FunASR - 基础语音识别工具包
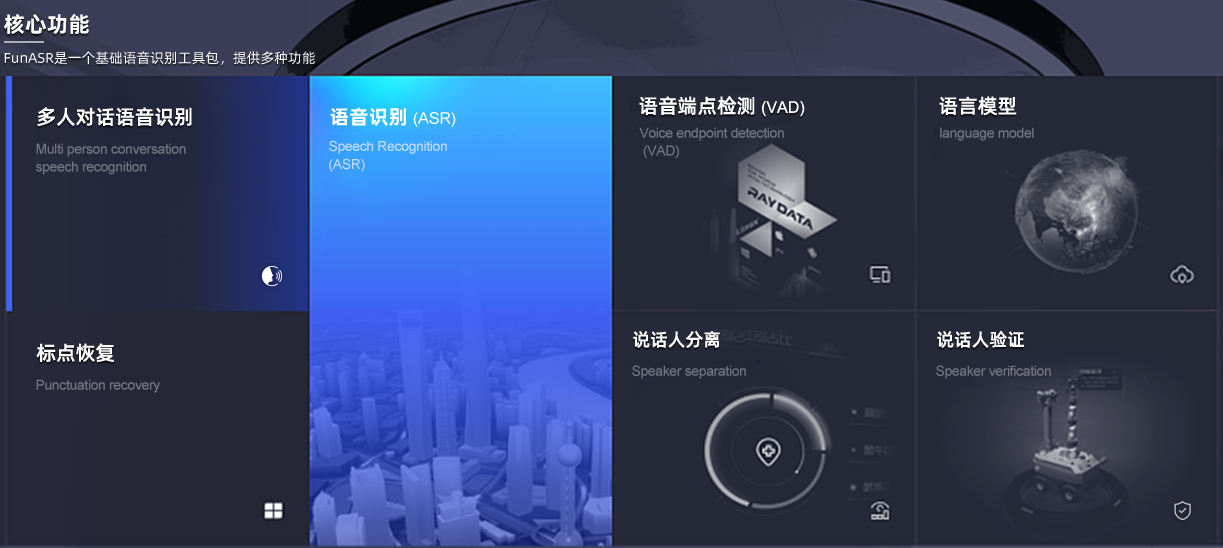
FunASR 是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。
FunASR 快速入门
核心功能
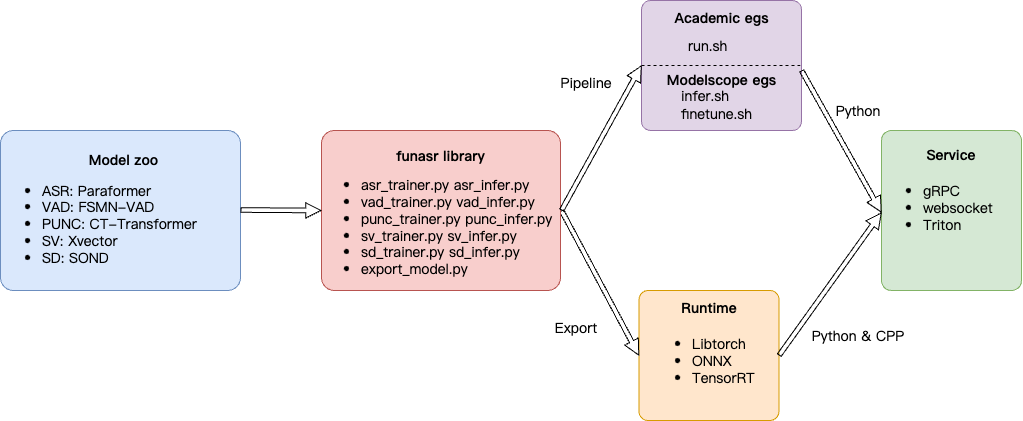
工作流程
离线文件转写服务

FunASR离线文件转写软件包,提供了一款功能强大的语音离线文件转写服务。拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。服务端集成有ffmpeg,支持各种音视频格式输入。软件包提供有html、python、c++、java与c#等多种编程语言客户端。
实时听写服务
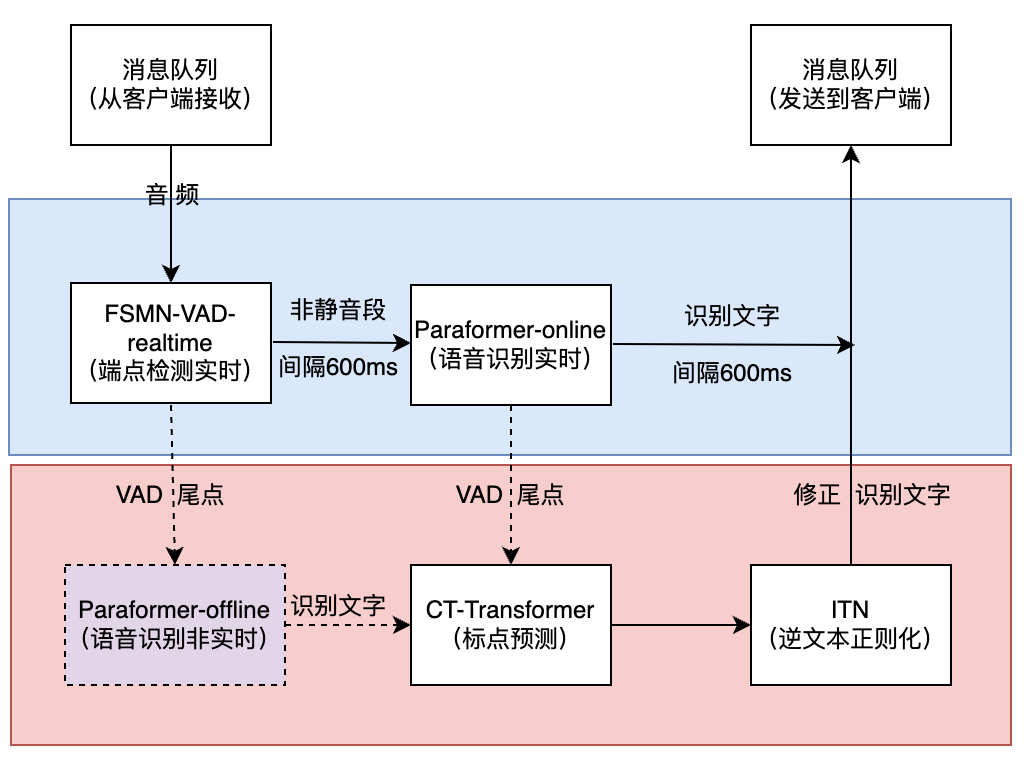
FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。软件包提供有html、python、c++、java与c#等多种编程语言客户端。
FunASR 镜像
- 在线 CPU 版本