FunASR:多模型协同推理与语音处理全链路实践 (ASR, VAD, PUNC, SV)
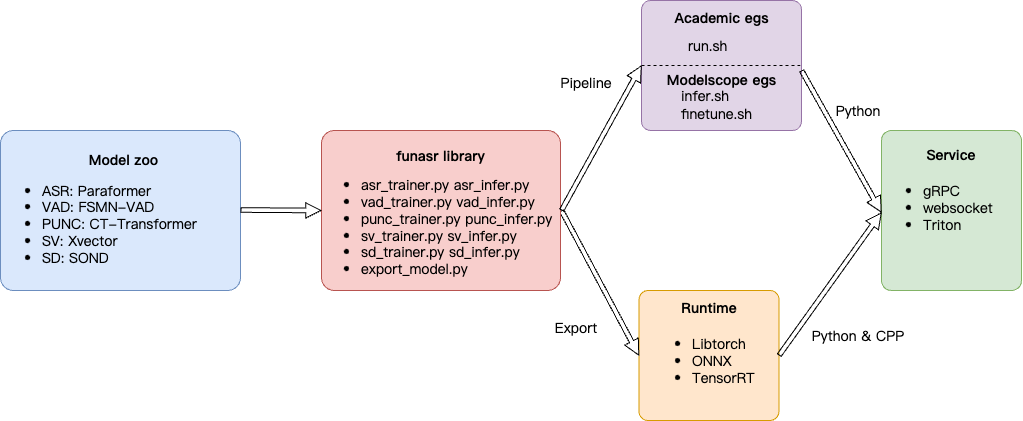
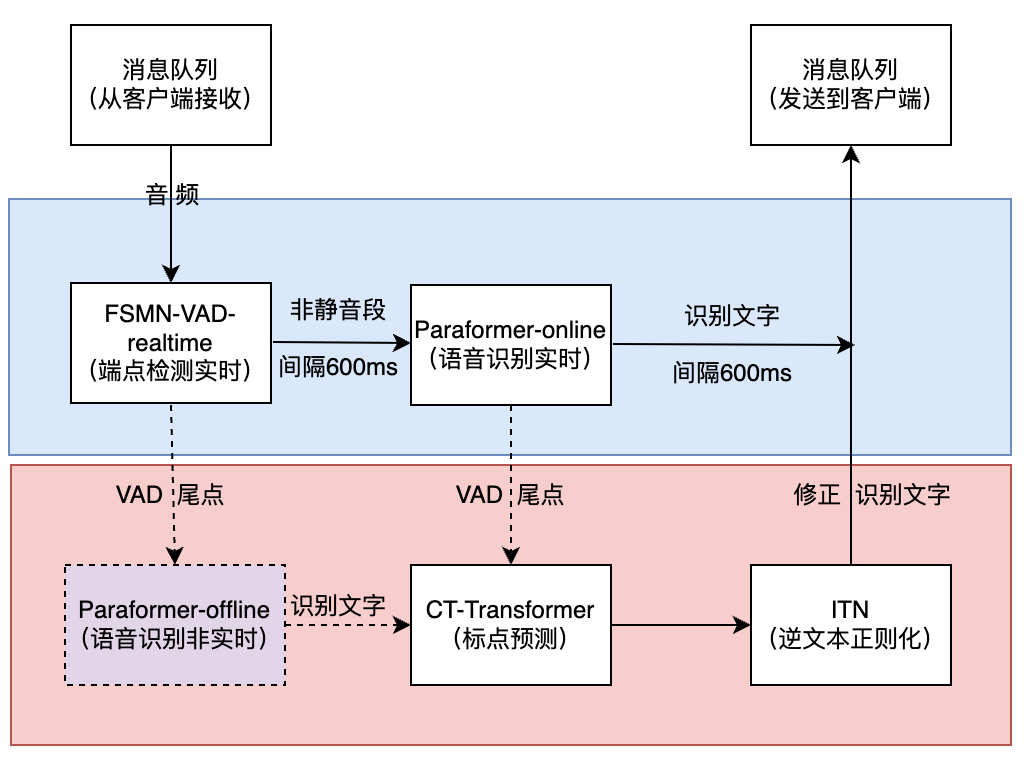
本文详细介绍了 FunASR 这一基础语音识别工具包,它提供了一套完整的语音处理服务,涵盖了离线转写和实时听写两大核心功能。其技术核心在于 AutoModel 多模型协调引擎,能够将不同的组件,如语音活动检测(VAD)、自动语音识别(ASR)、标点恢复和说话人分离(SV),按序串联起来,实现复杂的音频转录任务。文档清晰展示了从原始音频输入到最终带说话人标签的转录结果的完整处理流程和数据流向。此外,本文不仅罗列了支持的多种中英文模型清单,还附带了音频格式转换指南和代码示例。最后,通过实验性能对比,文章论证了在不同硬件上,结合 VAD、PUNC 和 SV 等组件后对推理用时和处理准确性的影响。
ASR 模型综合对比表
| 模型名称 | 中文准确度 | 英文/混合识别 | 可读性 (标点) | 附加功能 | 综合评分 |
|---|---|---|---|---|---|
| Fun-ASR-Nano | 极高 | 完美 | 极佳 | 生产环境级别 | 5.0 |
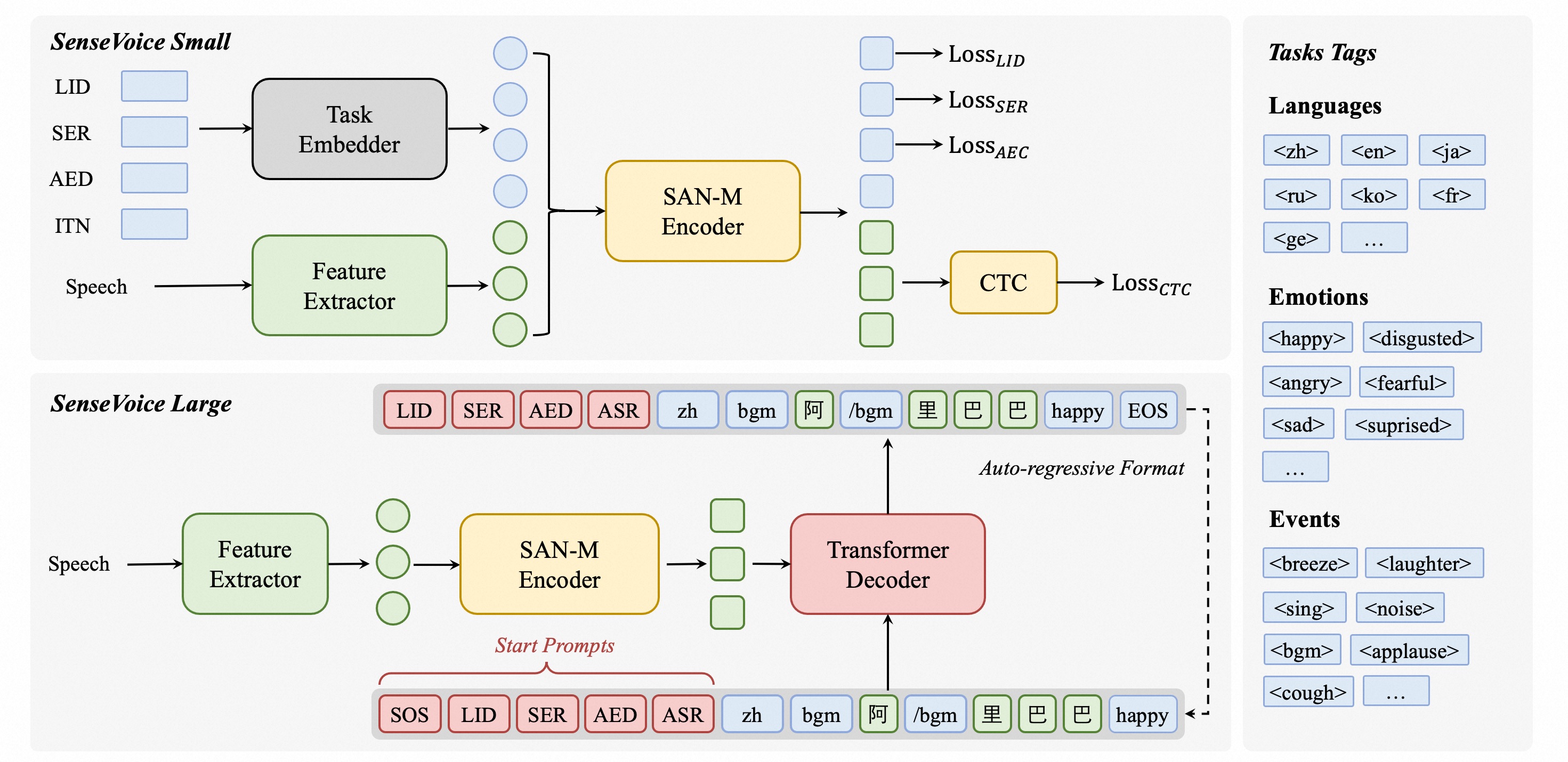
| SenseVoiceSmall | 高 | 较弱 (漏失) | 较好 | 情感/事件检测 | 4.0 |
paraformer-zh (ASR) |
一般 | 极差 | 无 | 原始数据 | 2.0 |
paraformer-zh (+VAD +PUNC) |
高 | 中等 | 优秀 | 自动断句 | 4.5 |
建议:
- 如果你的场景需要极致的准确率和排版,首选 Fun-ASR-Nano。
- 如果你的场景需要分析说话人的情绪,SenseVoiceSmall 是唯一的选择。
- 对于普通的长音频转写,带标点补全的 paraformer-zh 性价比最高。