深度网络连接范式演进:残差连接 → 超连接 (HC) → 流形约束超连接 (mHC)
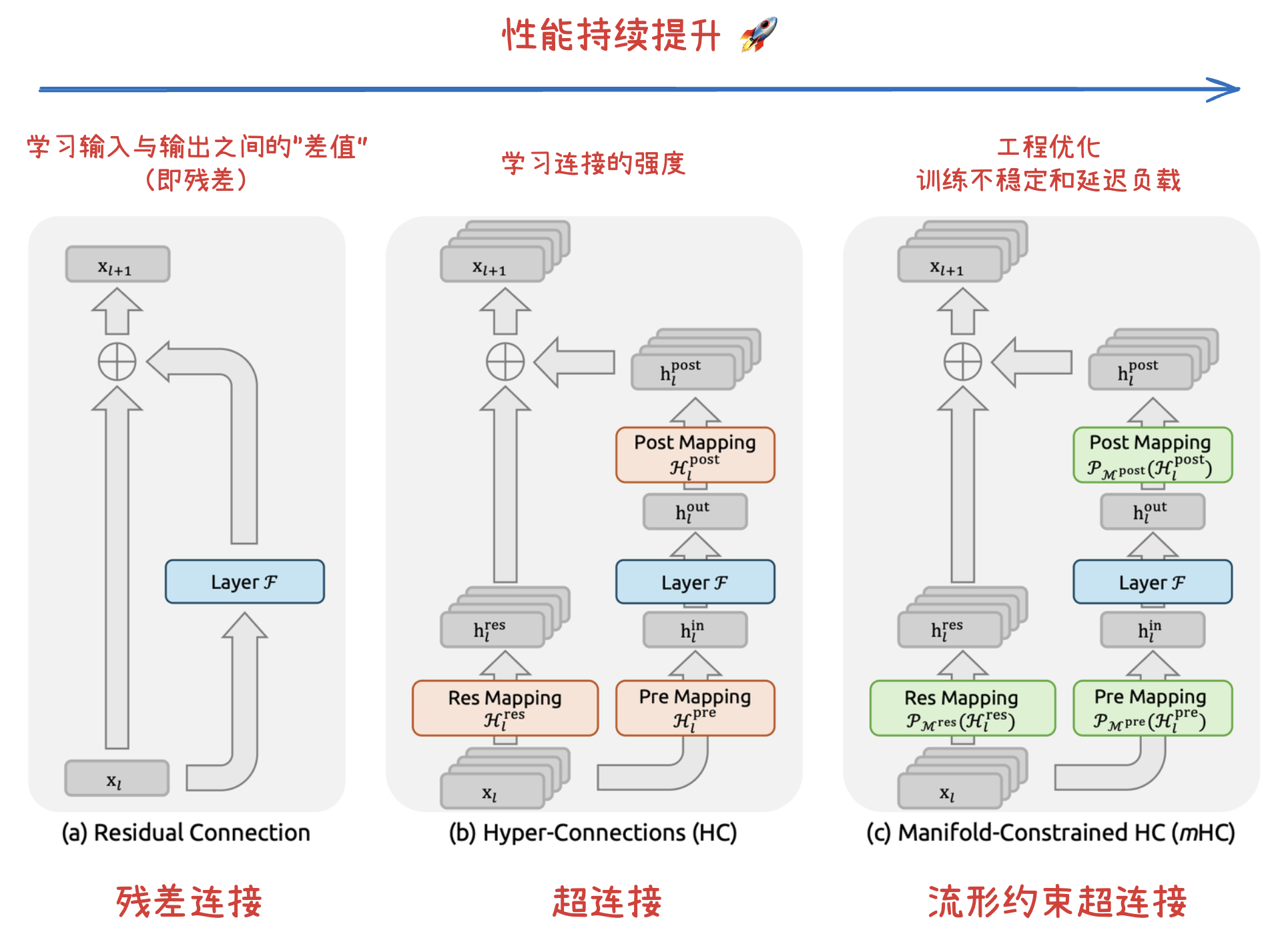
深度神经网络架构的演进,本质上是在寻找梯度稳定性与特征表达力的最优解:残差连接 通过恒等映射初步破解了深层网络的退化难题,但在缓解梯度消失与防止表征坍缩之间仍存在“跷跷板效应”;超连接(HC) 在此基础上打破了固定连接的束缚,通过引入可学习的深度连接与宽度连接,允许网络“自主学习最优连接强度”,显著提升了大模型训练的性能;流形约束超连接(mHC) 则通过将 HC 的连接矩阵投影至双随机流形,利用数学上的凸组合约束恢复了恒等映射的数值稳定性,并辅以算子融合、选择性重算和 DualPipe 通信重叠等工程优化,最终在大模型训练中实现了训练稳定性和显著降低延迟负载。
深度神经网络
梯度消失与梯度爆炸
在深度学习中,梯度消失(Vanishing Gradient) 和 梯度爆炸(Exploding Gradient) 是训练深层神经网络时经常遇到的两个核心障碍。
它们本质上是由于神经网络在反向传播过程中,梯度通过多层链式法则累积相乘导致的数值稳定性问题。
数学根源:链式法则的连乘效应
在反向传播时,我们需要计算损失函数对某一层权重的偏导数。根据链式法则,对于每一层,其梯度贡献项通常与激活函数的导数以及权重的数值有关。
- 梯度消失: 如果每一层的梯度项都小于 1(例如使用 Sigmoid 激活函数,其导数最大值仅为 0.25),经过 层连乘后,梯度会呈指数级衰减。当层数很多时,靠近输入层的梯度会变得接近于 0,导致权重无法更新,网络停止学习。
- 梯度爆炸: 如果每一层的权重较大(例如 ),且激活函数的导数也大于 1,梯度会随着层数的增加呈指数级增长。这会导致权重更新步长过大,数值溢出(出现
NaN),模型剧烈震荡甚至崩溃。