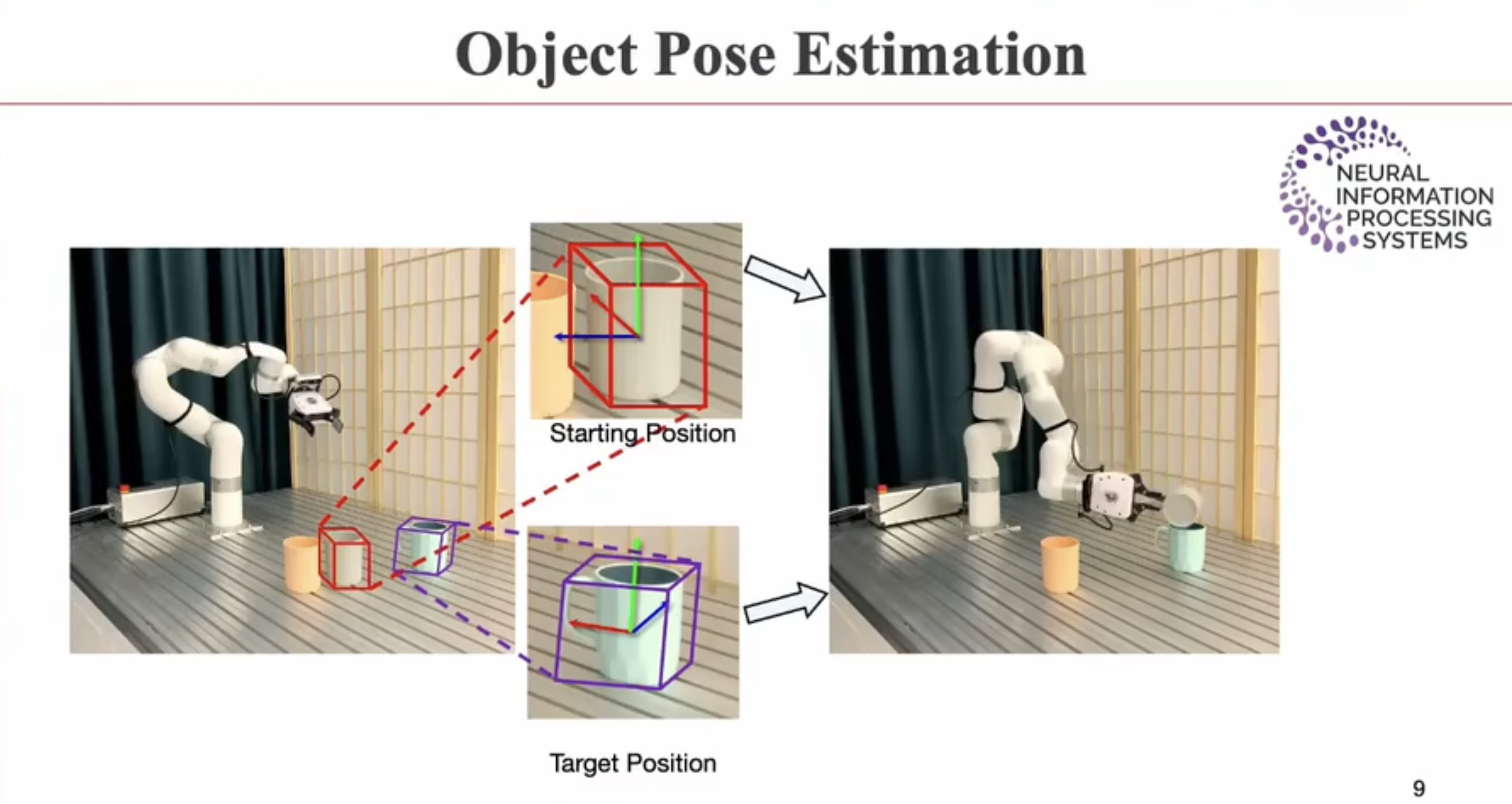
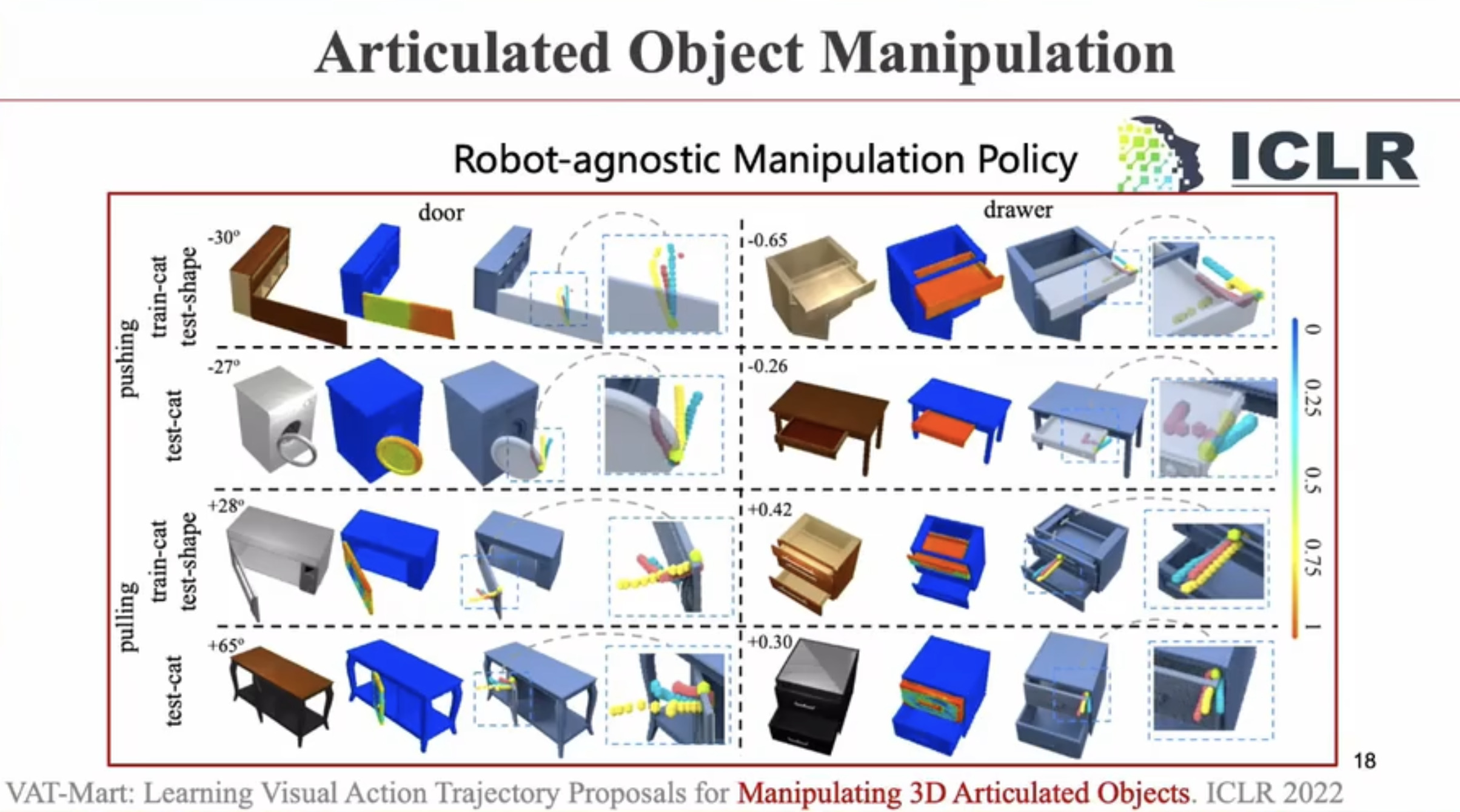
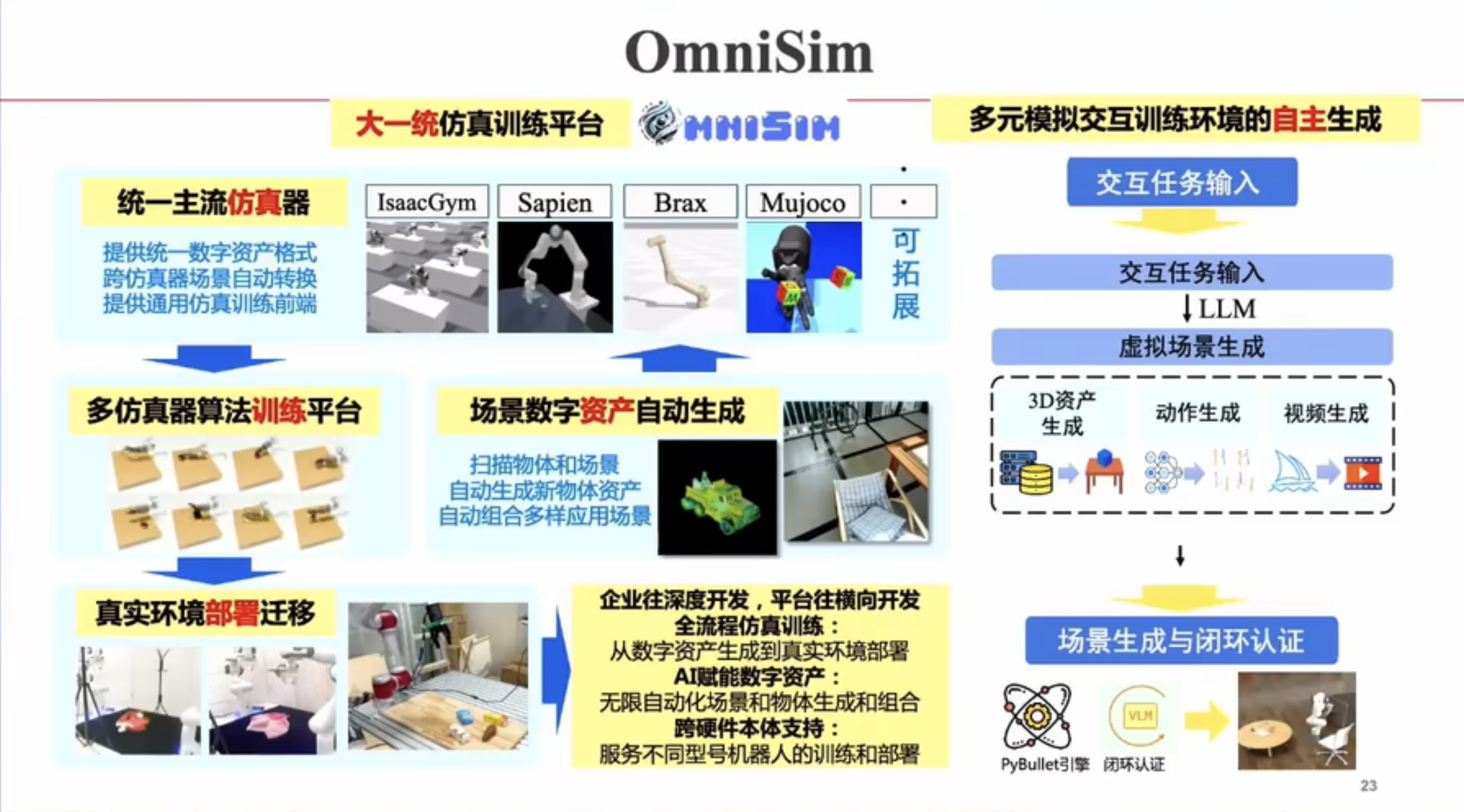
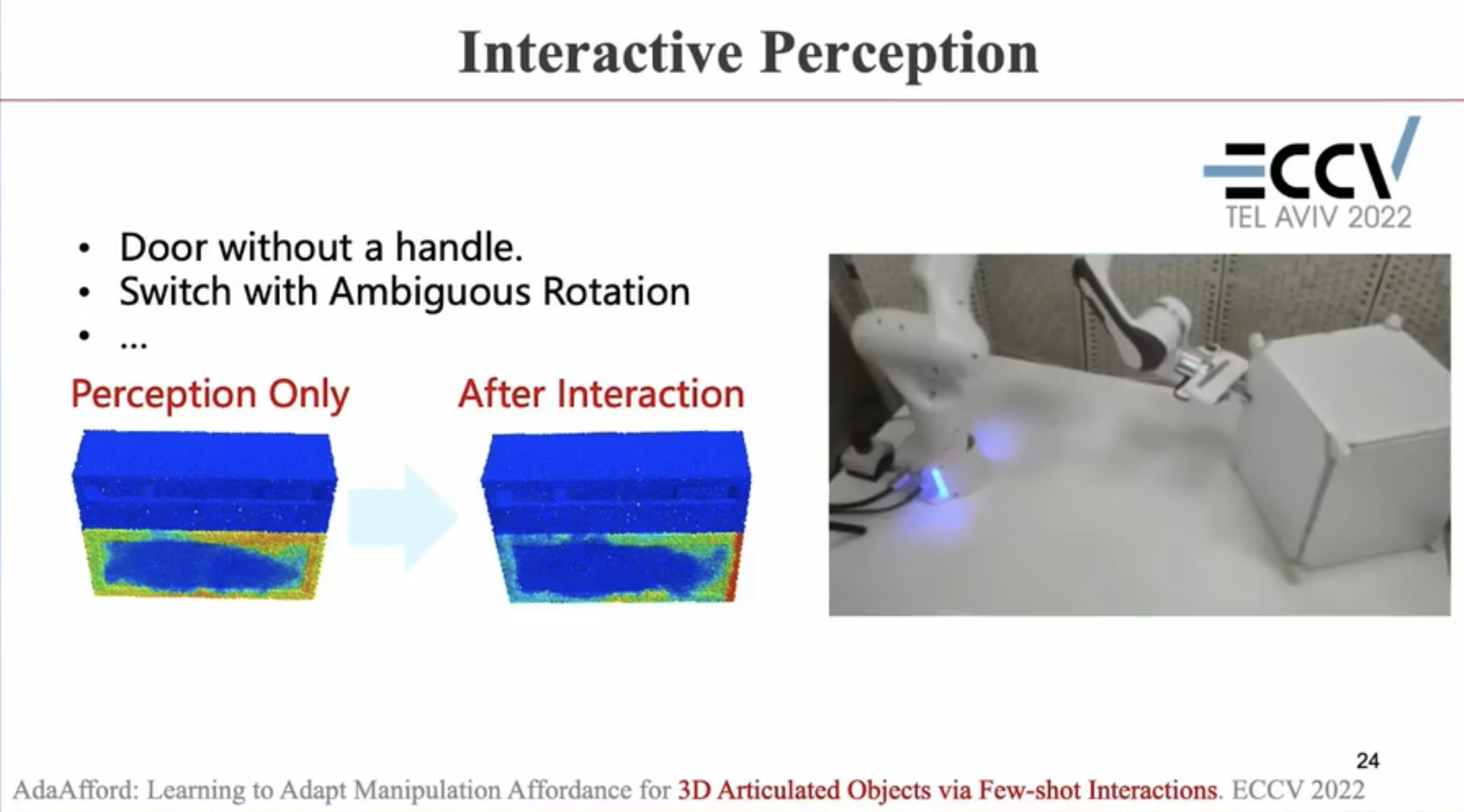
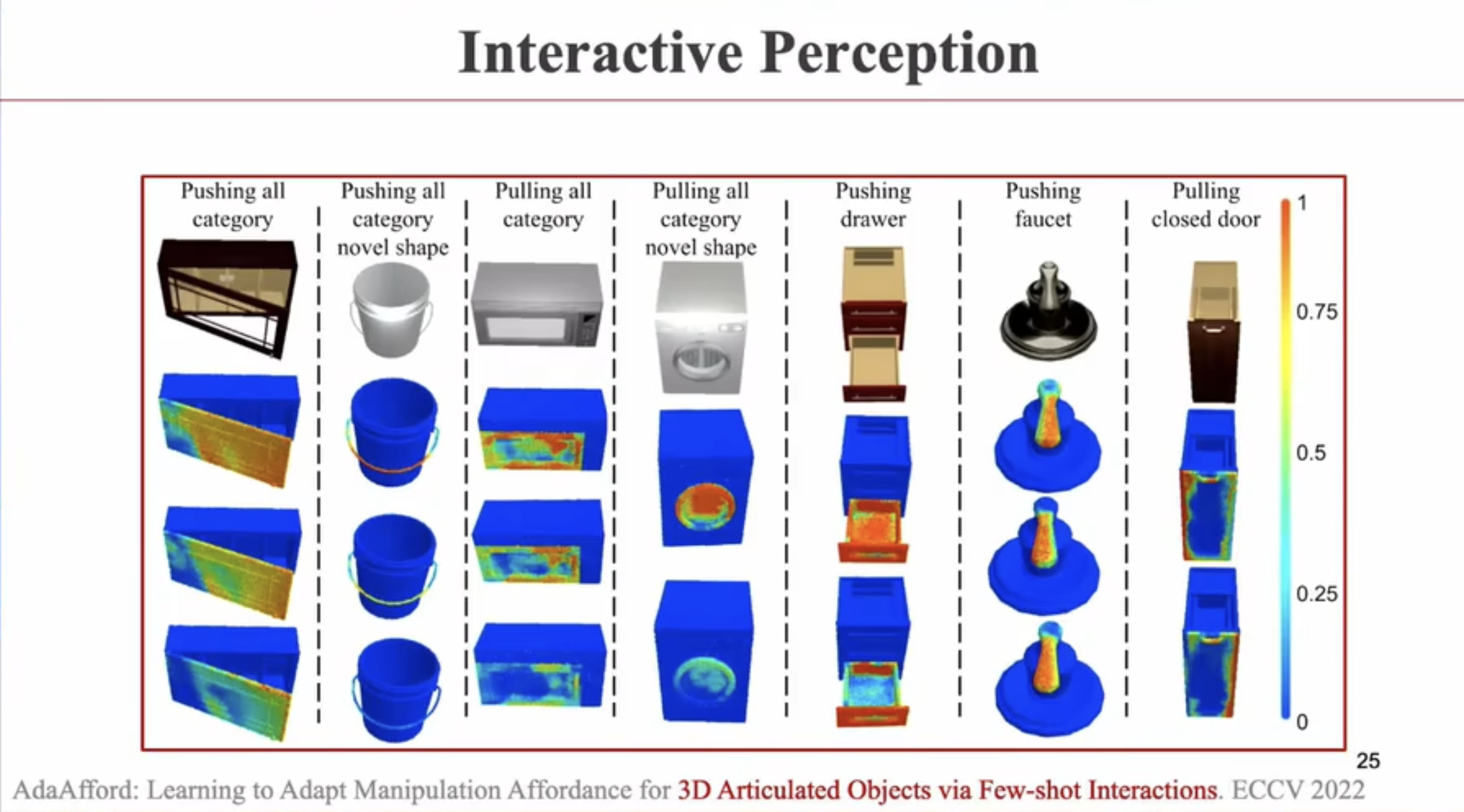
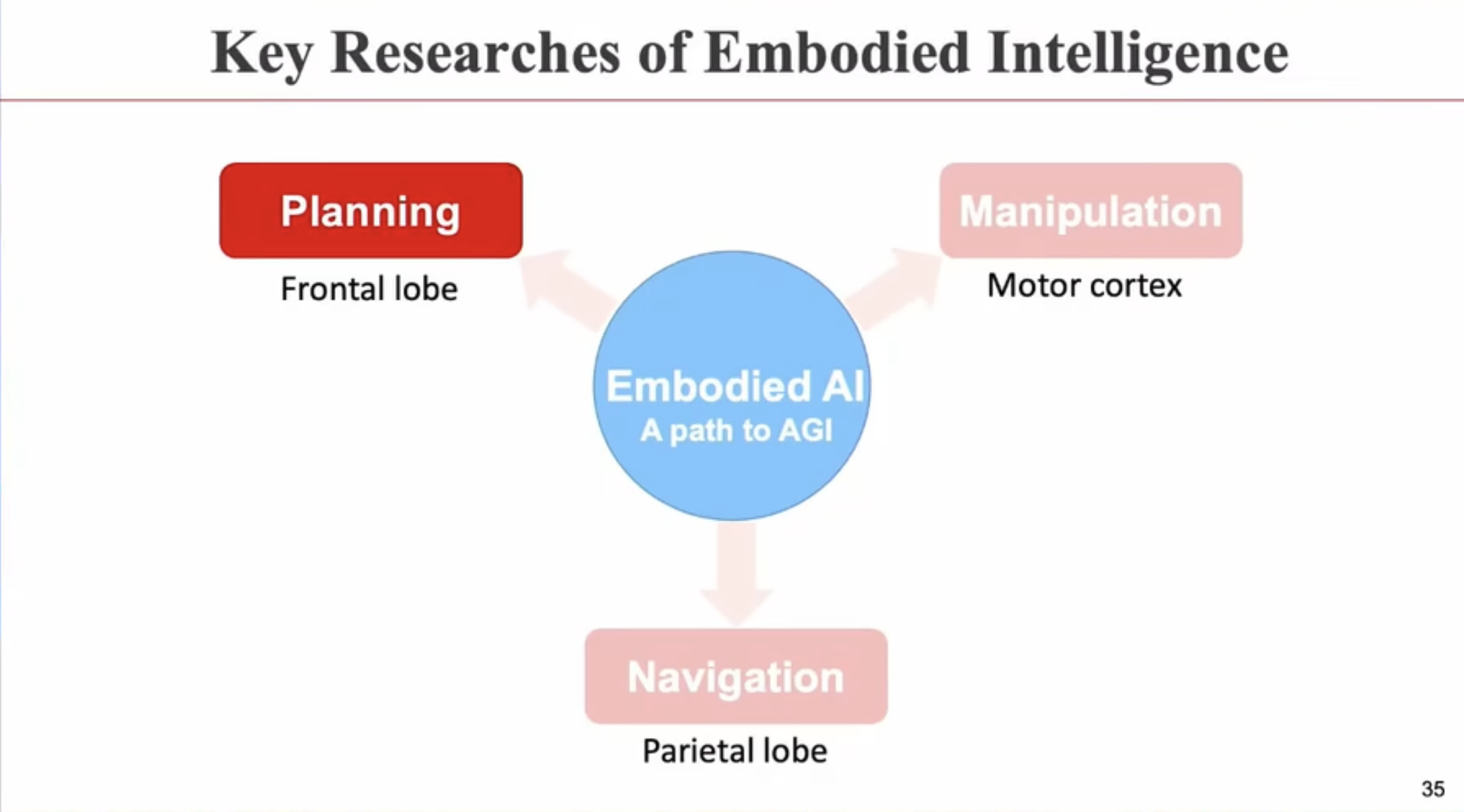
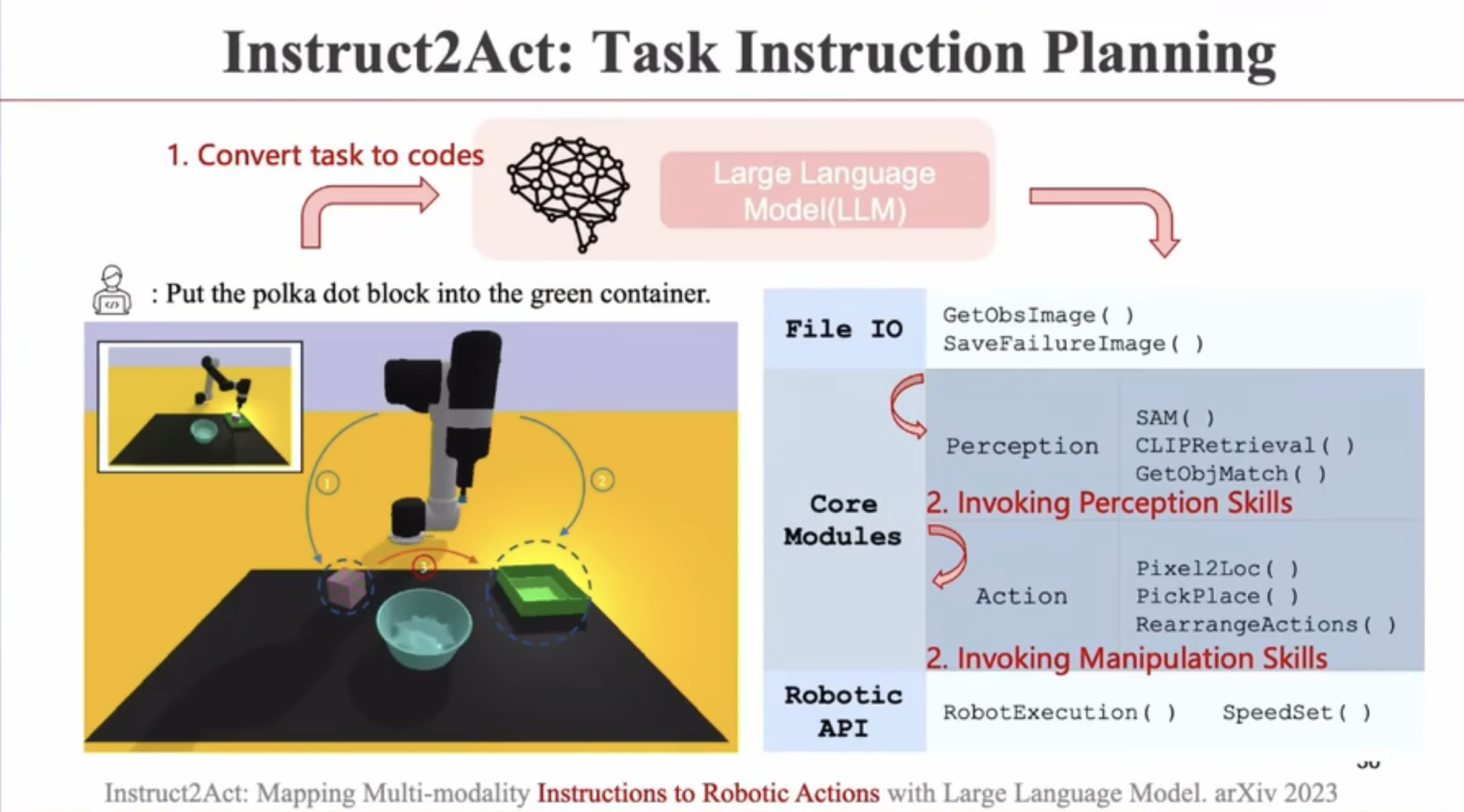
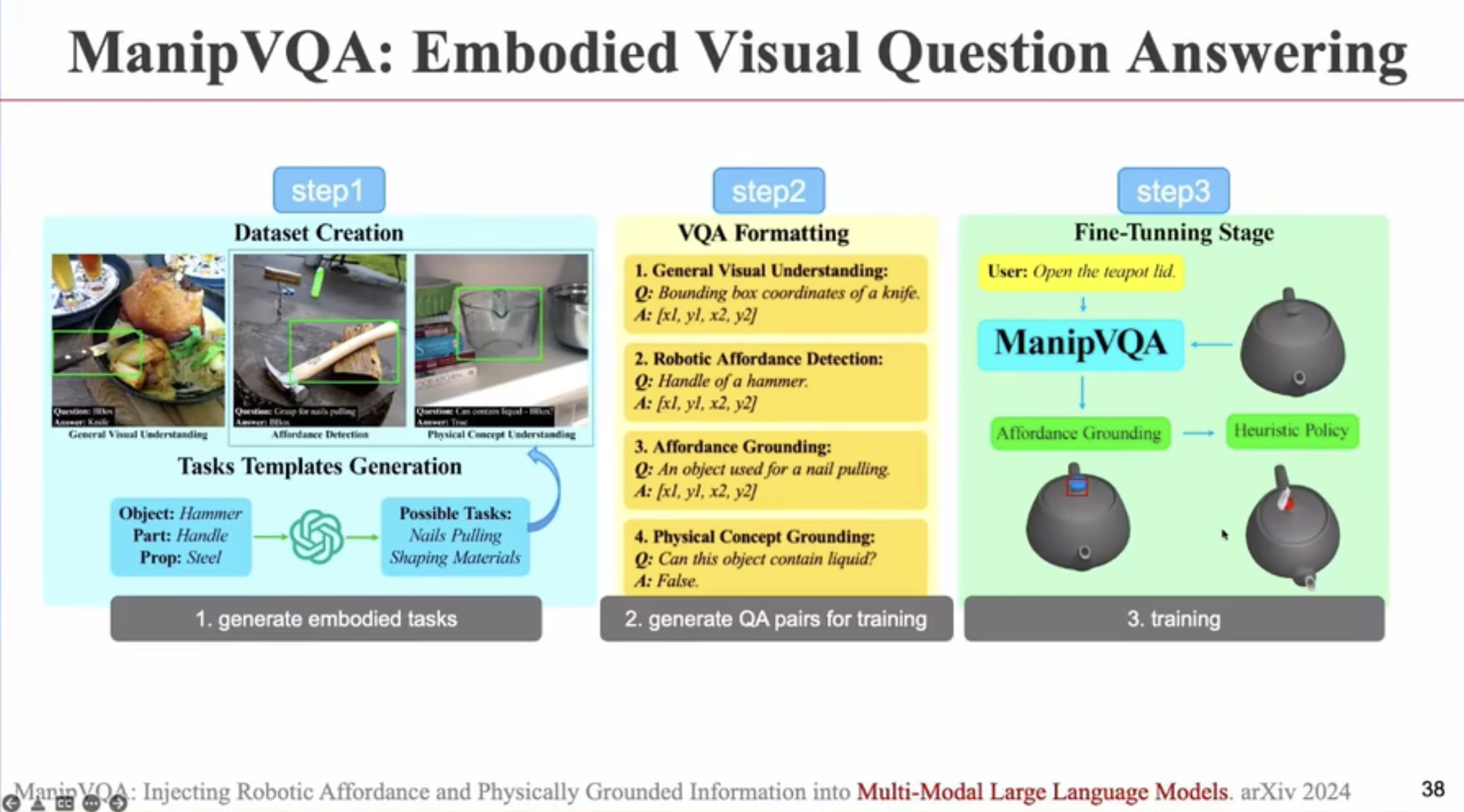
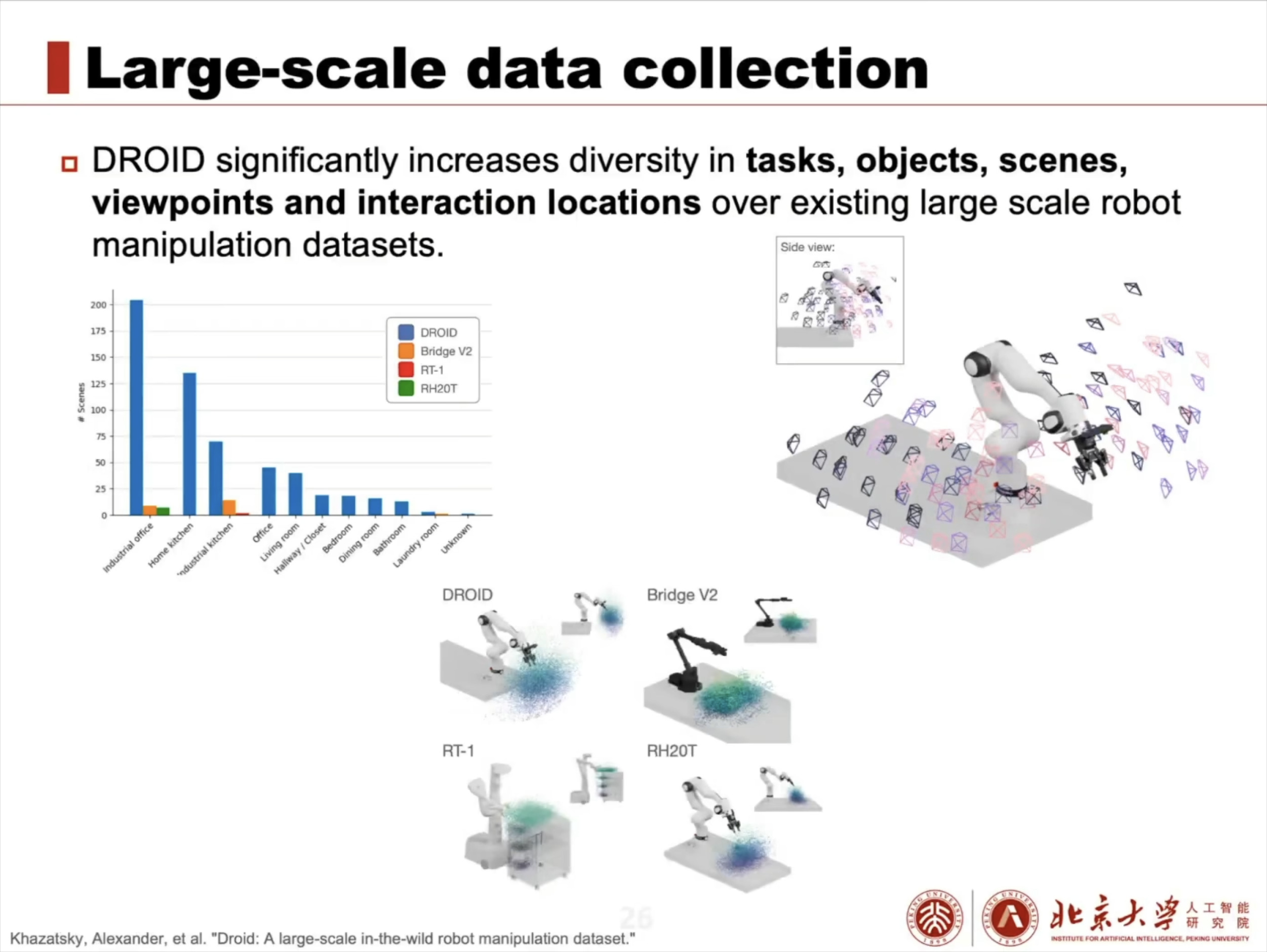
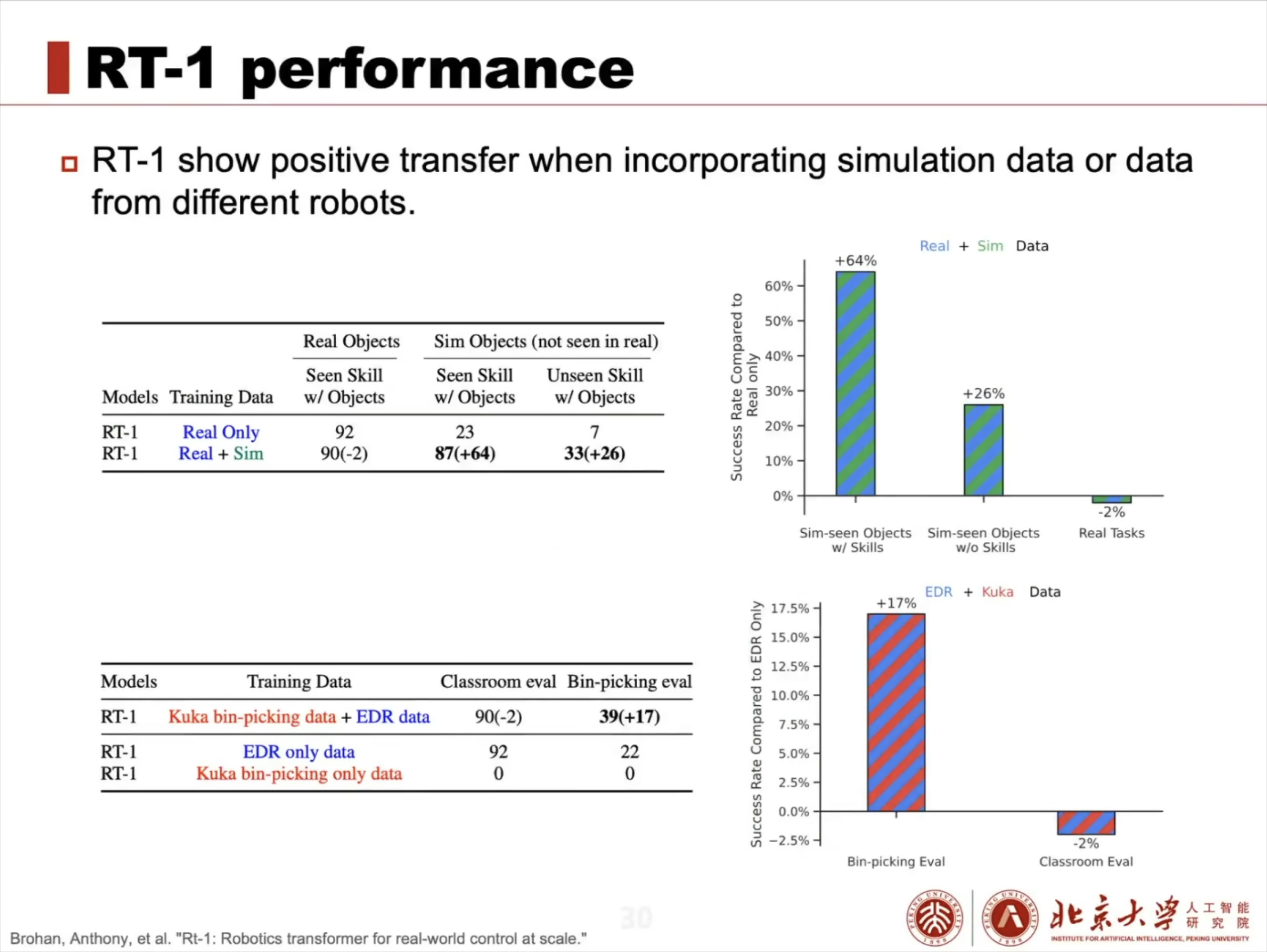
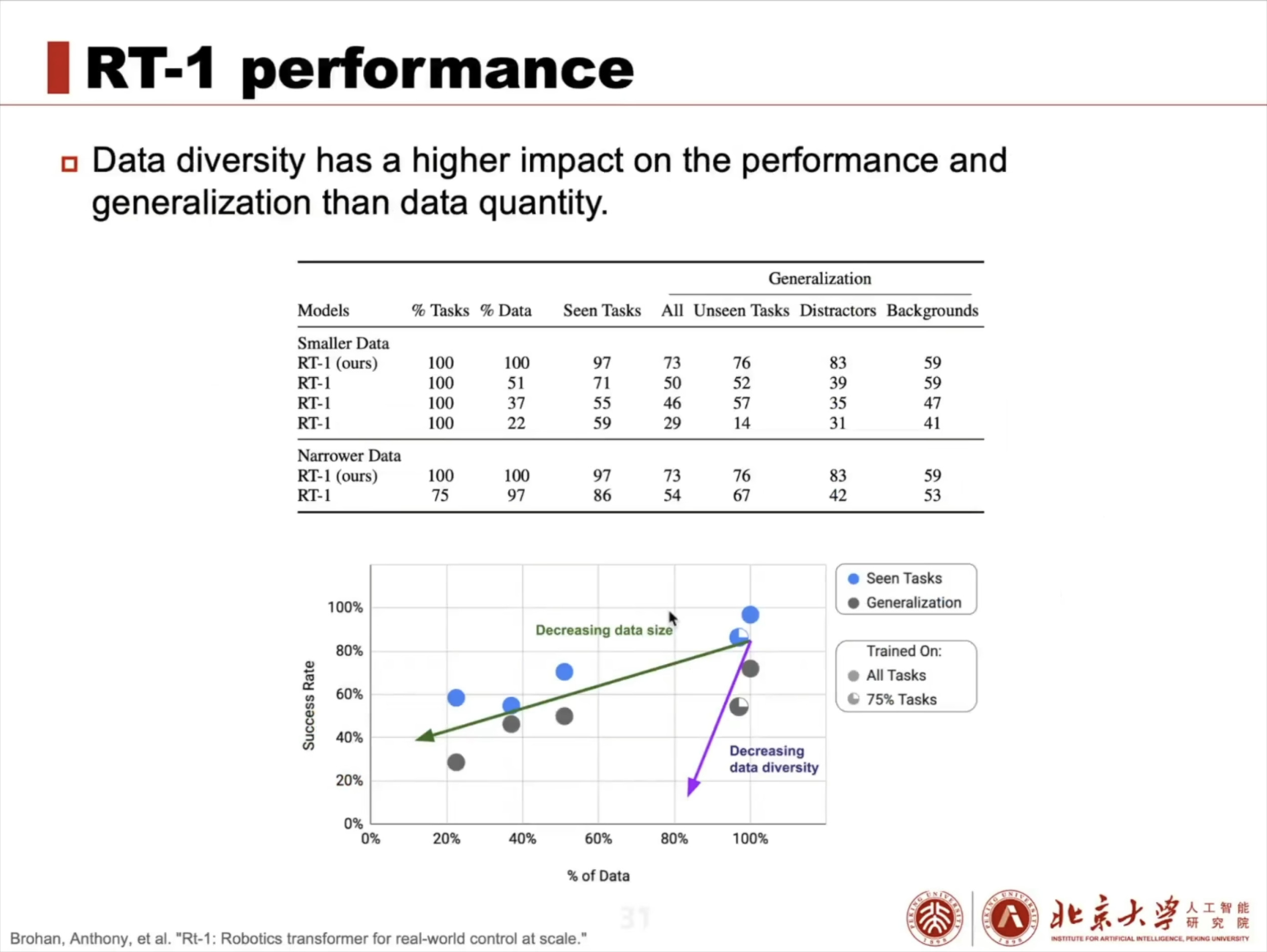
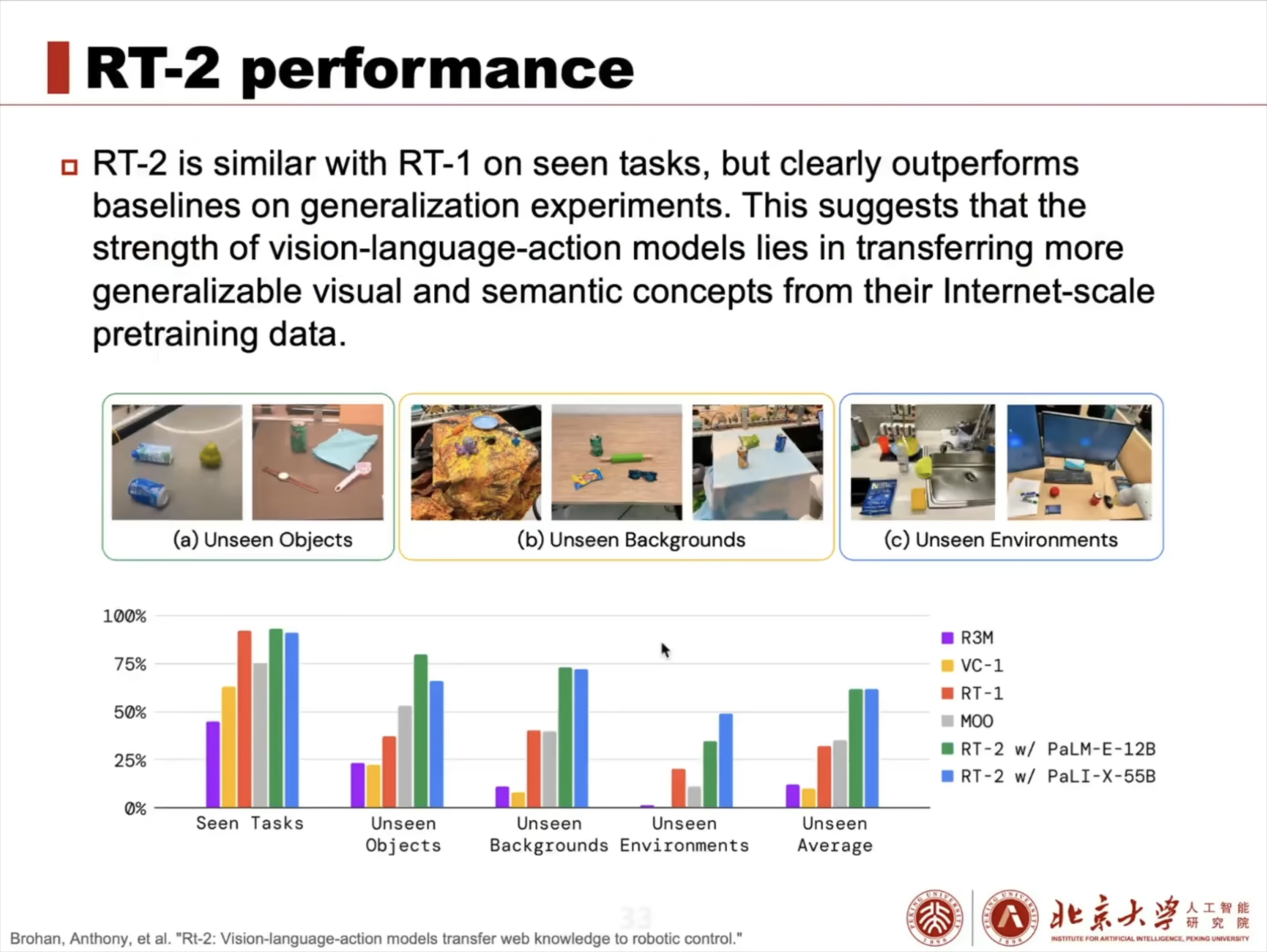
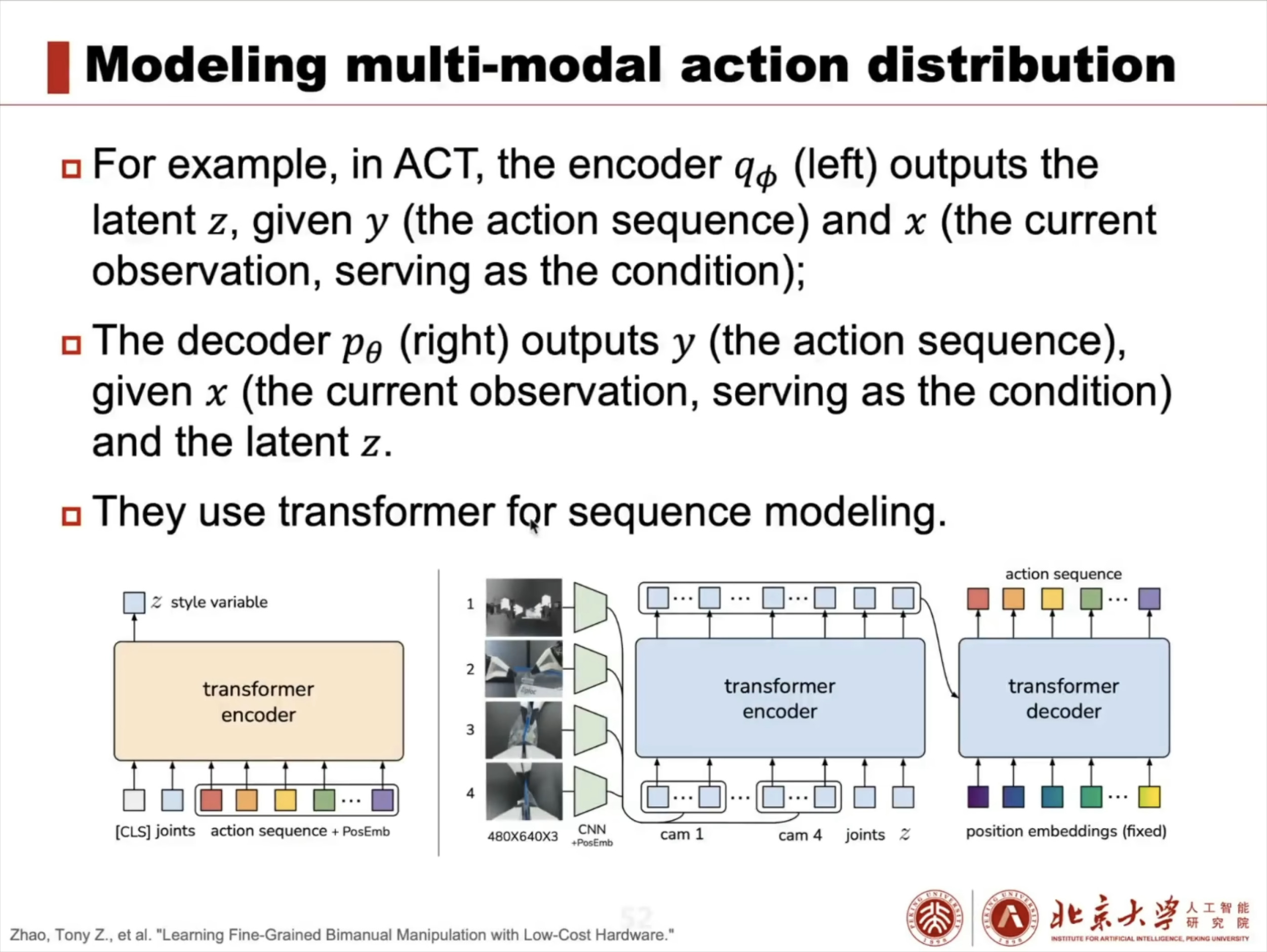
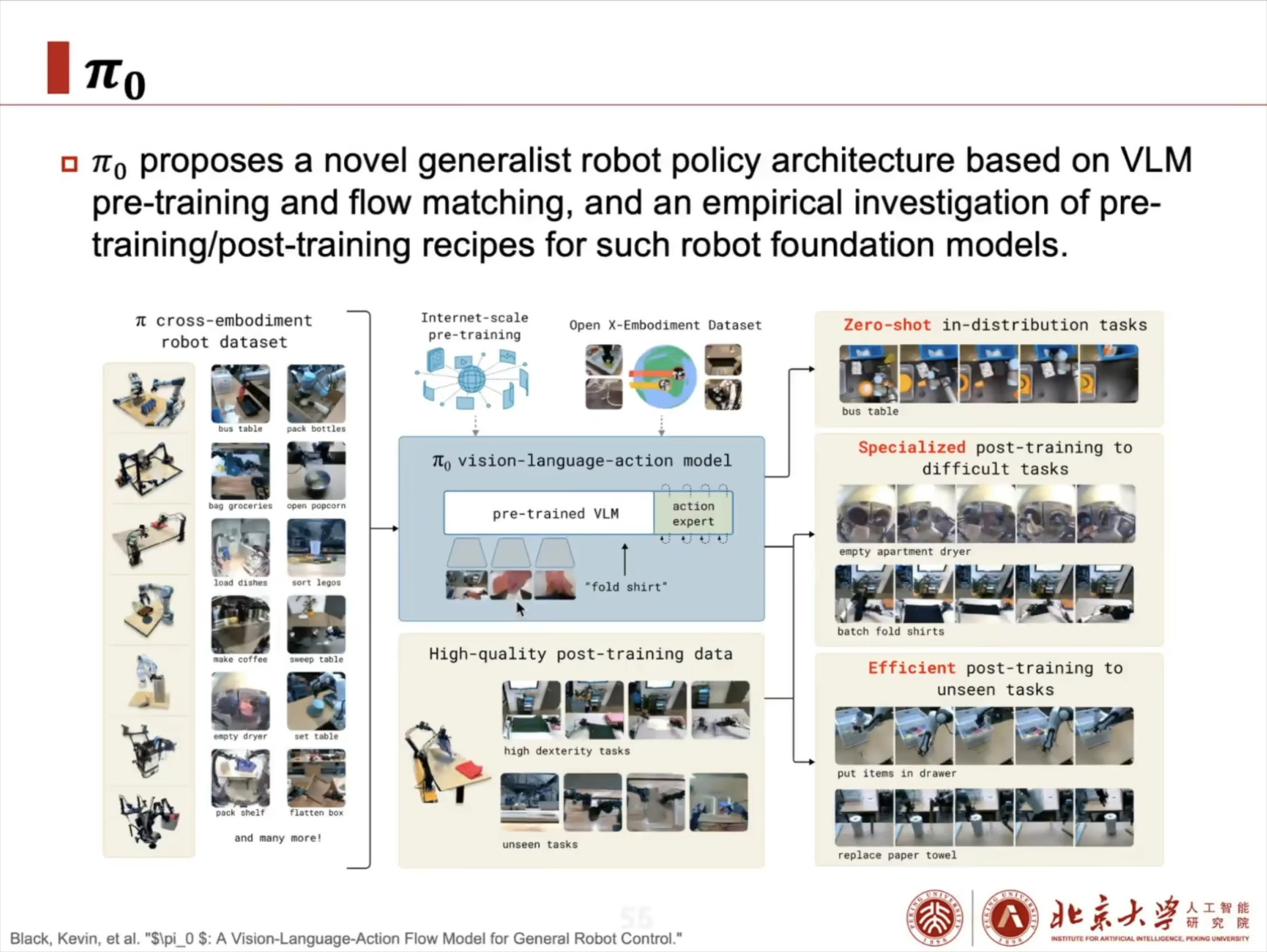
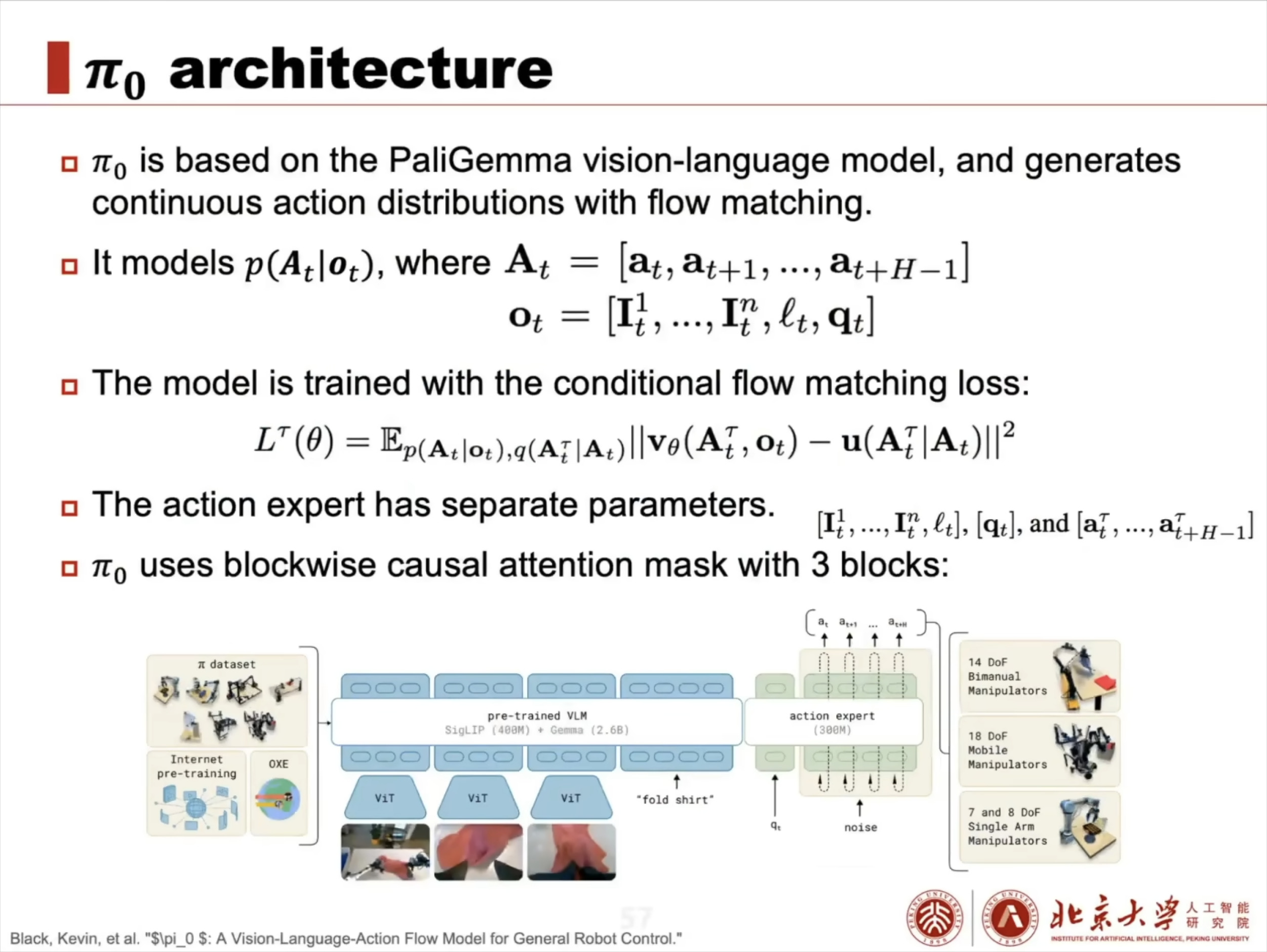
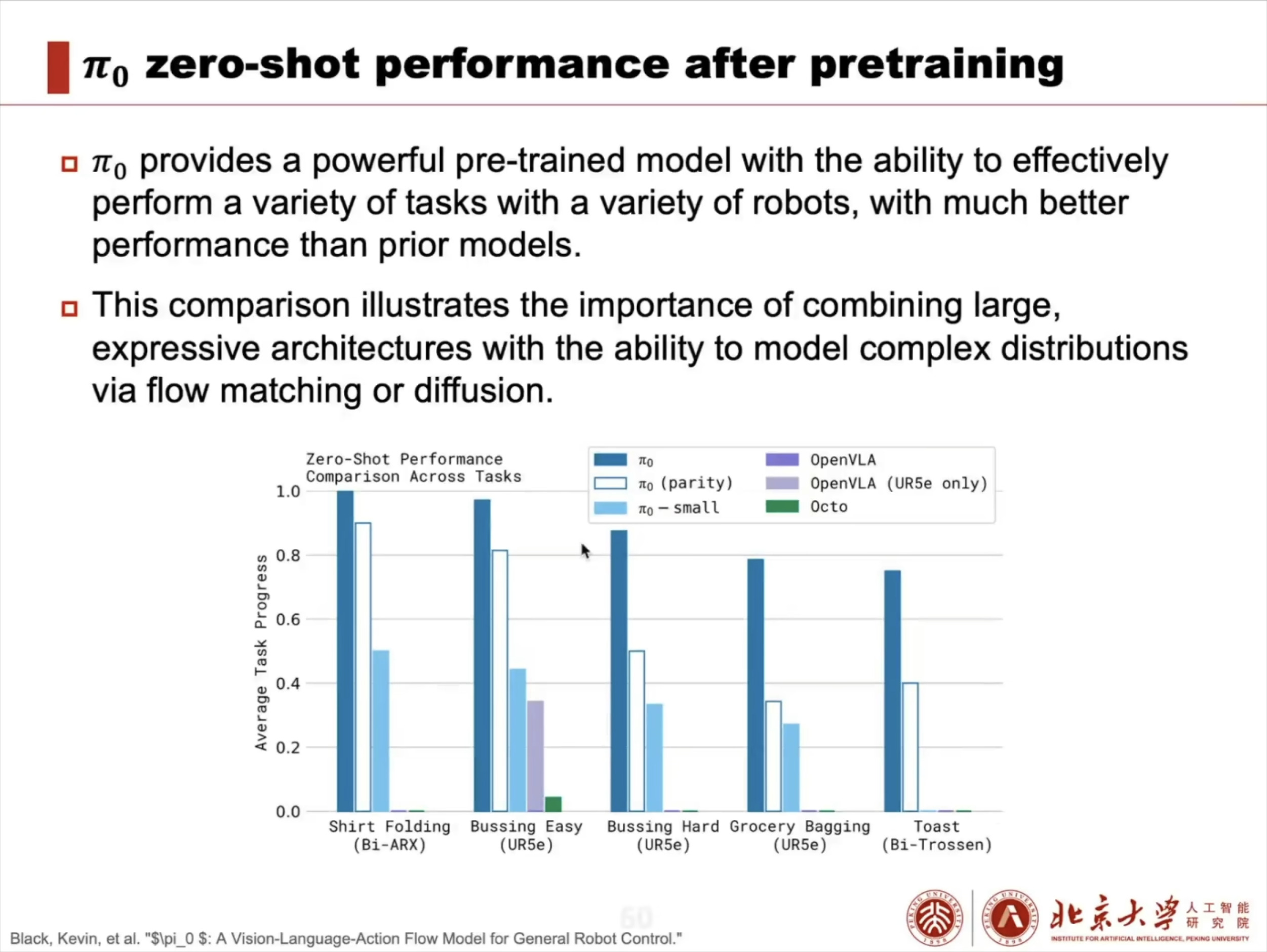
具身智能(Embodied AI)技术综述:从基础理论到工程实践
具身智能(Embodied AI)作为人工智能通往通用人工智能(AGI)的关键路径,近年来取得了突破性进展。本文基于 Every-Embodied 开源项目的丰富实践经验,系统性地综述具身智能领域的技术栈、算法演进、工程实践和前沿复现。全文涵盖:(1)具身智能的基础理论与发展历程;(2)机器人学基础(运动学、动力学、坐标变换);(3)计算机视觉在具身场景中的应用;(4)强化学习与模仿学习;(5)视觉-语言-动作(VLA)大模型全景;(6)视觉语言导航(VLN)技术;(7)世界模型最新进展;(8)无人机控制与规划专题;(9)仿真环境与真机部署;(10)数据集与评估基准。本文强调"理论-实践-复现"三位一体的学习路径,为工程师和从业者提供从入门到前沿复现的完整技术指南。
关键词:具身智能、机器人学习、视觉-语言-动作模型、VLA、视觉语言导航、VLN、世界模型、强化学习、模仿学习、MuJoCo仿真
目录
- 引言
- 具身智能基础理论
- 机器人学基础
- 具身场景的计算机视觉
- 强化学习与模仿学习
- 视觉-语言-动作(VLA)大模型
- 视觉语言导航(VLN)
- 具身世界模型
- 无人机控制与规划专题
- 仿真环境与真机部署
- 数据集与评估基准
- 工程实践指南
- 总结与展望
1. 引言
1.1 什么是具身智能?
人工智能的发展历程中,我们见证了从"非具身"(Disembodied)到"