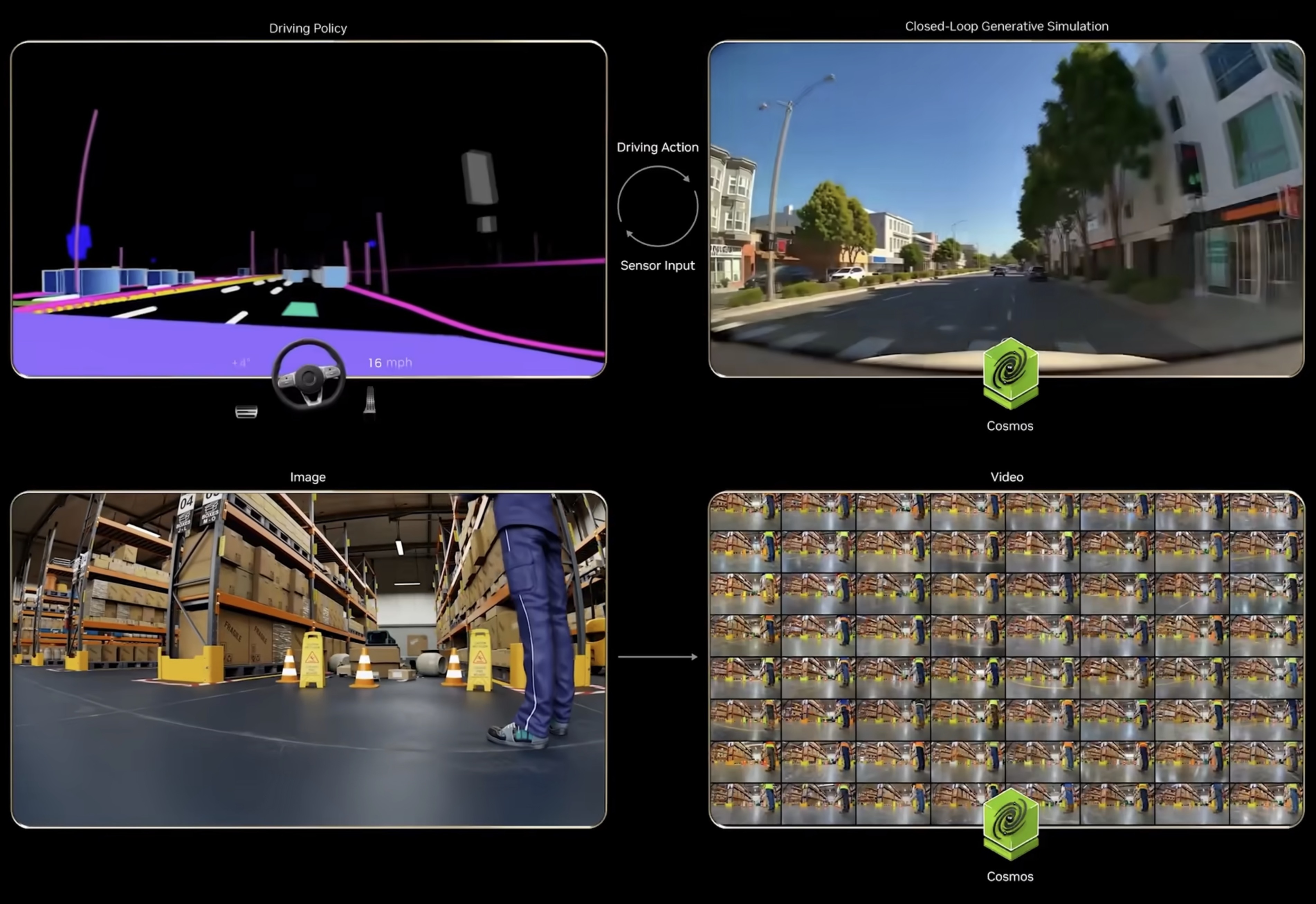
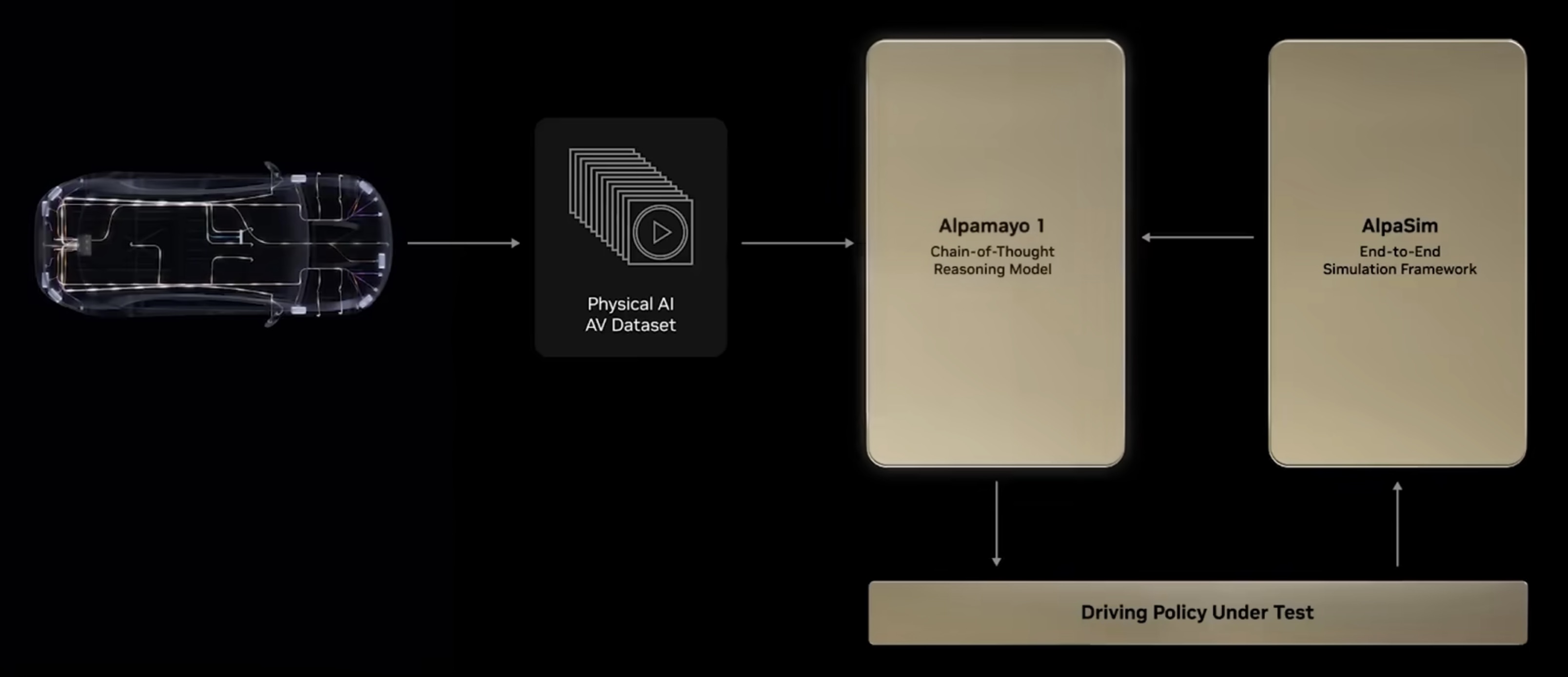
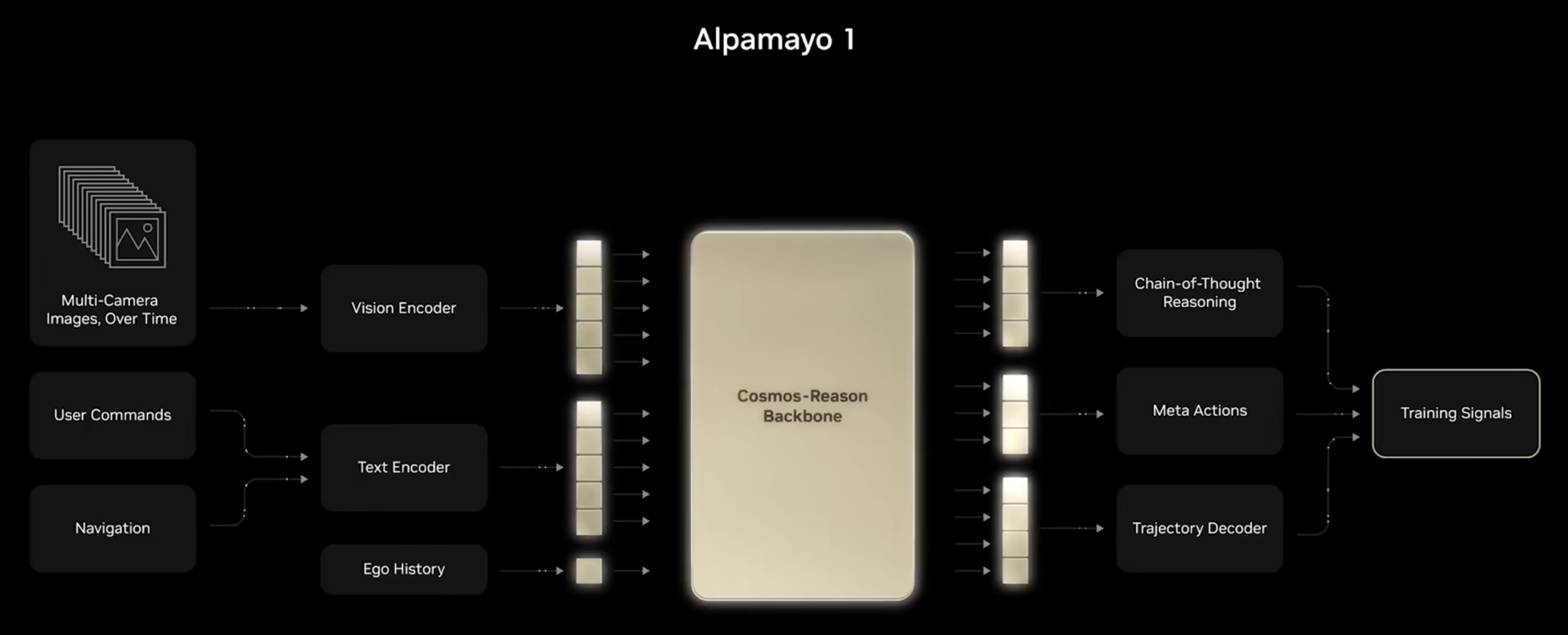
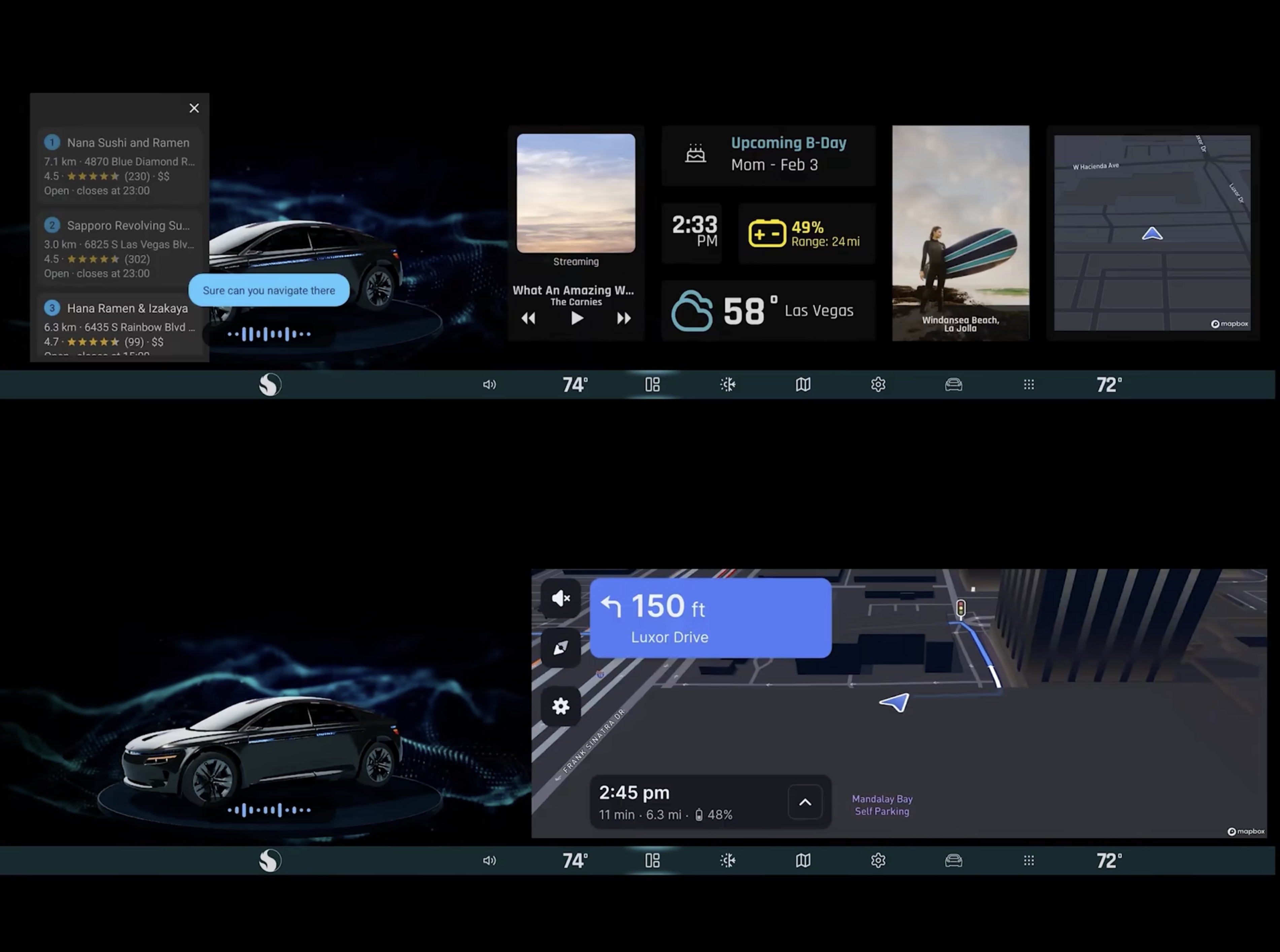
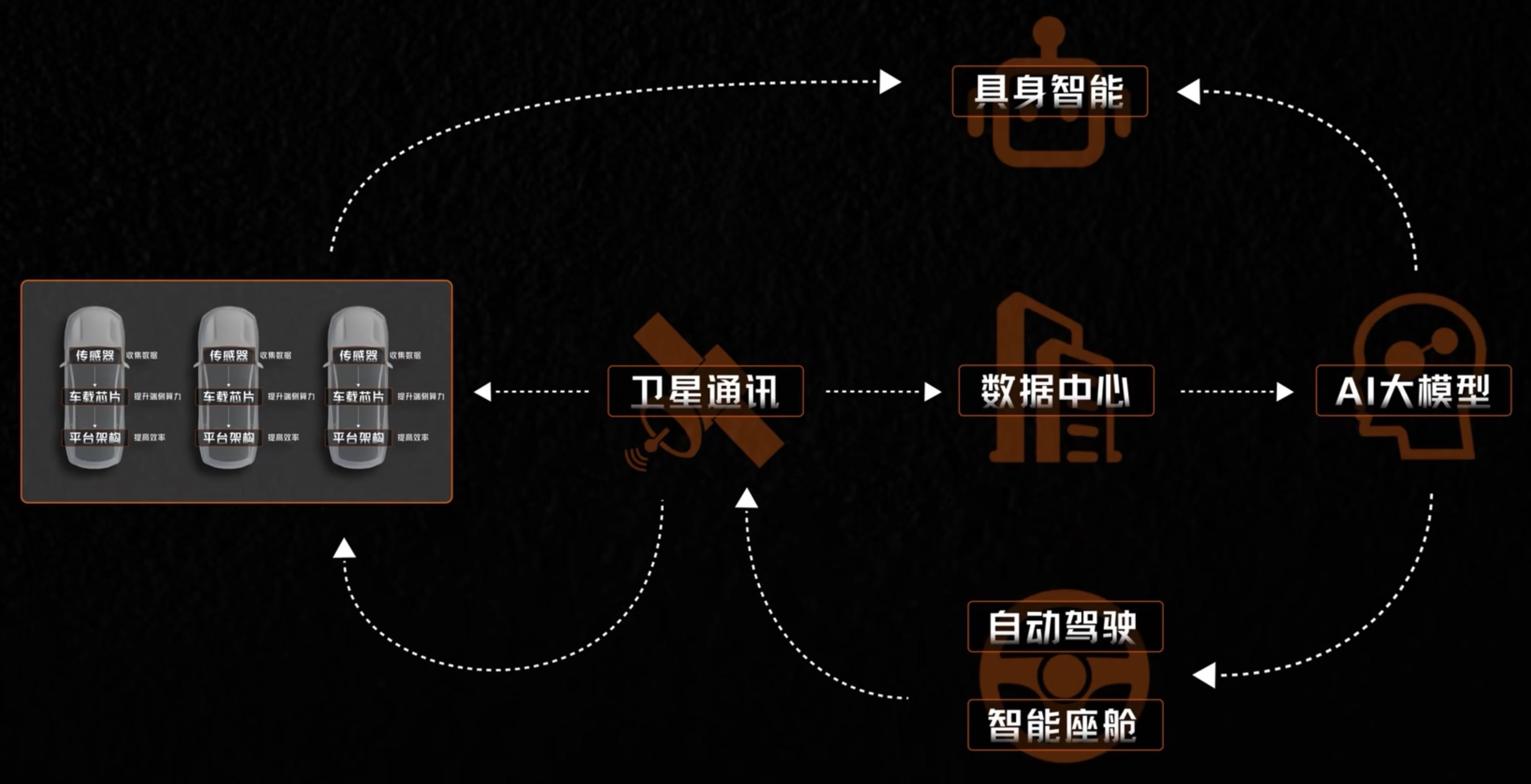
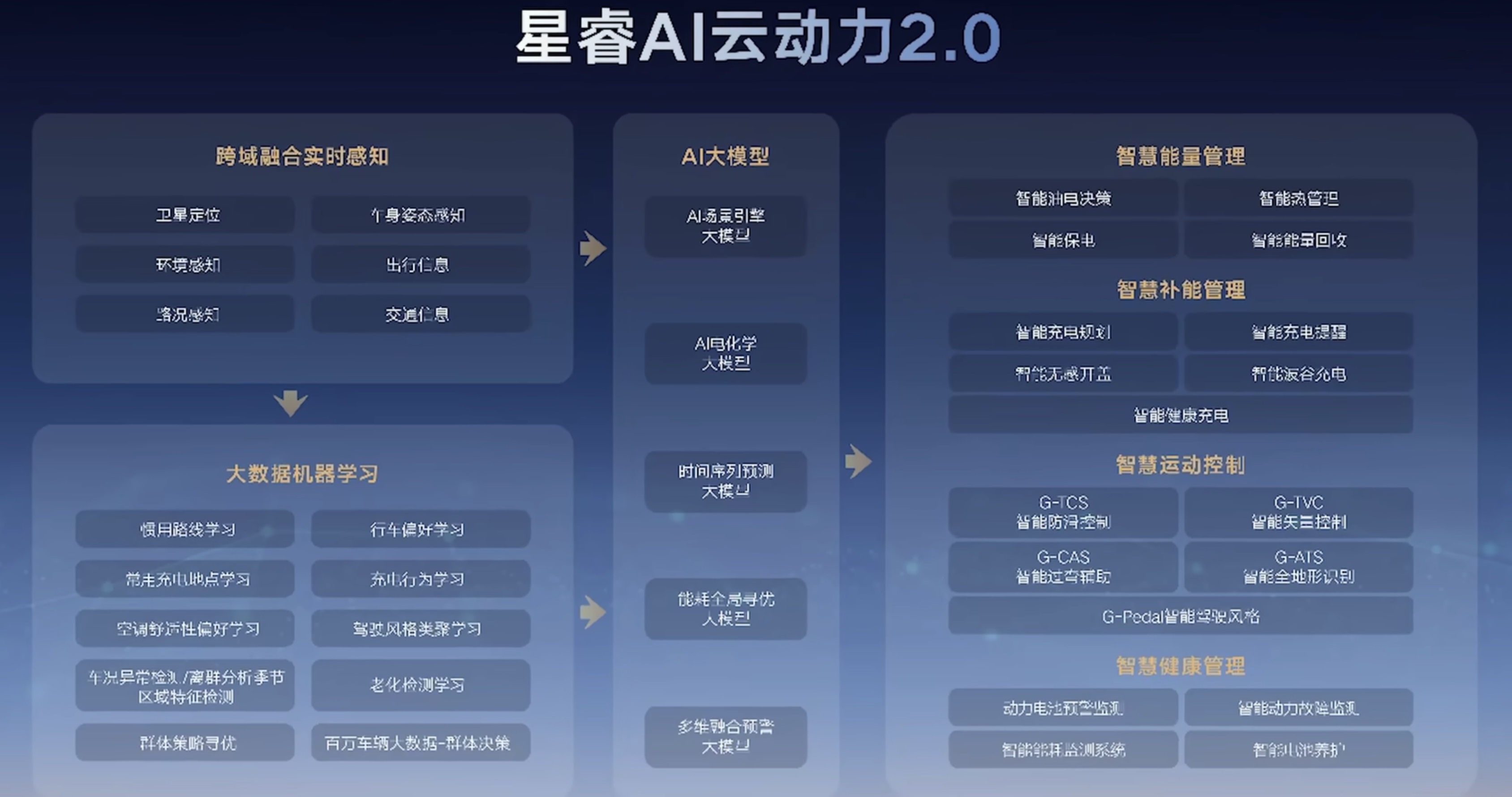
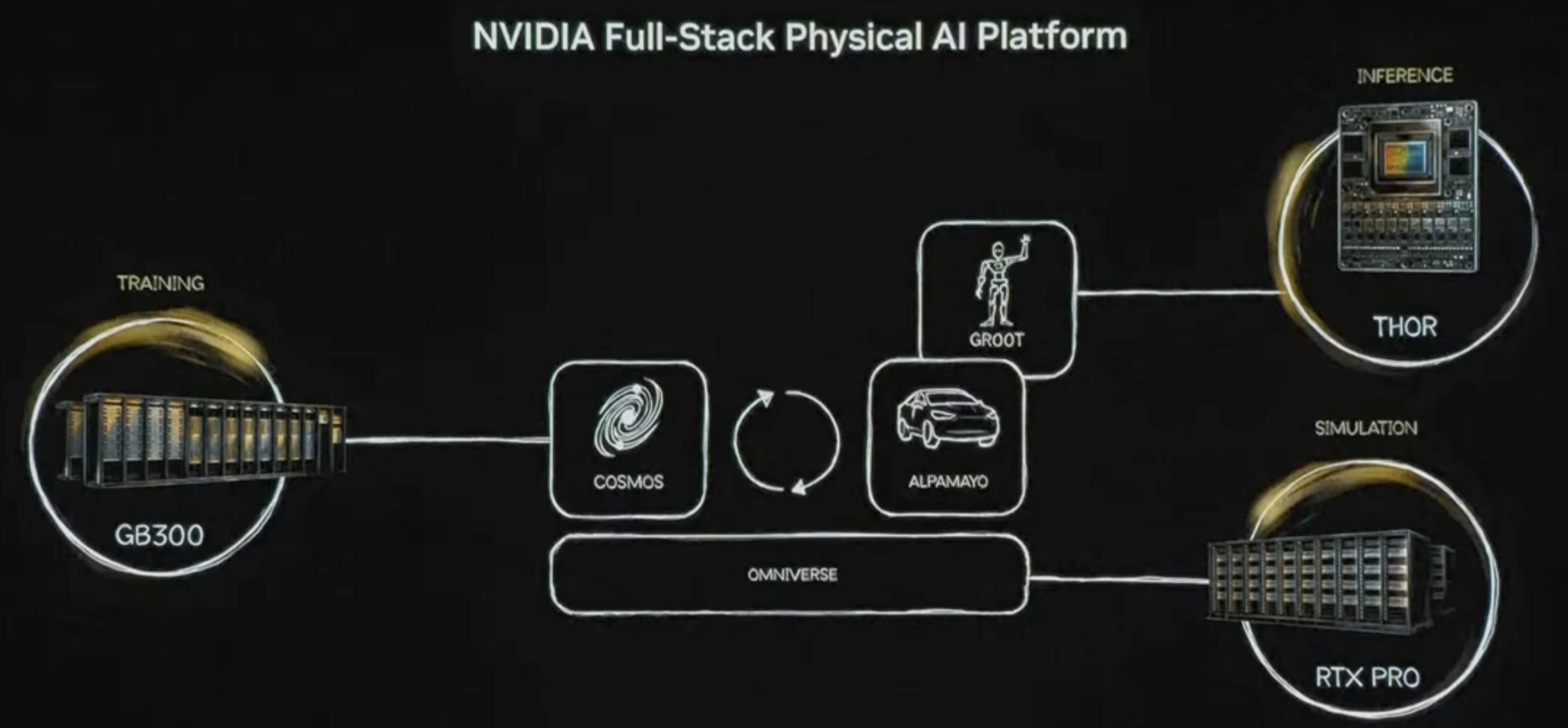
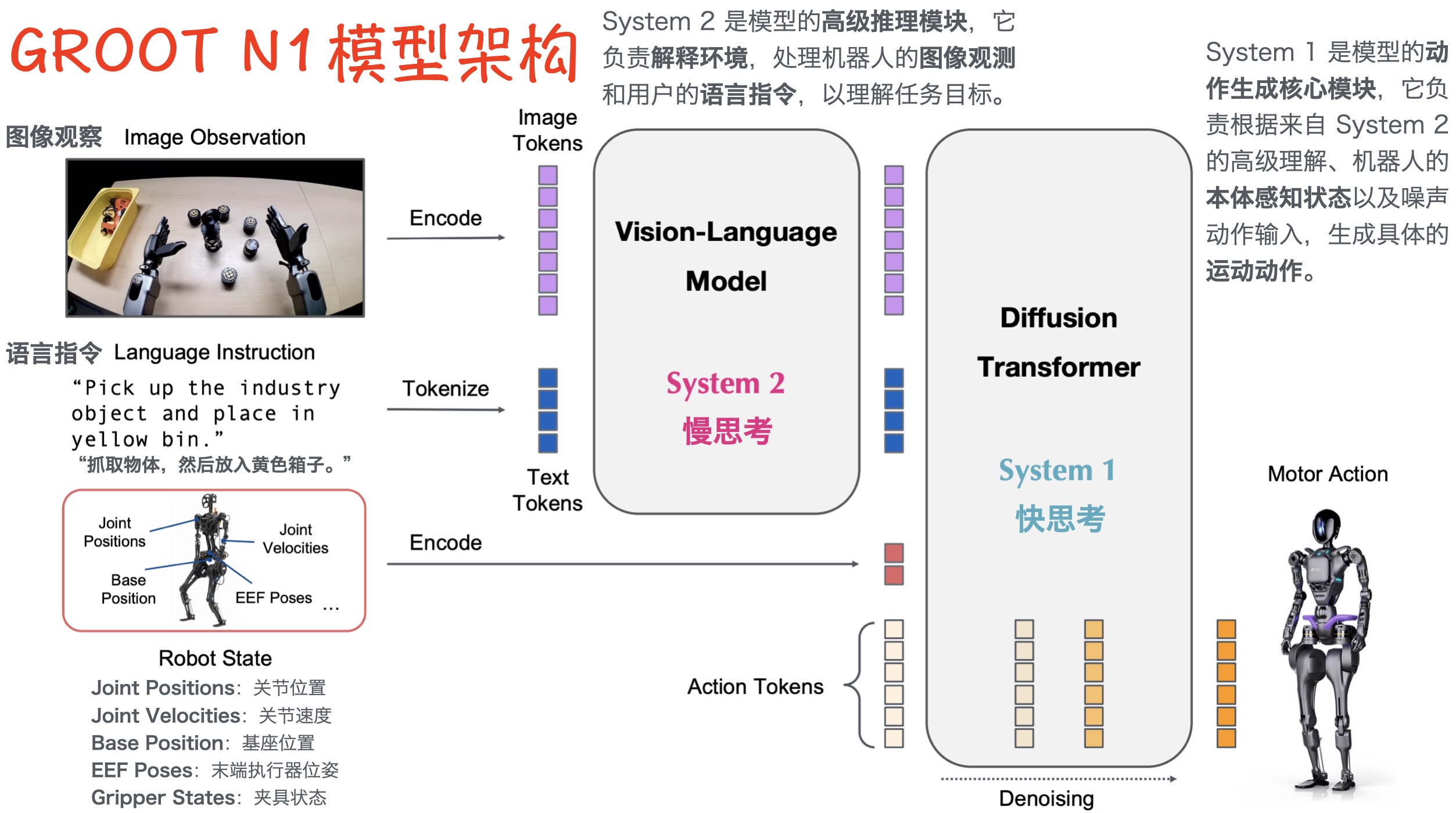
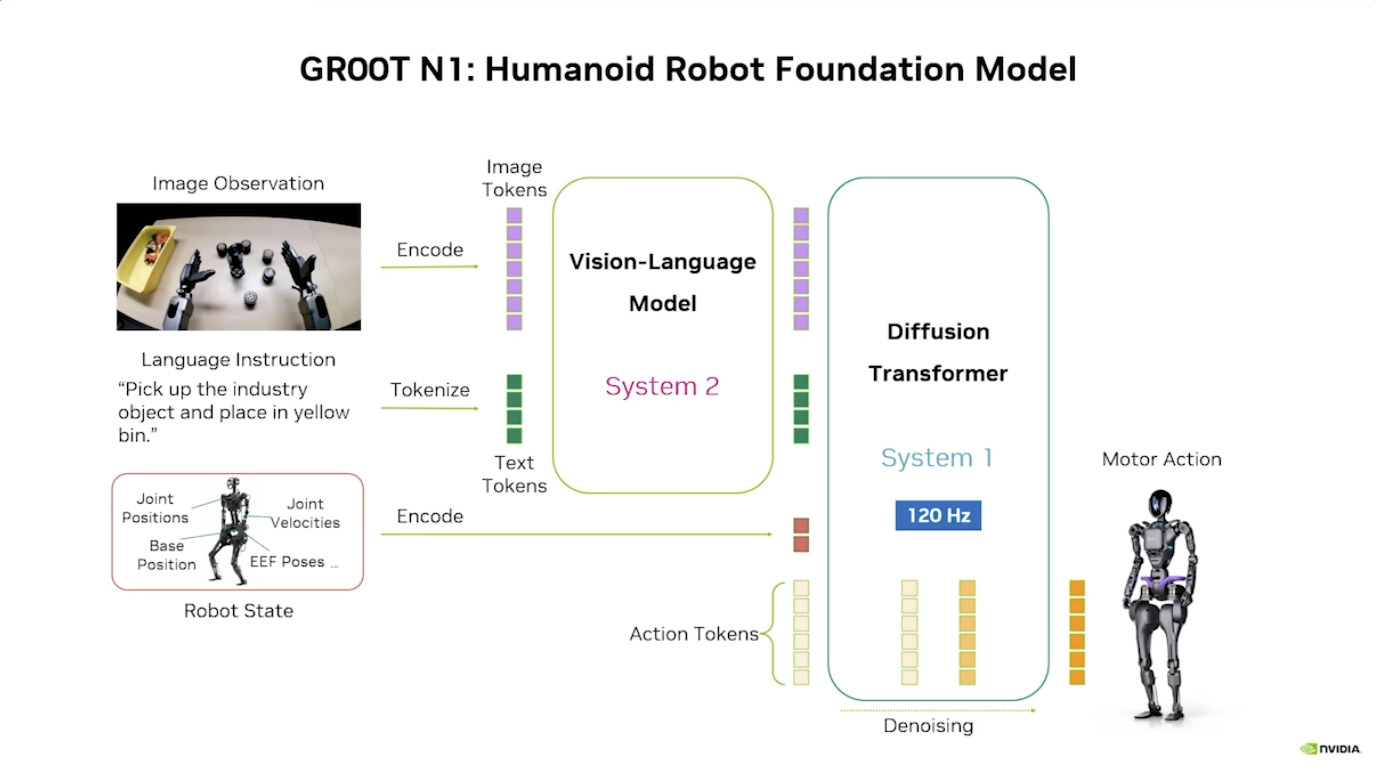
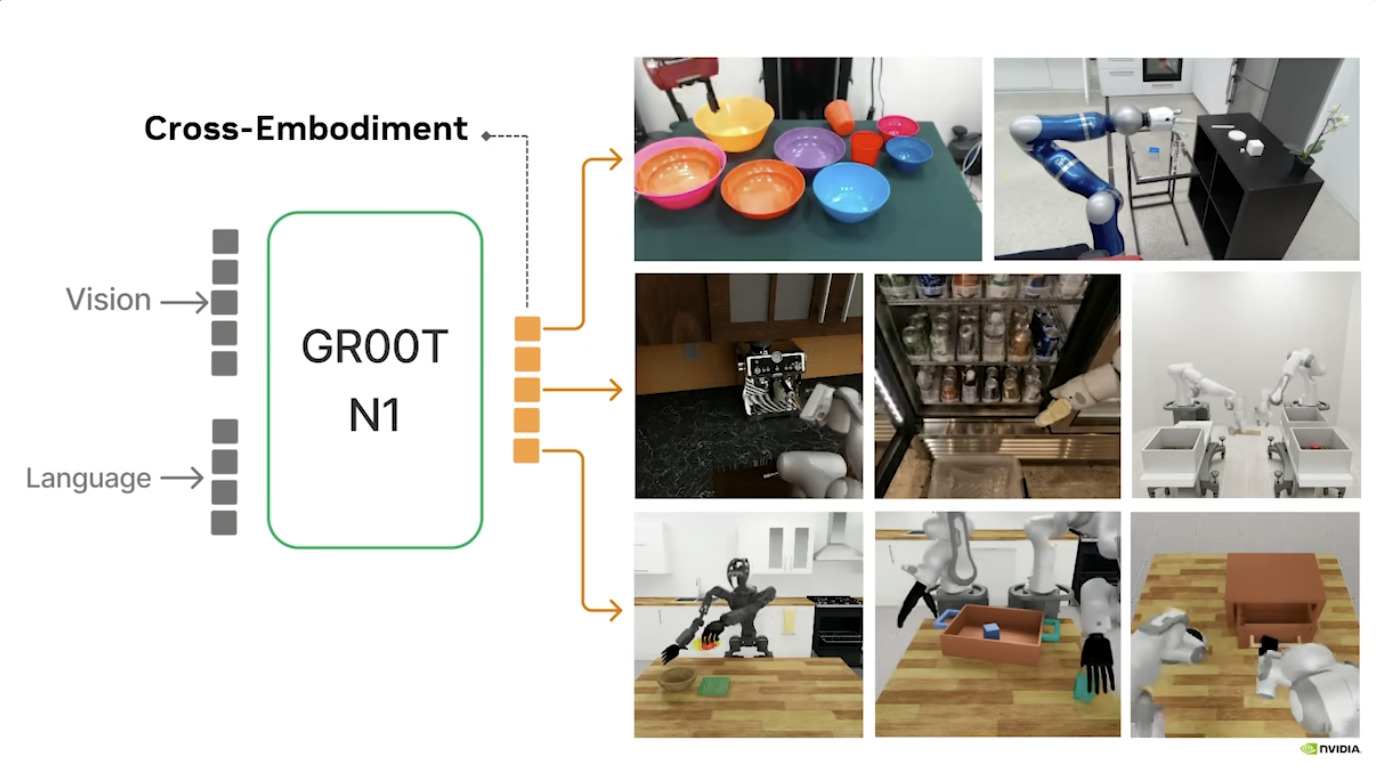
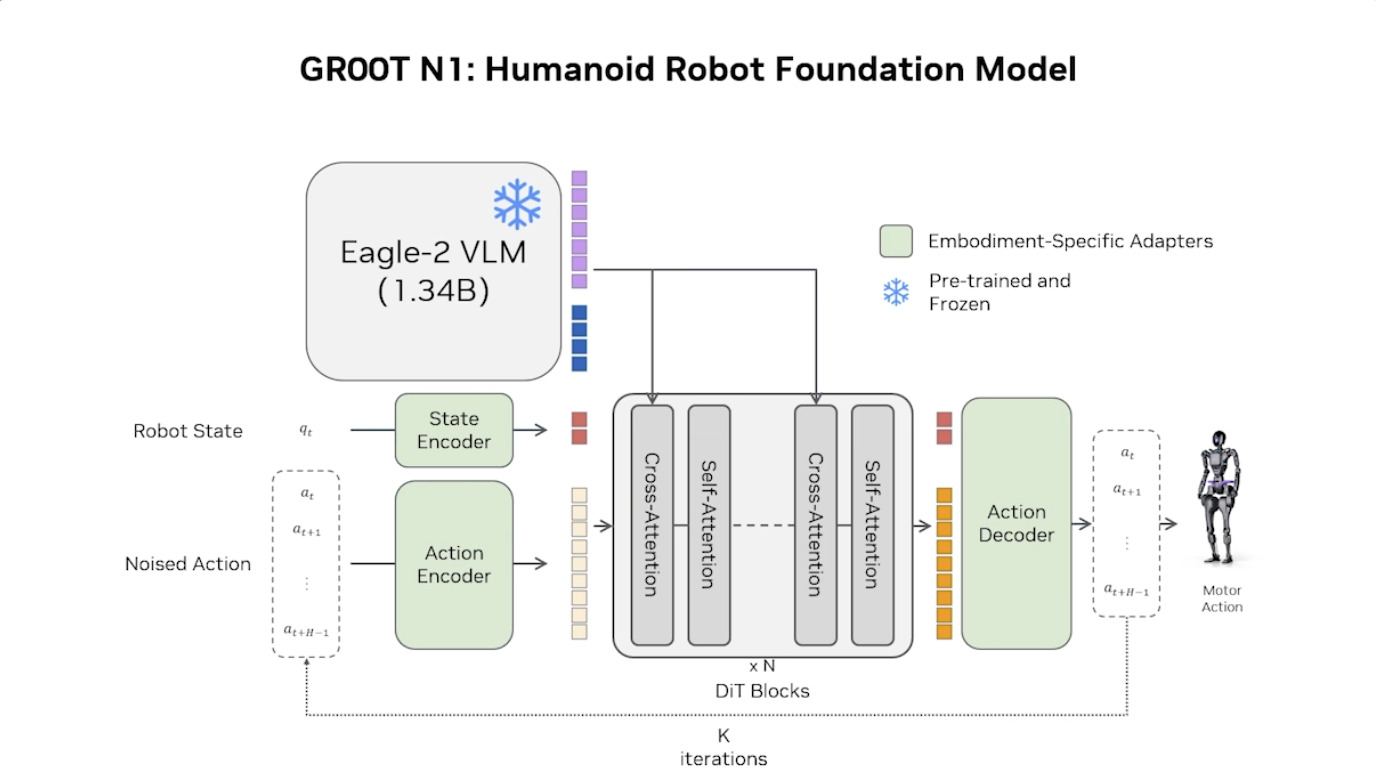
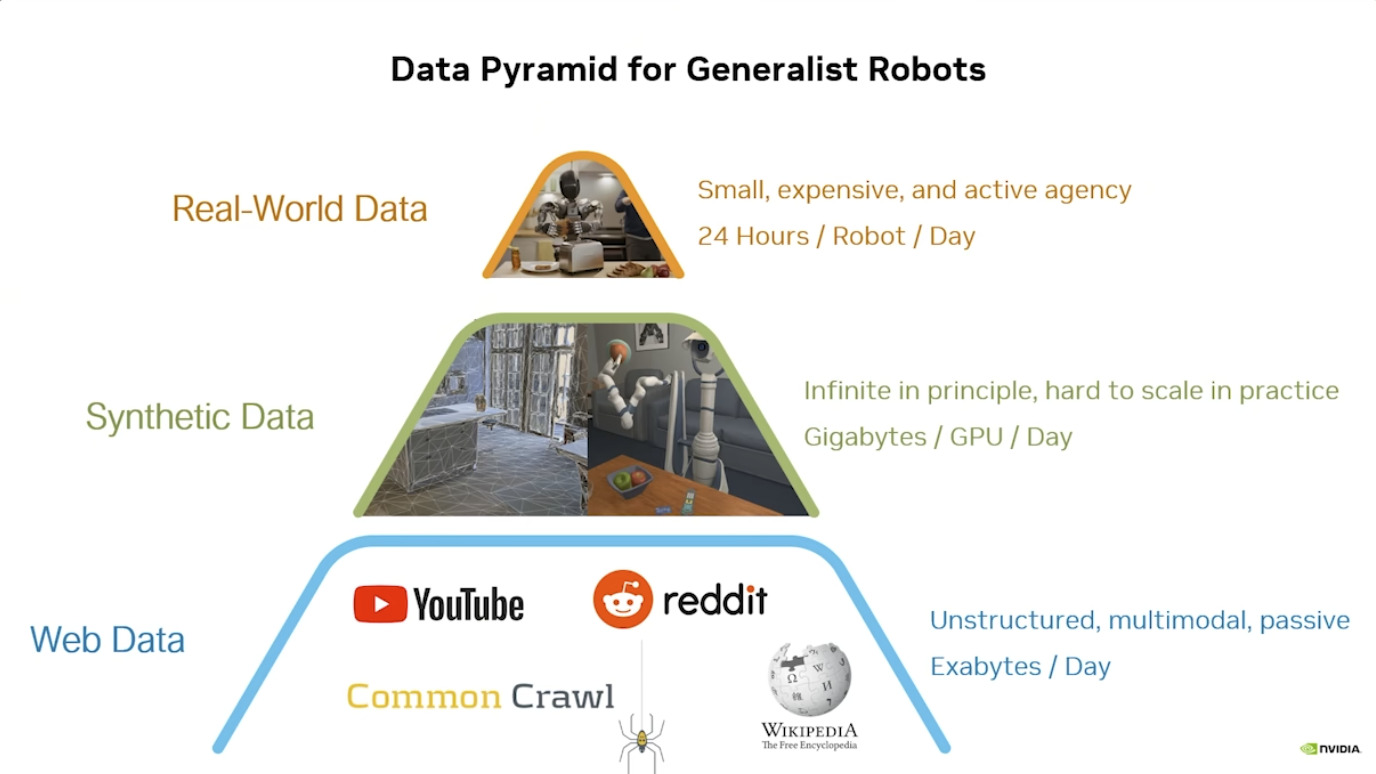
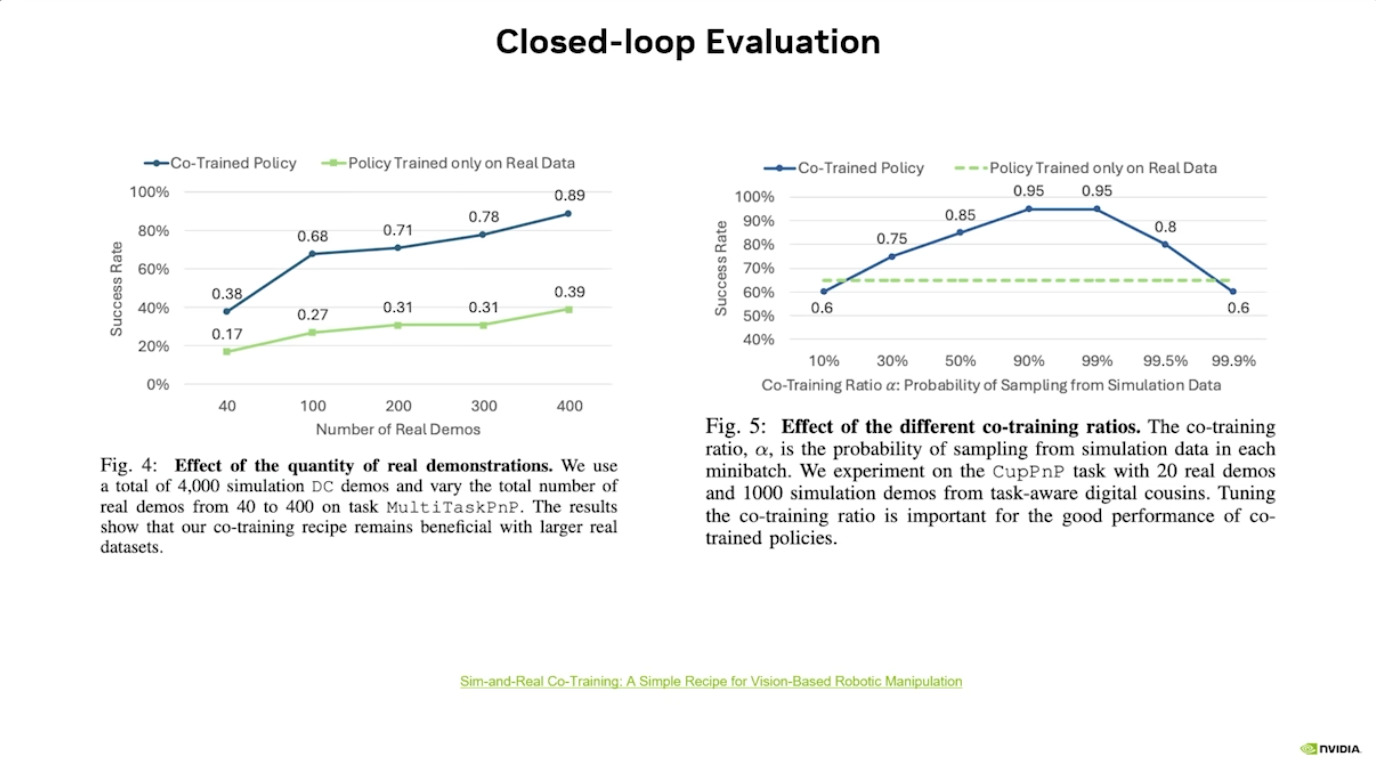
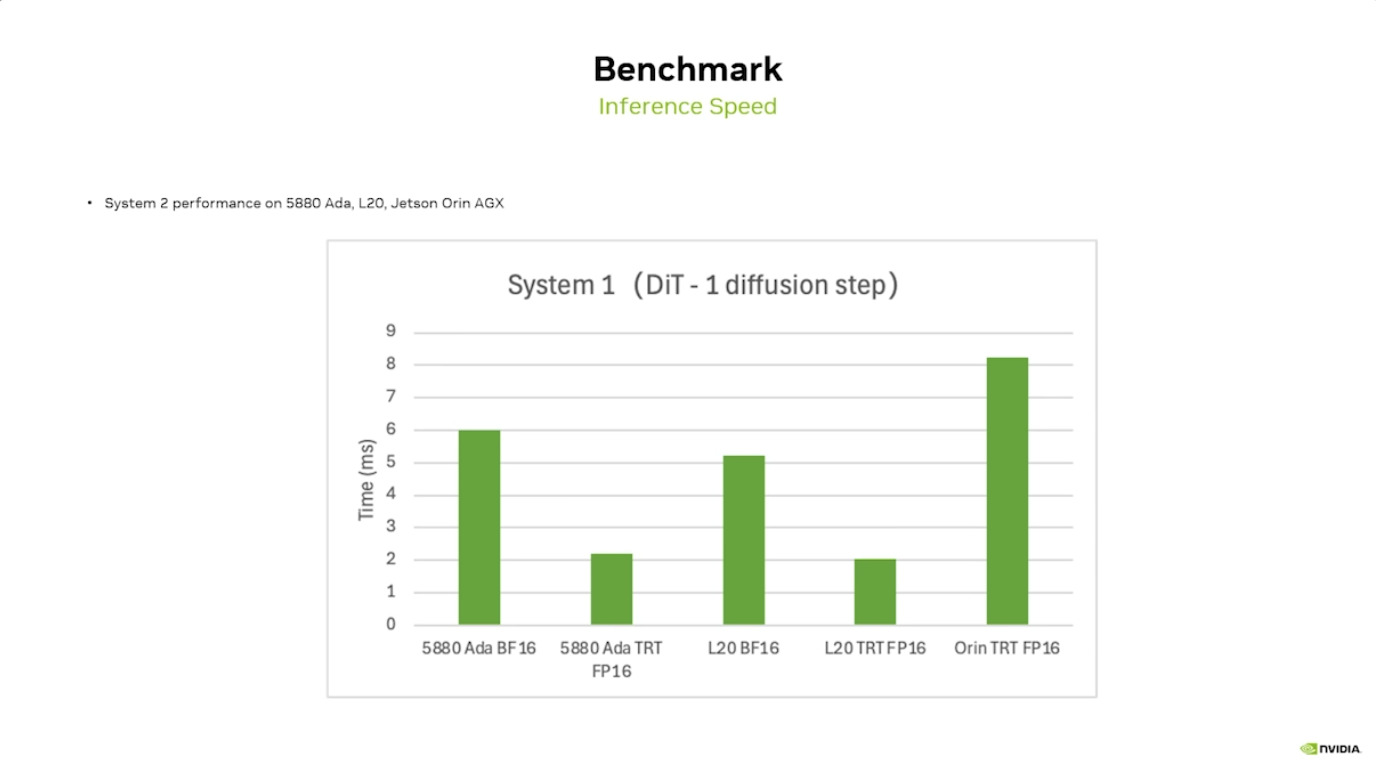
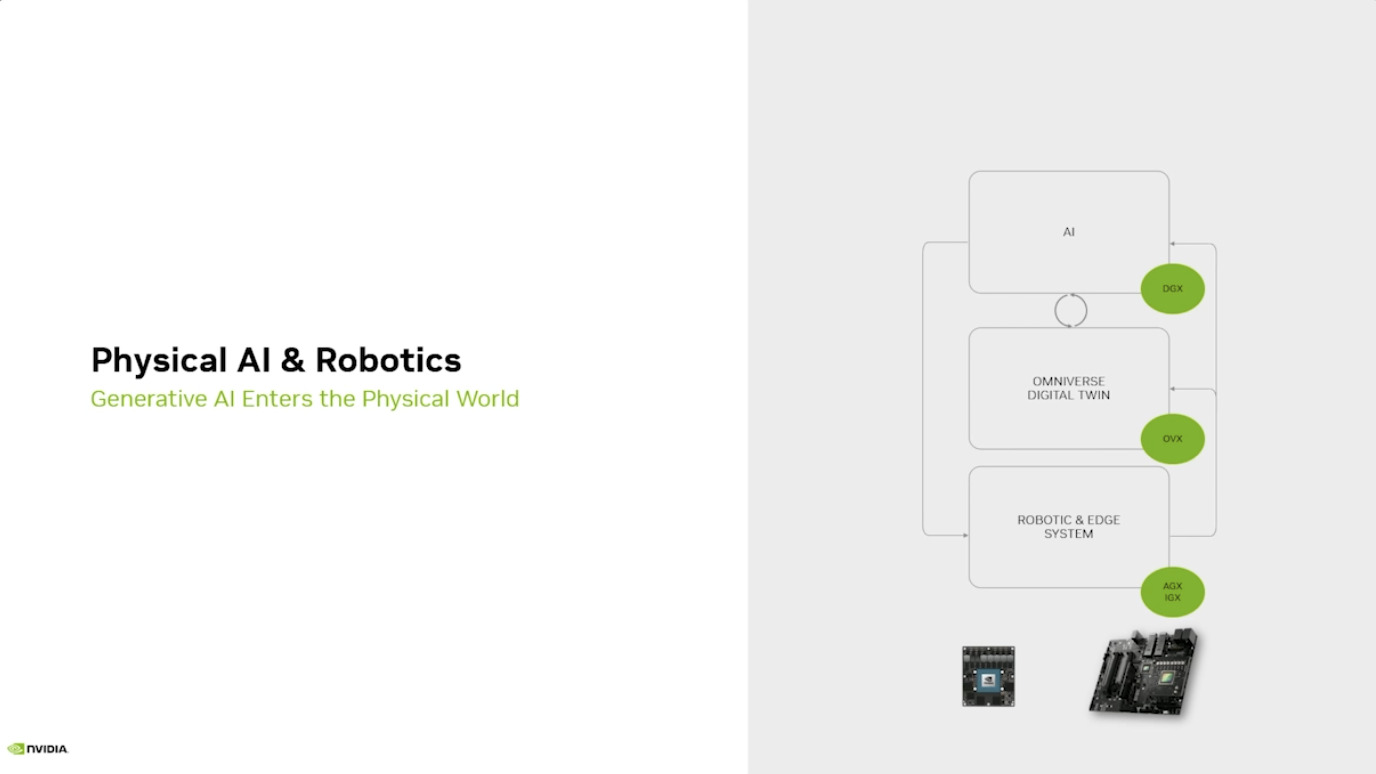
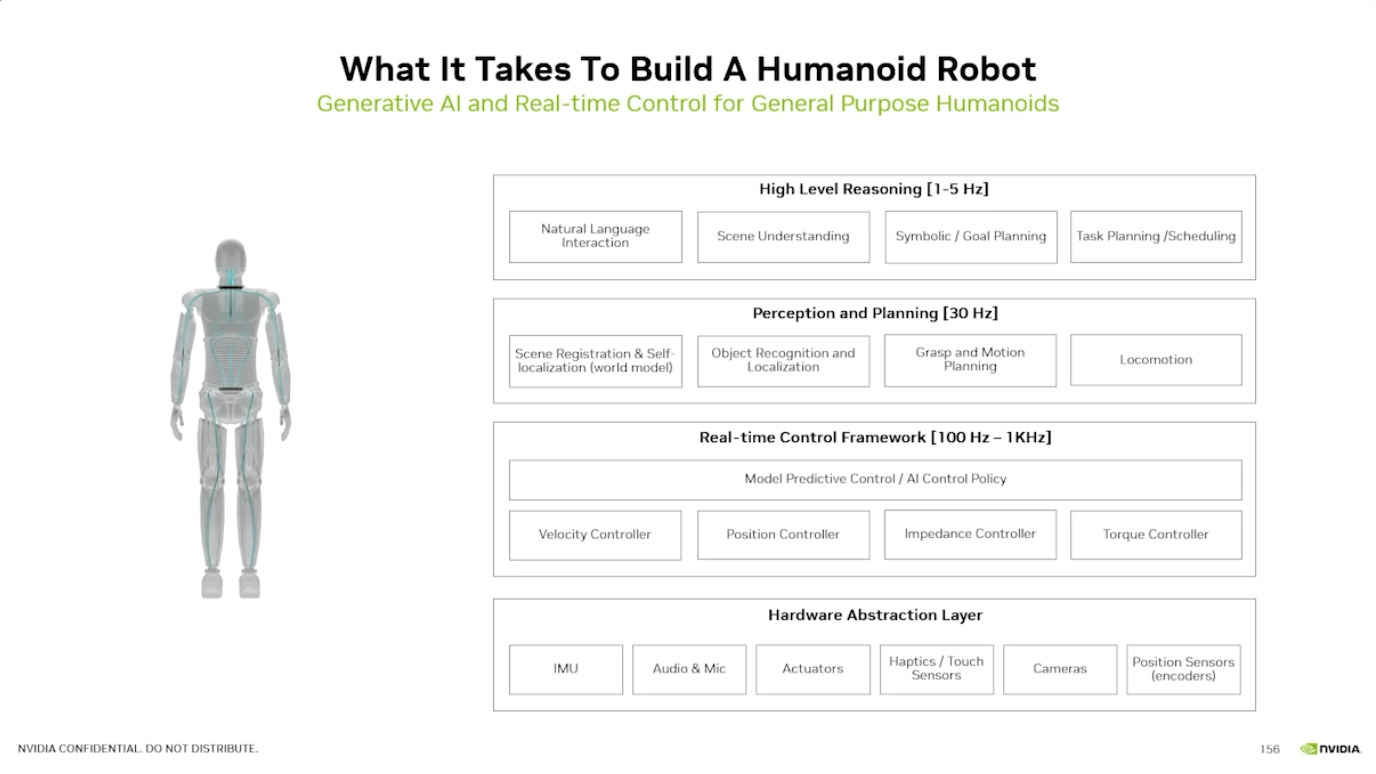
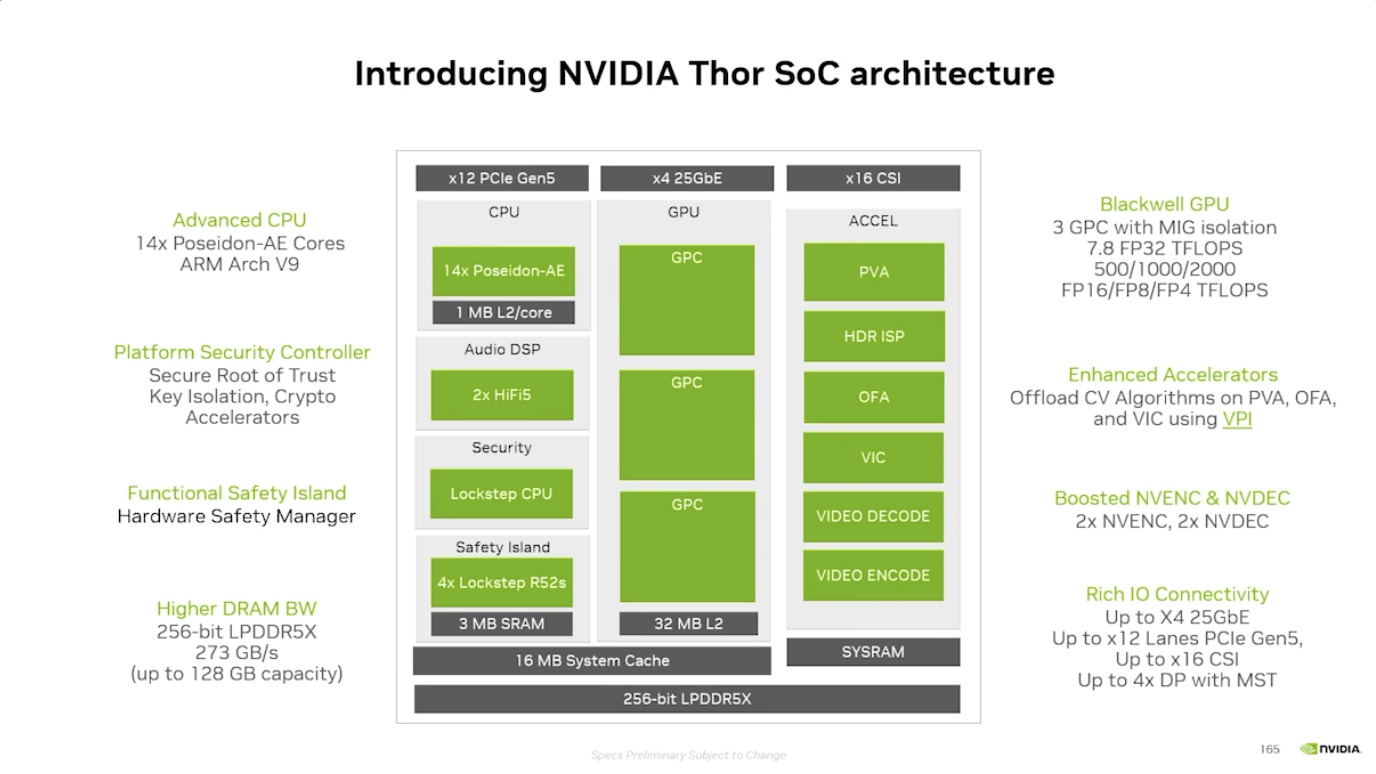
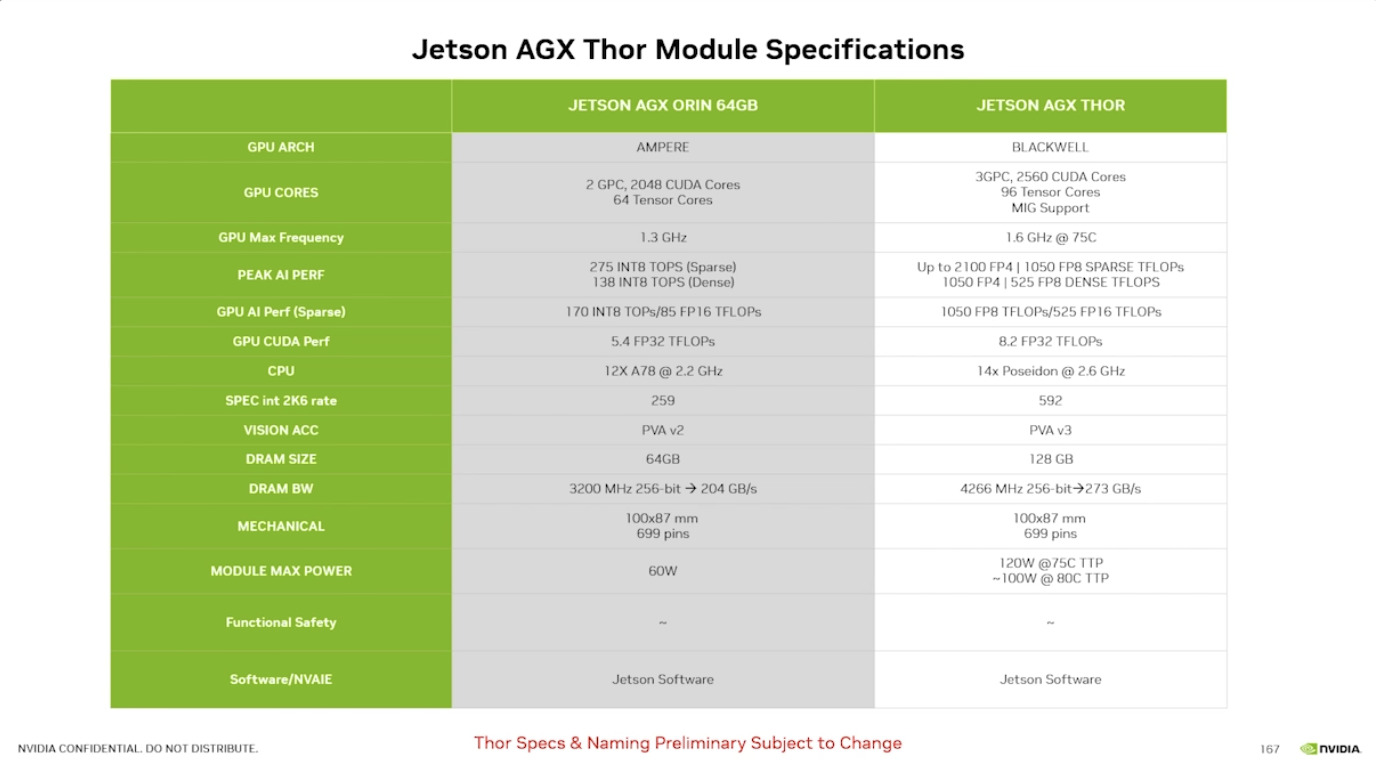
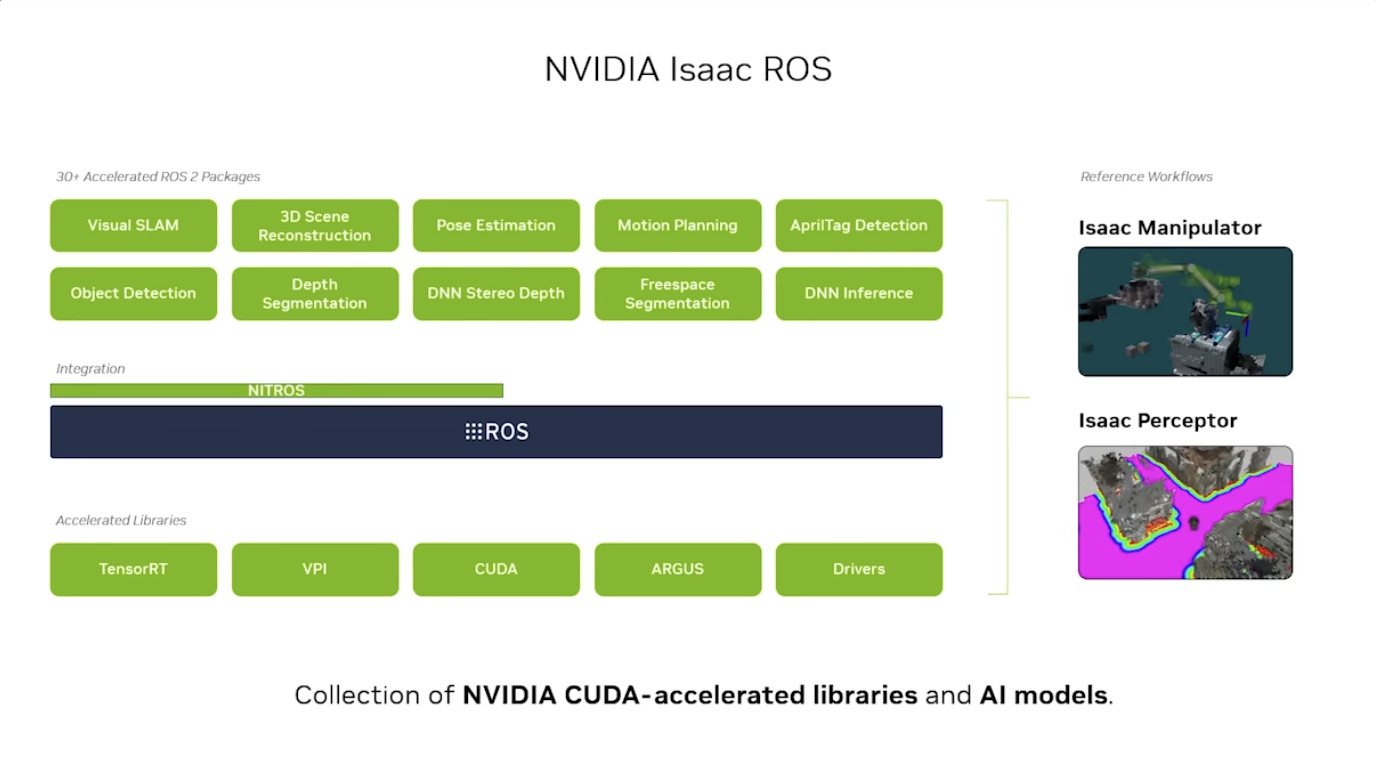
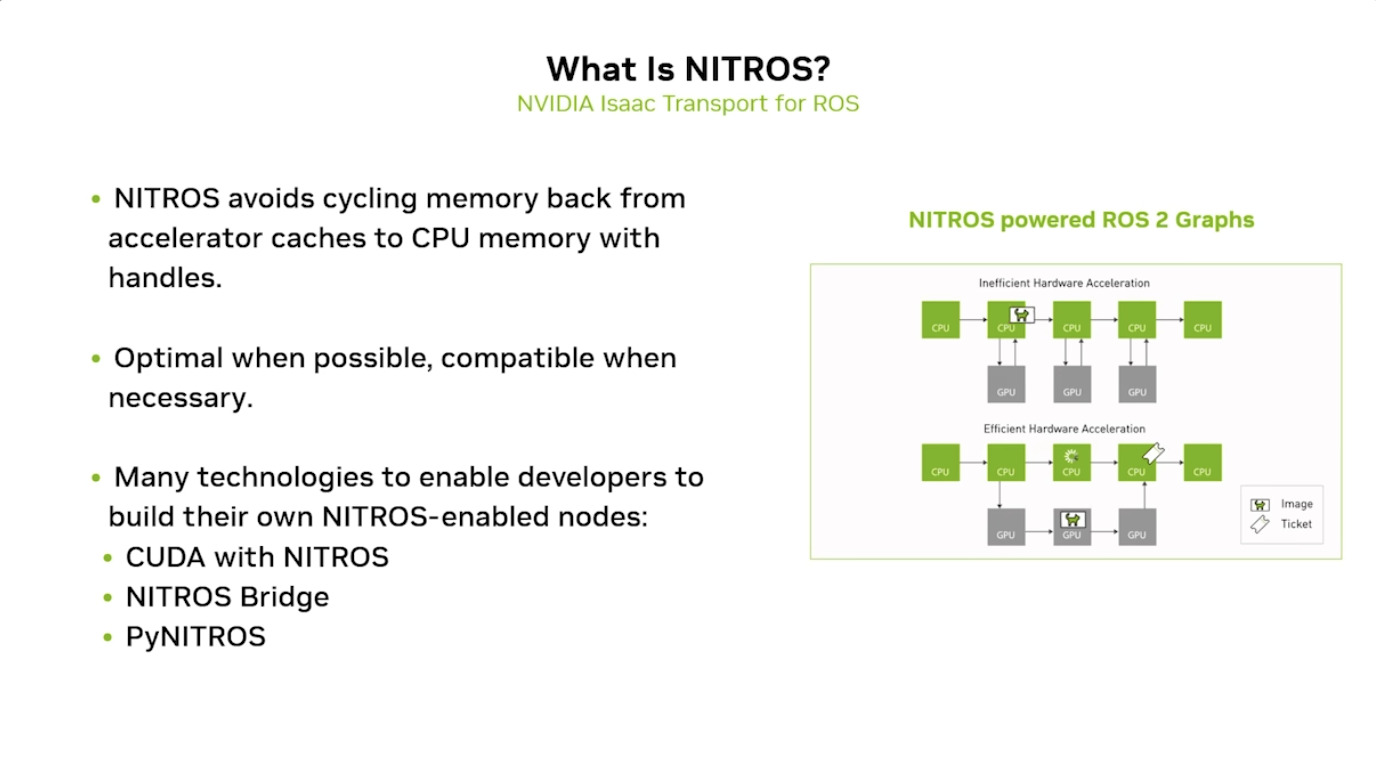
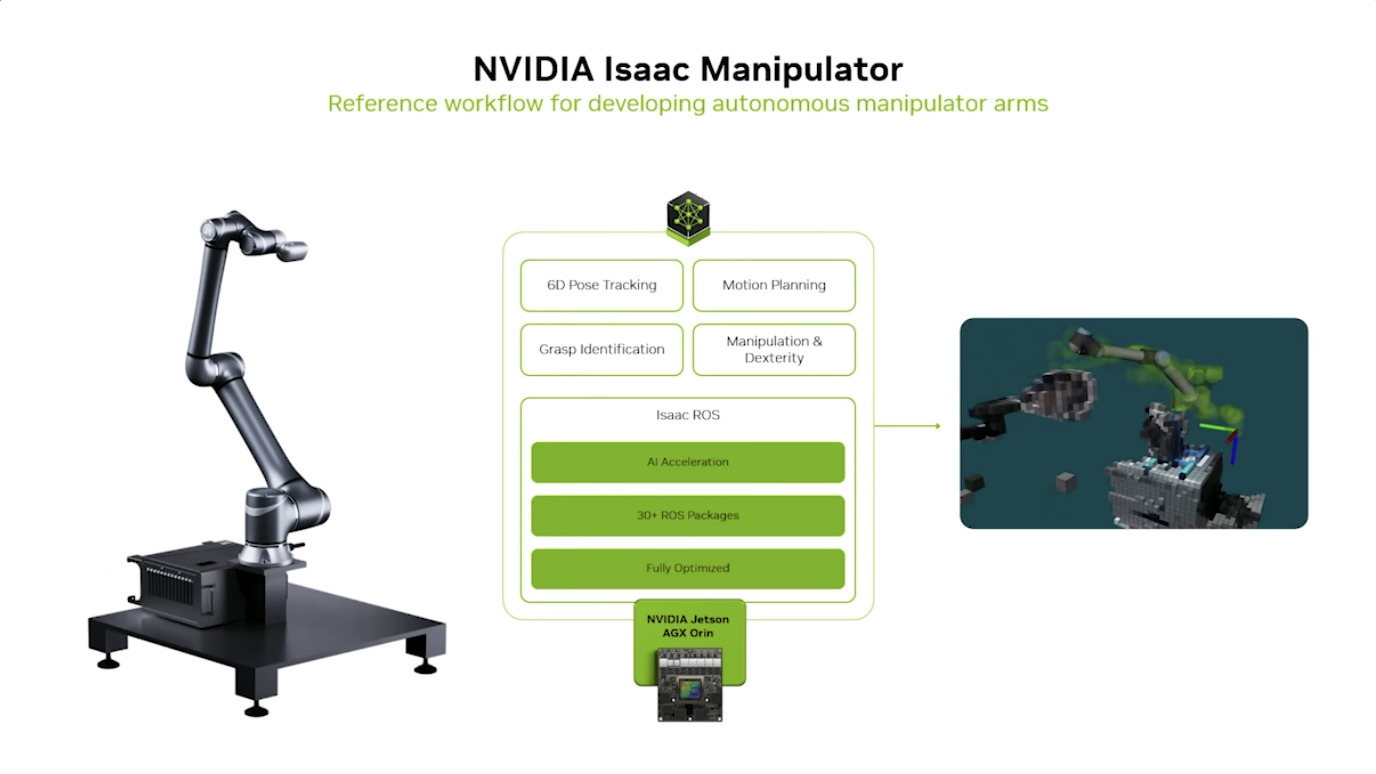
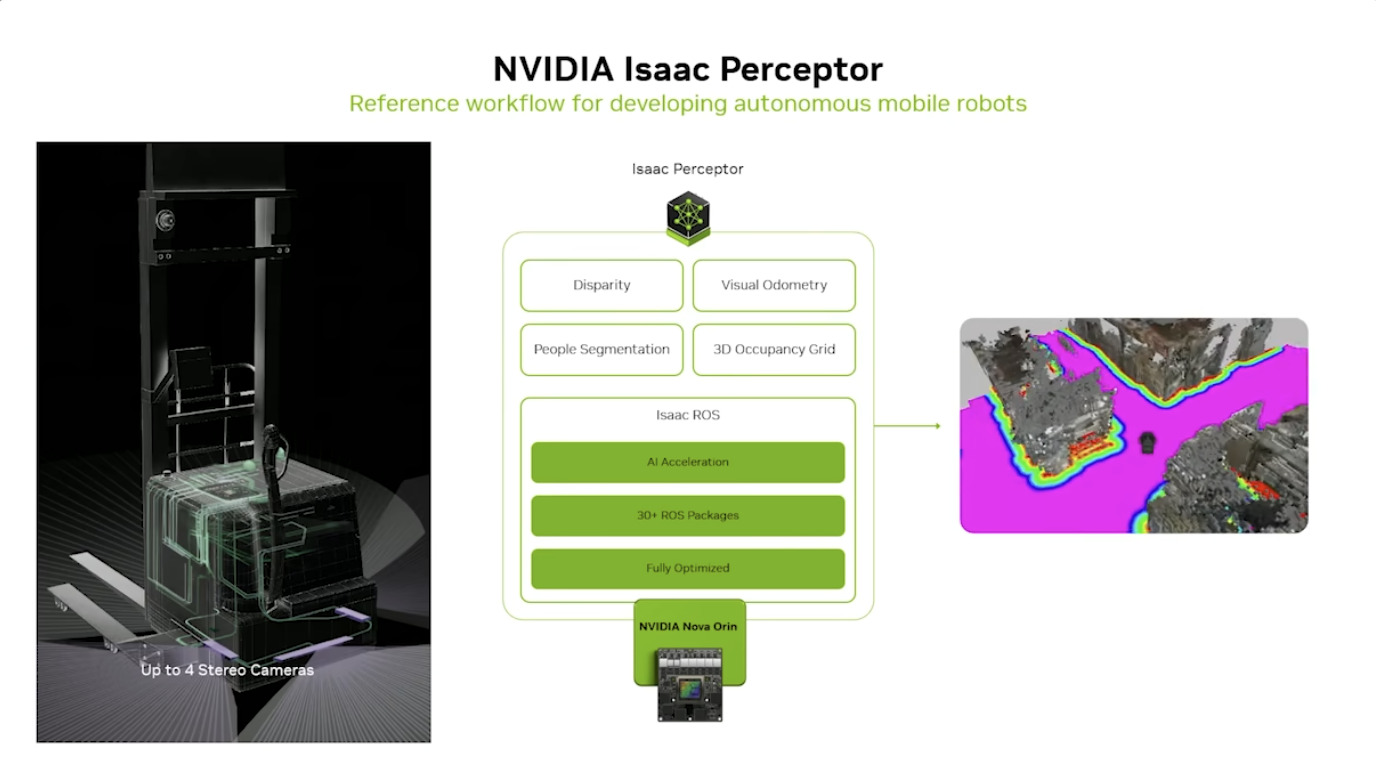
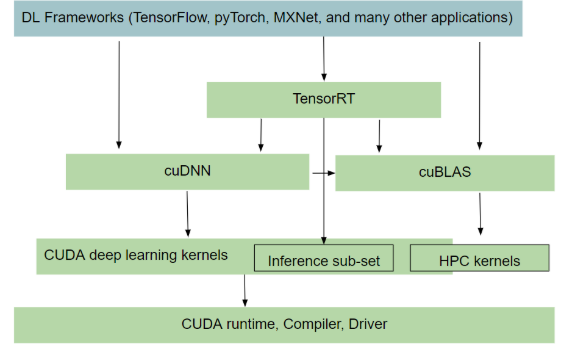
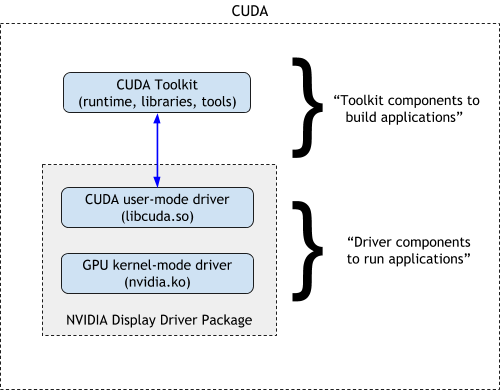
本周 AI 新闻 20260619
本周主线:开源模型密集发布、SpaceX 600 亿美元吞下 Cursor、Anthropic Fable 5 遭美国商务部强制下线,智能体安全与监管同时升温。
本周看点
- SpaceX 全股票收购 Cursor:这笔 600 亿美元的交易将 AI 编程工具市场进一步纳入马斯克生态,也标志着开发者工具成为巨头 AI 军备竞赛的制高点。
- Anthropic Fable 5 / Mythos 5 遭美商务部下线:因一句 "Fix this code" 触发出口管制,Dario Amodei 本周赴华盛顿谈判,事件持续发酵。
- 智谱 GLM-5.2 与月之暗面 Kimi K2.7-Code 相继开源:中国开源模型在 1M 上下文与编程专用模型上继续施压闭源 frontier。
- DeepSeek 完成首轮融资:超过 500 亿元人民币(约 74 亿美元)、估值突破 500 亿美元,继续刷新中国大模型公司的融资纪录。
- Agentjacking 攻击曝光:针对 Claude Code、Cursor、Codex 的假 Sentry 错误注入,85% 成功率,再次敲响智能体安全警钟。
一句话串起本周主线:模型开源、资本整合、监管收紧、安全反噬四条线同时加速,AI 行业正从能力竞赛进入治理与商业化并行的深水区。
一、大模型前沿动态
1. 智谱 GLM-5.2 以 MIT 许可证开源权重