SenseVoice
SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或声学事件检测(AED)。
SenseVoice
核心功能 🎯
SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测
- 多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理: SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
- 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java 与 c# 等。
架构图
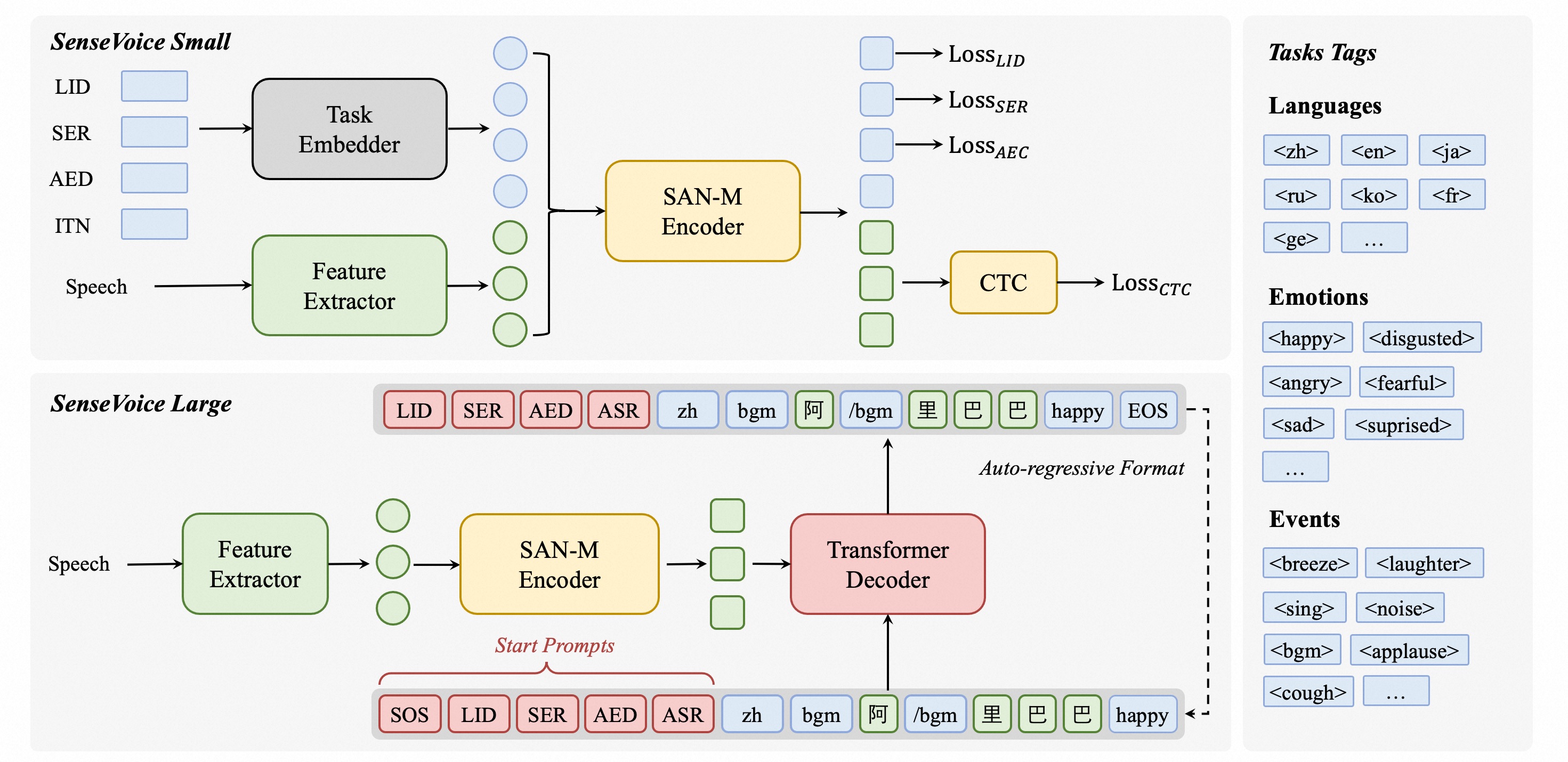
- 语音识别(ASR)
- 语言识别(LID)
- 语音情感识别(SER)
- 音频事件检测(AED,比如笑声、掌声、背景音乐、咳嗽等)
- 逆文本归一化(ITN)
安装
克隆代码库