User: 研究这个网站设计的风格和功能:https://simonwillison.net/
这里有许多不同类型的内容(如Link、TIL、Tool、Entries、Quotes、Notes、Guides等),它是如何融合到一起的。
https://wangjunjian.com/ 是我的博客,我想参考一下。
Kimi: 让我先浏览这两个网站,了解它们的设计风格和内容组织方式。
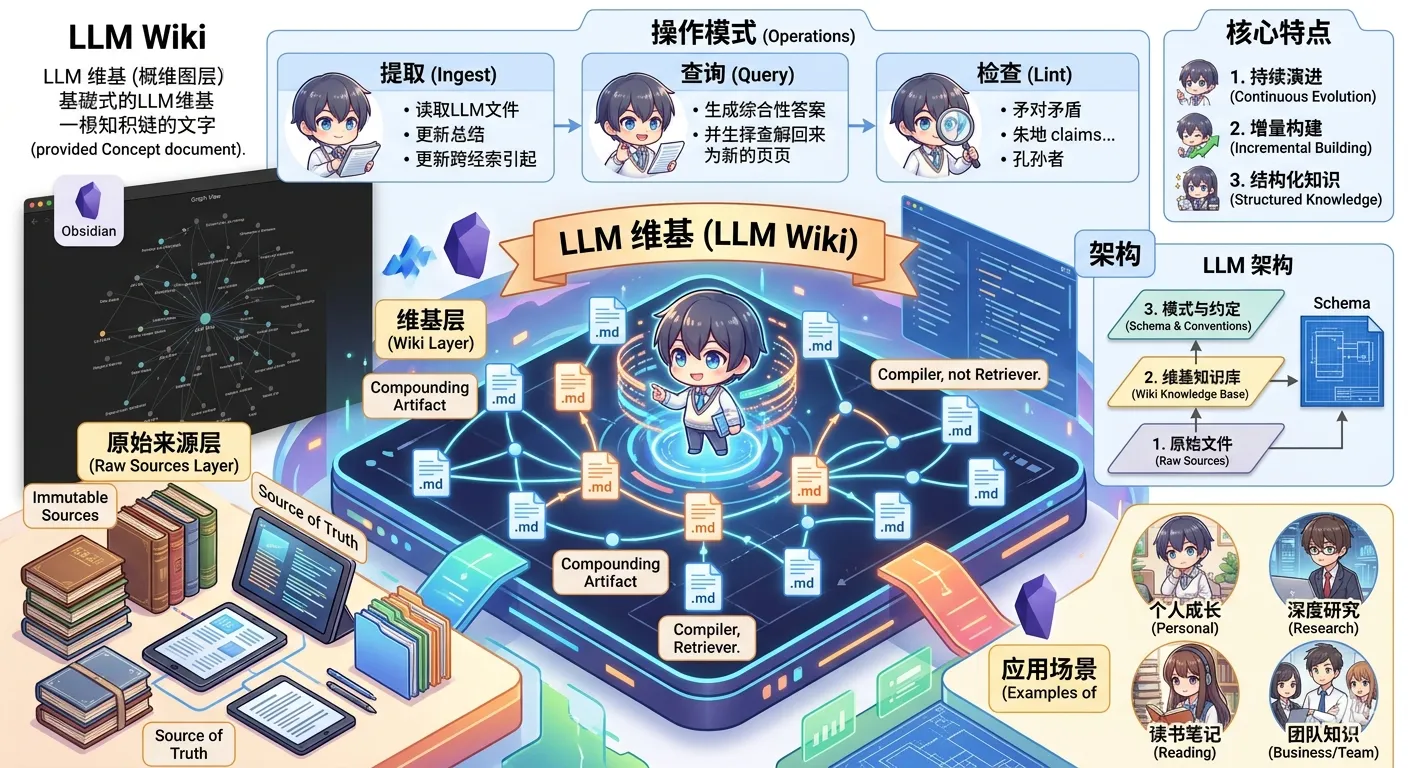
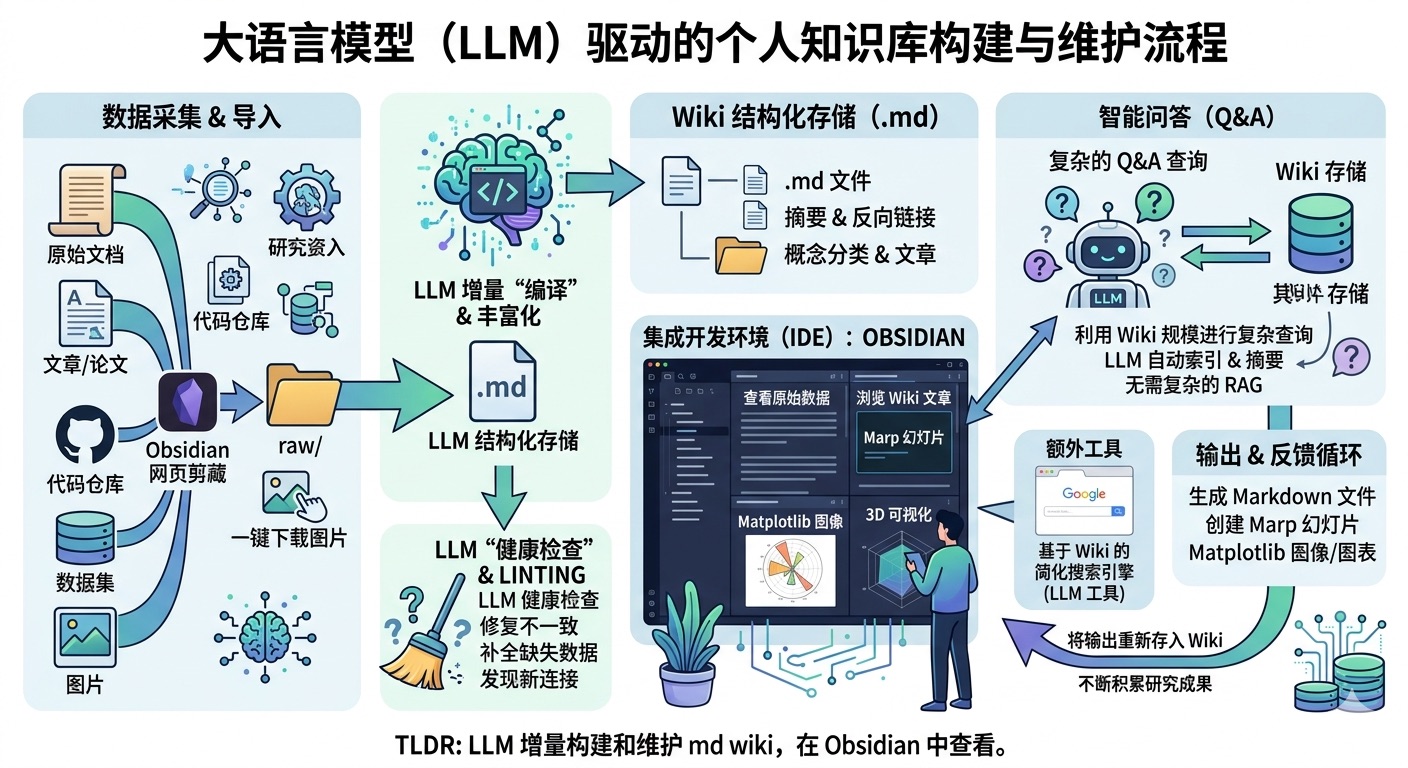
我已经仔细浏览了这两个网站。Simon Willison 的博客是一个非常经典的"个人知识流"设计,它将 Entries、Links、Quotes、Notes、Guides、TILs、Tools 等多种内容类型按时间线无缝融合,配合极简的排版和强大的标签系统。你的博客"军舰的日志"则是更传统的技术博客布局,内容质量很高,主要围绕 AI Agent、LLM 等技术主题。
在我深入研究并给出具体建议之前,想先确认几个关键问题:
- 你想借鉴的侧重点是什么? 是 primarily 学习 Simon 的视觉设计风格和布局(极简、时间流、多种内容类型混排),还是想在自己的博客中也引入多种内容类型(如 Link、TIL、Quotes 等),还是两者都想?
你目前的博客是基于什么技术栈? 比如 Jekyll、Hugo、Next.js、VuePress 等?