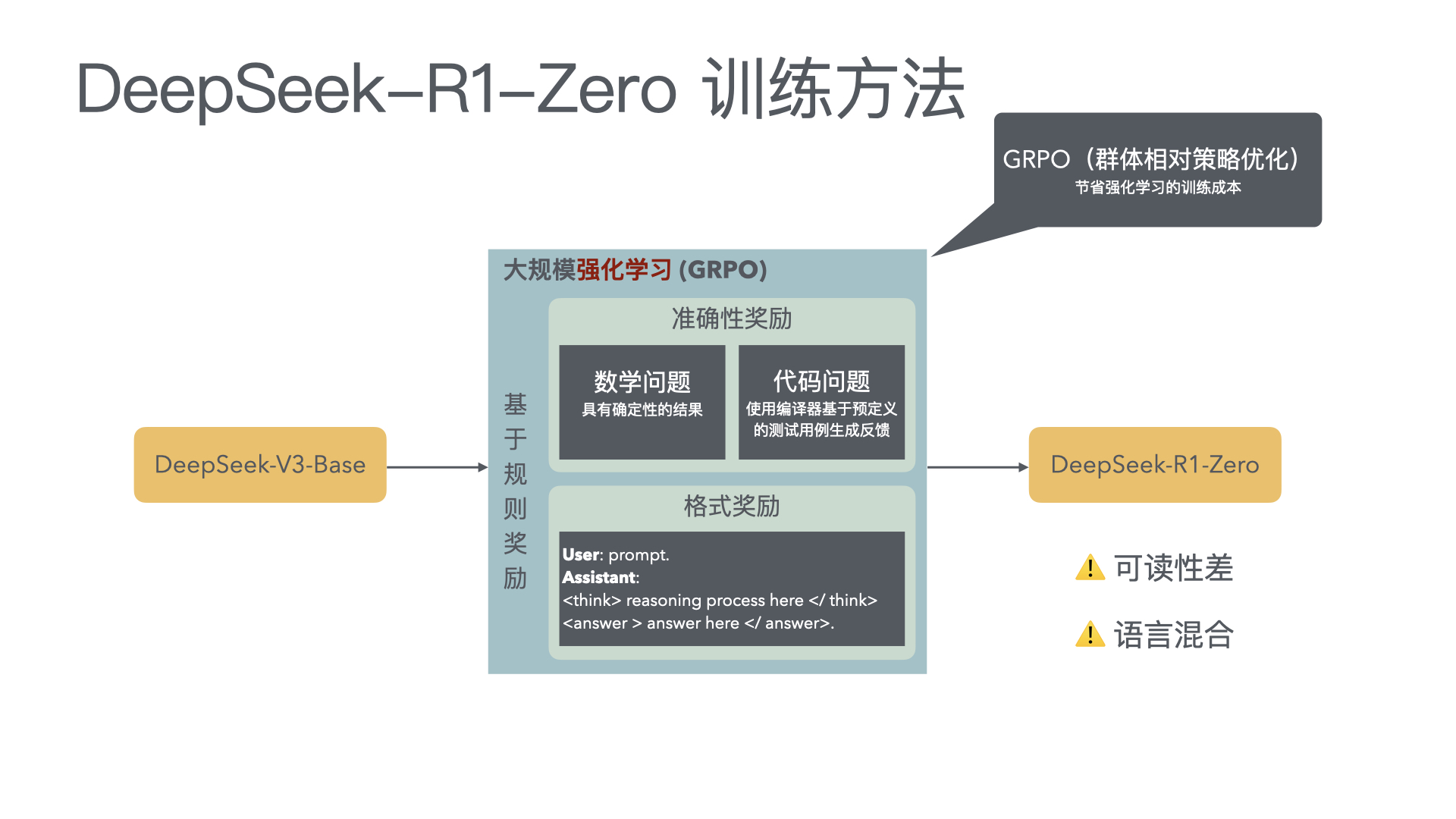
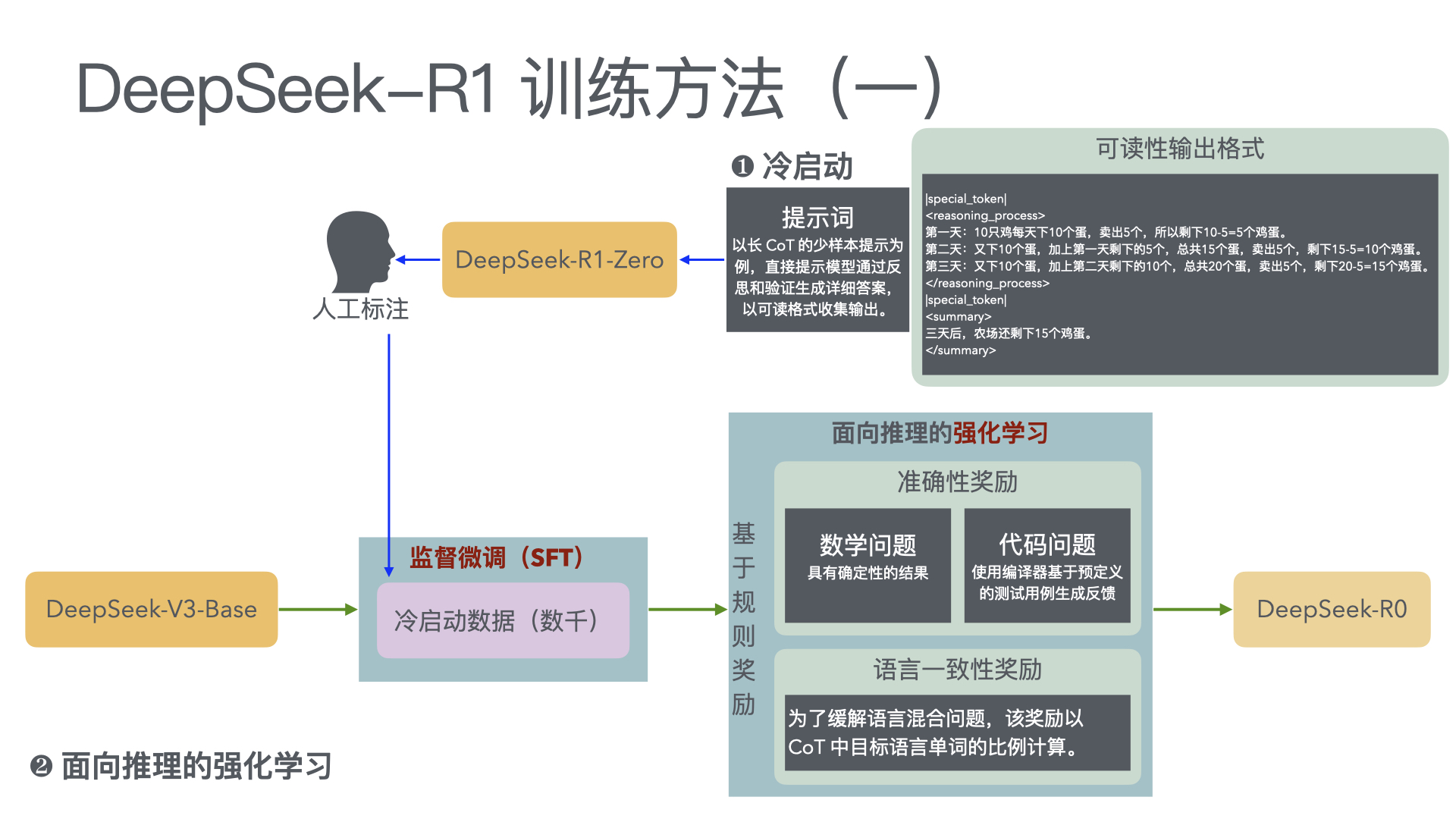
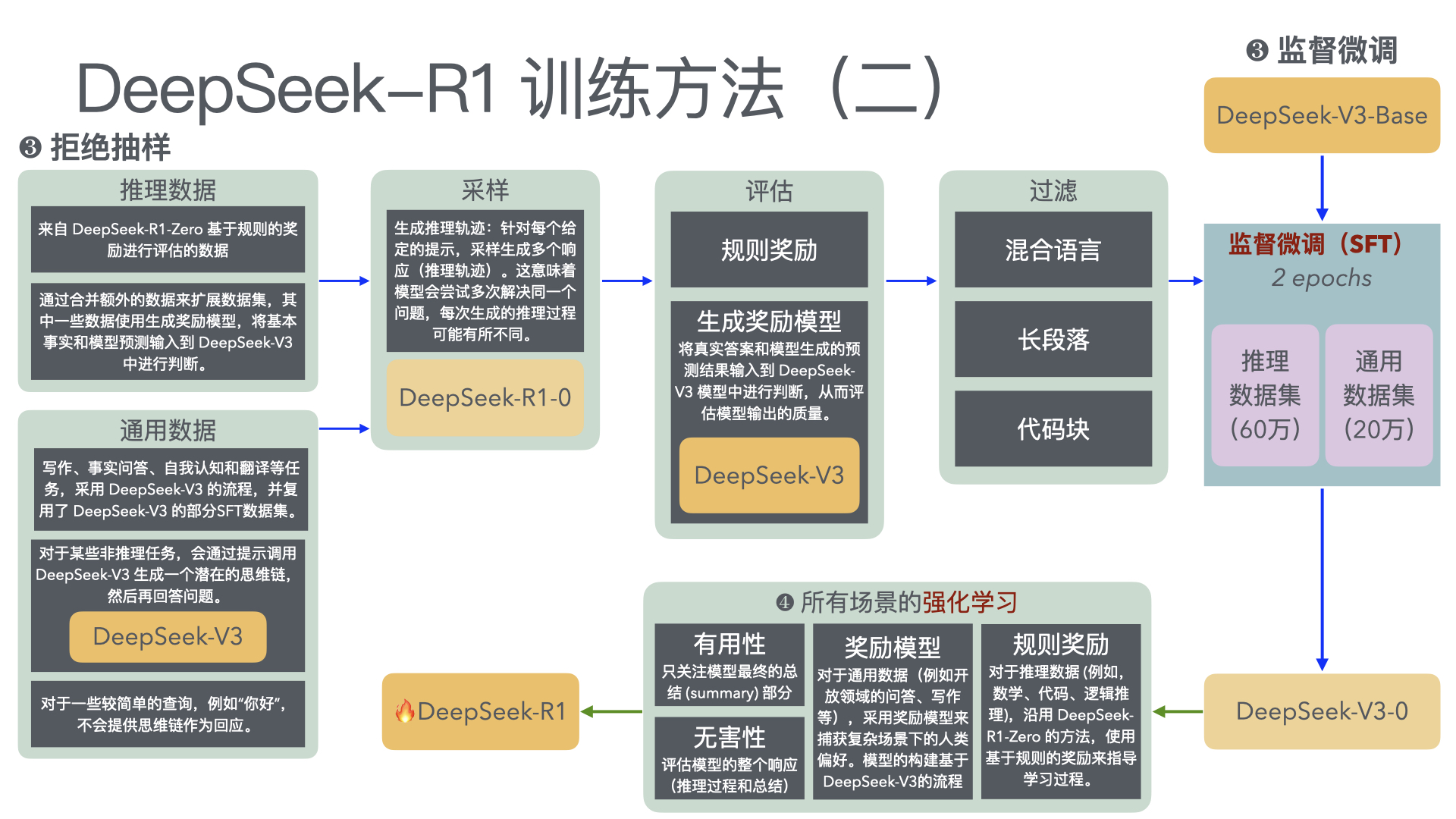
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning