华为 Atlas 800I A2 大模型部署实战(八):GPUStack 实现 GPU 集群化管理
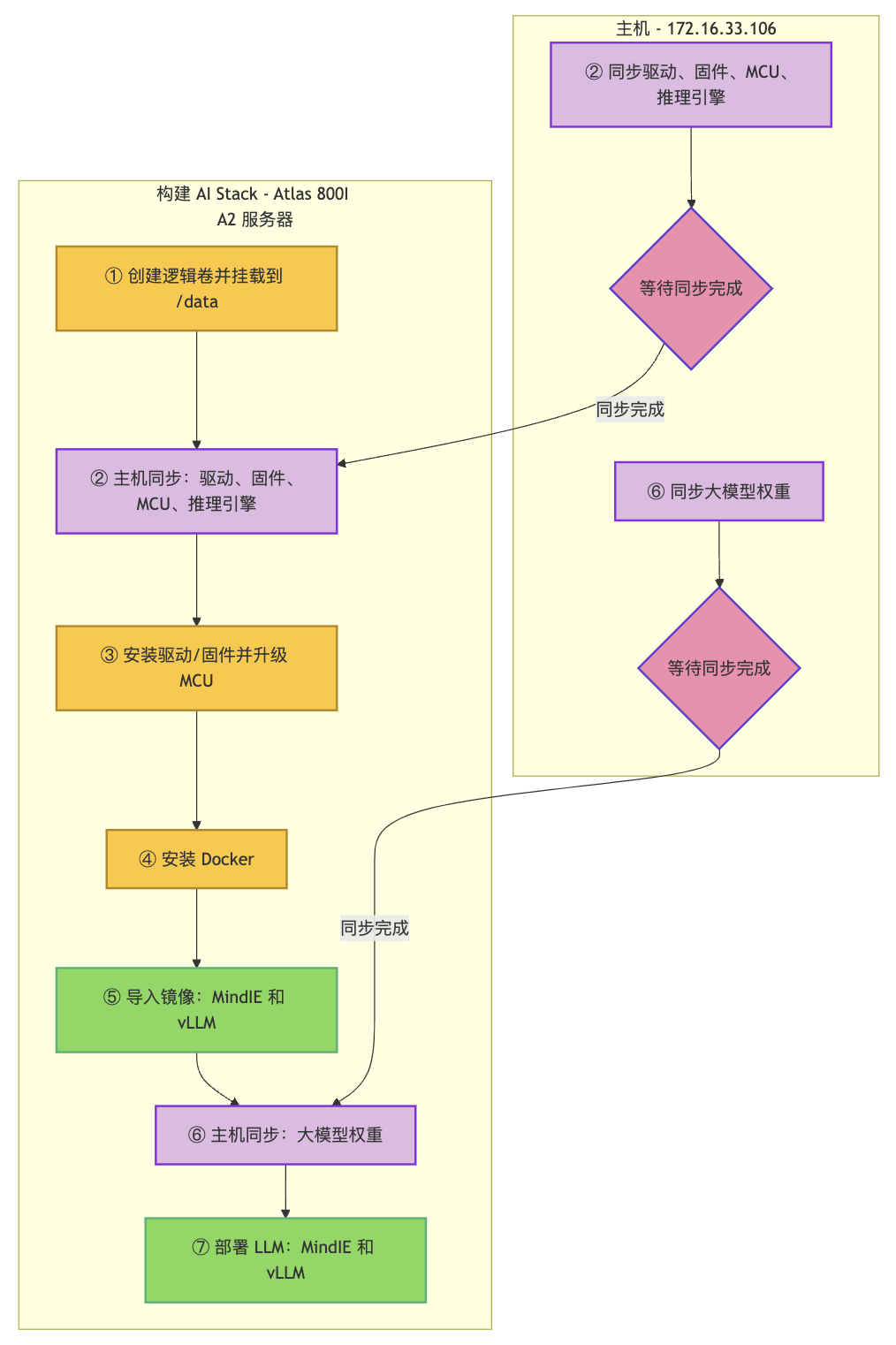
本文章详细介绍了华为 Atlas 800I A2 推理服务器上部署大型AI模型的实践过程,重点围绕GPUStack这一开源GPU集群管理工具。文章首先阐述了GPUStack的核心特性,包括其广泛的兼容性、对多种模型和推理框架的支持、灵活的部署能力以及智能管理功能。随后,文档提供了在主服务器和从服务器上安装、配置和使用GPUStack的详尽步骤,并展示了如何通过NFS实现模型文件的统一存储,以优化多服务器集群中的模型调度效率。文中还包含了GPUStack用户界面的截图,帮助读者直观理解其各项功能。
服务器配置
AI 服务器:华为 Atlas 800I A2 推理服务器 X 5
| 组件 | 规格 |
|---|---|
| CPU | 鲲鹏 920(5250) |
| NPU | 昇腾 910B4(8X32G) |
| 内存 | 1024GB |
| 硬盘 | 系统盘:450GB SSDX2 RAID1 数据盘:3.5TB NVME SSDX4 |
| 操作系统 | openEuler 22.03 LTS |
GPUStack 介绍
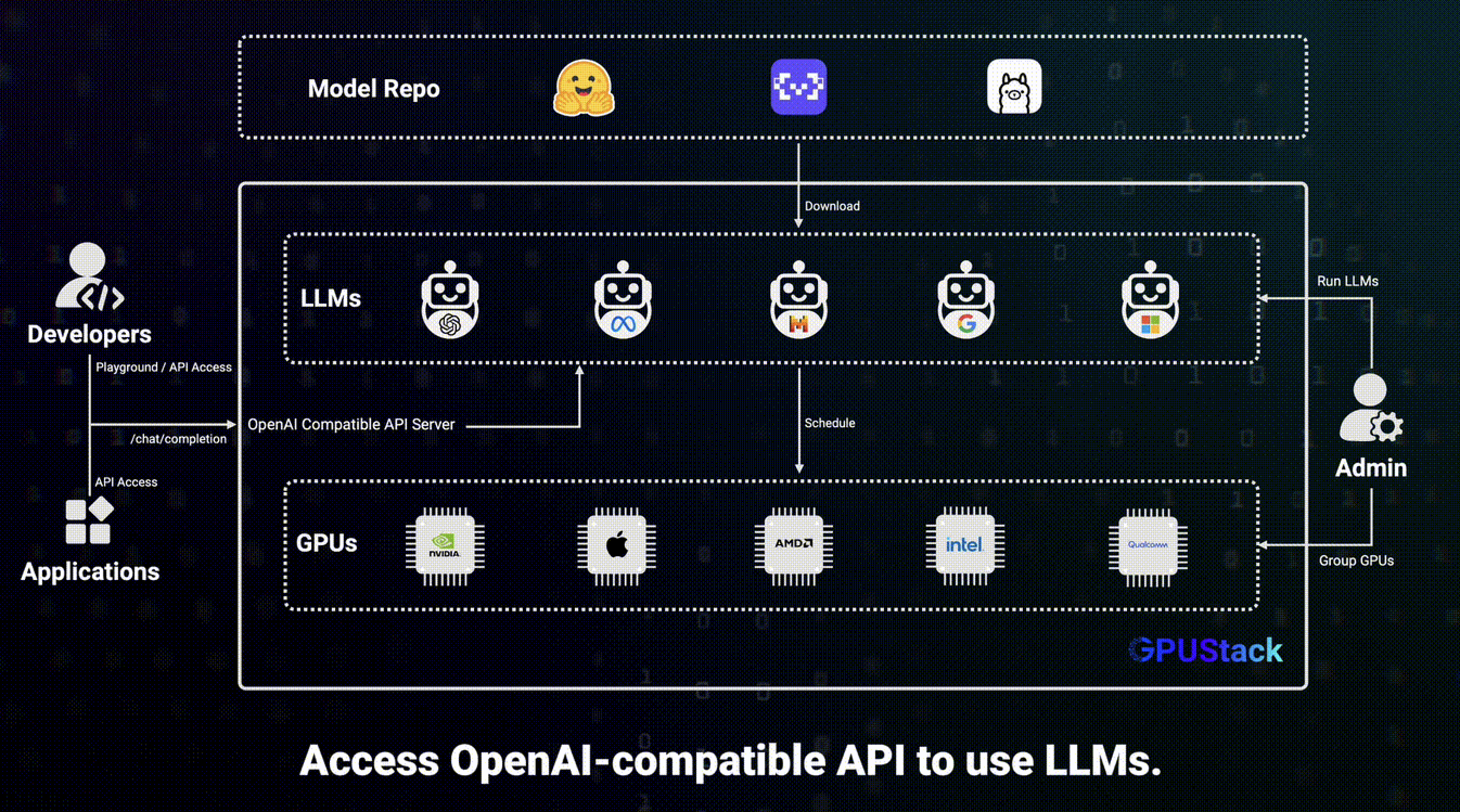
GPUStack 是一款开源的 GPU 集群管理器,专为运行 AI 模型设计,其核心特点如下:
- 广泛的兼容性:支持多厂商 GPU,覆盖苹果 Mac、Windows 电脑及 Linux 服务器,还能适配多种推理后端(如 vLLM、Ascend MindIE 等),并可同时运行多个版本的推理后端,满足不同模型的运行需求。
- 丰富的模型支持与灵活部署:支持 LLM、VLM、图像模型、音频模型等多种类型模型,可实现单节点和多节点多 GPU 推理,包括跨厂商和不同运行环境的异构 GPU,且能通过添加更多 GPU 或节点轻松扩展架构。
- 稳定与智能管理:具备自动故障恢复、多实例冗余和推理请求负载均衡功能,保障高可用性;能自动评估模型资源需求、兼容性等部署相关因素,还可基于可用资源动态分配模型。
- 实用的附加功能:采用轻量级 Python 包,依赖少、运维成本低;提供与 OpenAI 兼容的 API,便于无缝集成;支持用户及 API 密钥管理,可实时监控 GPU 性能、利用率以及令牌使用量和 API 请求速率。