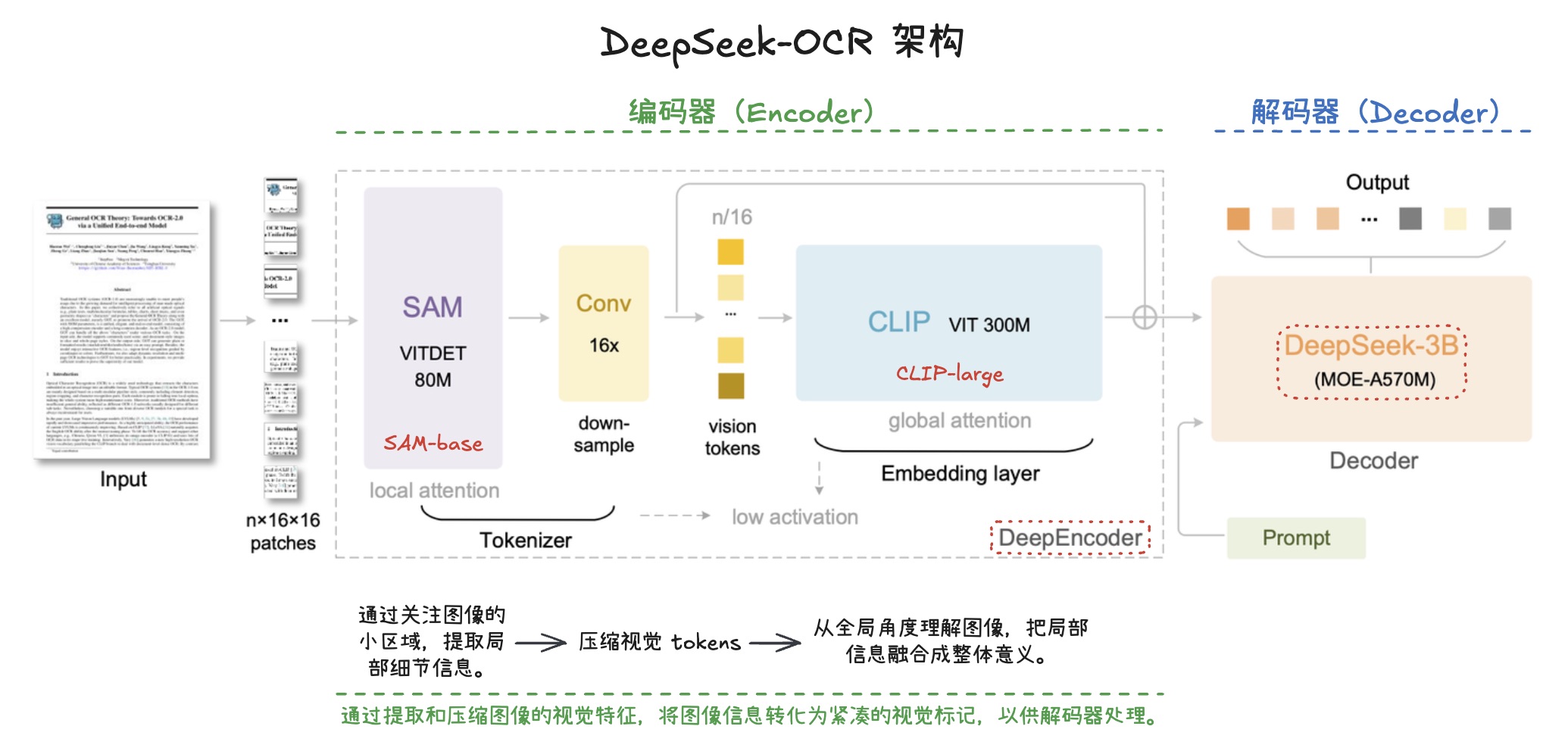
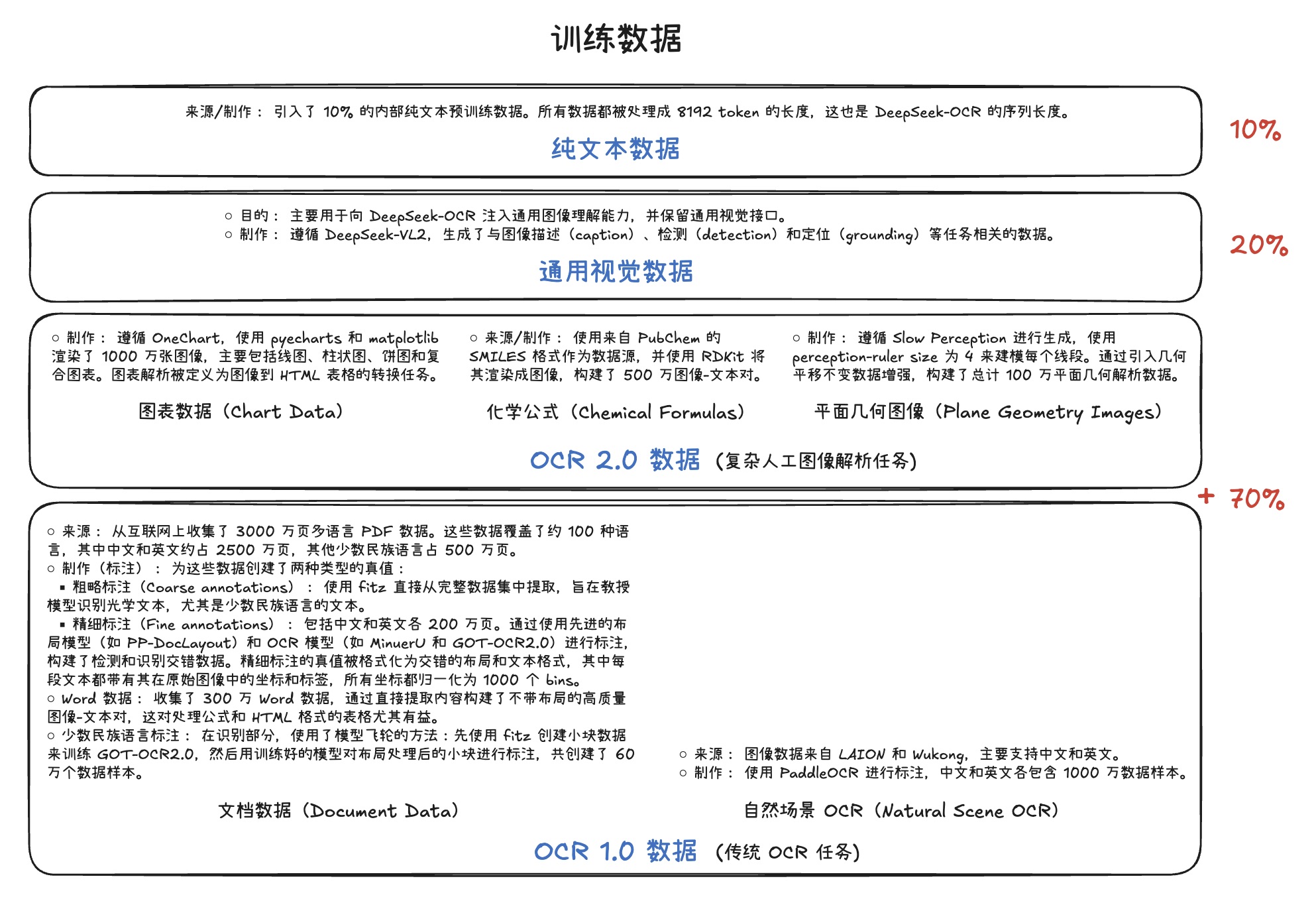
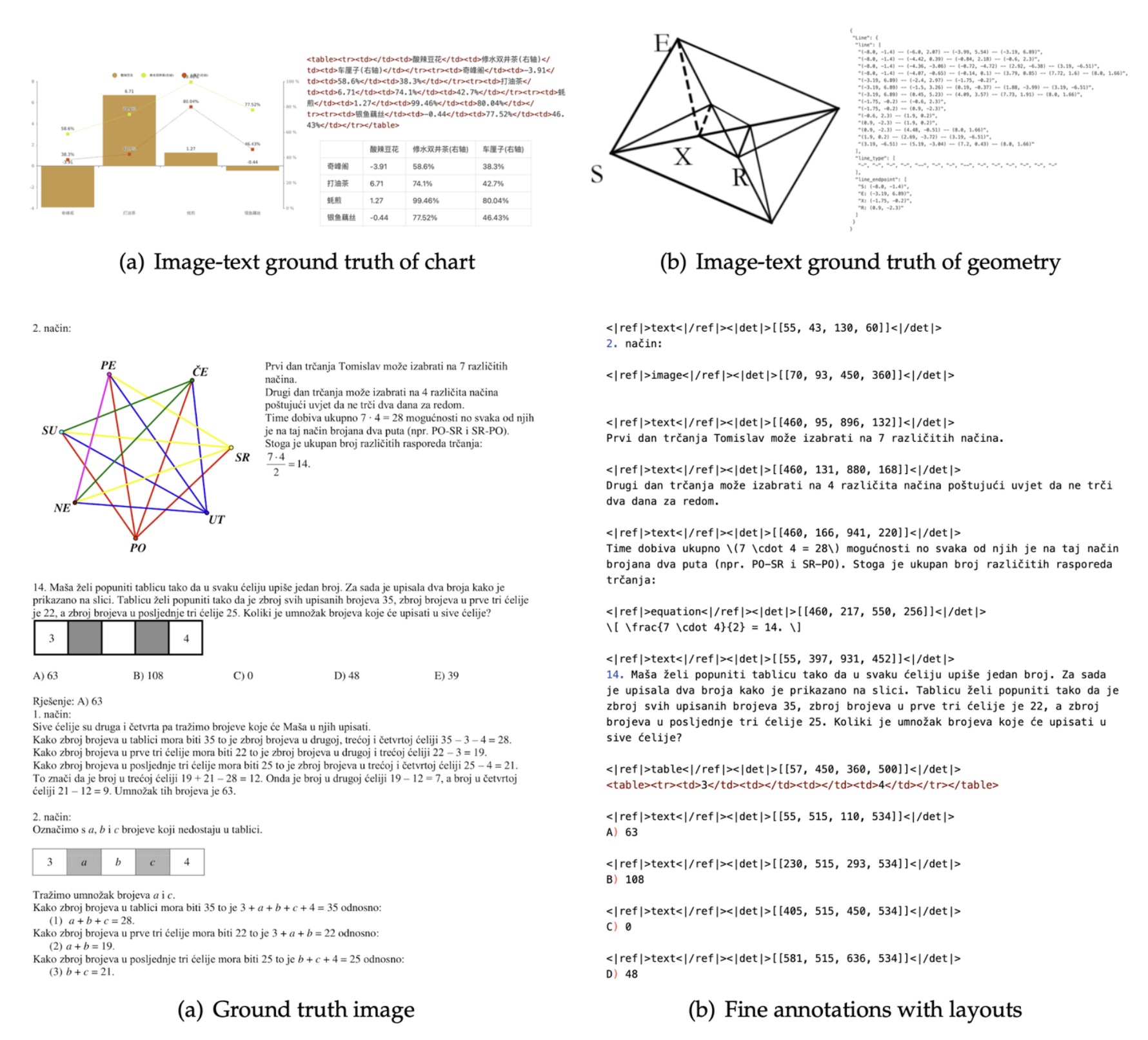
MinerU 是 OpenDataLab 开源的一款高精度文档解析引擎,能把 PDF、DOCX、PPTX、XLSX、图片和网页转换成结构化的 Markdown 或 JSON,方便下游 LLM、RAG 和 Agent 工作流直接消费。
What|是什么
MinerU 的定位是“为 LLM 准备数据”的文档解析基础设施。它支持多种输入格式,输出则强调人类阅读顺序和语义结构:
- 输入:PDF、图片、DOCX、PPTX、XLSX、网页
- 输出:Markdown、JSON(按阅读顺序)、多模态 Markdown,以及可可视化的中间格式
- 核心能力:自动去除页眉页脚页码、识别多栏与复杂版式、提取表格/图片/公式、公式转 LaTeX、表格转 HTML、OCR 识别 109 种语言
- 提供 CLI、FastAPI、Gradio WebUI、Docker 和
mineru-router等多种使用形态
Why|为什么值得关注
MinerU 诞生于 InternLM 预训练过程中的实际需求,最初是为了解决科技文献中的符号转换问题。相比直接购买商业文档解析服务,它的几个亮点很突出:
- VLM + OCR 双引擎:
pipeline后端快且省资源,vlm-engine/hybrid-engine后端精度更高,可按场景选择 - 全格式原生解析:3.0 以后陆续加入 DOCX、PPTX、XLSX 原生解析,避免先转 PDF 再解析带来的信息损失
- 许可更友好:从 AGPLv3 切换到基于 Apache 2.0 的 MinerU Open Source License,降低了商业部署门槛
- 数据说话:
pipeline后端在 OmniDocBench v1.6 上整体得分 86.47,hybrid后端可达 95.39(high 模式)