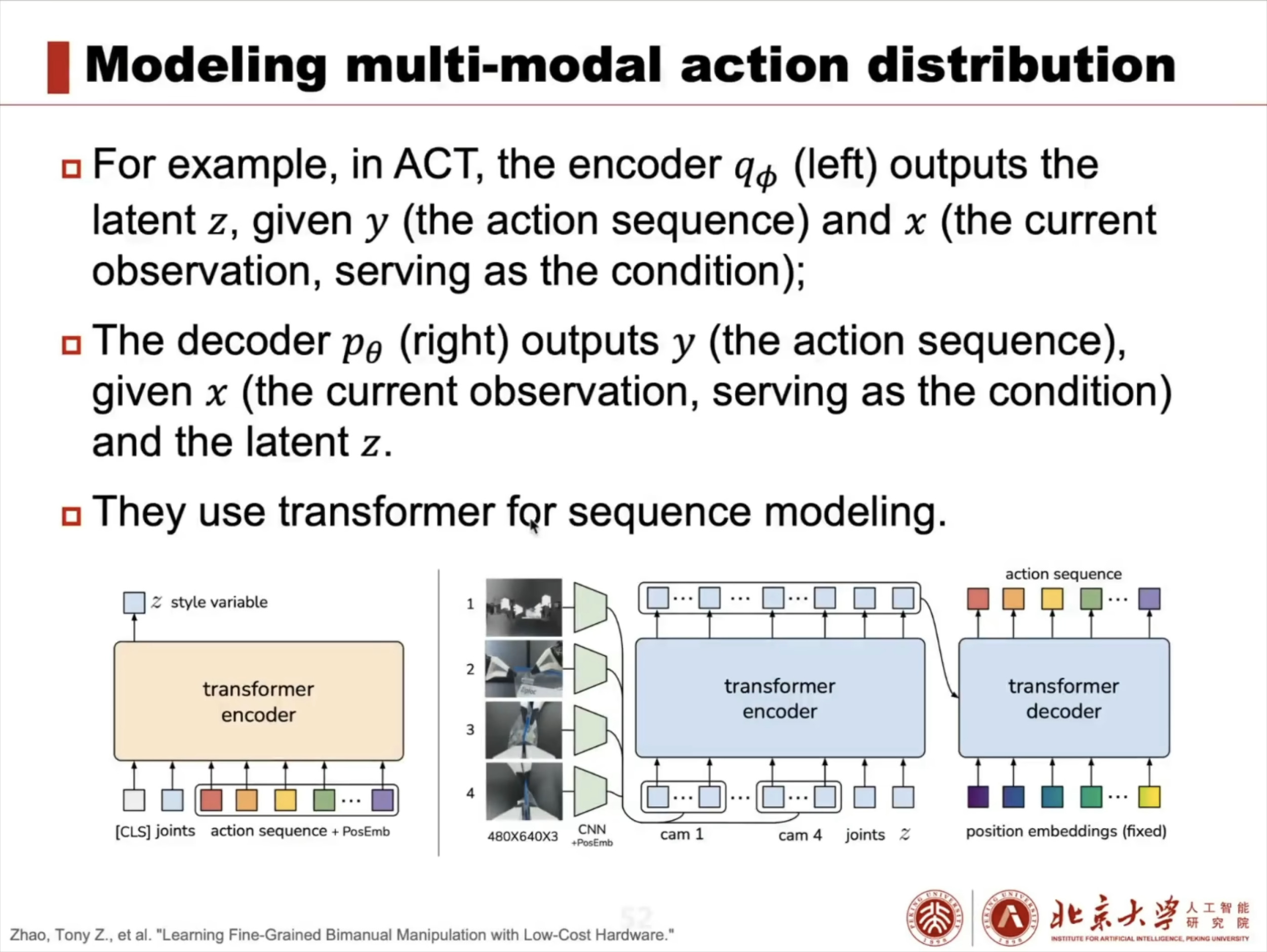
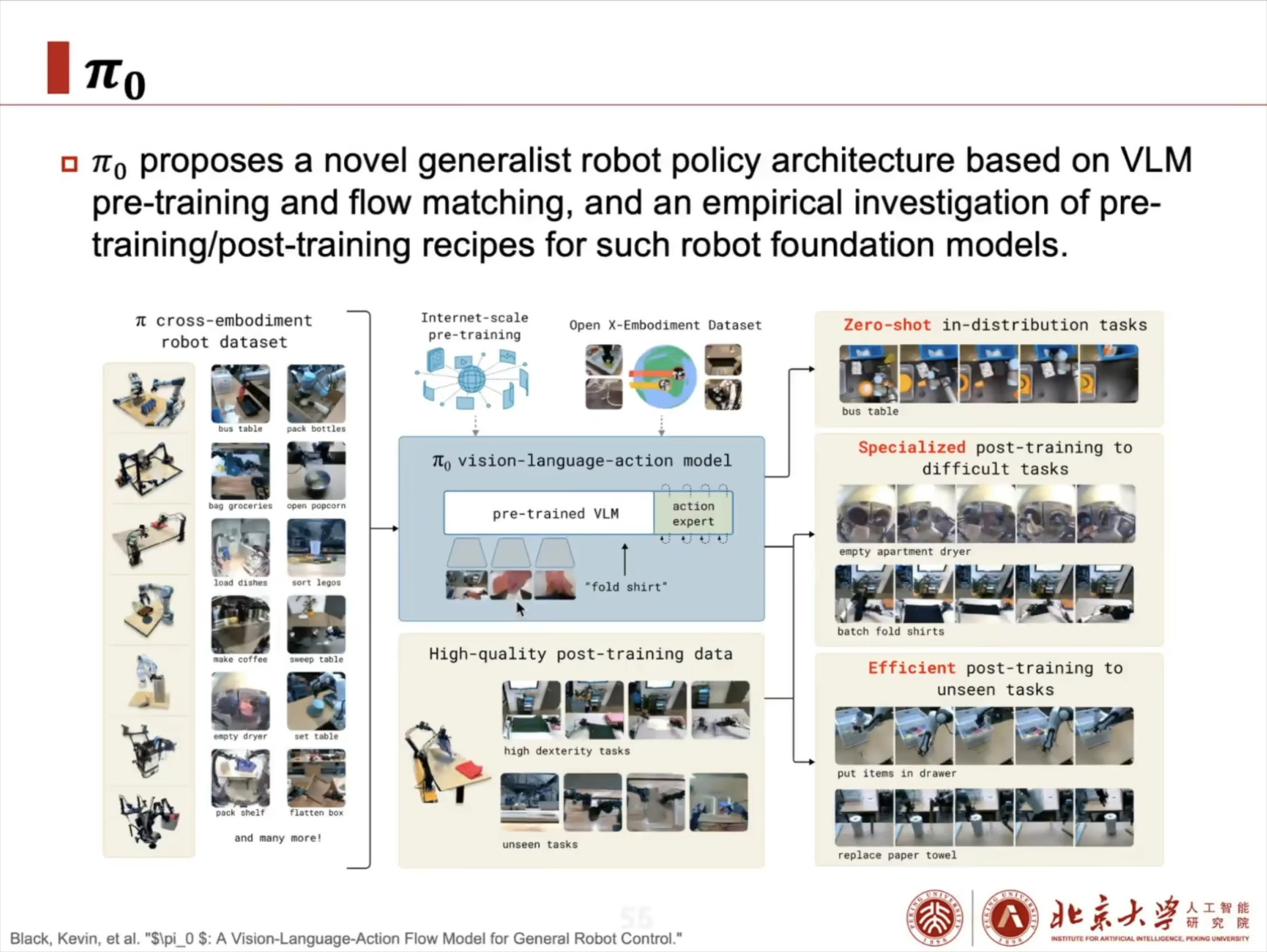
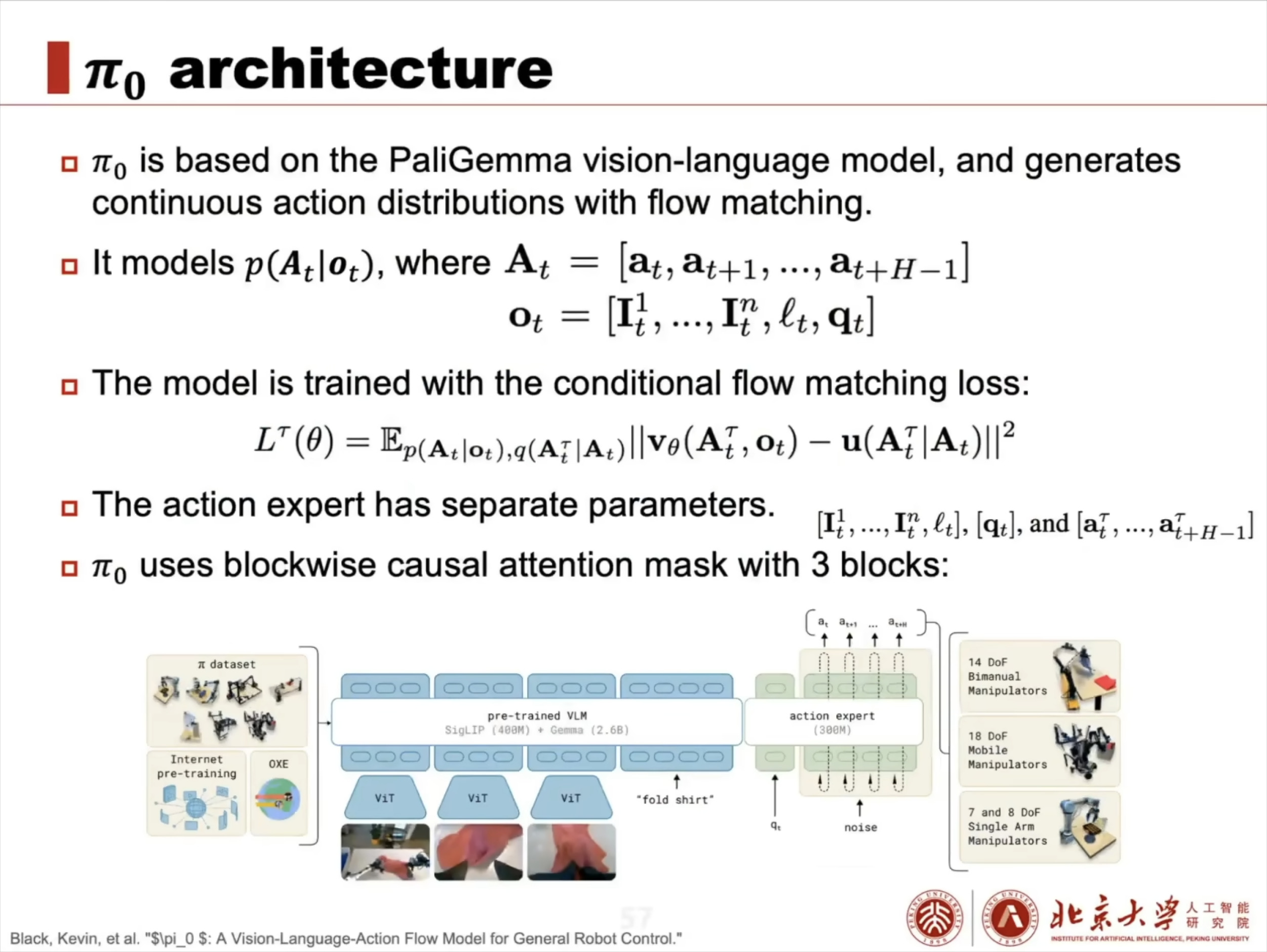
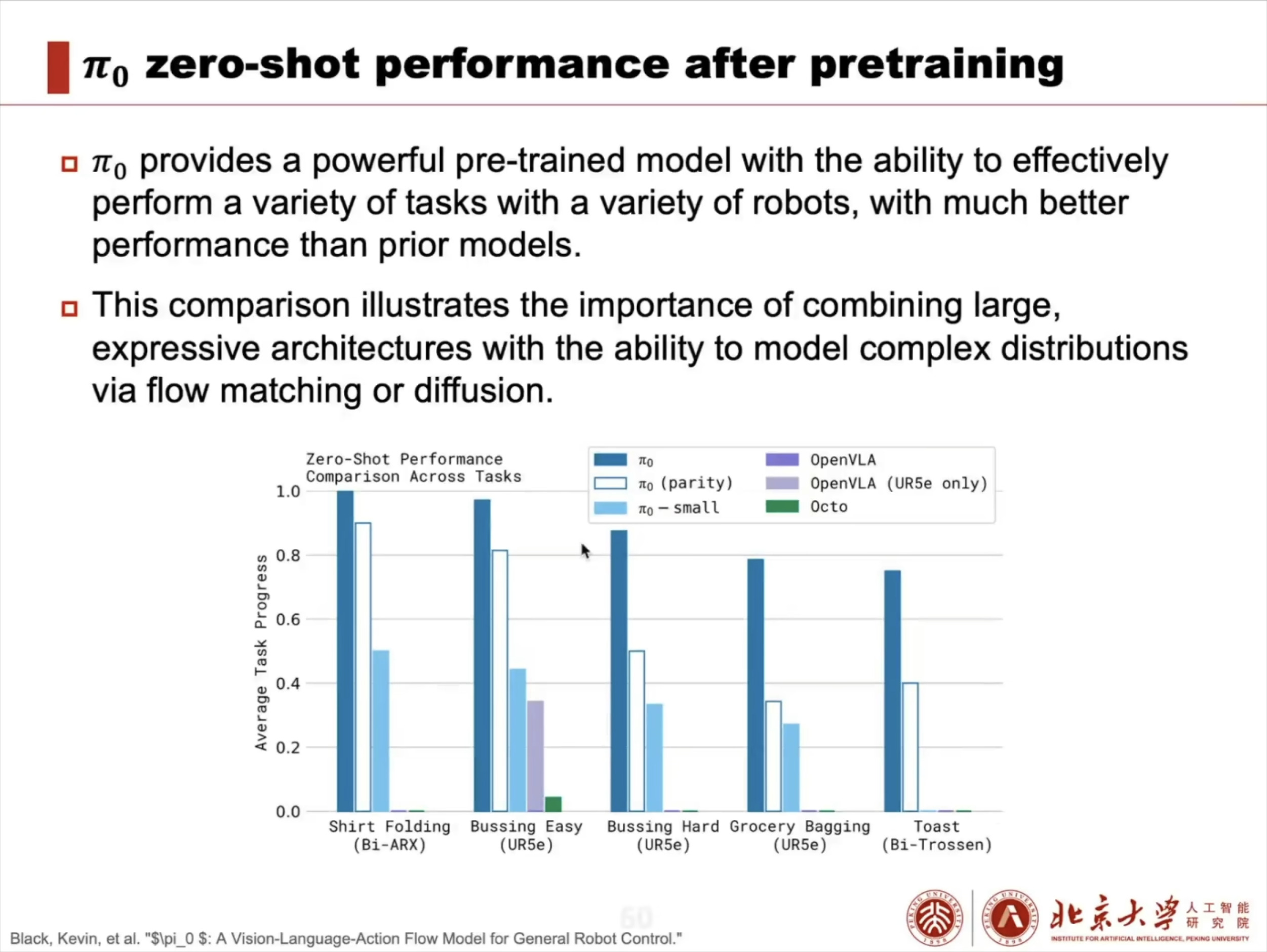
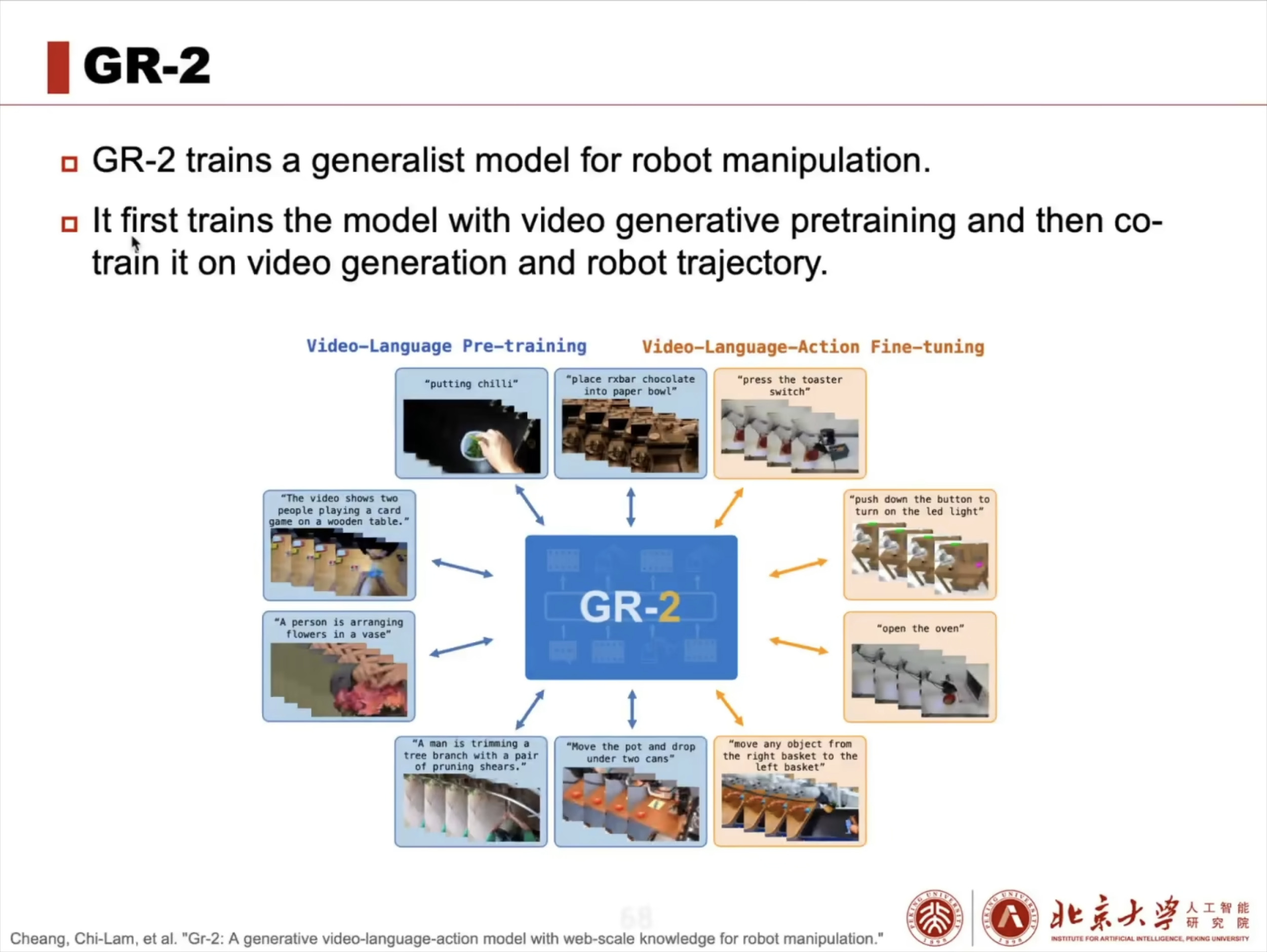
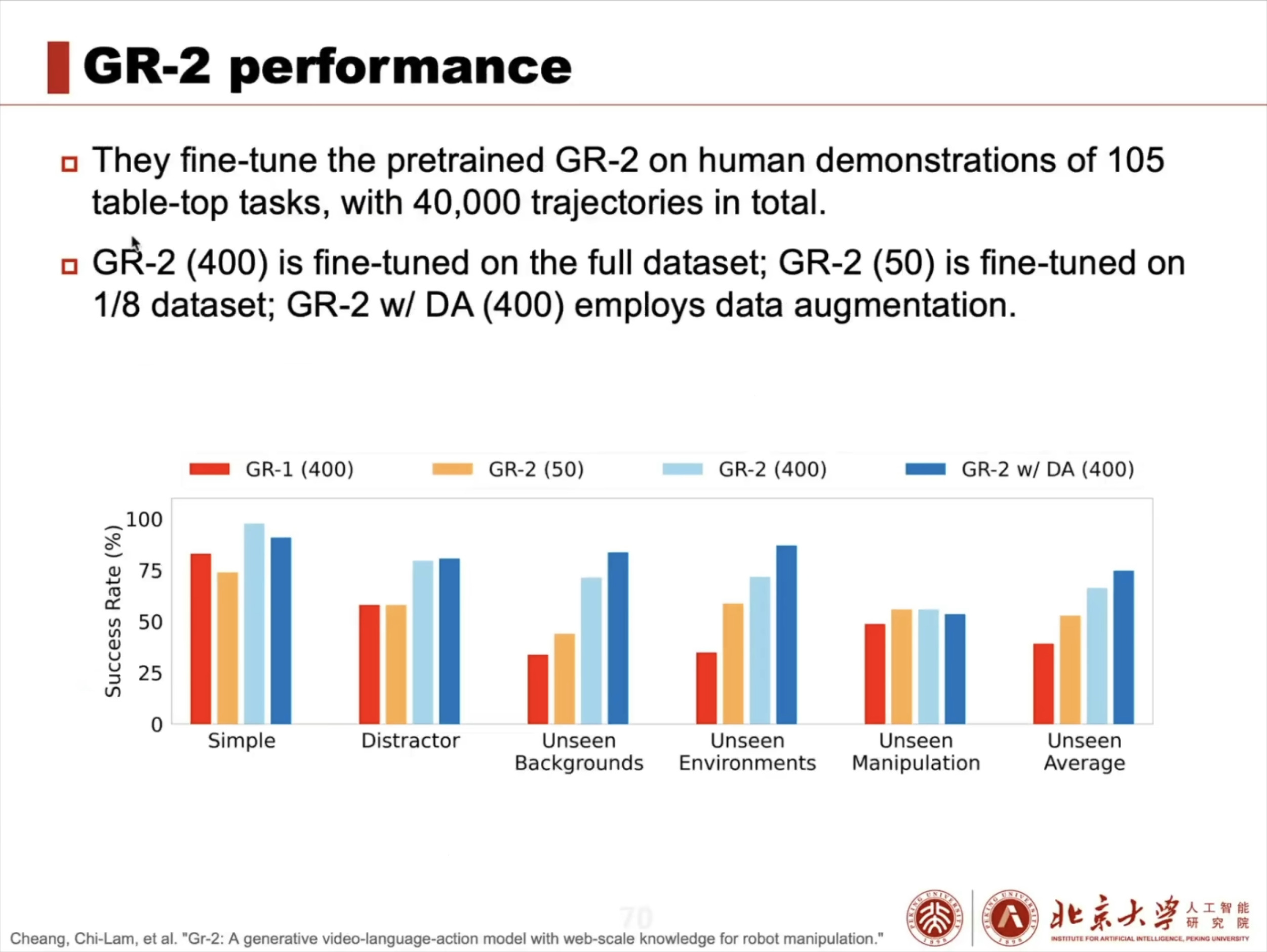
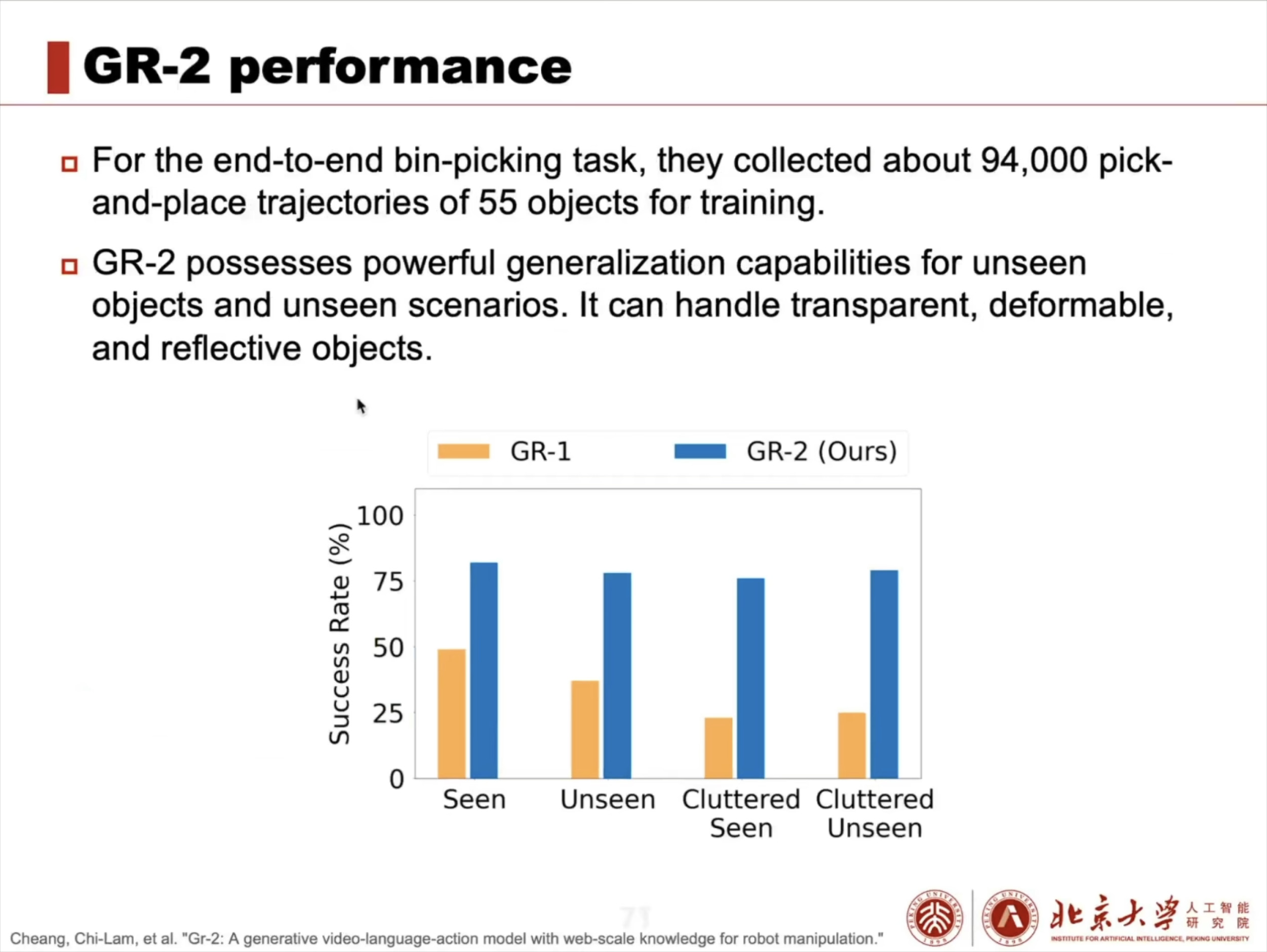
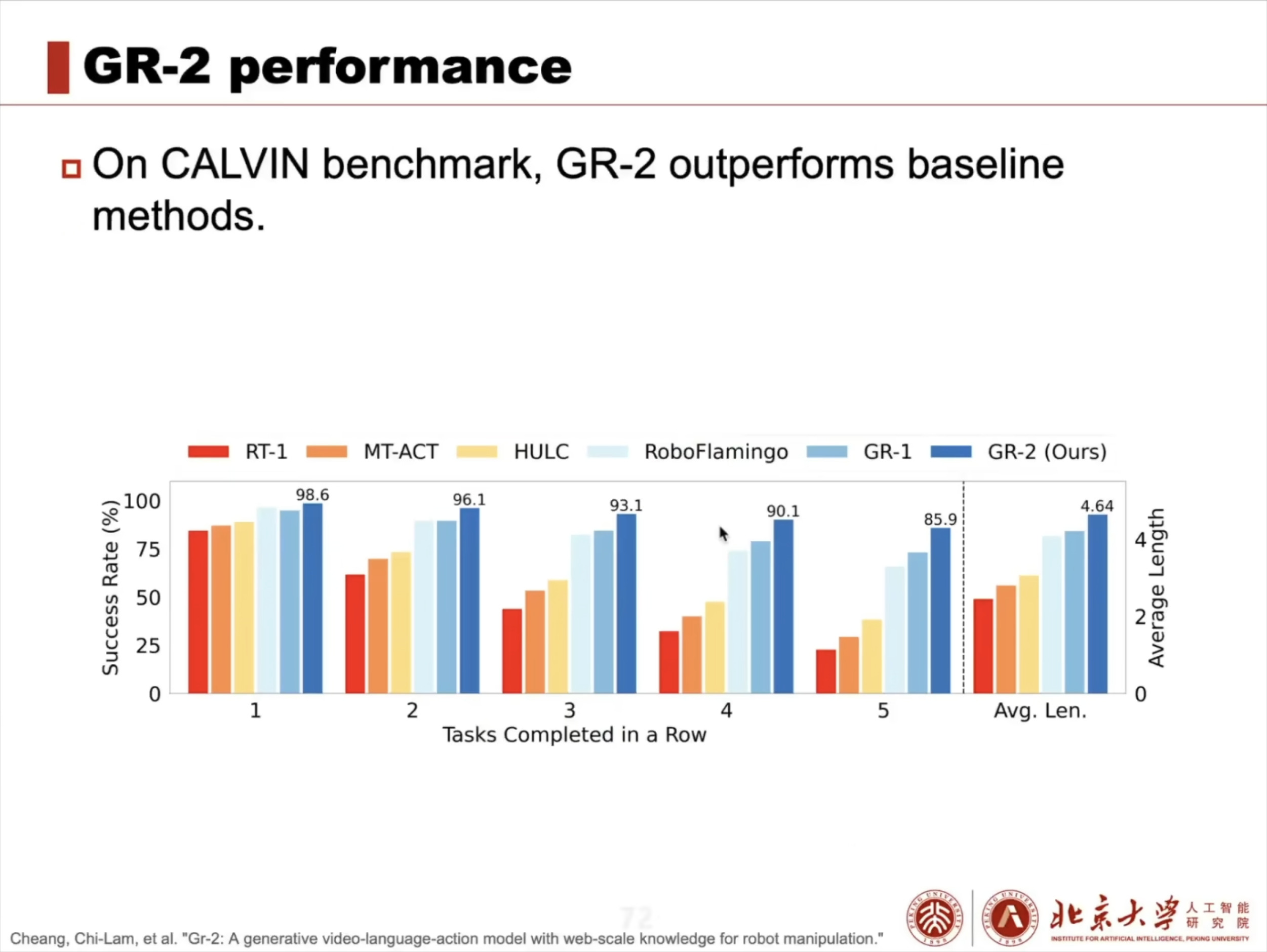
具身智能大脑:VLA 模型架构解析与训练实战
🦞 太空龙虾:基于 OpenVLA、π0、π0.5、π0.6 等核心论文
📋 目录
1. VLA 模型概述
1.1 什么是 VLA 模型?
Vision-Language-Action (VLA) 是具身智能领域的核心范式,将三大核心能力端到端集成:
- Vision:视觉感知(理解机器人看到的环境)
- Language:语言理解(理解人类指令)
- Action:动作生成(输出机器人执行的控制指令)
1.2 VLA 的革命性意义
传统机器人范式:
视觉感知 → 状态估计 → 任务规划 → 运动控制 → 执行
问题:各模块独立训练,误差累积,泛化能力弱
VLA 范式:
[图像 + 语言] → VLA 模型 → [动作序列]
优势:端到端训练,全局优化,泛化能力强
2. 架构设计
2.1 核心架构组件
2.1.1 视觉编码器(Vision Encoder)
作用: 将机器人视角的图像转换为特征表示
常用架构:
| 架构 | 特点 | 适用场景 |
|---|---|---|
| ViT (Vision Transformer) | 全局注意力,适合复杂场景 | 通用机器人操作 |
| CLIP ViT | 预训练视觉-语言对齐 | 开放场景理解 |
| EfficientNet | 高效,适合边缘部署 | 低功耗机器人 |
| DINOv2 | 自监督预训练 | 少样本学习 |
输入维度: 单帧图像:[B, 3, H, W] 多帧历史:[B, T, 3,