whisper.cpp
NEON & MPS 🆚 CoreML
下载模型(large-v3)
models/download-ggml-model.sh large-v3
NEON & MPS
编译
make clean
make -j
main 帮助 ./main --help usage: ./main [options] file0.wav file1.wav ...
NEON & MPS 🆚 CoreML
下载模型(large-v3)
models/download-ggml-model.sh large-v3
NEON & MPS
编译
make clean
make -j
main 帮助 ./main --help usage: ./main [options] file0.wav file1.wav ...

SeamlessM4T 概述
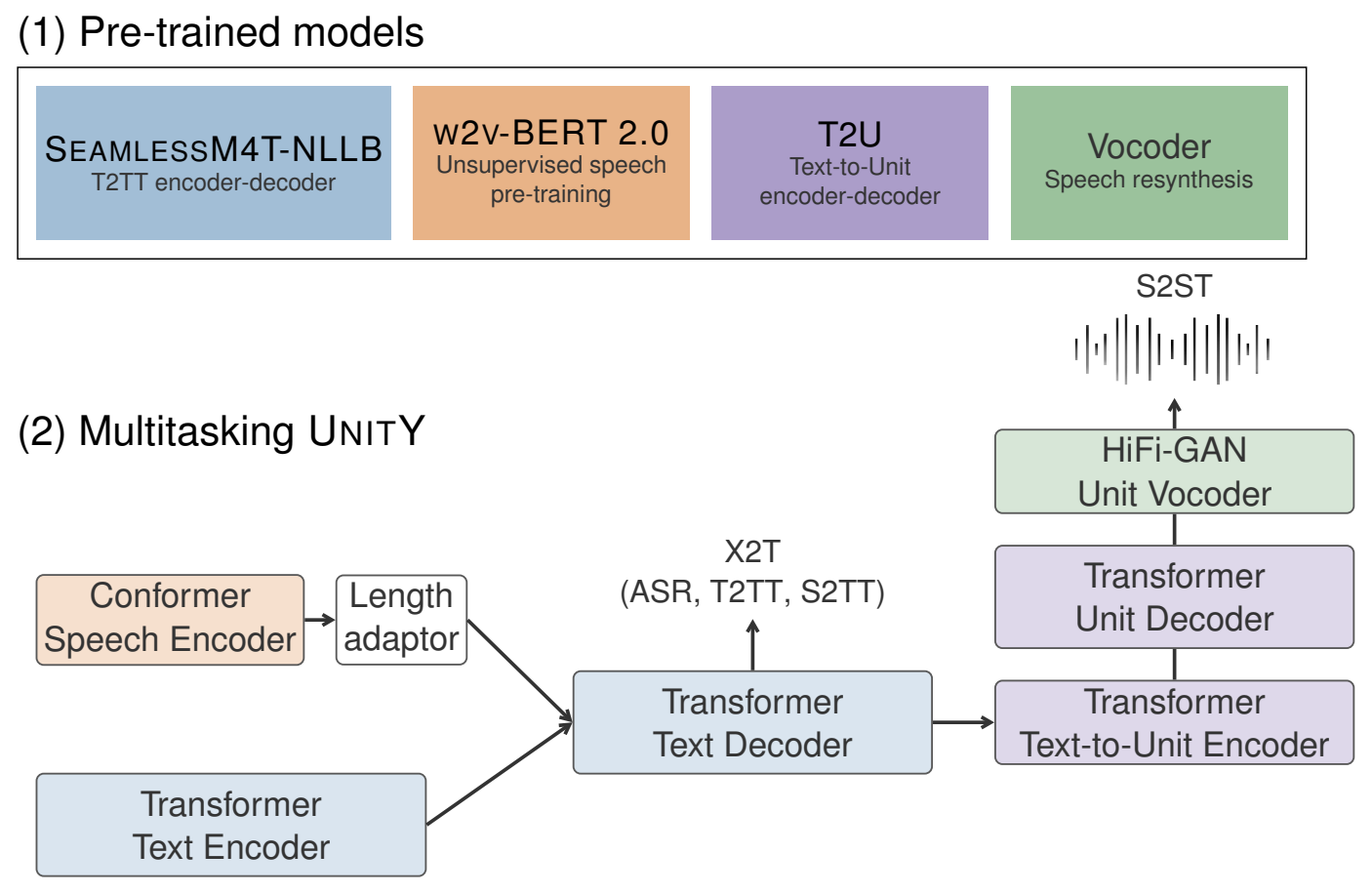
安装 [Seamless Communication][seamless_communication]
克隆仓库 git clone https://github.
该文档详细介绍了 2023年全国行业职业技能竞赛,涵盖了多个技术任务。任务一侧重于语音处理,通过Python代码展示了如何利用腾讯云API进行语音识别和语音合成,包括音频文件的Base64编码转换和请求参数配置,并输出了实际的识别结果。任务二则聚焦于语音模型,阐述了声学模型的初始化、加载预训练模型以及语音识别的整个流程,并提到了模型训练的配置。任务三涉及文本处理,通过requests库抓取网页内容,并利用re、BeautifulSoup和lxml.etree等工具进行网页内容解析和文本提取,同时展示了文本清洗、数据扩充以及使用Stanford CoreNLP进行中文分词、词性标注和命名实体识别。任务四是数据分析与可视化,展示了如何从Excel文件中读取急诊科就诊数据,并计算男女比例、每日就诊人数和各诊室就诊人数,最终通过matplotlib库生成饼状图、柱状图和折线图进行数据可视化。
2023年全国行业职业技能竞赛 第二届全国电子企业职业技能竞赛
任务一
任务1.1
任务1.2
Whisper
功能
文件上传目前限制为 25 MB,并且支持以下输入文件类型:mp3, mp4, mpeg, mpga, m4a, wav, webm.
语音内容
Mira Murati 是一位对人工智能技术充满热情的科技领袖,她的理念和影响对人工智能技术的发展和应用产生了深远的影响。
她认为人工智能技术应该是以人为本的,强调人工智能技术应该是一种能够服务于人类的工具,而不是取代人类的工具。
她指出,人工智能技术的最终目的是为人类服务,因此人工智能技术应该以人类的利益和需求为中心,以解决人类面临的实际问题。人工智能技术的应用需要深入了解人类社会的需要和价值,将其应用到真正有意义的领域中。
OpenAI Whisper
安装 OpenAI
!pip install -U openai
测试
语音识别
import openai
audio_file= open("data/audios/test.m4a", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
print(transcript["text"])
Miramurati是一位对人工智能技术充满热情的科技领袖 他的
开发文档
查看音频文件信息
file
data/podcast_clip.mp3: Audio file with ID3 version 2.4.0, contains: MPEG ADTS, layer III, v1, 64 kbps, 44.1 kHz, Stereo
ffprobe ffprobe -hide_banner data/podcast_clip.mp3 Input #0, mp3, from 'data/podcast_clip.mp3': Metadata: major_brand : M4A minor_version : 512 compatible_brands: M4A isomiso2 date : 2023-02-06 14:59 title : "Clip created on ListenNotes.com" encoder : Lavf58.76.100 Duration: 00:03:00.04, start: 0.025057, bitrate: 128 kb/s Stream #0:0: Audio: mp3, 44100 Hz, stereo, fltp, 128 kb/s Metadata: encoder : Lavc58.
介绍
PaddleSpeech 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
功能
学习
安装
conda create -n paddlespeech python==3.10.9
conda activate paddlespeech
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install pytest-runner paddlespeech
pip install "numpy<1.24"
测试数据下载
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/en.wav
FAQ paddlespeech asr --lang zh --input zh.
准备音频文件
macOS 上打开 QuickTimePlayer
m4a 转换 wav
ffmpeg -i test.m4a -ar 16000 -ac 1 -c:a pcm_s16le test.wav
创建虚拟环境
conda create --name whisper python
conda activate whisper
安装
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
wget https://raw.githubusercontent.com/openai/whisper/main/requirements.txt
pip install -r requirements.txt
测试 模型默认保存在 ~/.cache/whisper ls ~/.cache/whisper base.pt large-v2.
树莓派4
硬件概述

烧录系统
wget https://downloads.raspberrypi.org/rpd_x86/images/rpd_x86-2021-01-12/2021-01-11-raspios-buster-i386.iso
dd if=2021-01-11-raspios-buster-i386.iso of=/dev/sdc bs=10M
ReSpeaker 2-Mics Pi HAT

ReSpeaker 2-Mics Pi HAT是专为AI和语音应用设计的Raspberry Pi双麦克风扩展板。 这意味着您可以构建一个集成Amazona语音服务等的功能更强大,更灵活的语音产品。
该板是基于WM8960开发的低功耗立体声编解码器。 电路板两侧有两个麦克风采集声音,还提供3个APA102 RGB LED,1个用户按钮和2个板载Grove接口,用于扩展应用程序。 此外,3.5mm音频插孔或JST 2.0扬声器输出均可用于音频输出。
硬件概述

产品特征

配置
$ sudo raspi-config
打开 I2C