提升 LLM 推理能力:CoT, ReAct, ToT
总结

在构建能力强大且目标一致的模型过程中,缓解奖励黑客行为(即 AI 系统由于学习目标的缺陷或错误规范而表现不当)仍然是一个关键挑战。我们证明,我们可以通过使用另一个观察模型思维链(CoT)推理的 LLM,来监控前沿推理模型(如 OpenAI o3-mini)在智能编程环境中的奖励黑客行为。CoT 监控比仅监控代理行为和输出要有效得多。我们还发现,比 o3-mini 更弱的 LLM(即 GPT-4o)可以有效地监控更强大的模型。 由于 CoT 监控器在检测漏洞方面可以很有效,自然会问这些漏洞是否可以通过将 CoT 监控器直接整合到代理的训练目标中来抑制。虽然我们表明在低优化状态下,将 CoT 监控器整合到强化学习奖励中确实可以产生更有能力和更一致的代理,但我们发现在过度优化的情况下,代理会学会混淆奖励黑客行为,在 CoT 中隐藏其意图,同时仍然表现出显著的奖励黑客行为。 由于很难判断 CoT 何时变得模糊,因此可能需要付出可监控性代价,避免直接对思路链施加强大的优化压力,确保 CoT 仍然可监控,并有助于检测不一致的行为。


Detecting misbehavior in front
大型语言模型(LLM)的工作原理根植于模式匹配和对下一个词元的统计预测("随机鹦鹉")。从这种方法中产生的一个有些出人意料的能力是它们也能在一定程度上"推理"解决问题。有些模型的推理能力比其他模型更强,OpenAI的"o1"和"o3"模型是两个突出的推理模型,而DeepSeek的"R1"最近引起了很大轰动。但是当我们在编码任务中使用AI时,这种能力发挥什么作用呢?
剧透提醒:我还没有答案!但我有问题和想法。
我将从两个方面开始讨论,这两个方面在我的理解中是推理能力的限制,而且这些限制在编码环境中是相关的。然后我将分享我的想法,即推理在哪些编码任务中可能有用,在哪些任务中可能没用。
上下文至关重要,尤其是对推理而言
苹果公司去年发表的一篇关于大型语言模型推理局限性的论文引起了广泛关注。作者引入了一个新的基准测试,用来测试LLM在"数学推理"方面的能力。他们的基准测试基于一个已有的包含小学数学问题的测试集。他们选取了100个问题,将其转化为带有变量占位符的模板,然后为每个模板创建了50个变体,形成了一个包含5,000个问题的数据集。在第二步中,他们还创建了一个新的数据集,在问题中添加了无关信息。
他们发现:



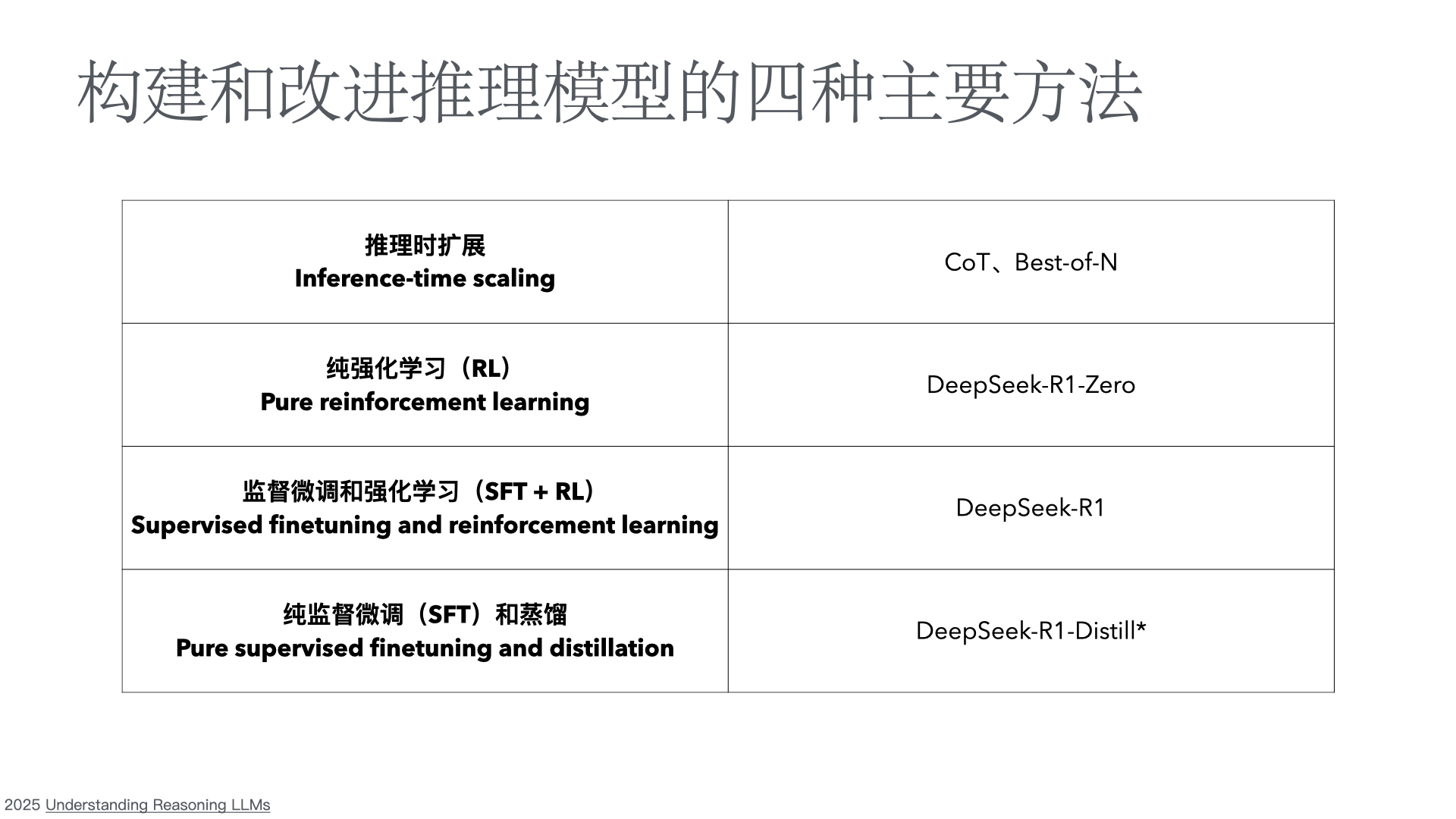

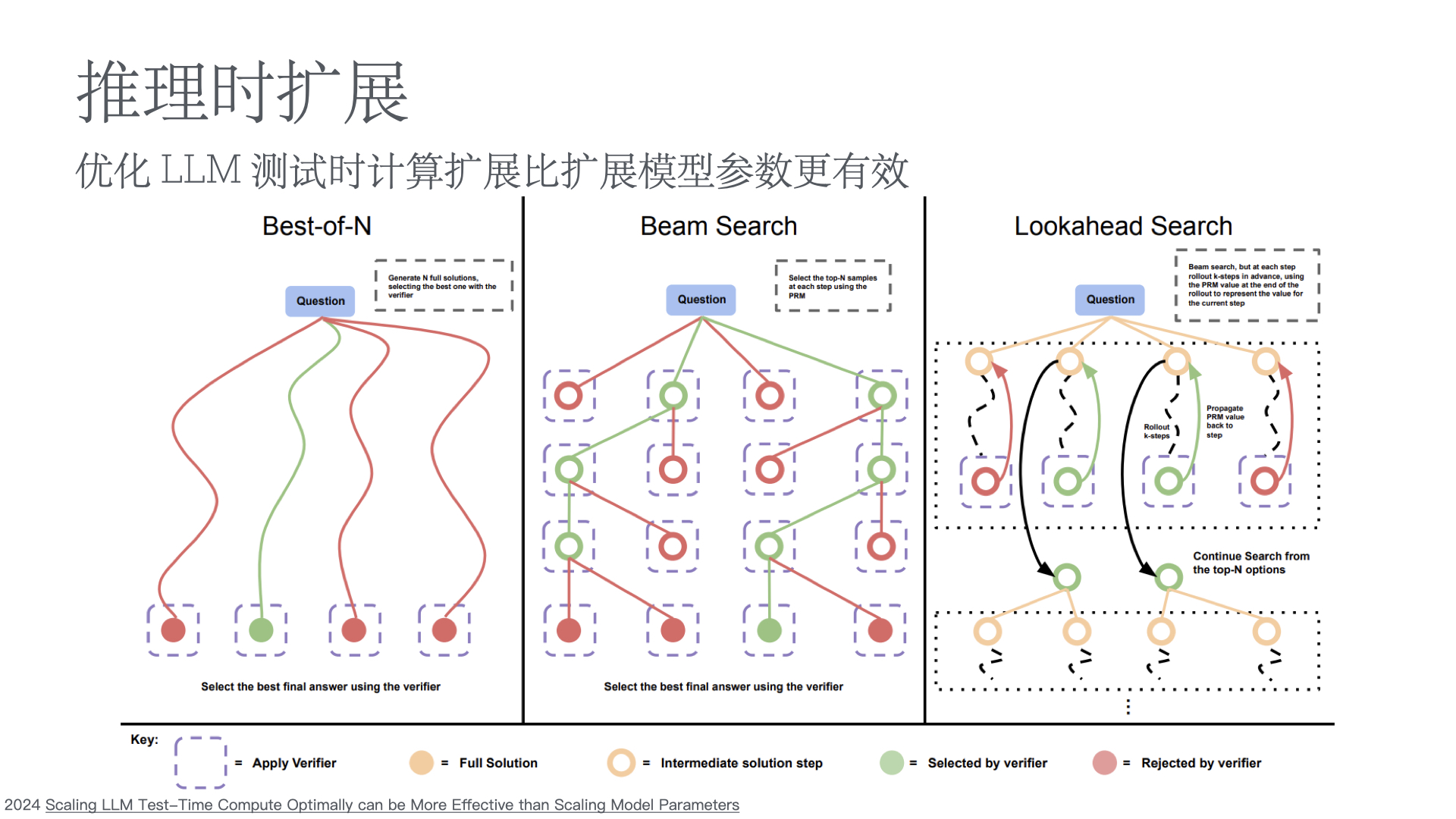
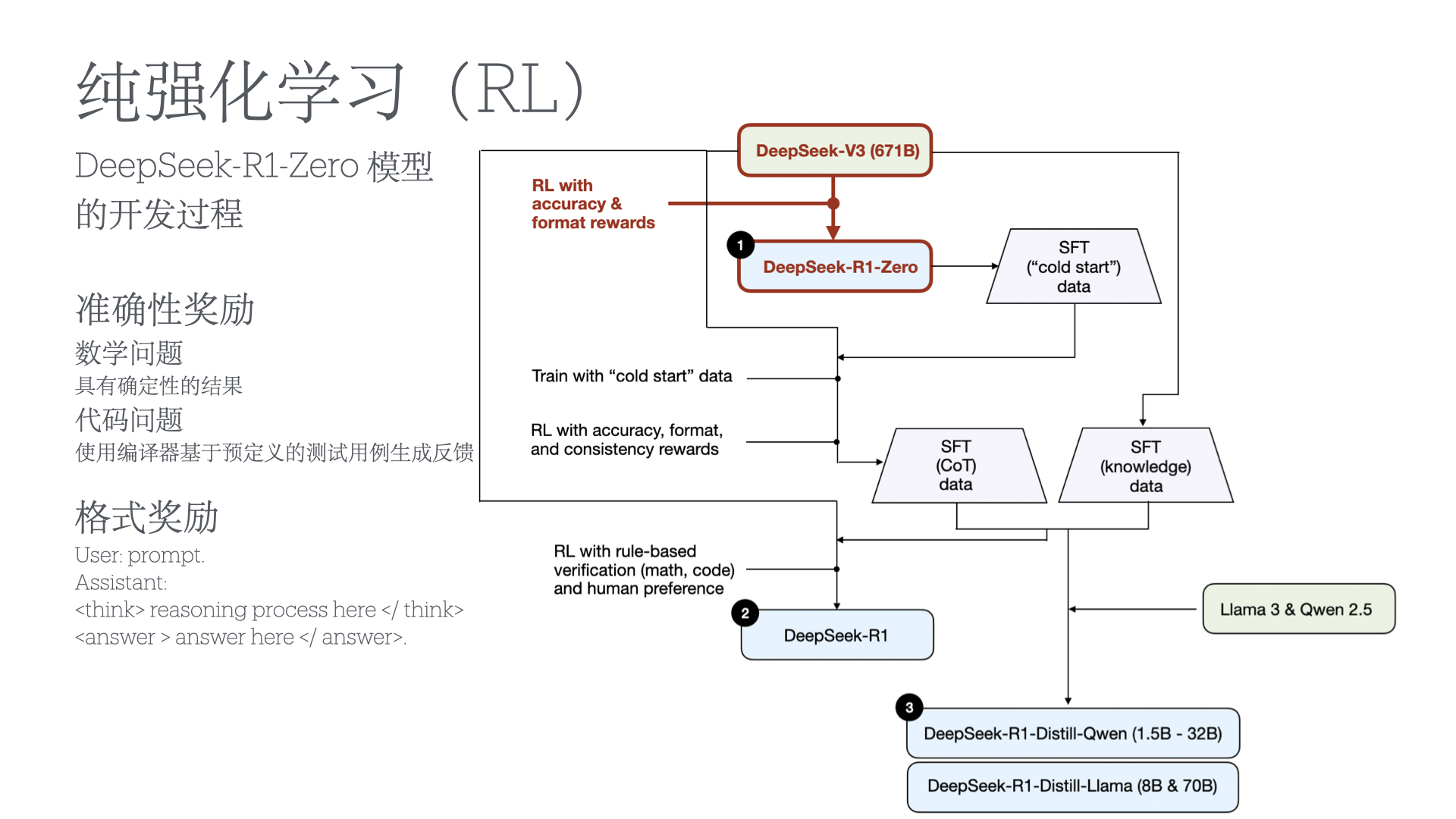

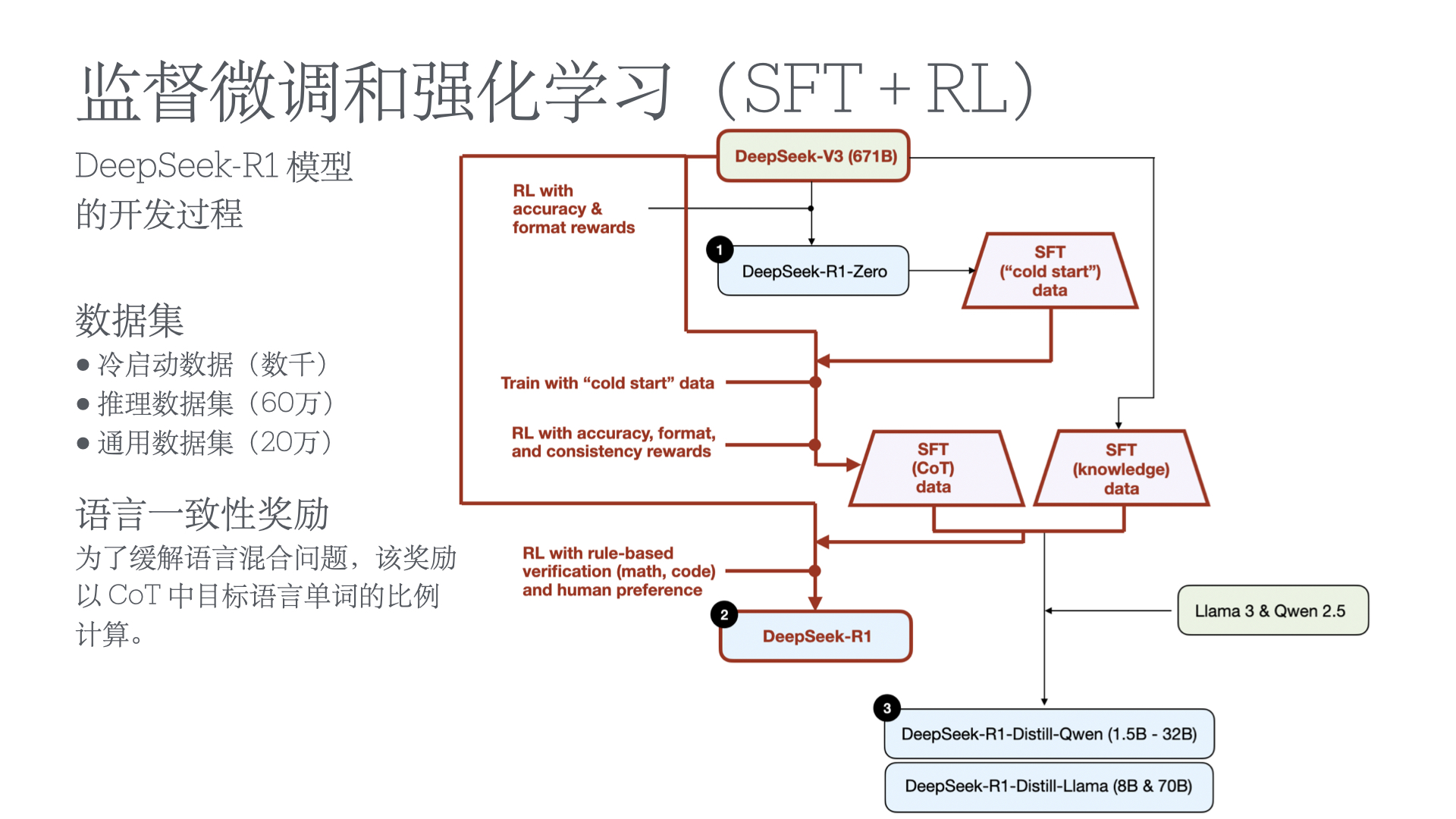


Abstract(摘要)
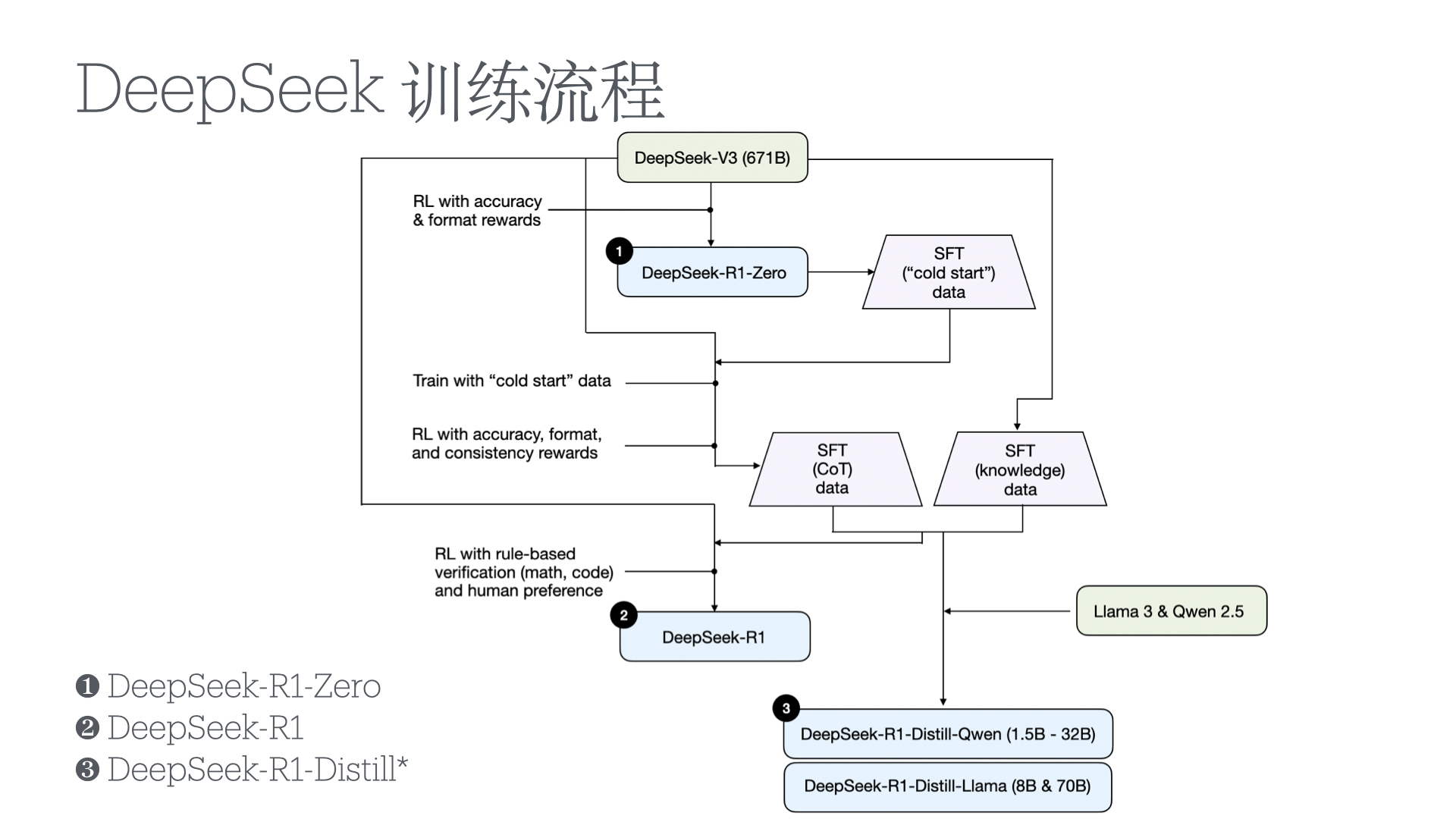
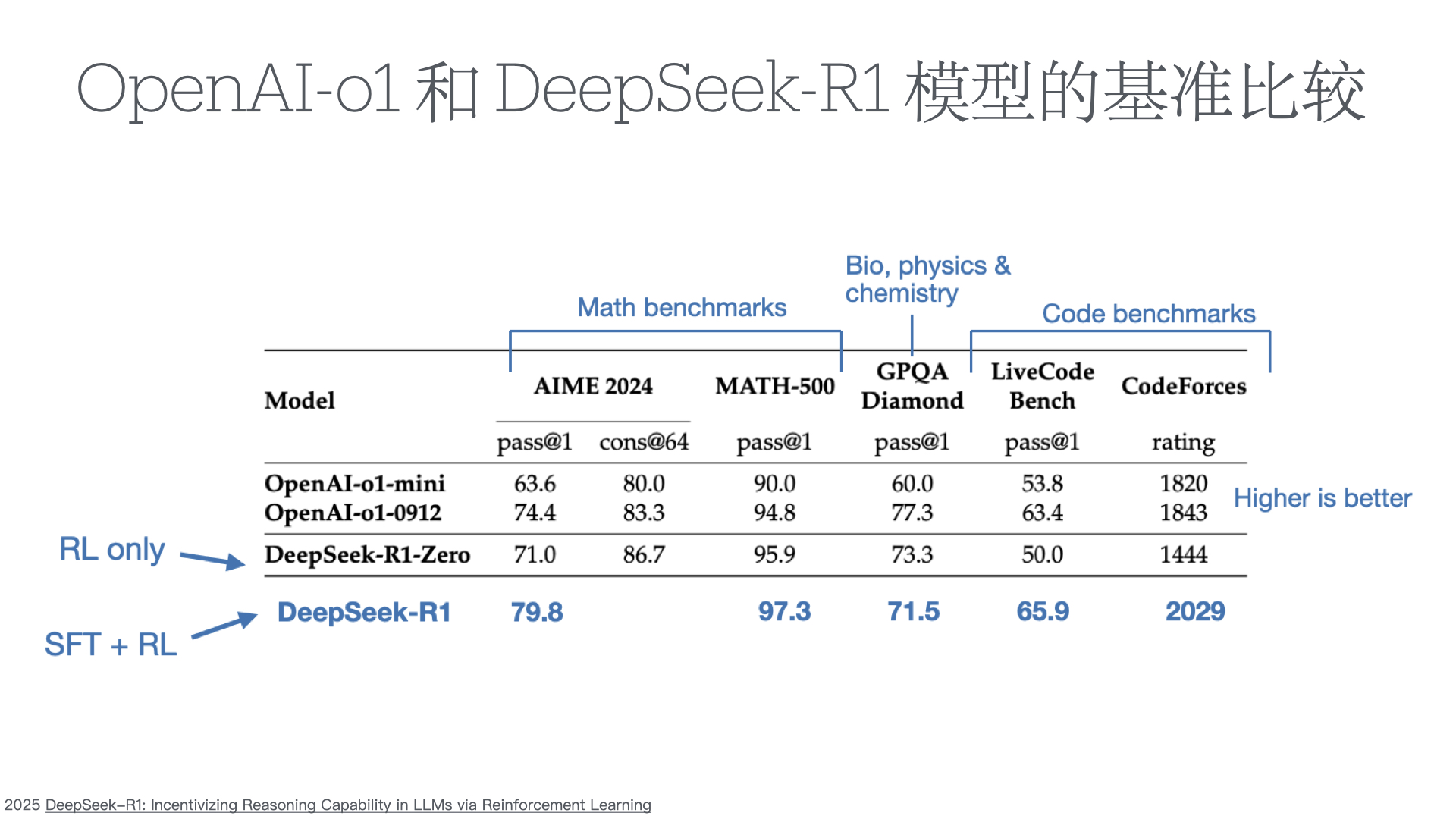
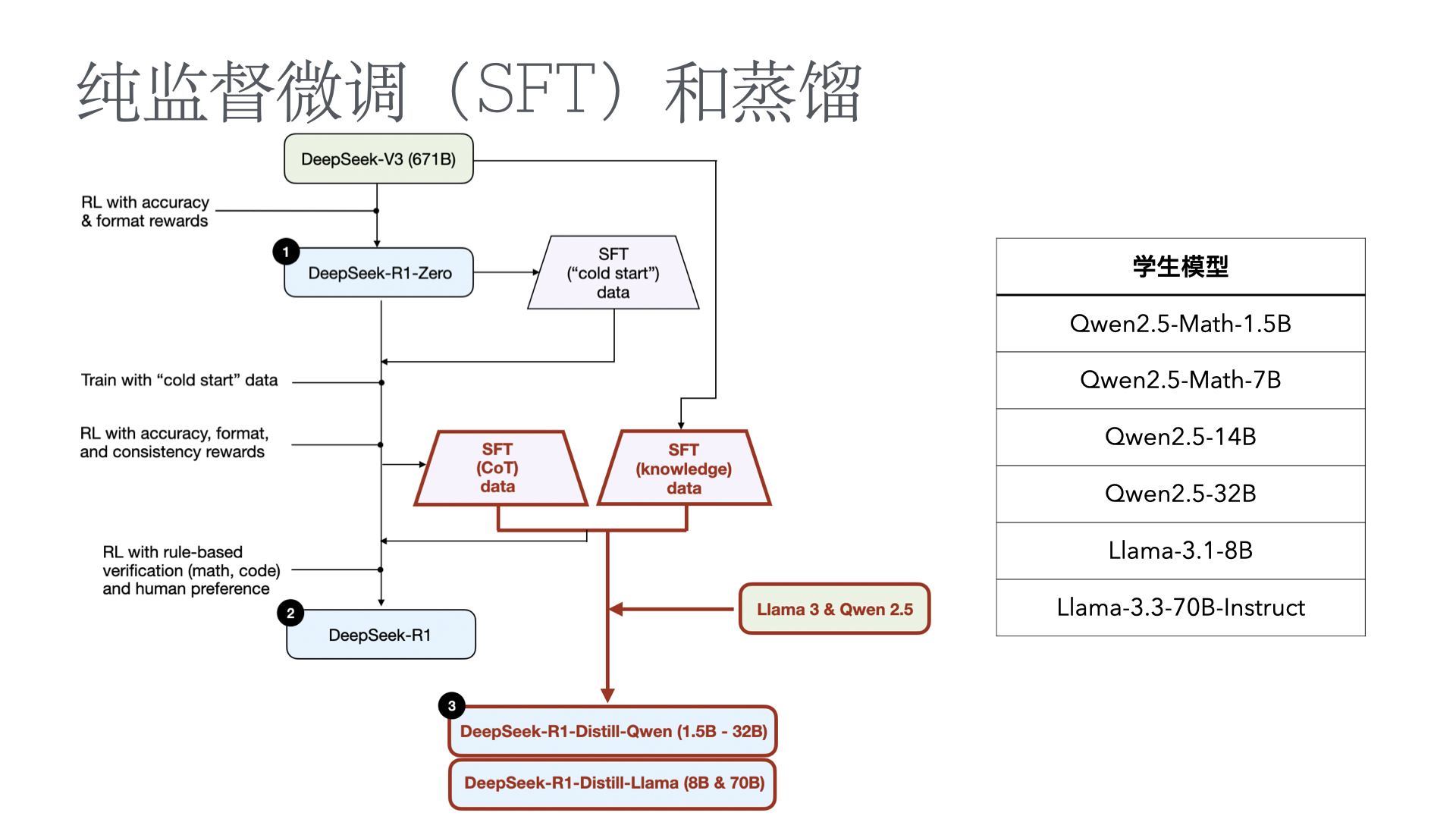
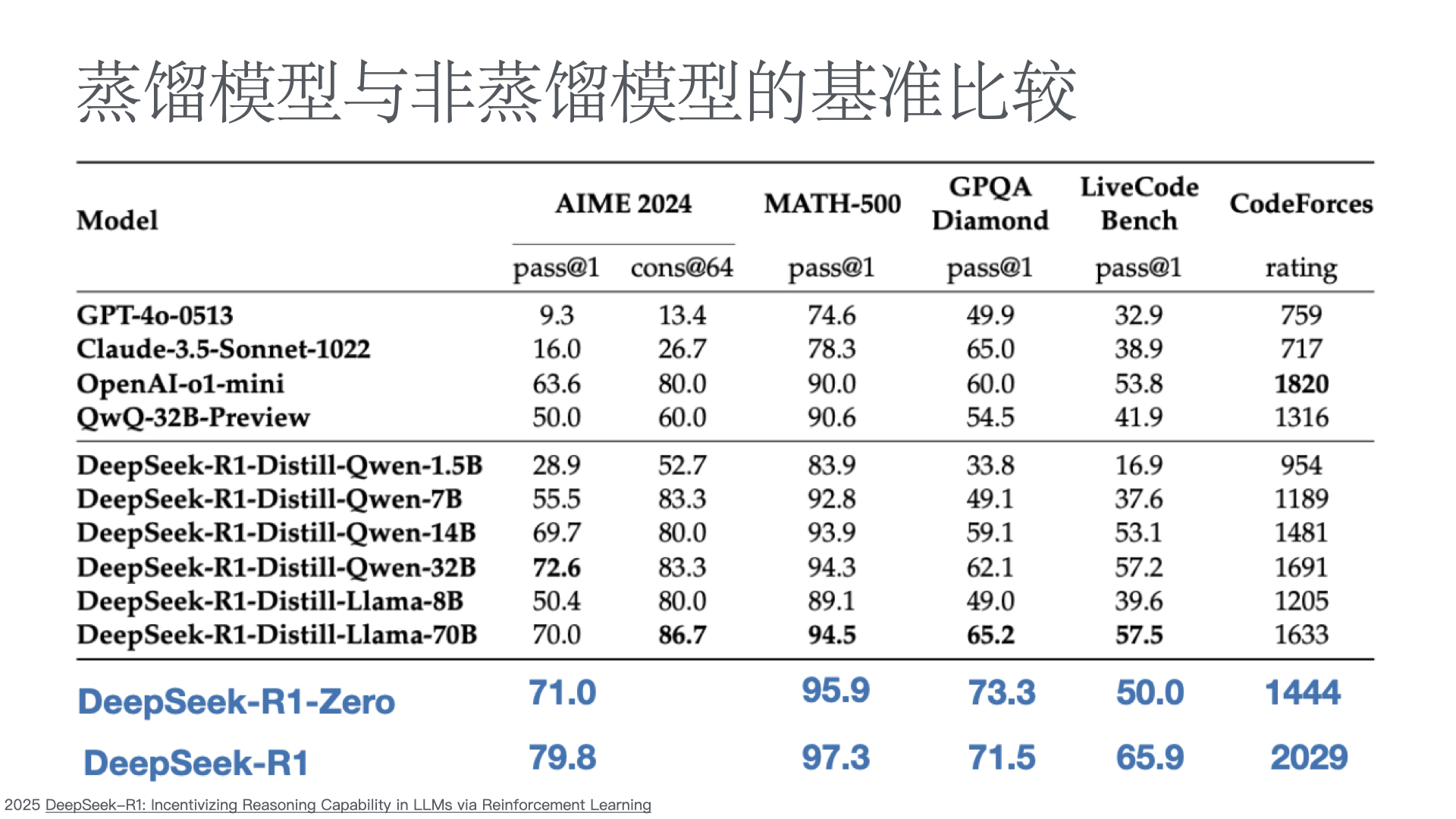
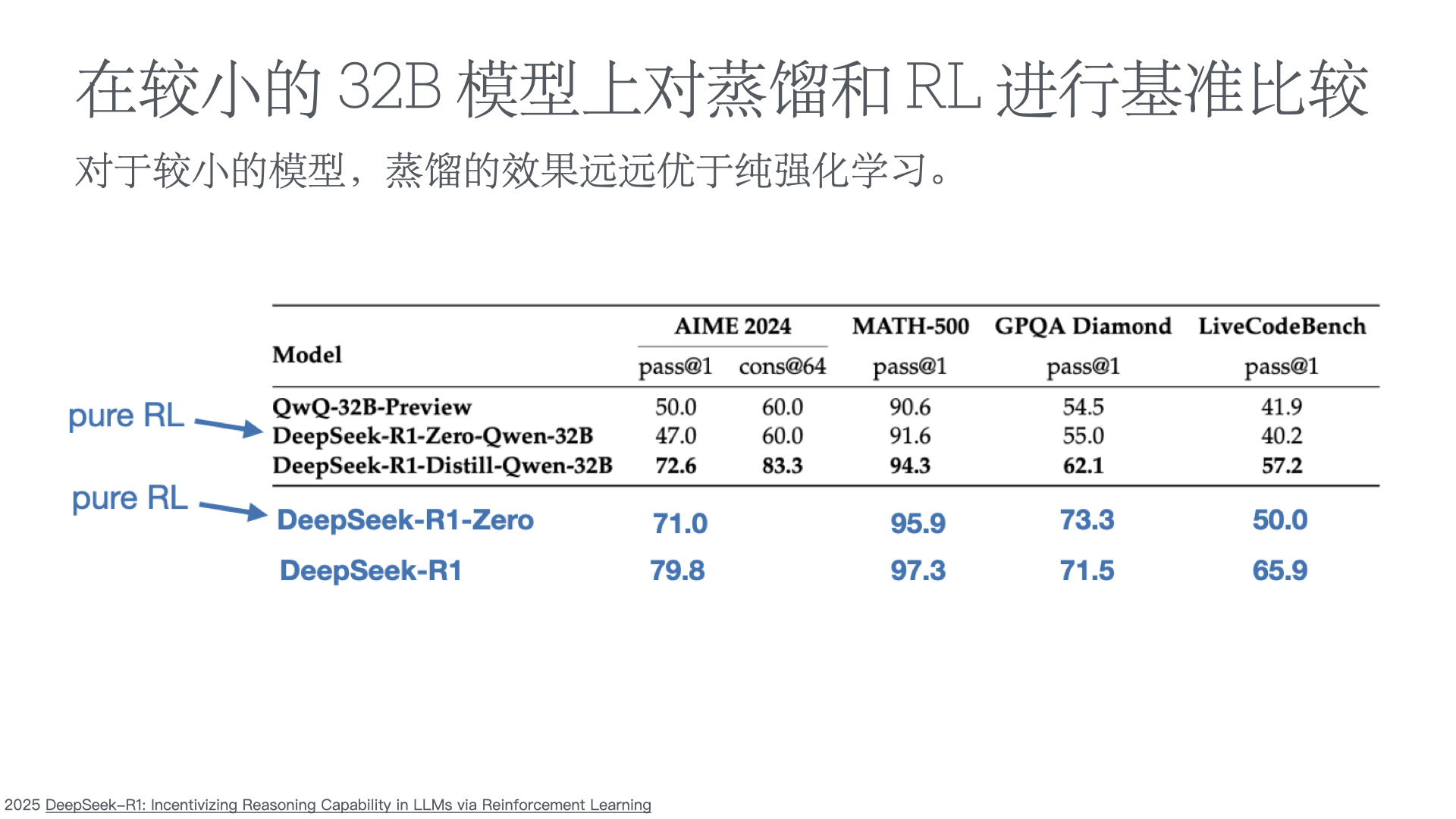
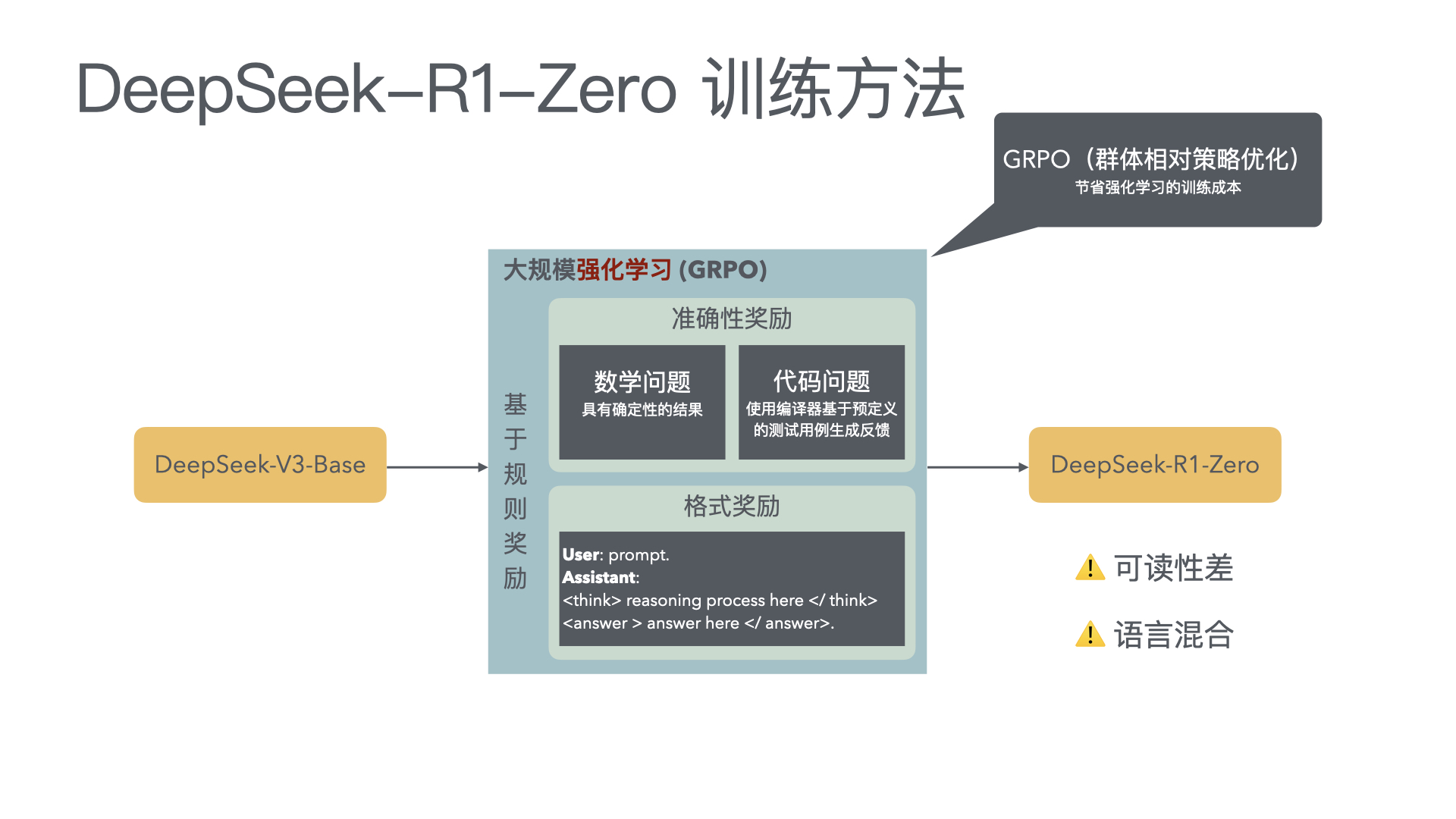
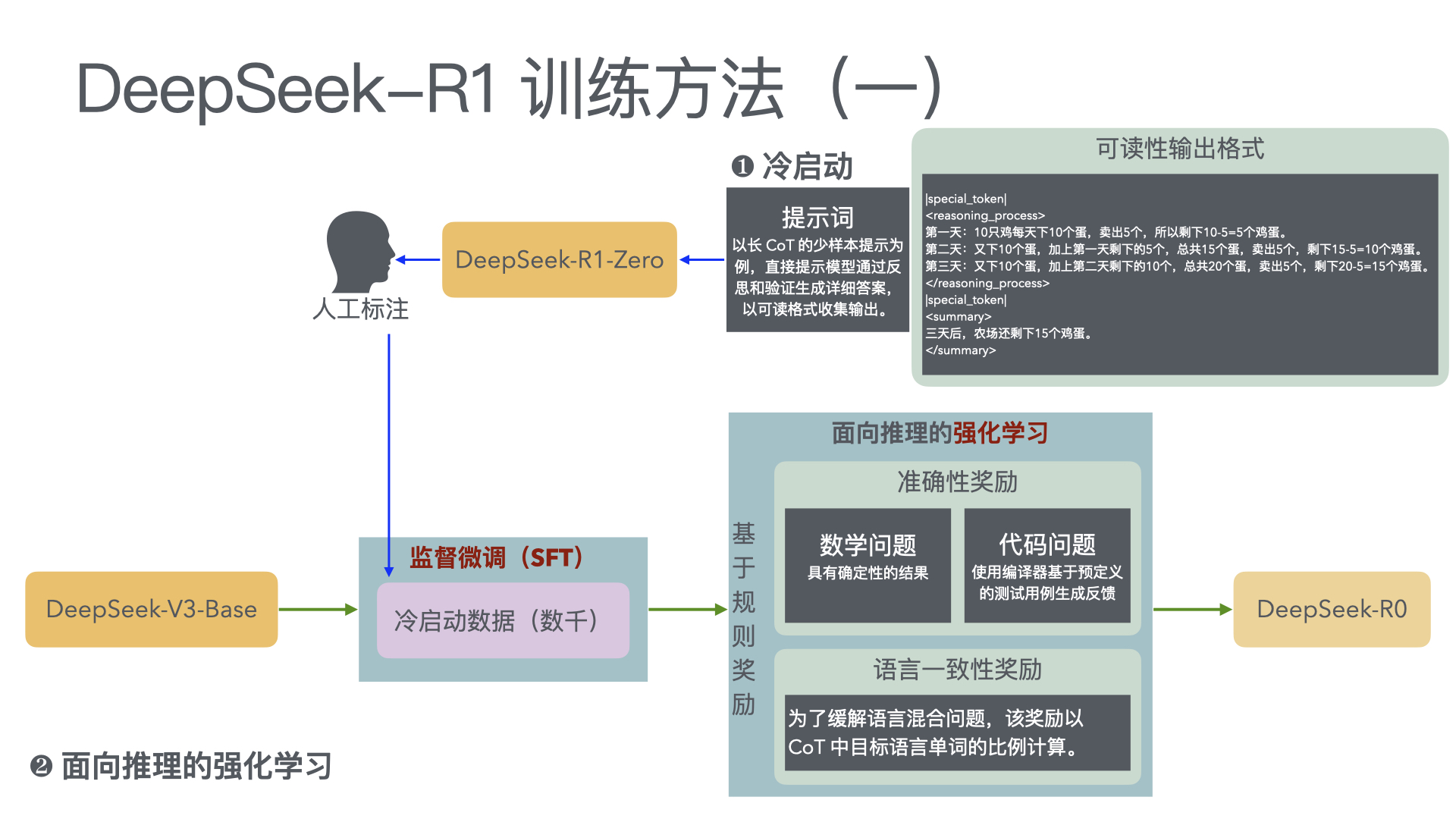
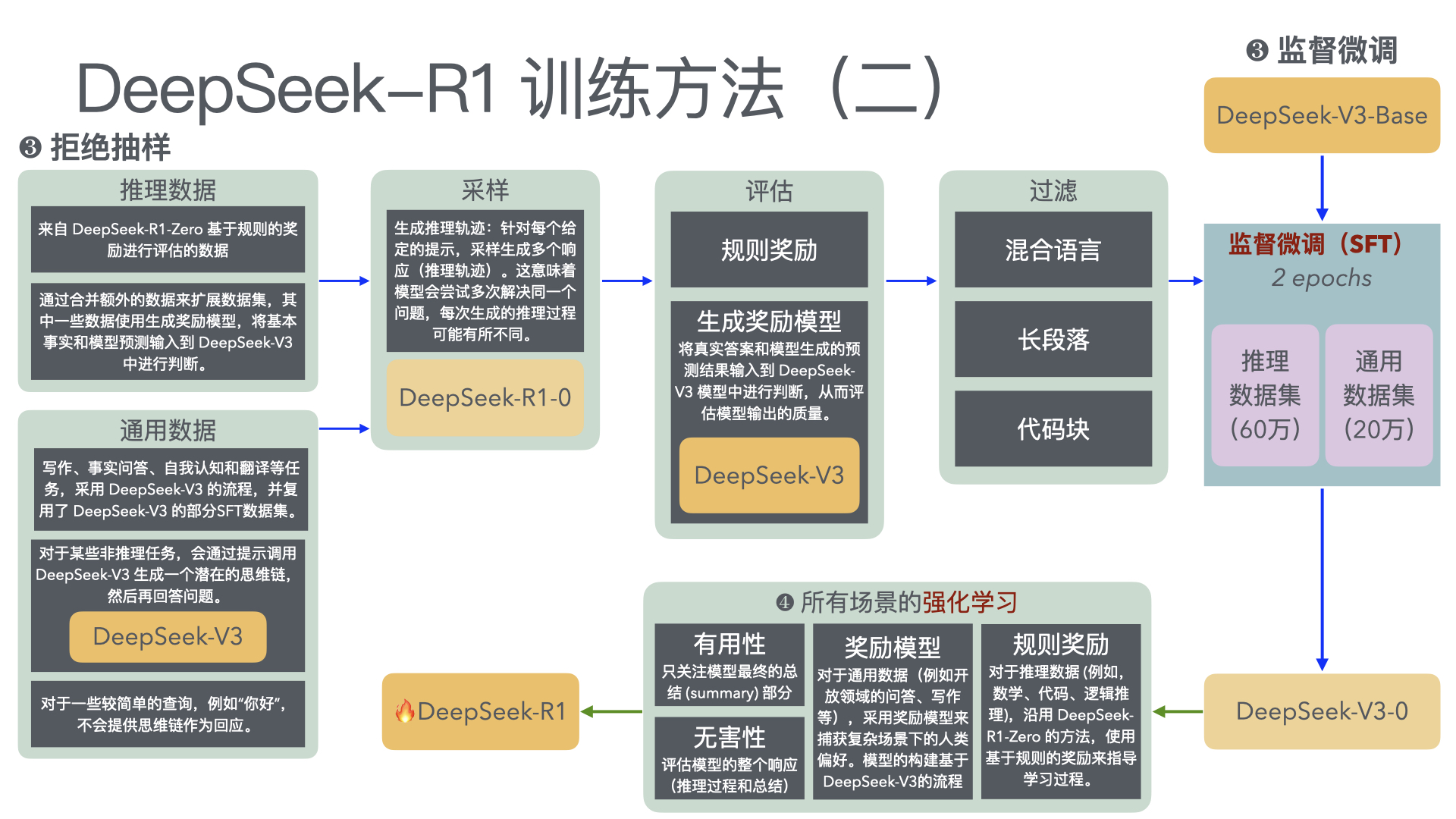
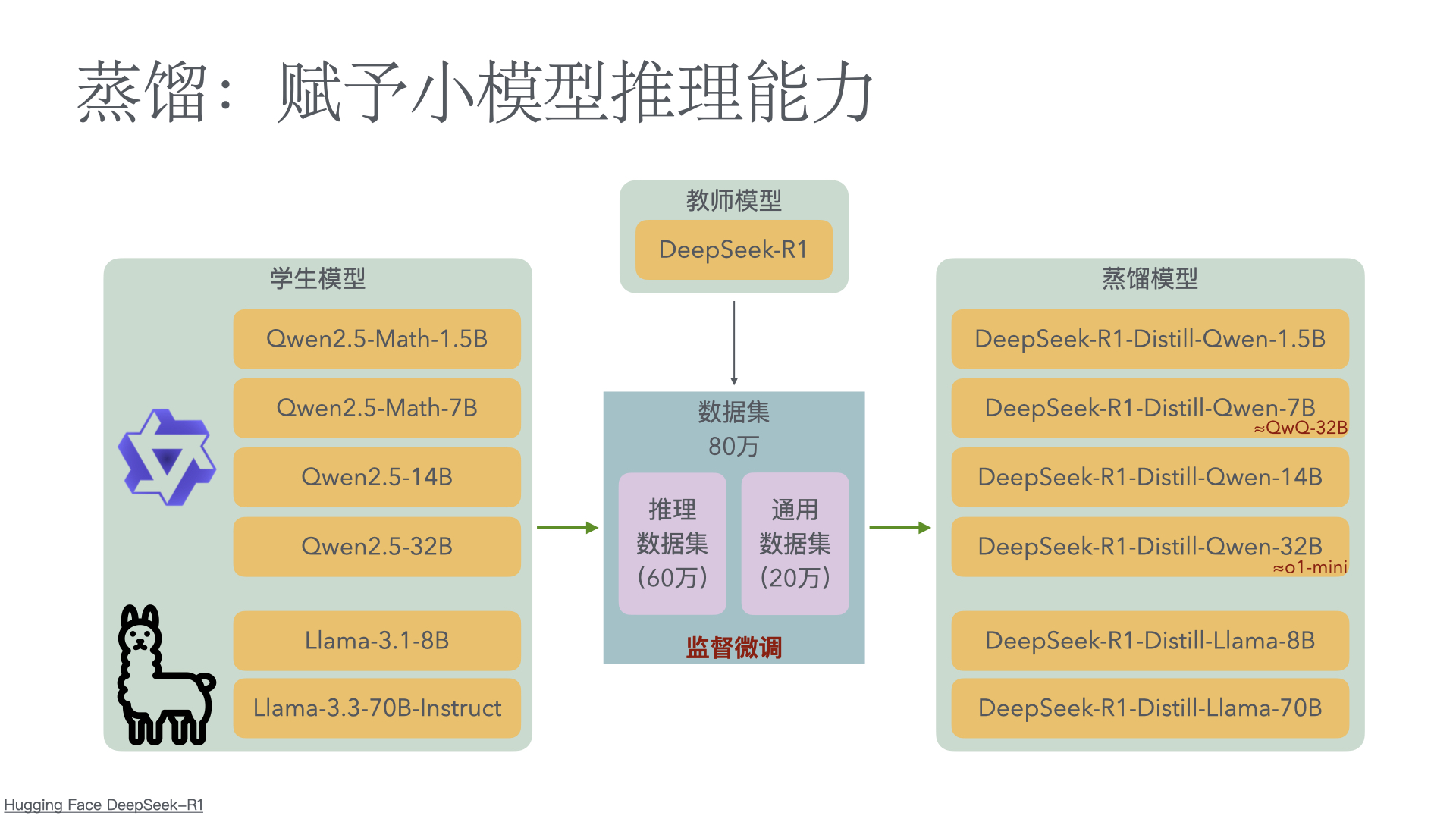
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without super- vised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities. Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing.
Prompt Engineering Techniques(提示工程技术)
In-Context Learning (上下文学习)
Standard prompt with instruction (标准提示与指令)