这篇研究论文介绍了 DSpark,一个由北京大学和 DeepSeek-AI 联合开发的投机采样(Speculative Decoding)大模型推理加速框架。以下是该论文的核心要点总结:
核心痛点
传统的投机采样在提高大模型推理速度上面临两个瓶颈:
- 生成质量退化(后缀衰减): 并行草稿模型(如 DFlash)虽然生成速度快,但因为各 Token 独立预测,缺乏前后依赖关系,容易产生语义冲突(多模态碰撞),导致后面 Token 的接受率急剧下降。
- 系统效率浪费: 在高并发的生产环境中,如果不加选择地验证所有生成的草稿 Token,会浪费宝贵的计算算力去验证那些极易被拒绝的末尾 Token,从而降低系统整体吞吐量。
DSpark 的核心架构与创新
DSpark 通过结合高吞吐的并行生成与自适应的负载感知验证,完美平衡了这两大难题:
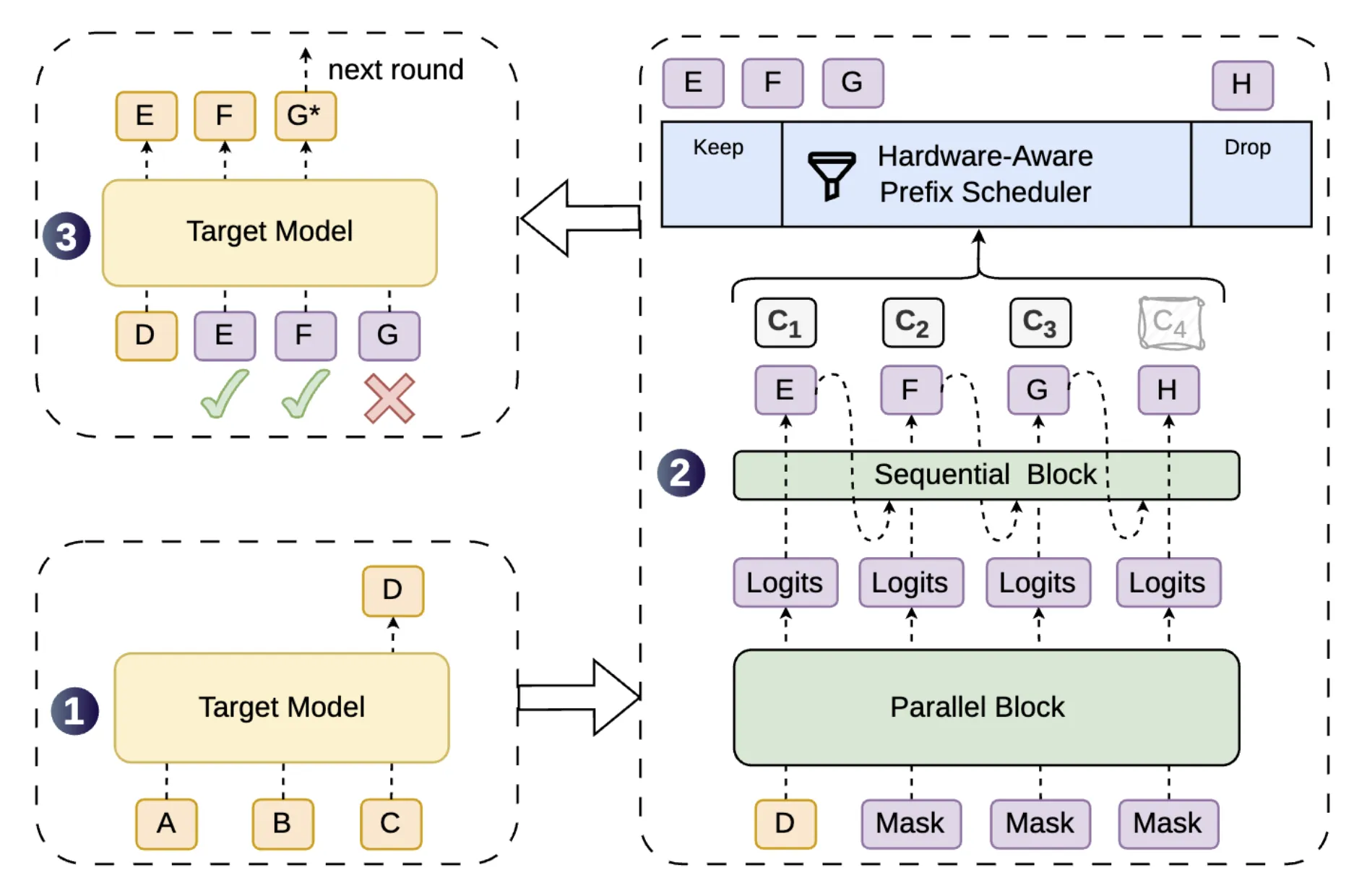
1. 半自回归生成(Semi-Autoregressive Generation)
- 并行骨干+轻量串行头: 保持昂贵的草稿模型主干完全并行(继承 DFlash 速度),但仅在输出端附加一个极轻量的串行模块(默认使用低秩因子化的 Markov 头,或使用 RNN 头)。
- 效果: 在保持高 drafting 速度的同时,为一整块 Token 注入了 causal 上下文依赖,大幅缓解了后缀衰减问题。
2. 置信度调度验证(Confidence-Scheduled Verification)
- 置信度预测头(Confidence Head): 预测每个位置的草稿 Token 在前置 Token 被接受的前提下,自身也能被接受的条件概率。
- 序列温度缩放(STS): 针对神经网络普遍“过度自信”的问题,引入 STS 进行后验校准,使计算出的累积生存概率精准反映实际接受率。
- 硬件感知前缀调度器(Hardware-Aware Prefix Scheduler): 结合实时硬件算力曲线和置信度,将验证长度选择转化为“全局吞吐量最大化”问题。在低负载时多验证,在高并发重负载时主动裁剪低置信度的末尾 Token,防止算力浪费。
主要实验结果
离线基准测试(Offline Benchmarks)
在 Qwen3(4B/8B/14B)和 Gemma4-12B 等目标模型上,涵盖数学推理(GSM8K)、代码生成(HumanEval)和日常对话(MT-Bench)等多领域的测试显示:
- DSpark 的宏观平均接受长度相比自回归模型 Eagle3 提升了 26.7% ~ 30.9%。
- 相比前沿并行模型 DFlash 提升了 16.3% ~ 18.4%。
- 实验证明,“微量的自回归(A Little Autoregression)”能够以极低的延迟开销(0.2%~1.3%)换取大幅的接受率提升。
生产环境实测(Live User Traffic)
DSpark 已成功部署于 DeepSeek-V4(Flash 和 Pro 预览版)的线上生产 serving 系统中:
- 速度大幅提升: 在相同的系统吞吐量下,DSpark 将用户的单并发生成速度(tok/s/user)提升了 60%~85%(V4-Flash)和 57%~78%(V4-Pro)。
- 拓宽服务边界: 在严格的低延迟 SLA 约束下(例如 Flash 120 TPS,Pro 50 TPS),传统方案会发生计算崩溃,而 DSpark 通过动态裁剪验证预算,成功维持了鲁棒的吞吐表现,彻底推高了 serving 系统的帕累托前沿(Pareto Frontier)。
开源贡献: 团队已将 DSpark 的模型权重,以及驱动投机采样算法训练的开源代码库 DeepSpec(集成了 Eagle3、DFlash 和 DSpark)向社区完全开源。