3 篇文章带有标签 “world-model”








具身智能(Embodied AI)技术综述:从基础理论到工程实践
具身智能(Embodied AI)作为人工智能通往通用人工智能(AGI)的关键路径,近年来取得了突破性进展。本文基于 Every-Embodied 开源项目的丰富实践经验,系统性地综述具身智能领域的技术栈、算法演进、工程实践和前沿复现。全文涵盖:(1)具身智能的基础理论与发展历程;(2)机器人学基础(运动学、动力学、坐标变换);(3)计算机视觉在具身场景中的应用;(4)强化学习与模仿学习;(5)视觉-语言-动作(VLA)大模型全景;(6)视觉语言导航(VLN)技术;(7)世界模型最新进展;(8)无人机控制与规划专题;(9)仿真环境与真机部署;(10)数据集与评估基准。本文强调"理论-实践-复现"三位一体的学习路径,为工程师和从业者提供从入门到前沿复现的完整技术指南。
关键词:具身智能、机器人学习、视觉-语言-动作模型、VLA、视觉语言导航、VLN、世界模型、强化学习、模仿学习、MuJoCo仿真
目录
- 引言
- 具身智能基础理论
- 机器人学基础
- 具身场景的计算机视觉
- 强化学习与模仿学习
- 视觉-语言-动作(VLA)大模型
- 视觉语言导航(VLN)
- 具身世界模型
- 无人机控制与规划专题
- 仿真环境与真机部署
- 数据集与评估基准
- 工程实践指南
- 总结与展望
1. 引言
1.1 什么是具身智能?
人工智能的发展历程中,我们见证了从"非具身"(Disembodied)到"
盘古大模型关键技术解读
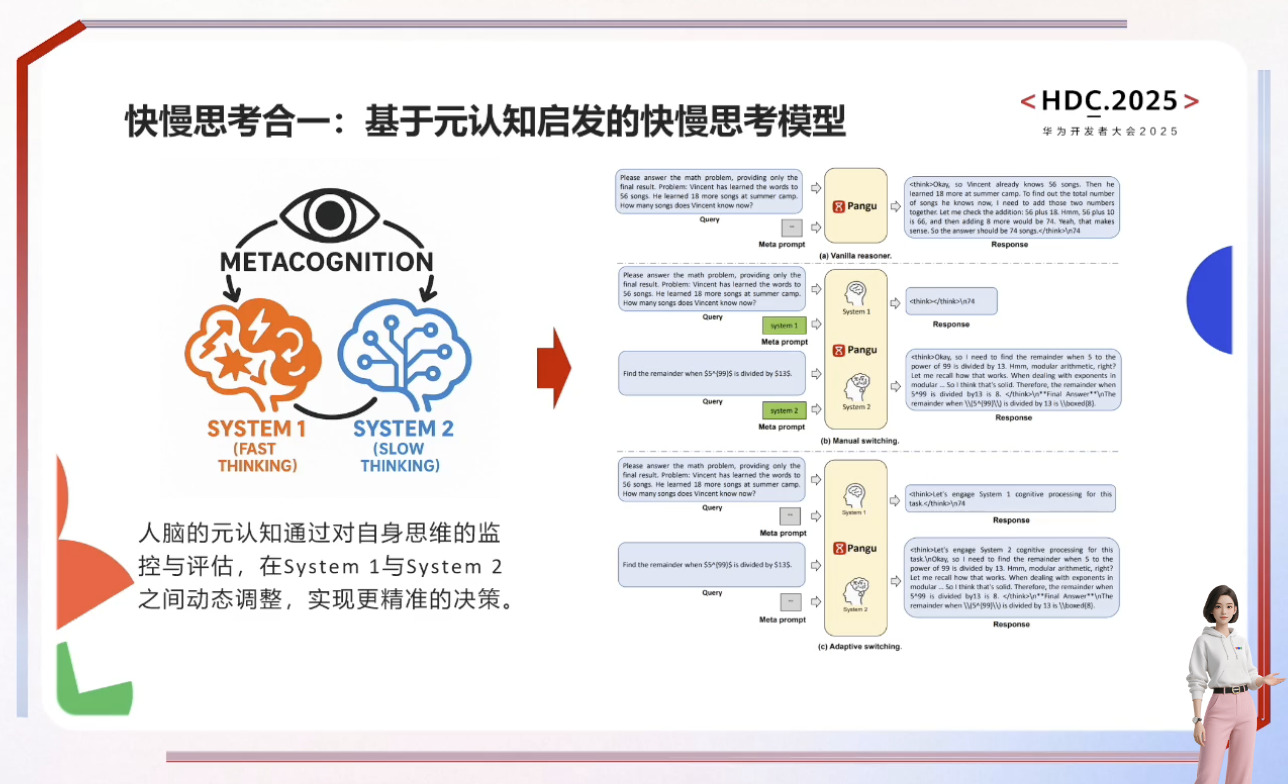
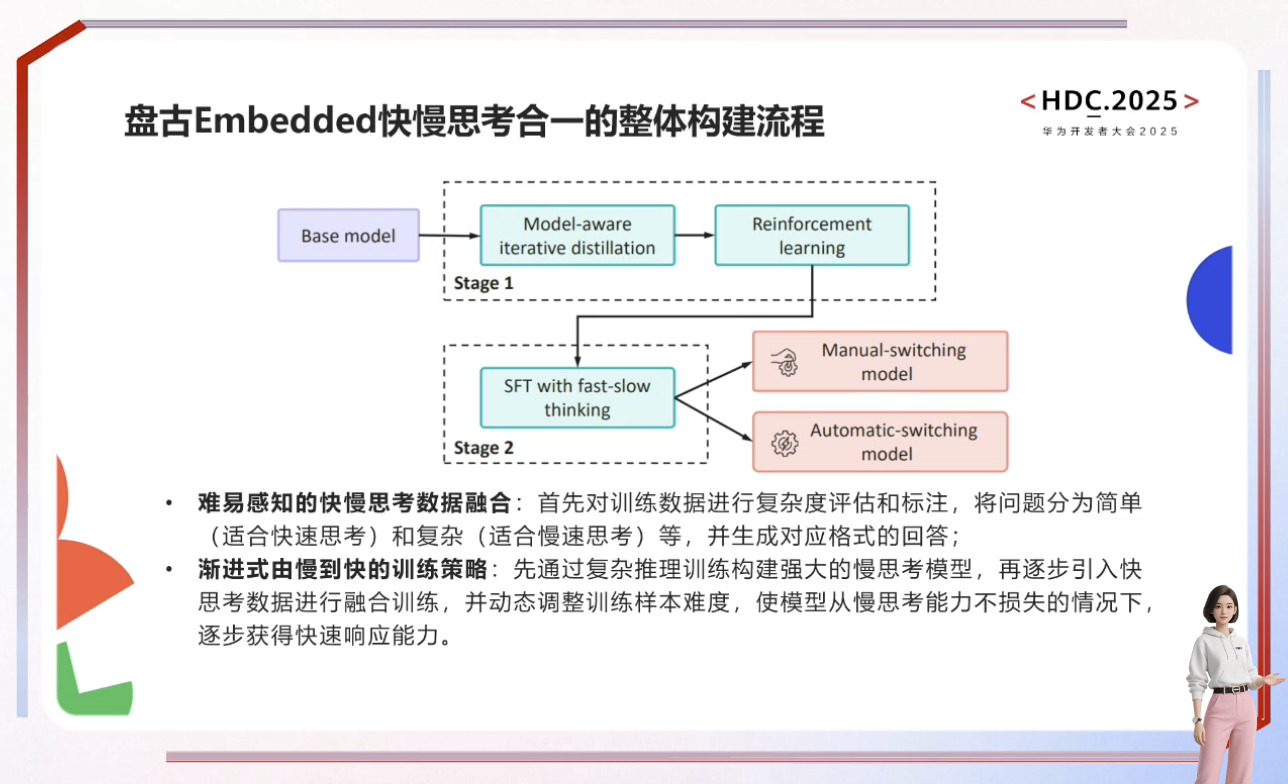
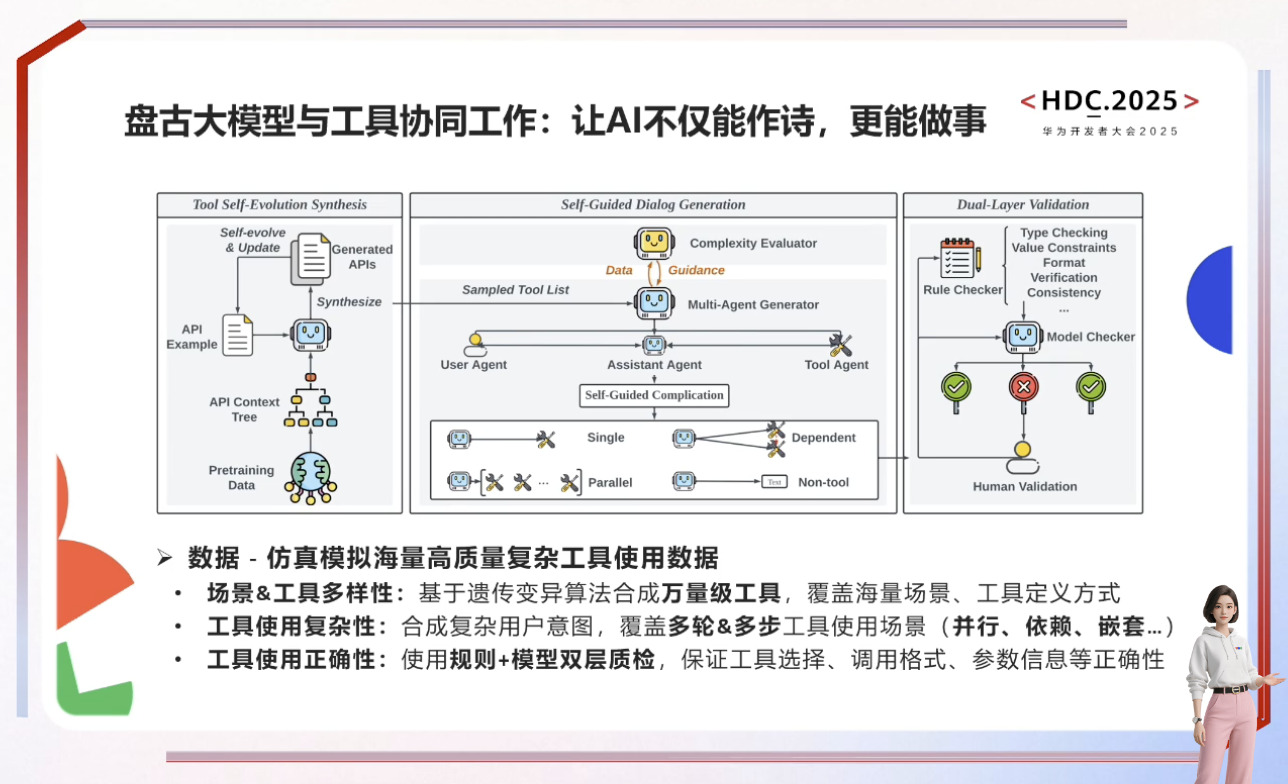
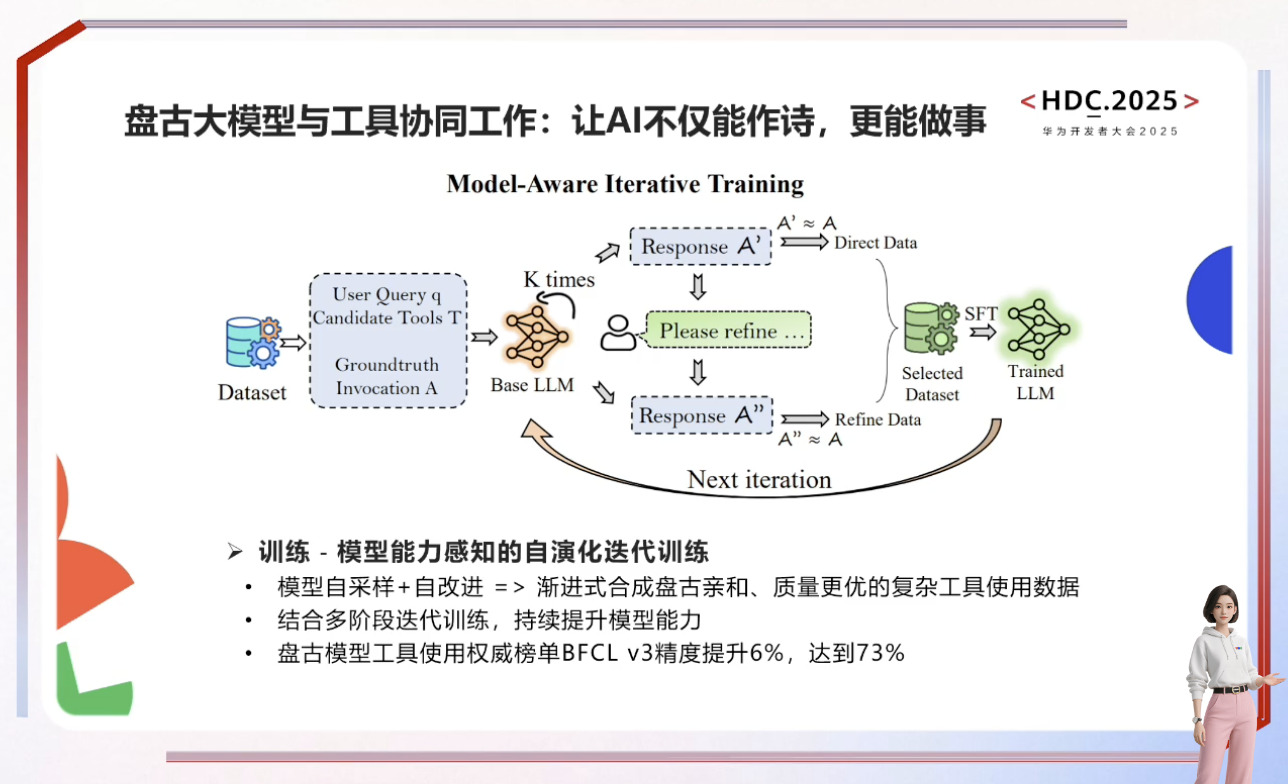
自动驾驶与具身智能的发展依赖于世界模型和虚拟环境的构建,通过数字孪生和4D物理空间模拟真实世界规律以解决训练数据不足和安全性问题。盘古NLP大模型借助外部工具提升行业智能水平,而具身智能需融合3D空间理解、物理推理及行为预测能力,最终实现在高危场景中超越人类的目标。尽管发展曲折,但SFT训练链条和通用机器人愿景已展现潜力,预测大模型则致力于打破数据孤岛,通过原子级表达实现跨场景统一推演,推动AI向善与社会效率提升。
基础模型
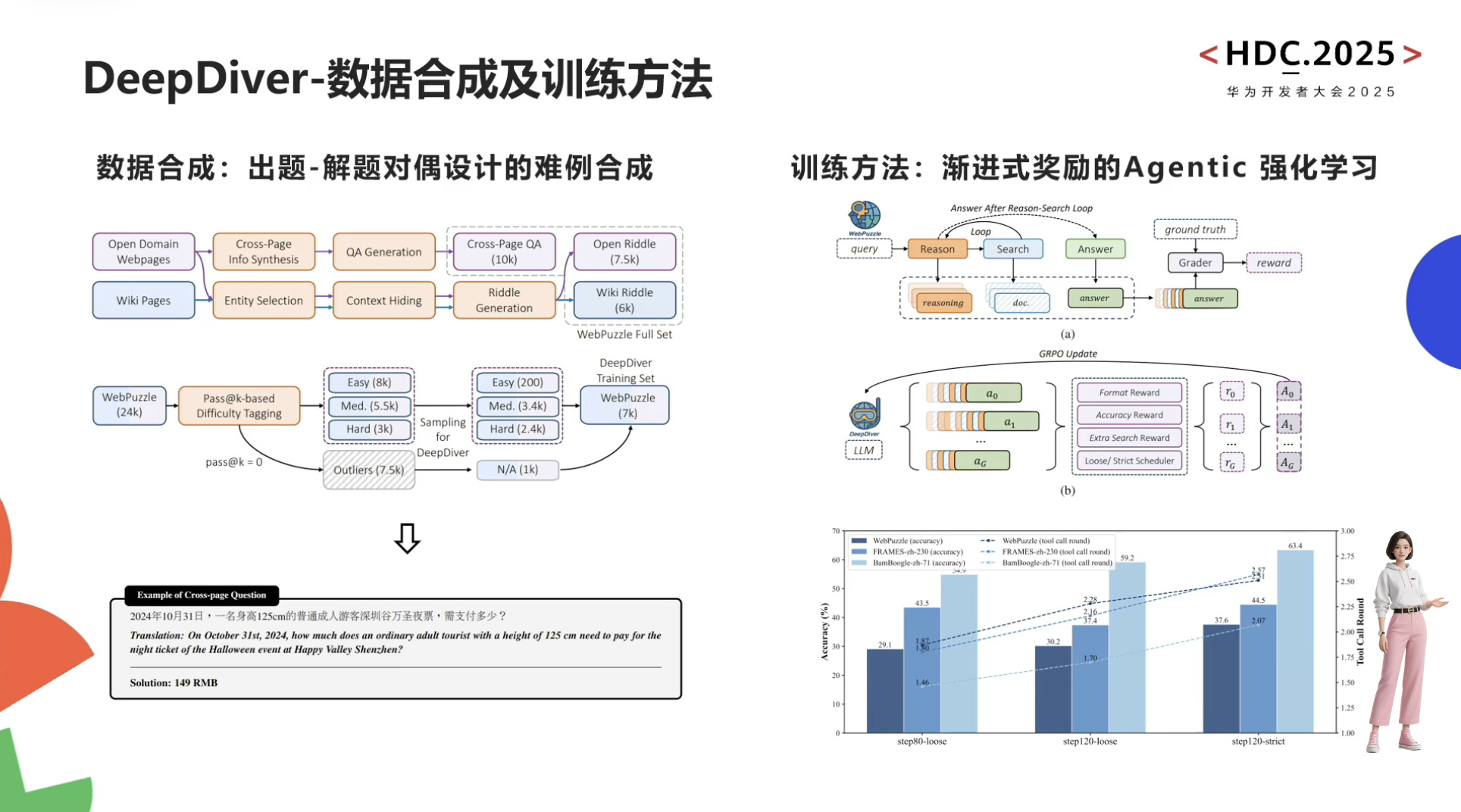

世界模型
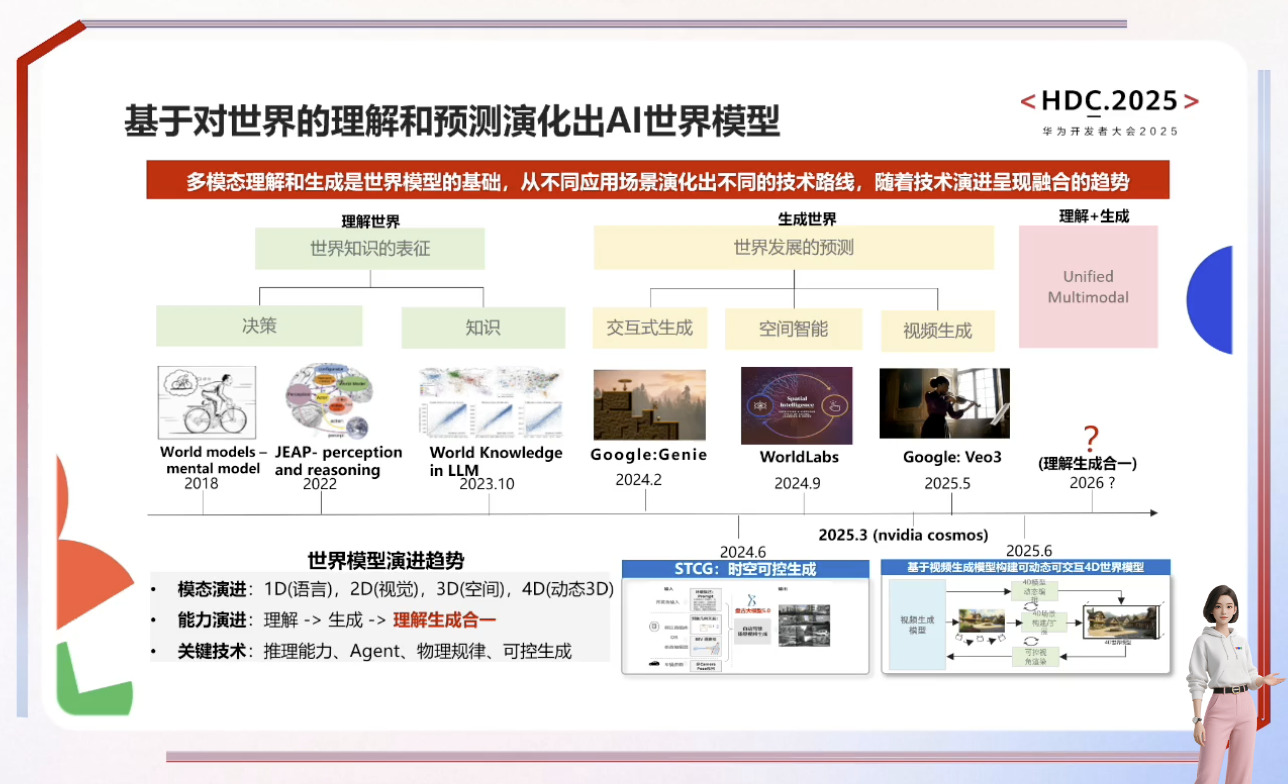
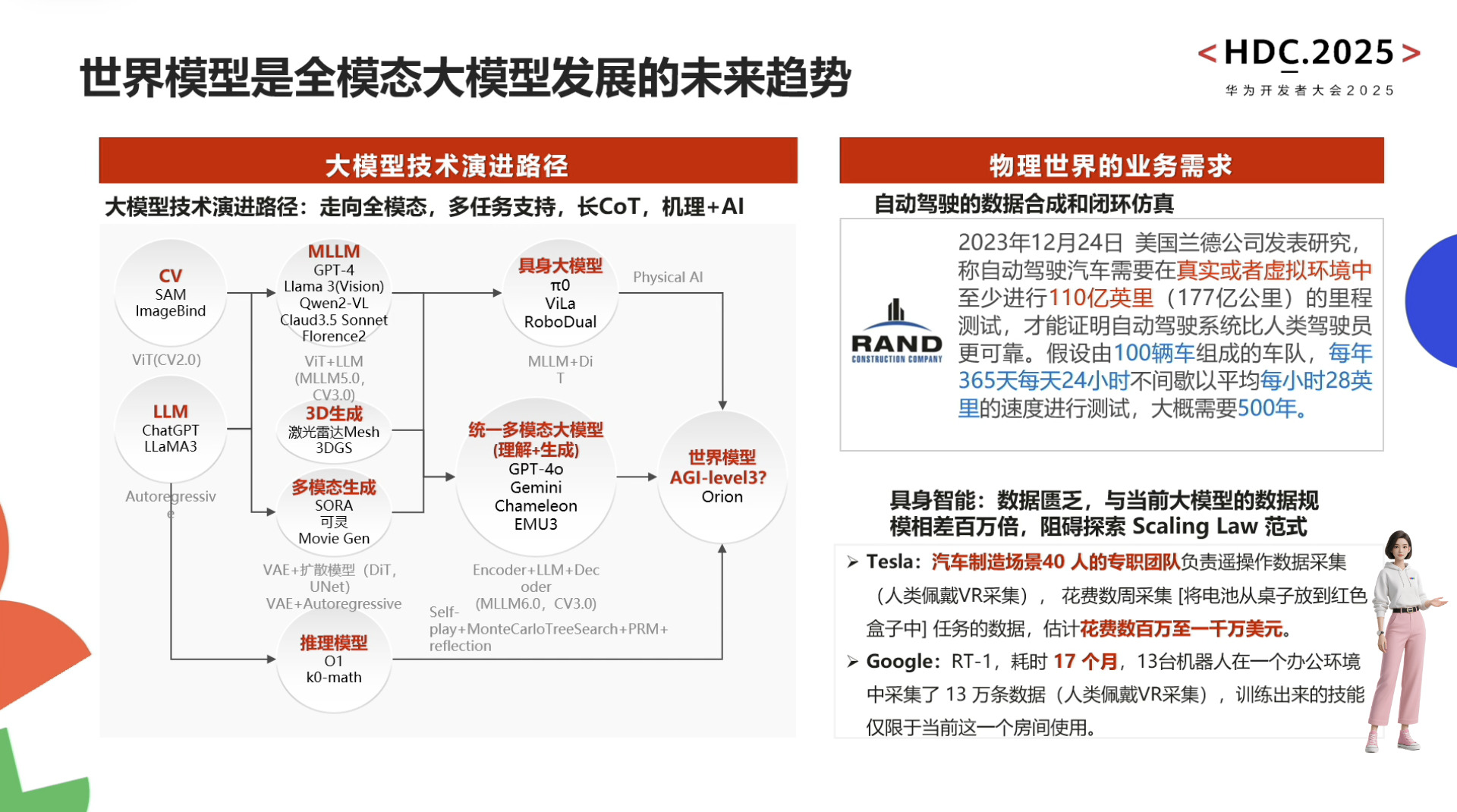











具身智能









预测大模型







参考资料