FunAudioLLM:用于人类与LLM自然交互的语音理解与生成基础模型
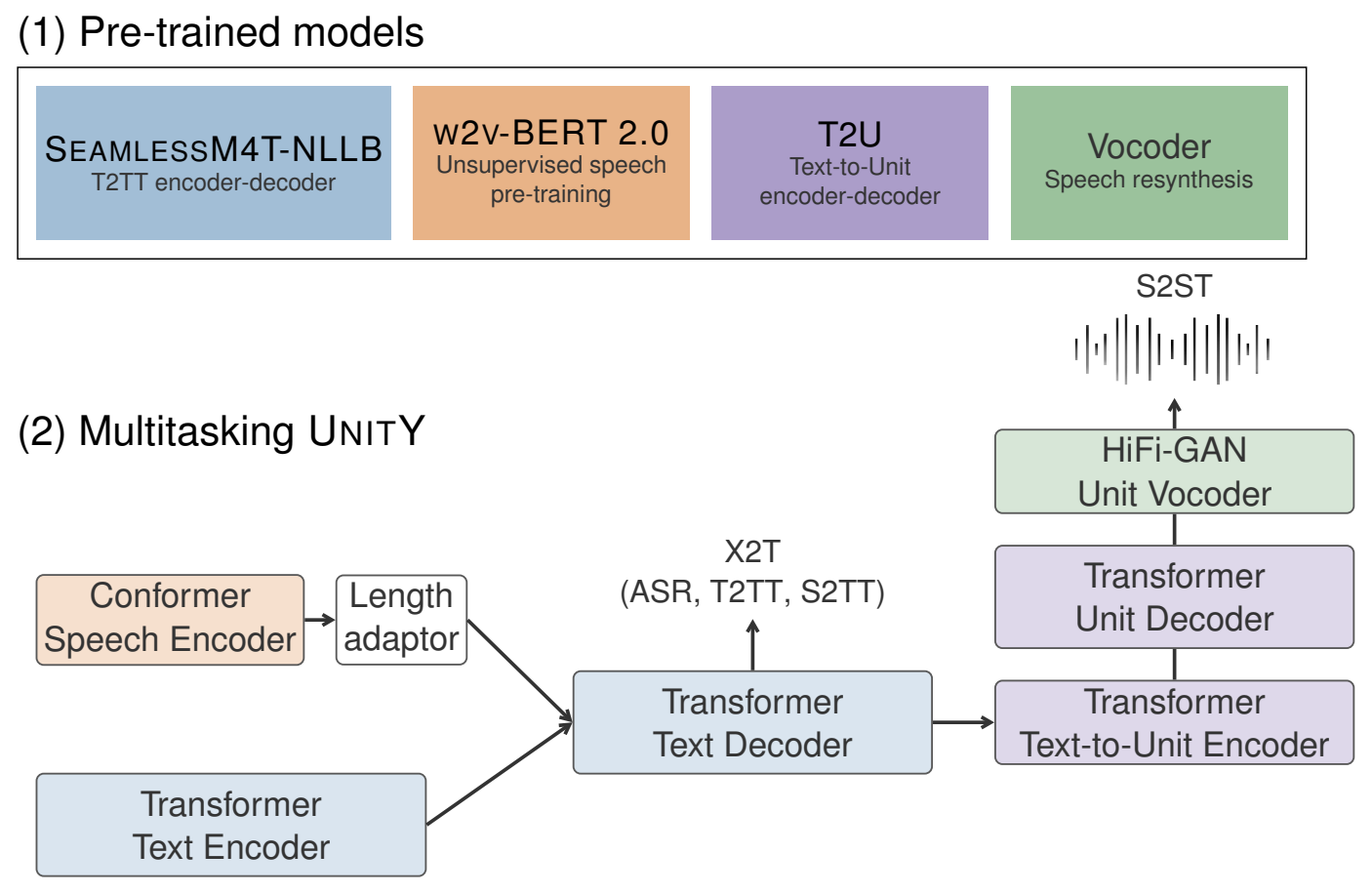
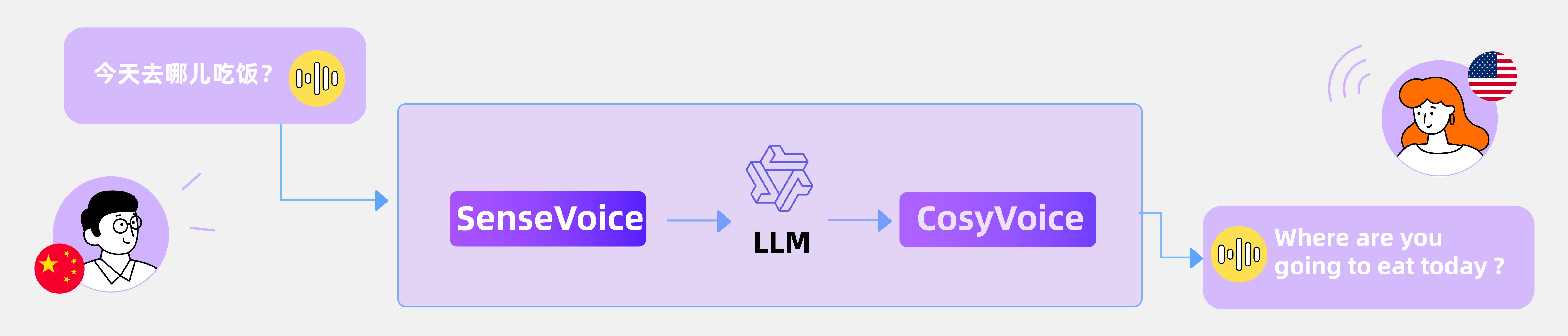
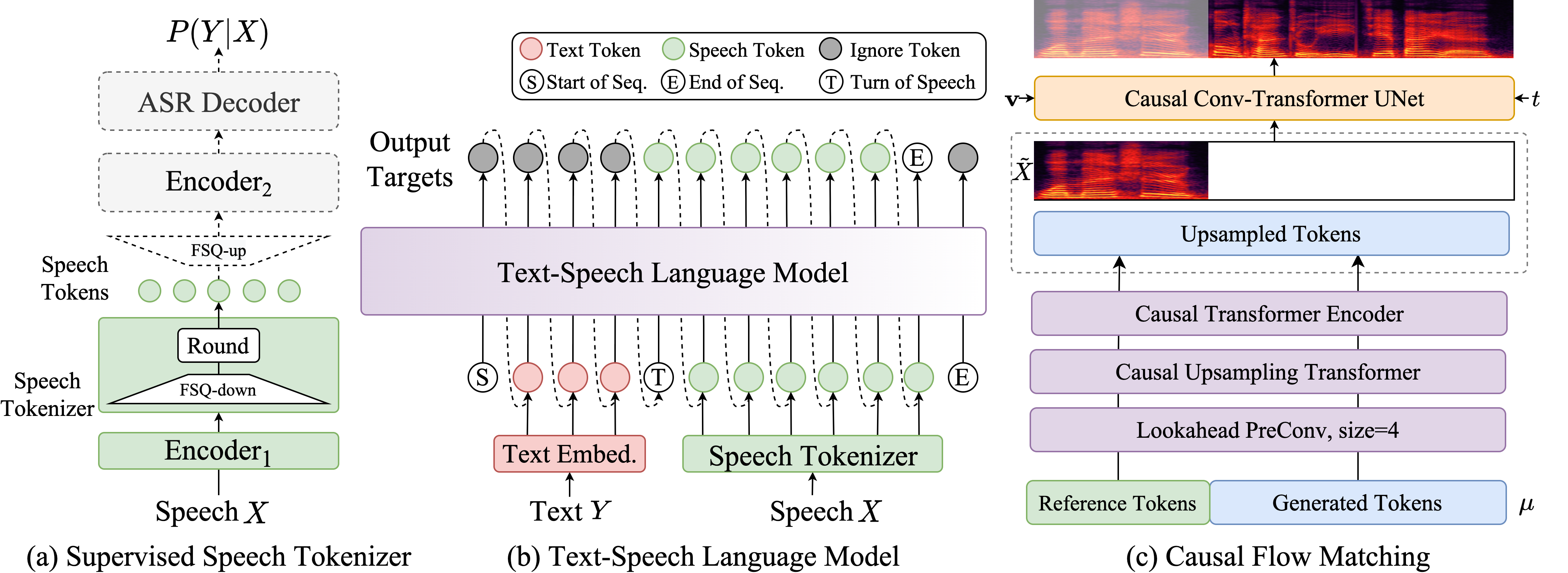
本文档介绍 FunAudioLLM,这是一个旨在增强人类与大型语言模型(LLM)之间自然语音交互的框架。其核心是两个创新模型:用于高精度多语种语音识别、情感识别和音频事件检测的 SenseVoice;以及用于多语种、音色和情感控制的自然语音生成的 CosyVoice。SenseVoice 具有极低的延迟并支持超过 50 种语言,而 CosyVoice 在多语种语音生成、零样本语音生成、跨语言语音克隆以及指令遵循能力方面表现出色。与 SenseVoice 和 CosyVoice 相关的模型已在 Modelscope 和 Huggingface 上开源,同时相应的训练、推理和微调代码也已在 GitHub 上发布。通过将这些模型与 LLM 集成,FunAudioLLM 能够实现语音翻译、情感语音聊天、交互式播客和富有表现力的有声读物叙述等应用,从而推动语音交互技术的边界。
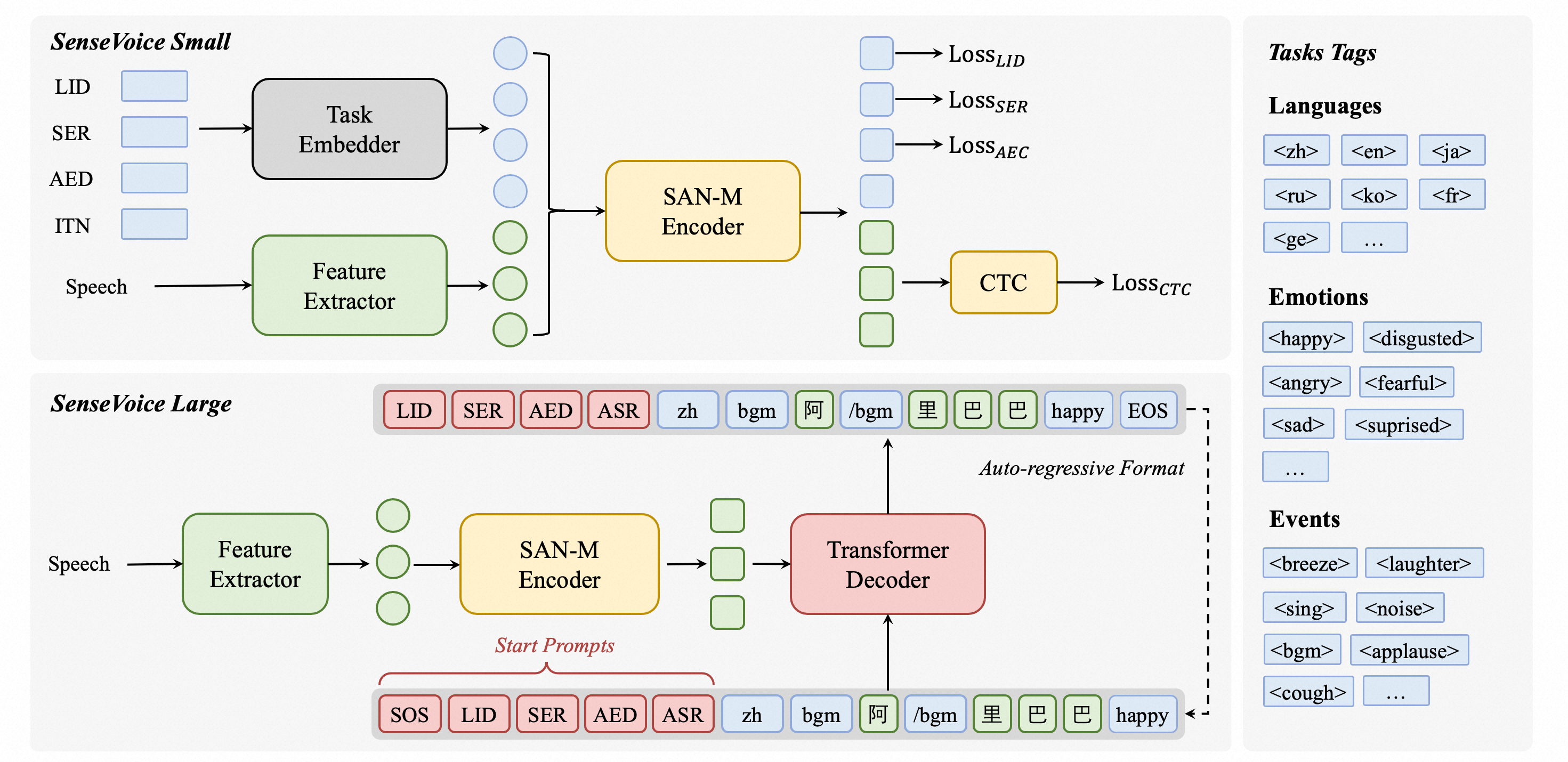
SenseVoice
参考资料 FunAudioLLM: Voice Understanding and Generation Foundation Models for Nat