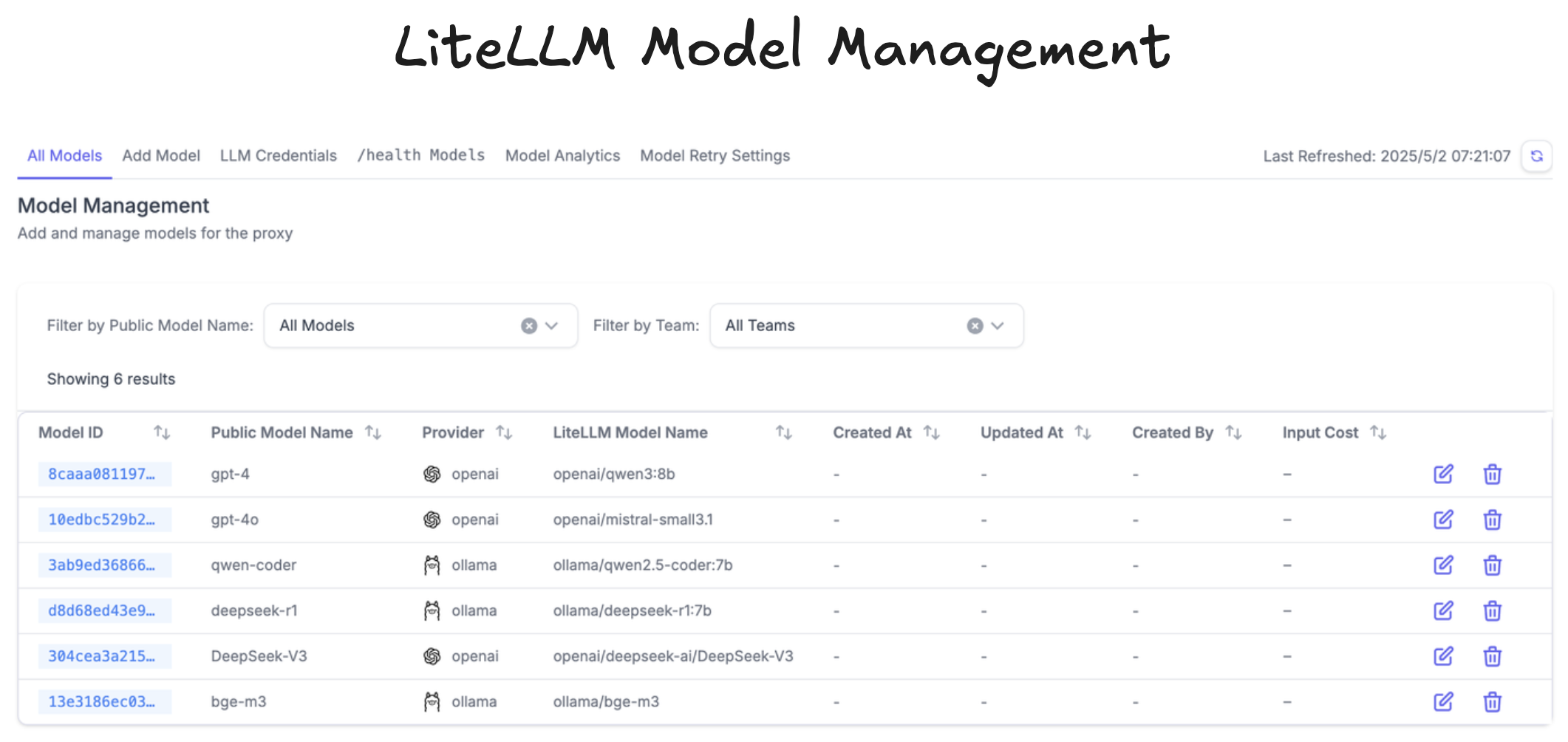
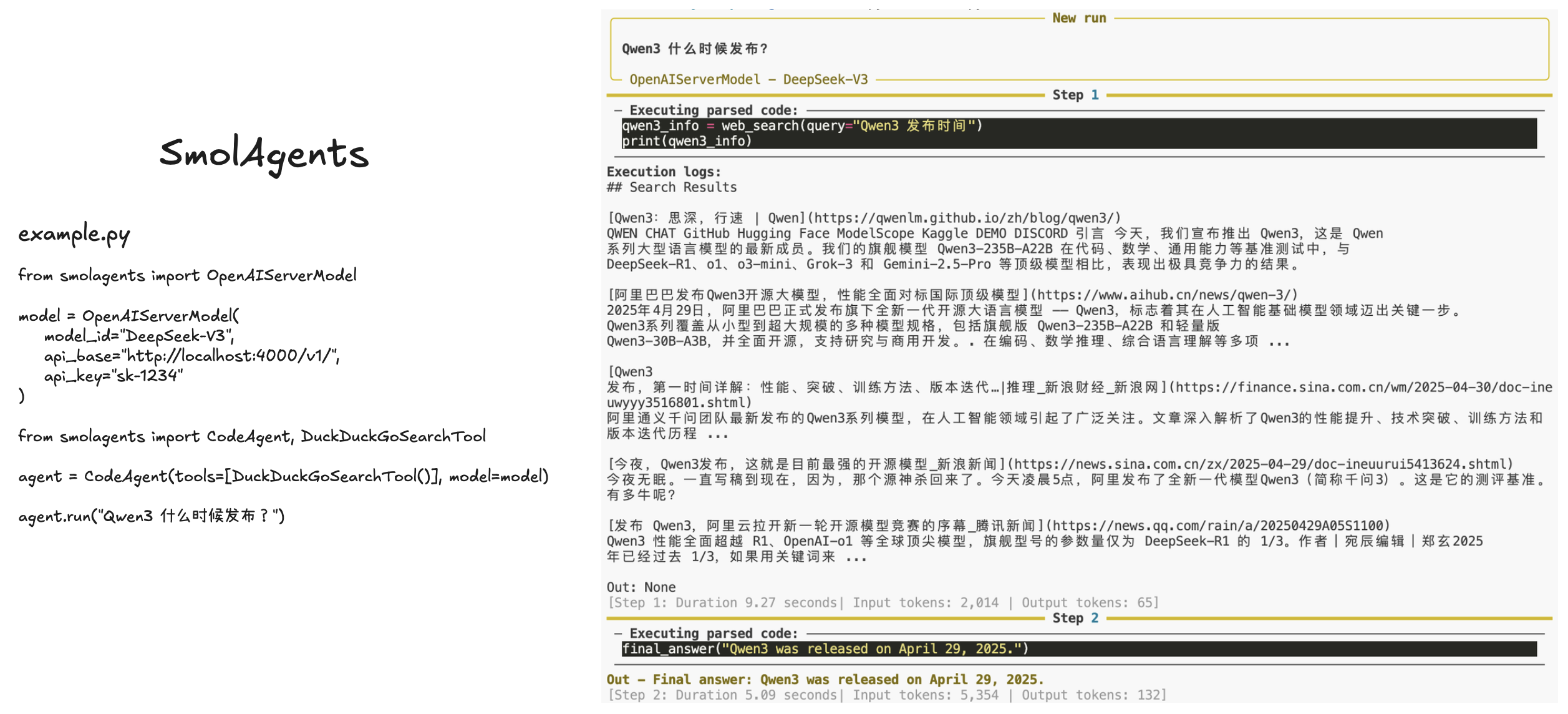
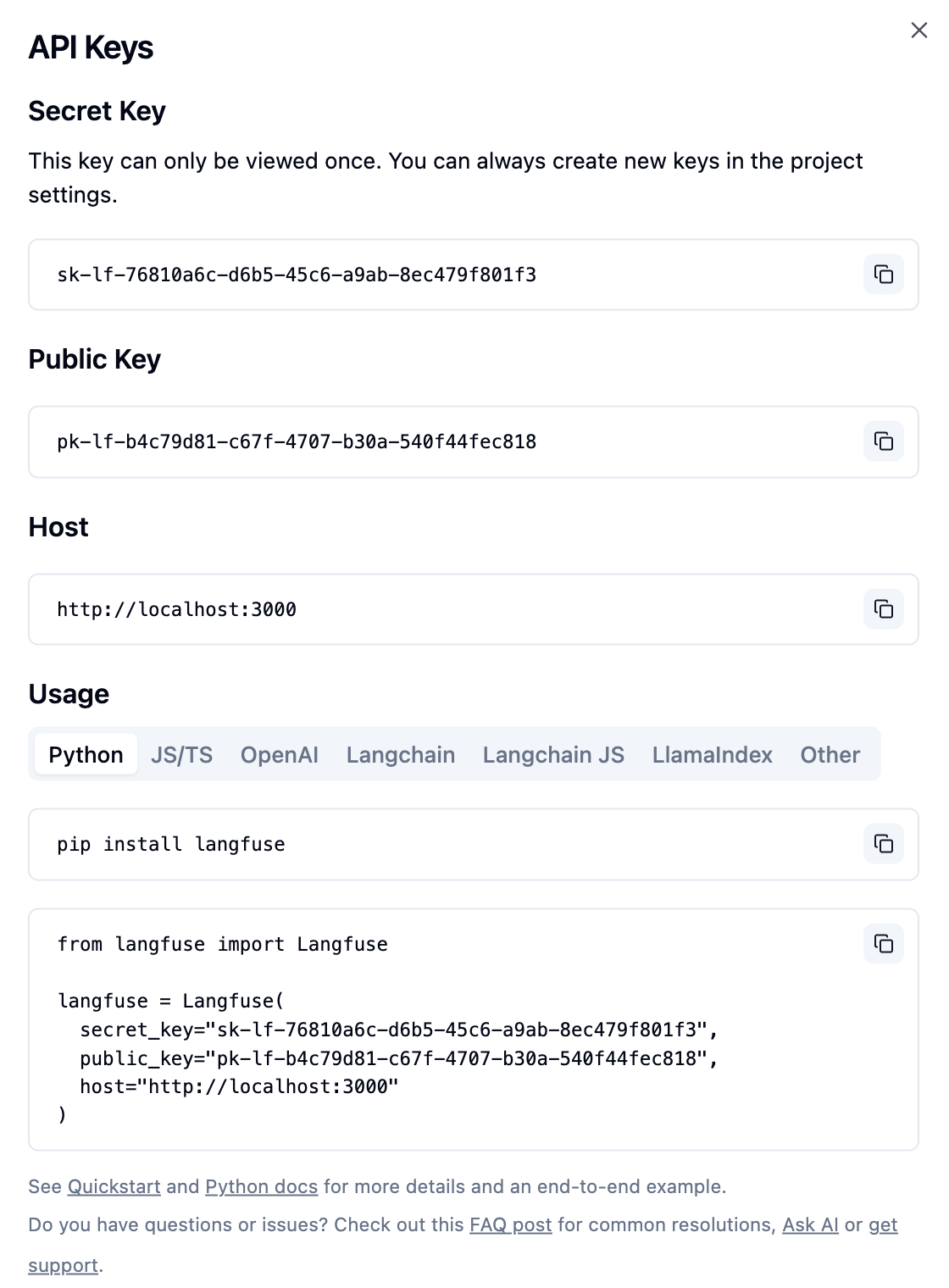
LiteLLM 代理实践:安装、配置与测试

安装
uv tool install 'litellm[proxy]'
配置
编写配置文件:config.yaml
model_list:
- model_name: gpt-5
litellm_params:
model: openai/LongCat-2.0-Preview
api_base: https://api.longcat.chat/openai/
api_key: sk-xxx
- model_name: gpt-5-nano
litellm_params:
model: openai/qwen3.5:9b
api_base: http://localhost:11434/v1
api_key: none
运行
litellm --config config.yaml
测试
⚠️ 通过测试说明 LiteLLM 代理只支持中转,上游没有提供对应的API支持(LongCat 只支持 Chat Completions),LiteLLM 也不支持。