Andrej Karpathy:大语言模型构建个人知识库的实践指南
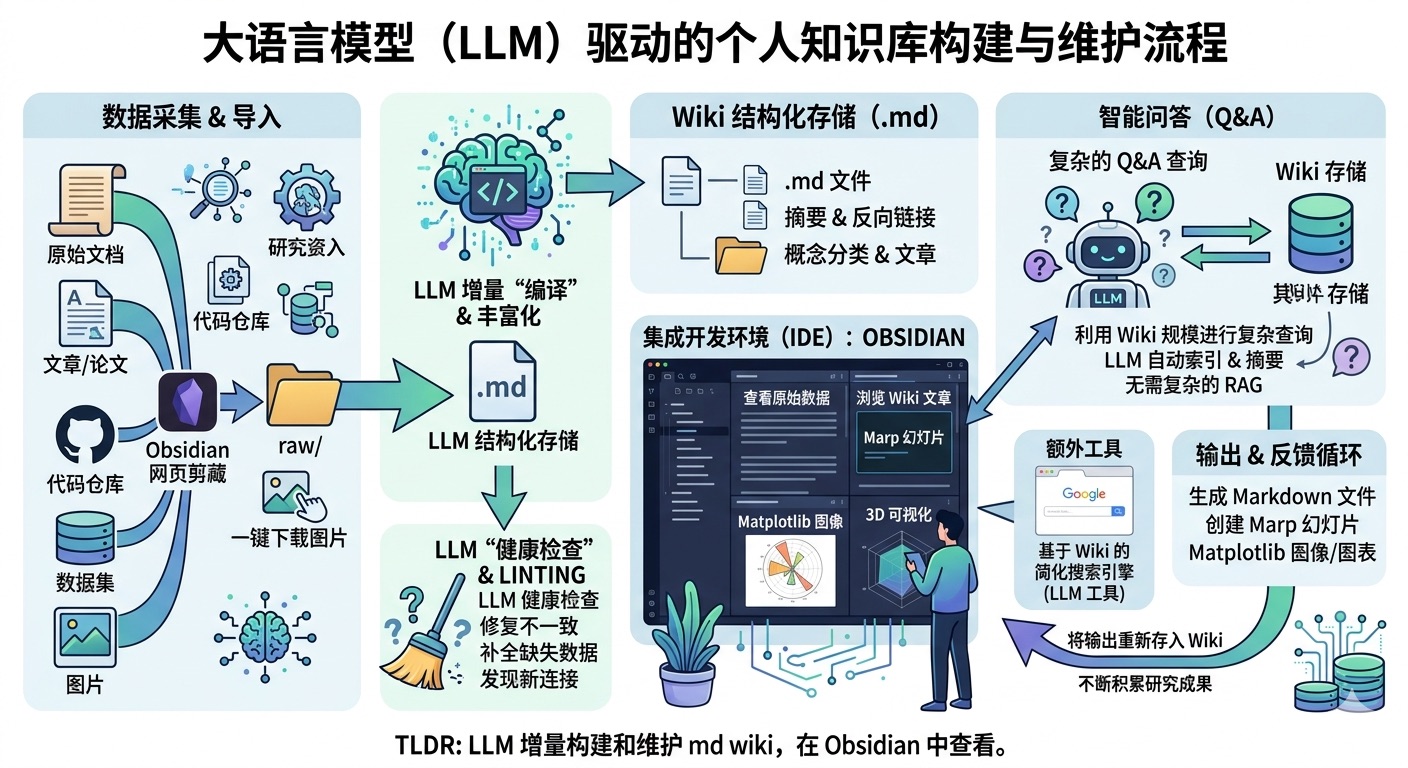
最近我发现一个非常实用的方法:利用大语言模型(LLM)为各类感兴趣的研究方向搭建个人知识库。这样一来,我近期消耗的模型令牌中,用于处理代码的占比大幅减少,更多被用于处理知识(以 Markdown 文件和图片形式存储)。最新的大语言模型在这方面表现十分出色。具体做法如下:
数据导入
我先将各类源文件(文章、论文、代码仓库、数据集、图片等)归档到 raw/ 目录下,再通过大语言模型逐步“编译”生成一份知识库,这份知识库本质就是按目录结构组织的一系列 .md 文件。
知识库会包含 raw/ 目录下所有数据的摘要、反向链接,还会将数据按概念分类、撰写对应词条并完成相互关联。
为把网页文章转为 .md 文件,我习惯使用 Obsidian 网页剪藏插件,同时通过快捷键将相关图片批量下载到本地,方便大语言模型直接调用。
集成开发环境
我把 Obsidian 当作前端 IDE,既能查看原始数据、编译后的知识库,也能查看衍生的可视化内容。 需要重点说明的是:整个知识库的内容撰写与维护均由大语言模型完成,我几乎不直接手动修改。我还试用过多款 Obsidian 插件,以其他形式渲染和查看数据(比如用 Marp 制作幻灯片)。
问答交互 真正有意思的是,当知识库规模足够大时(比如我近期的研究知识库已有约 100 篇词条、40 万字),就可以向大语言模型智能体提出各类复杂问题