基于 DSpark 的投机解码训练框架原理与实现(论文+代码对照)
结合 DSpark 论文与代码实现,全面剖析 DeepSpec 的工作原理与核心组件。
项目地址:https://github.com/deepseek-ai/DeepSpec DSpark 论文:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
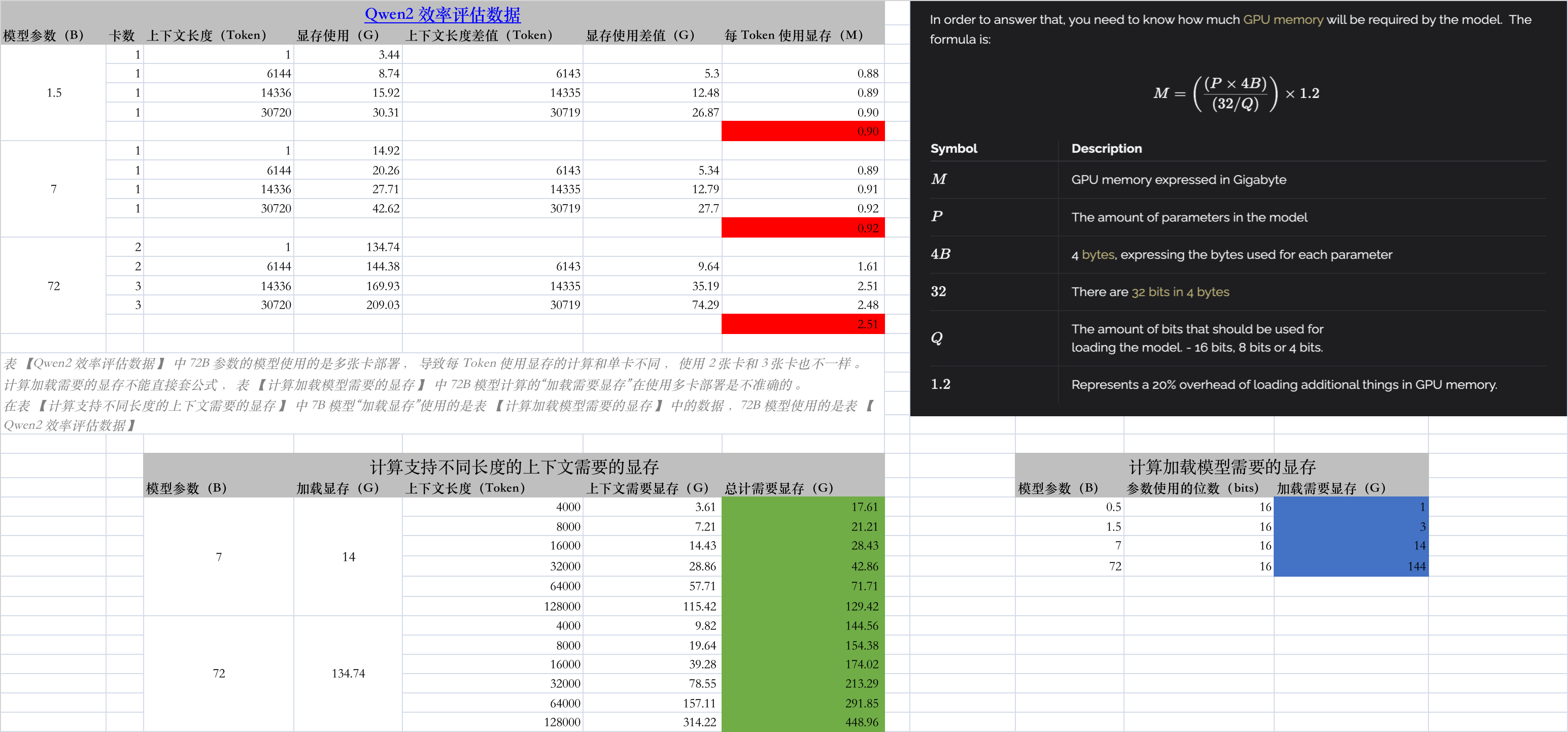
DSpark 是 DeepSeek 提出的一套无损加速大模型推理的“看人下菜碟”机制。 传统加速手段(推测解码)通常是让小模型一次性盲目盲猜一大串后续 Token,再让大模型统一验证。但这存在两个痛点:小模型猜得越往后越不准(多模态冲突导致“后缀衰减”);高并发时,大模型花大力气去验证那些猜得不准的 Token,会严重压垮系统吞吐。
DSpark 的核心突破就在于两点:
- 猜得更准(半自回归): 它在原有的单次并行生成网络后,拼了一个极轻量的小尾巴(顺序头),在几乎不增加延迟的情况下,让后面的 Token 能根据前面猜出的 Token 进行自适应修正,大幅提升长序列的猜测准确度。
- 动态裁剪(置信度调度): 它能实时感知系统的硬件负载与并发压力。如果并发高、大模型很忙,或者发现后面小模型猜的置信度太低,它就会果断把不靠谱的后缀砍掉,只送靠谱的前缀给大模型验证。
通过这种“高质量猜测”与“负载感知动态裁剪”的结合,DSpark 在保障大模型输出质量完全无损的前提下,成功