vLLM 推理引擎的核心优化技术及其工作流程
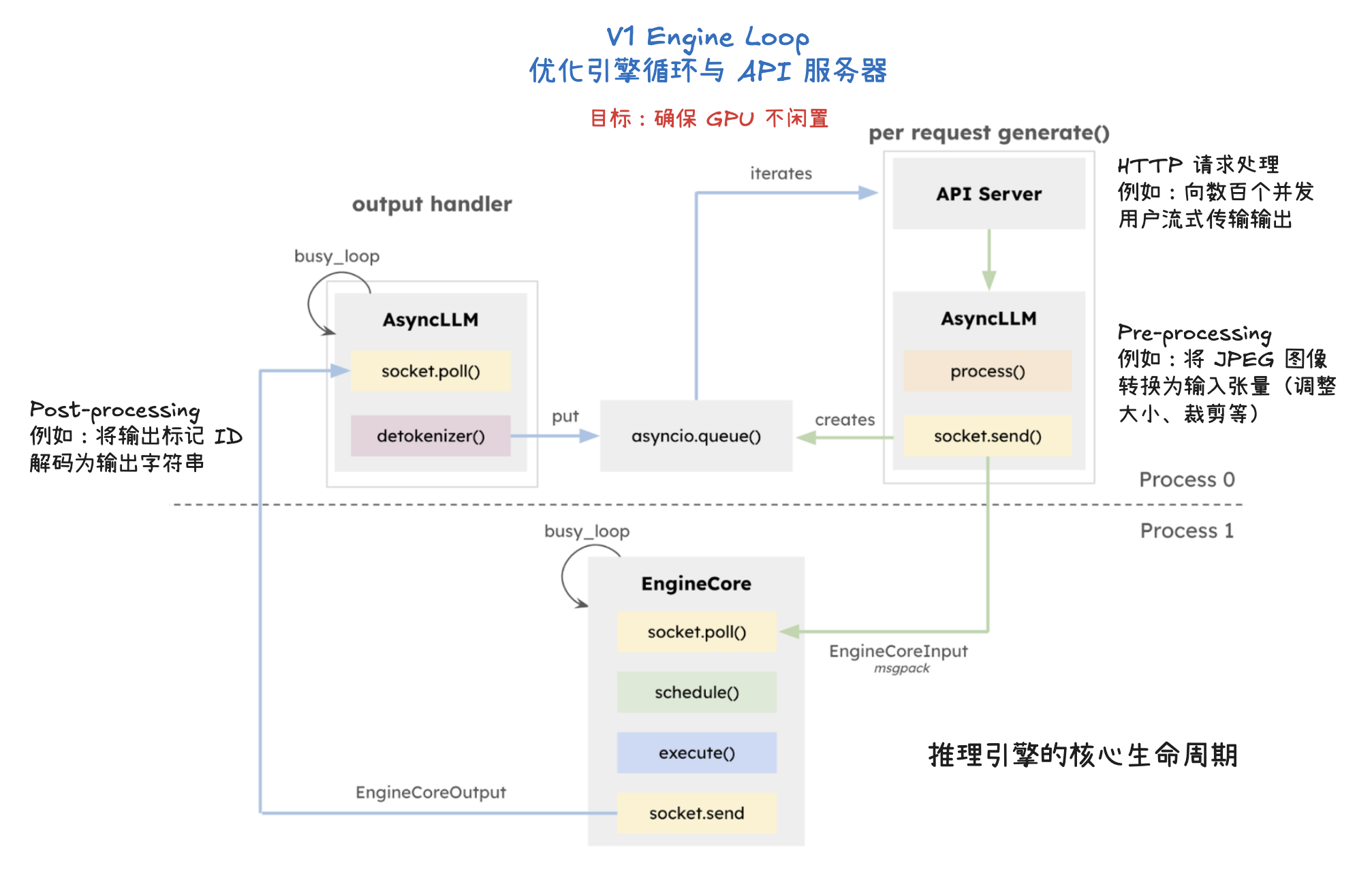
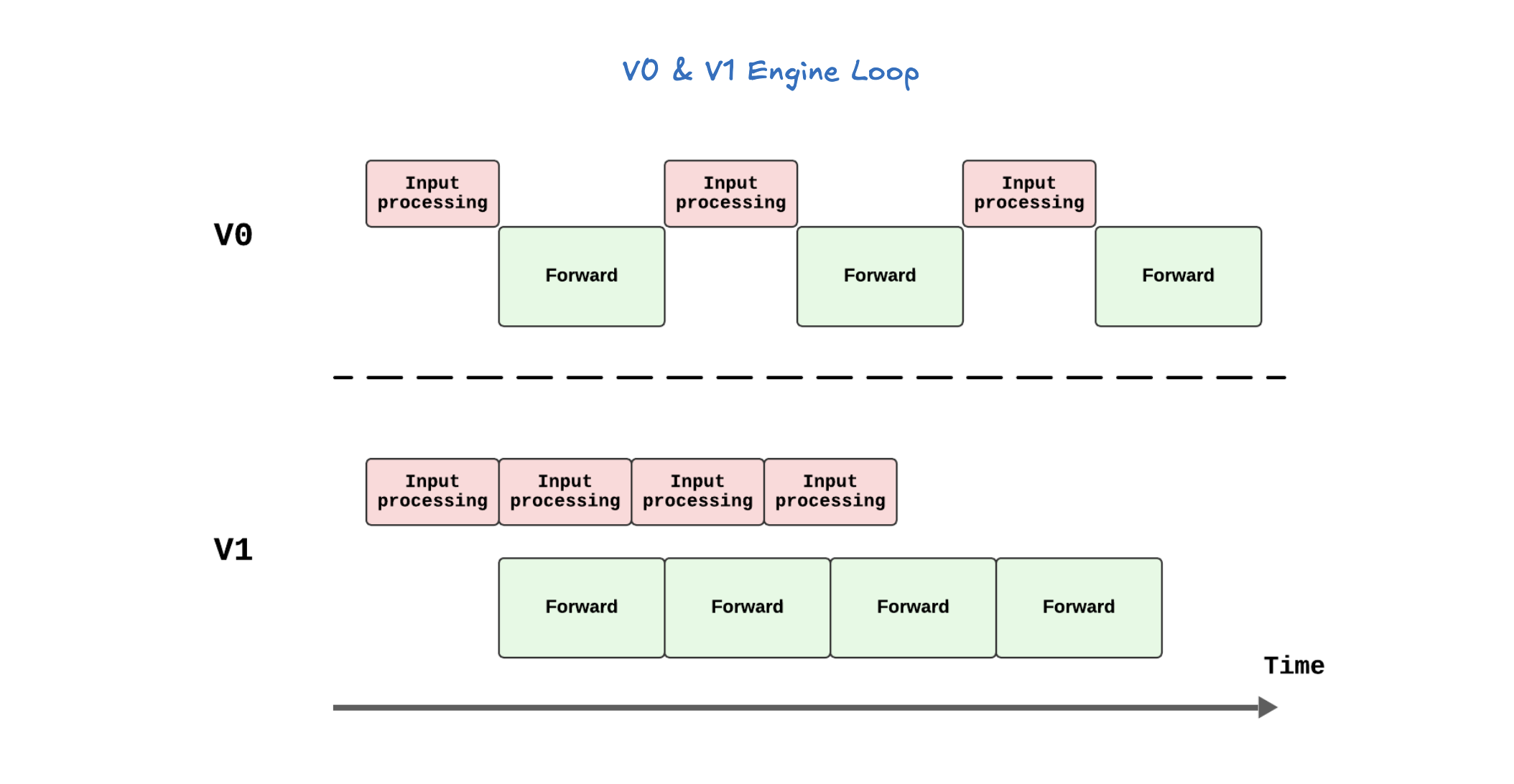
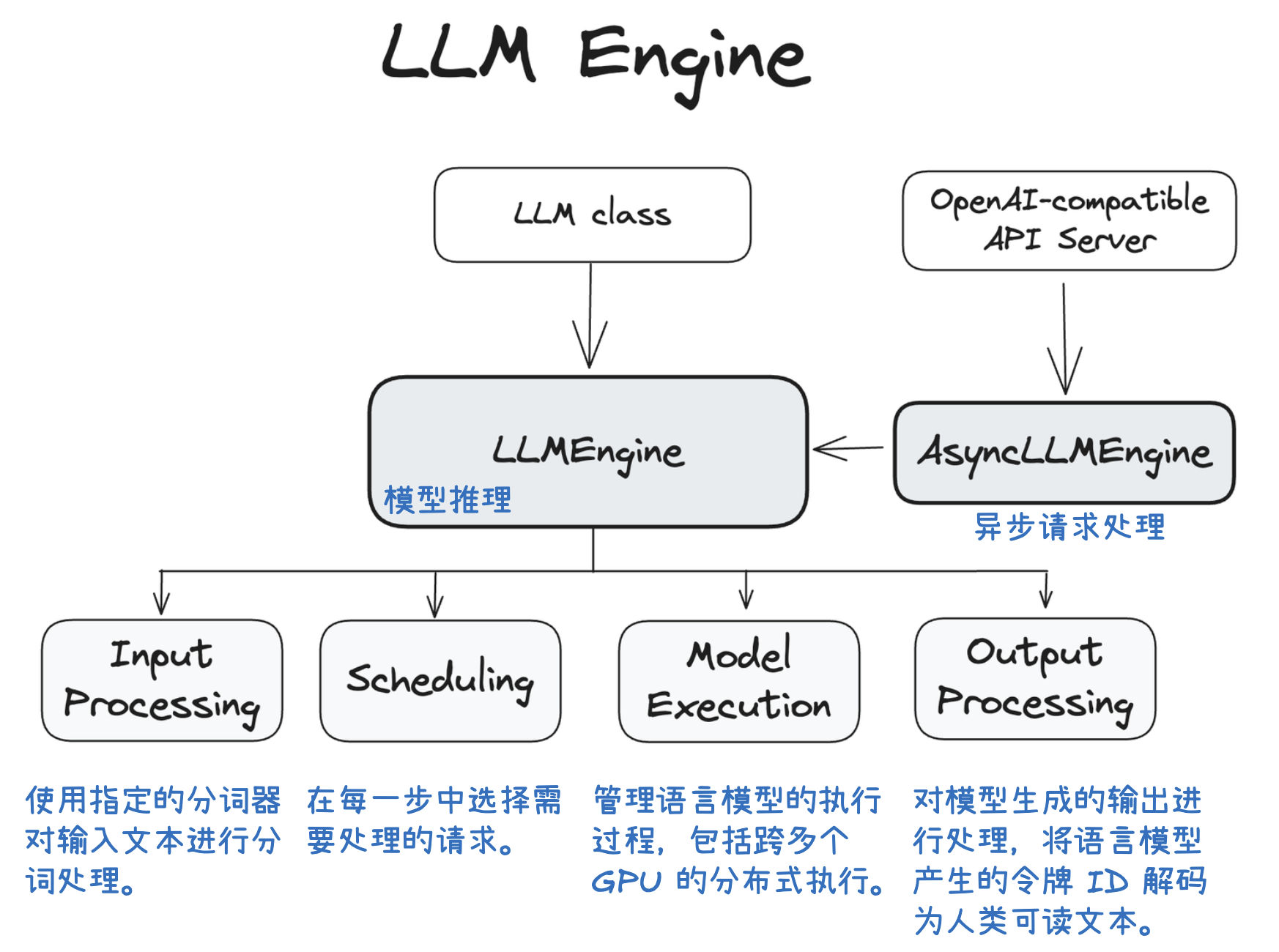
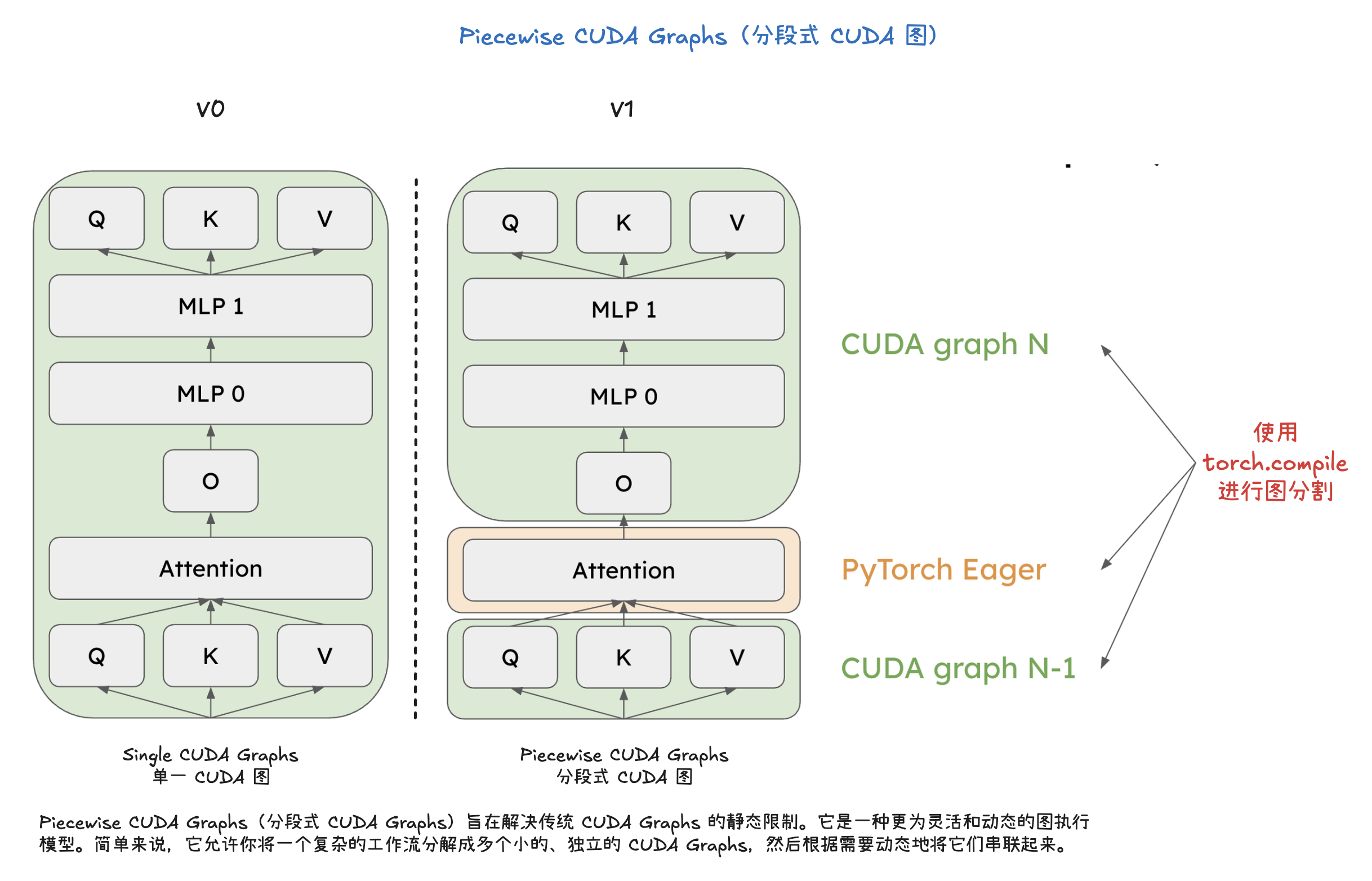
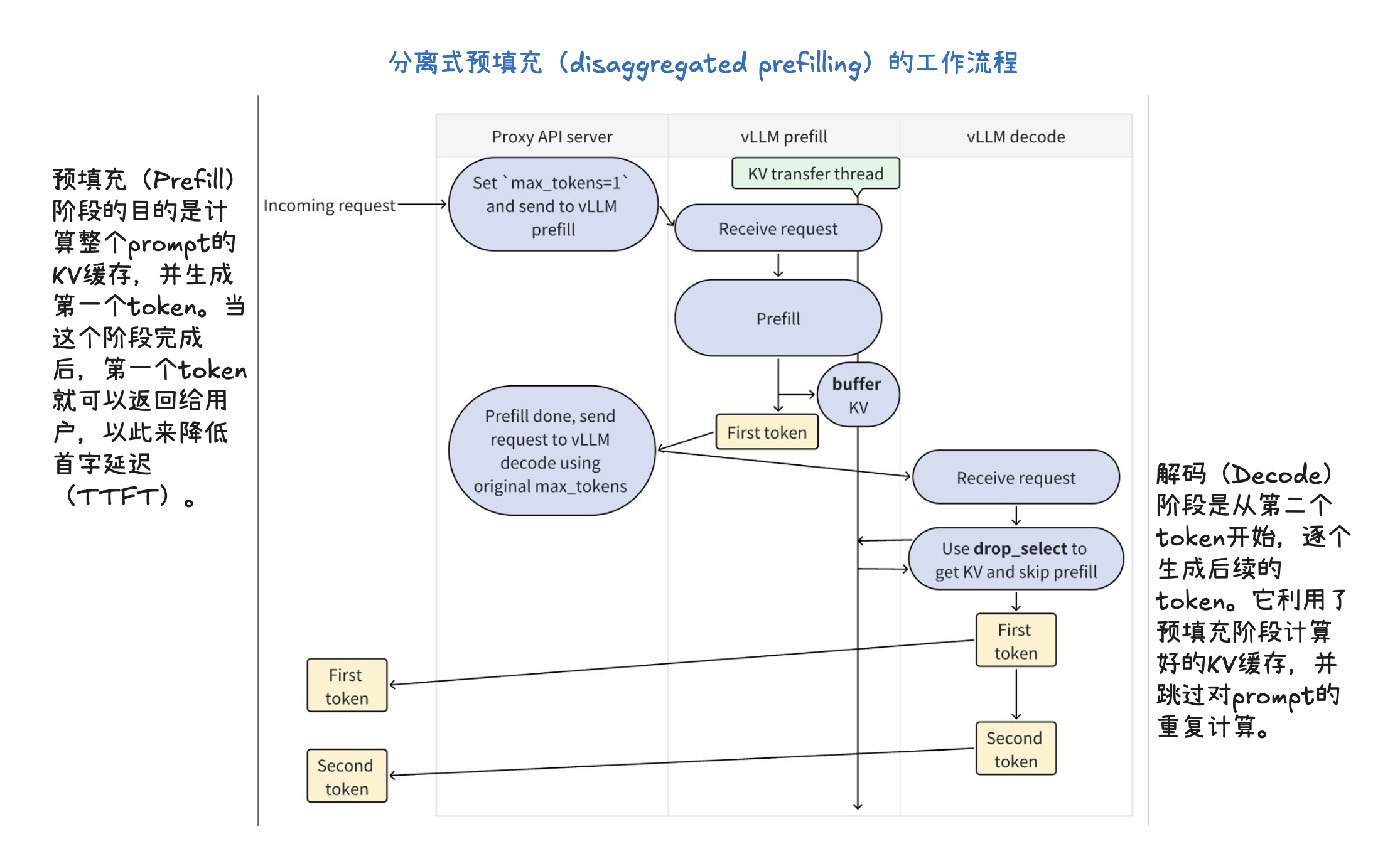
vLLM V1 引擎通过优化其核心引擎循环,将输入处理并行化,并引入了分段式 CUDA 图,从而实现了更灵活、动态的执行模型,显著降低了在线服务的延迟(TTFT 和 TPOT),同时保持了高吞吐量。其设计目标是确保 GPU 不闲置,通过 API 服务器和 EngineCore 之间的协作来高效调度和执行任务。为了进一步加速大型语言模型推理,vLLM V1 采用了多种优化技术:它通过分离式预填充和分块预填充来优化首个 token 的生成延迟,并结合连续批处理与分页注意力来提高 KV 缓存的内存效率和 GPU 利用率。此外,前缀缓存技术避免了重复计算相同提示的 KV 缓存,而级联推理则是一种内存带宽高效的共享前缀批处理解码技术,通过结合多查询注意力处理共享 KV 和单查询批处理解码处理独特 KV,特别适用于多用户共享长提示的场景,能显著提升性能。其他高级解码方法如推测性解码利用草稿模型加速生成,跳跃解码则适用于结构化输出场景。最后,量化技术是提升性能的关键手段,通过对权重、激活值和 KV 缓存使用低位精度(如 FP8、INT8),它能减少存储和内存占用,加速计算密集型和内存带宽密集型任务,并允许在固定硬件下处理更多 token,从而大幅提升吞吐量,同时保持模型准确性。
V1 Engine 工作流程
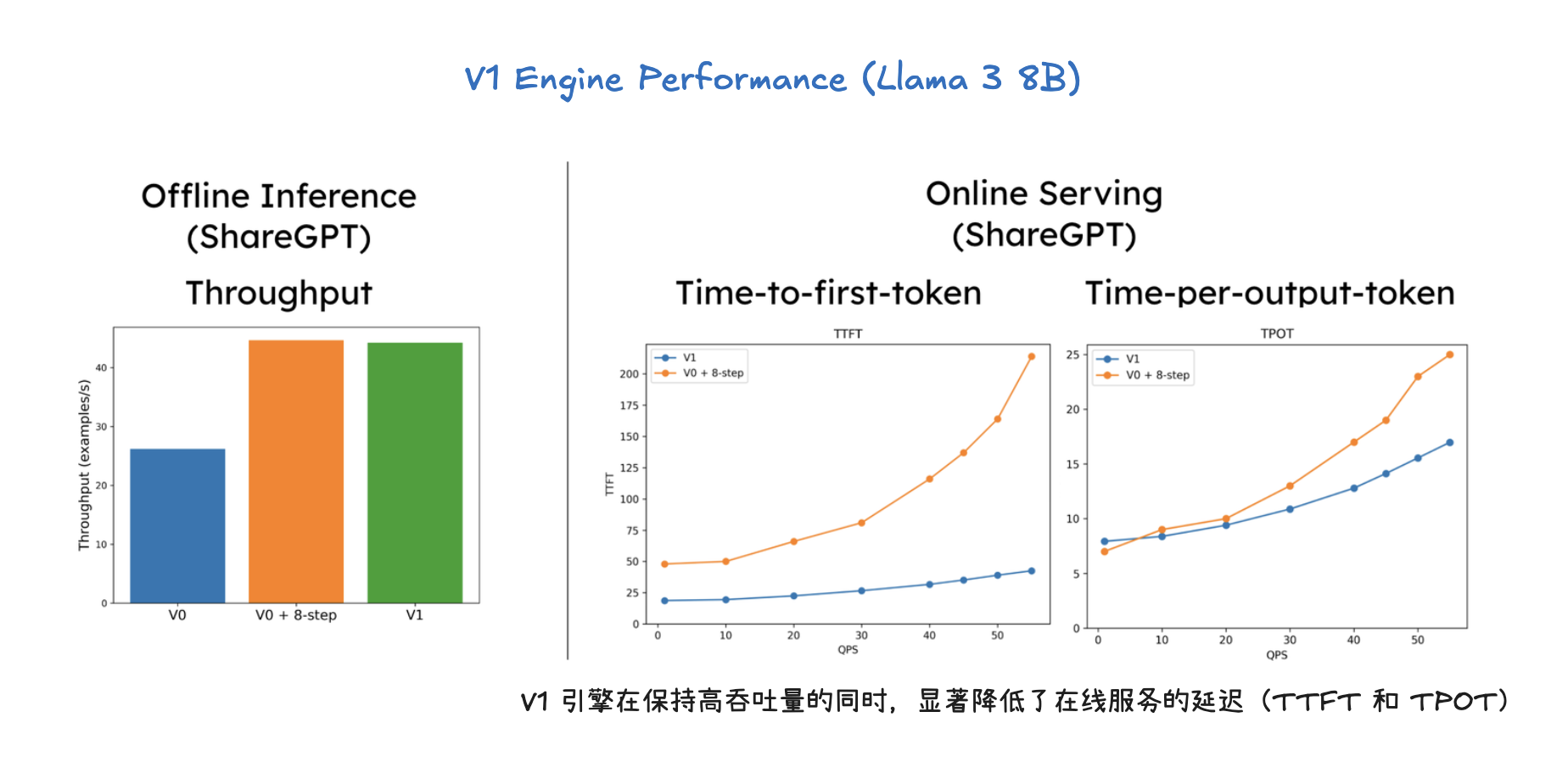
推理优化
典型 LLM 推理优化
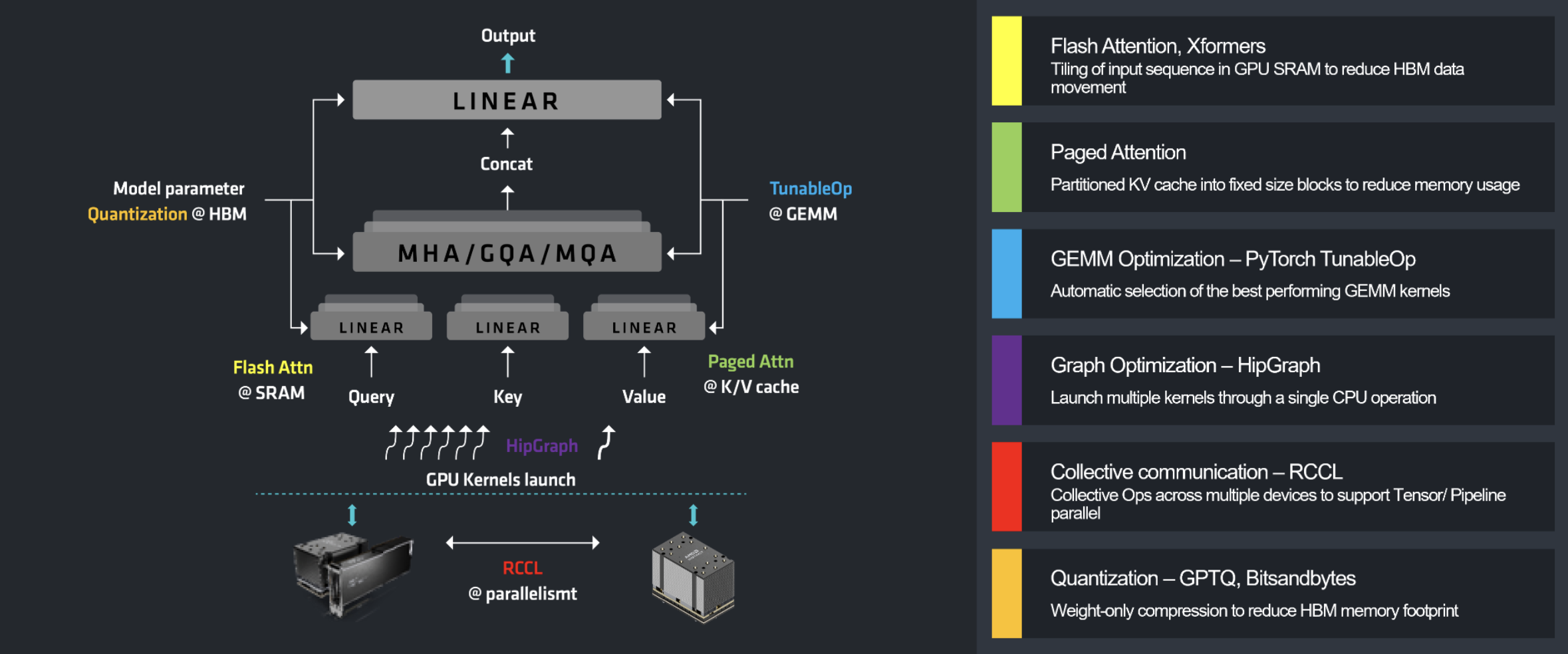
- Flash Attention 的核心思想是将多个操作融合为一个 GPU 内核(kernel),并充分利用速度极快的片上 SRAM(静态随机存取存储器)。