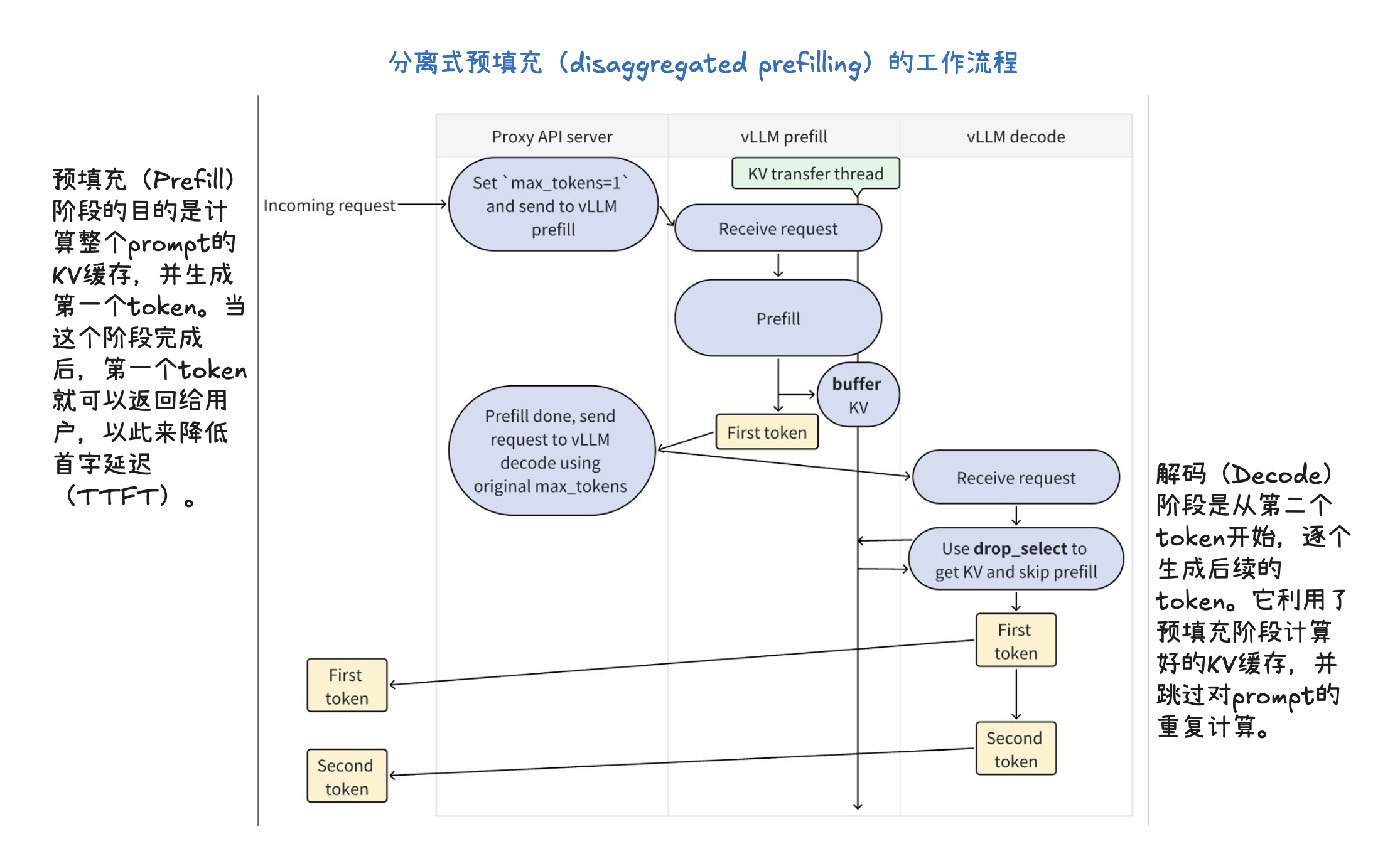
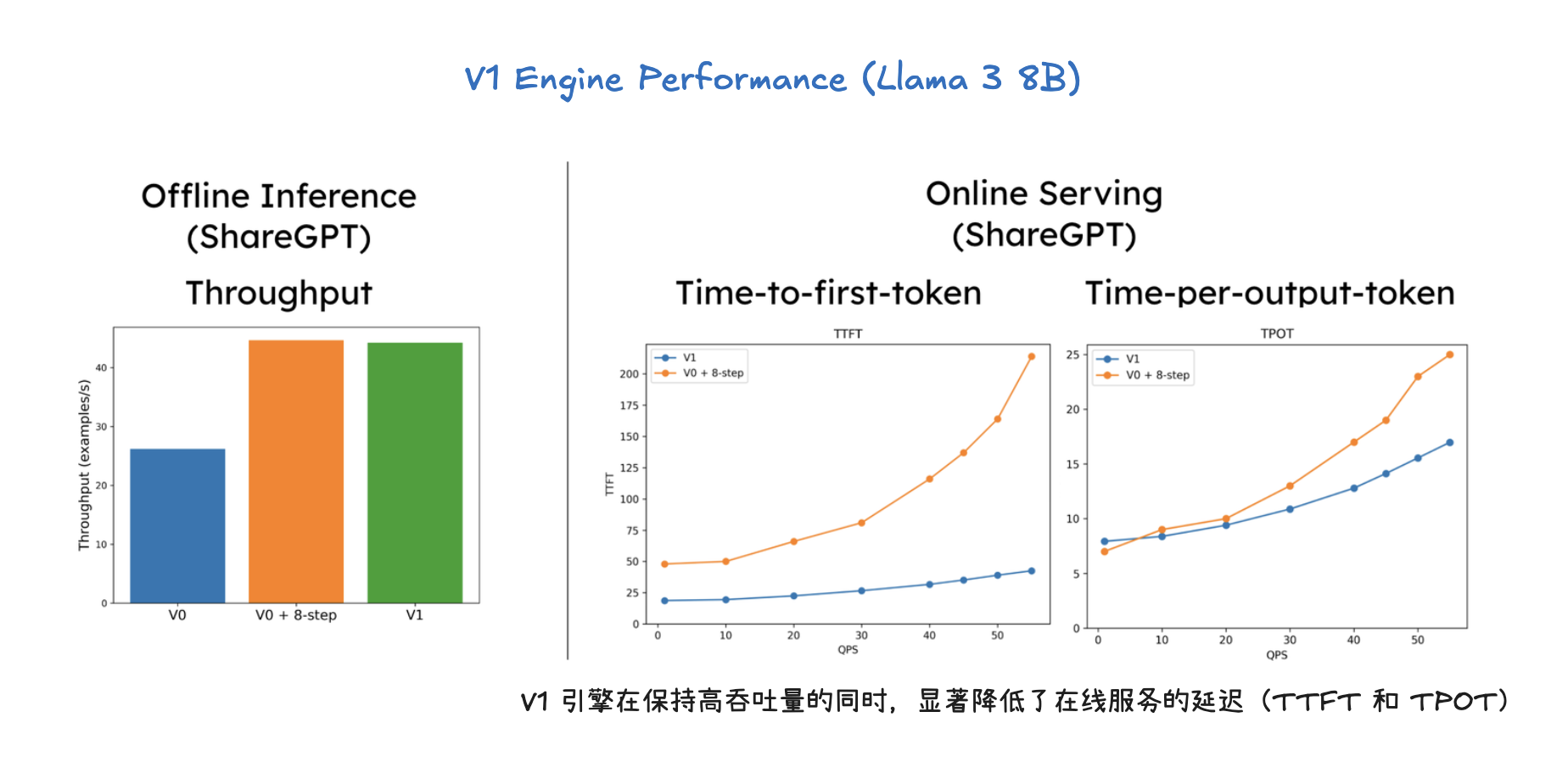
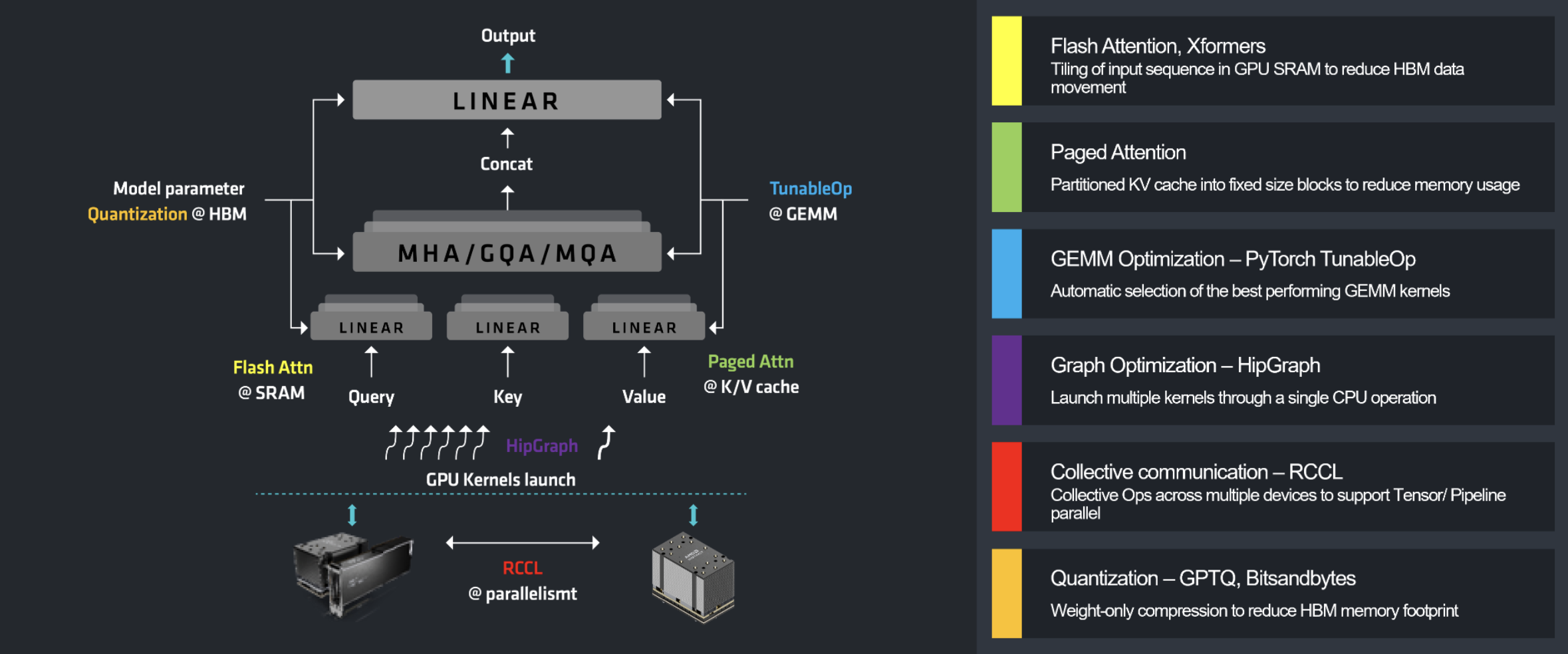
大模型(语言、视觉语言、语音)推理服务部署与测试
推理服务
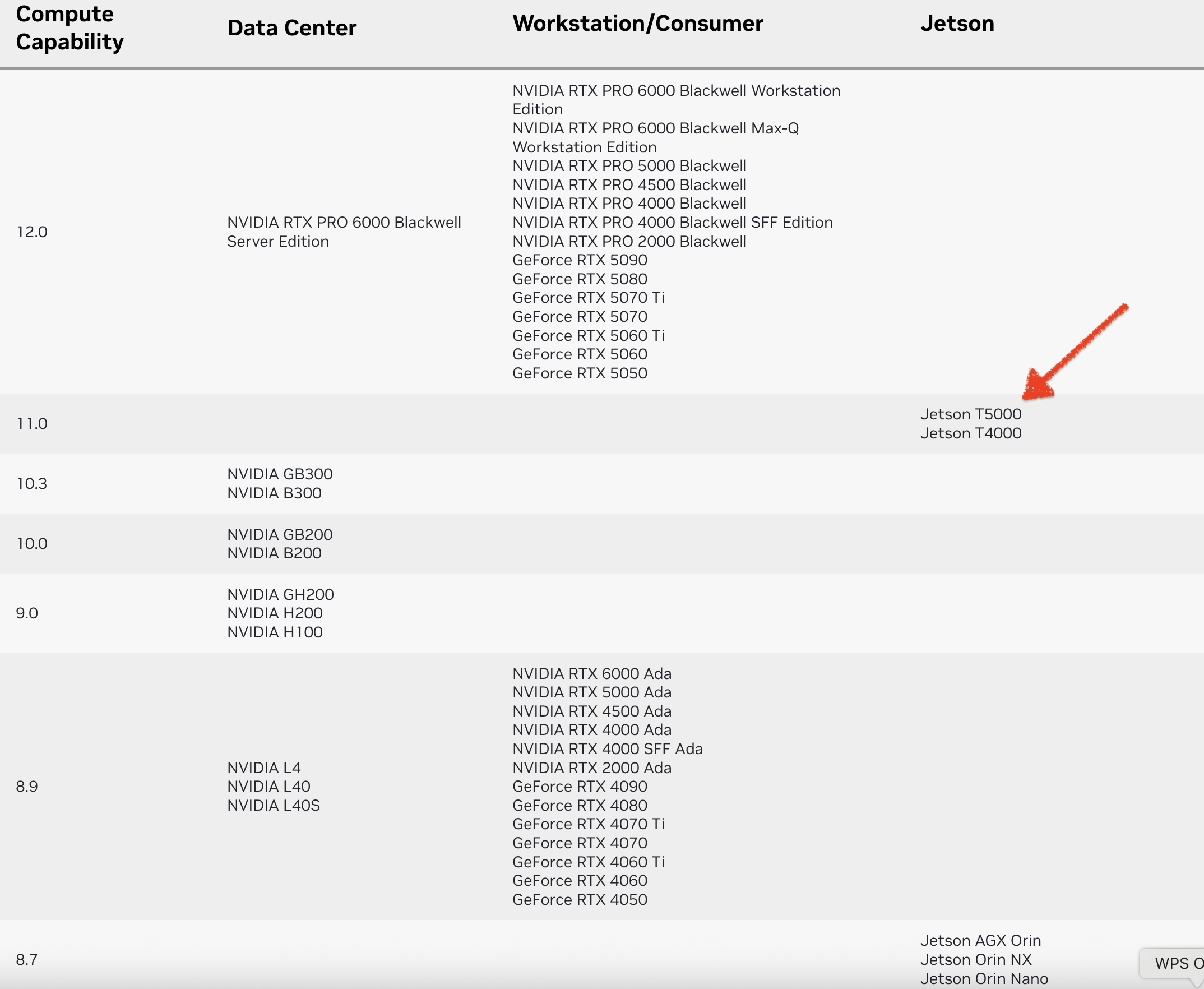
CUDA GPU Compute Capability(计算能力)
计算能力(CC)定义了每种 NVIDIA GPU 架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。
vLLM
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm-test \
-v /models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/vllm:25.10-py3 \
bash
默认情况下,如果模型未指向有效的本地目录,它将从 Hugging Face Hub 下载模型文件。要从 ModelScope 下载模型,请在运行命令之前进行如下设置:
export VLLM_USE_MODELSCOPE=true
vllm serve /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
SGLang