研究编码智能体(Kilo Code)开源项目的最佳实践
研究编码智能体开源项目的最佳实践
基于 Kilo Code 的架构特征和当前编码智能体领域的生产实践 ,以下是系统研究此类项目的 方法论框架:
阶段 1:宏观定位(Why & Where)
| 研究维度 | 关键问题 | Kilo Code 的启示 |
|---|---|---|
| Fork 溯源 | 上游是谁?核心差异点?社区分裂原因? | Kilo 从 Roo Code 分叉,差异集中在 Cloud 集成和商业化功能 |
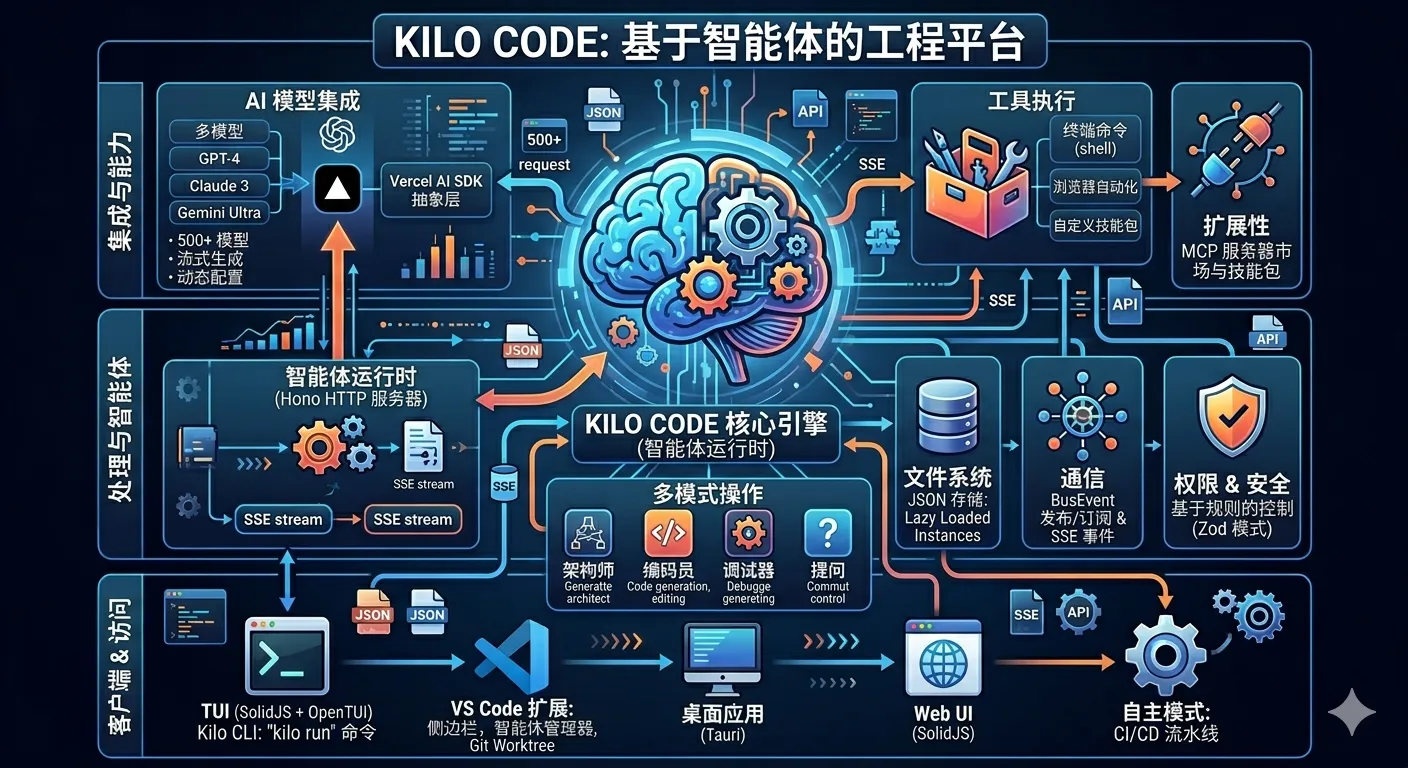
| 生态位 | 是「IDE 插件」「CLI 工具」还是「平台」? | Kilo 是「IDE 扩展 + CLI + Cloud」的三位一体 |
| 许可策略 | 是否存在 BSL/SSPL 等限制性条款? | MIT 许可证,无商业限制 |
| 模型绑定 | 是否硬编码单一提供商? | 模型中立是核心卖点,避免供应商锁定 |
阶段 2:架构解构(How)
建议的代码阅读路径(以 Kilo 为例):
- 入口层 —
src/extension/activate.ts(VS Code 生命周期)、src/extension/api.ts(IPC 外部 API) - 核心代理循环 — 查找
Cline/Roo/Kilo主类,理解 Plan → Act → Verify 的循环 - 工具调用层 —
McpHub如何集成外部工具(文件系统、终端、浏览器) - 上下文管理层 — Memory Bank、Context Mentions、自动索引的实现
- 模式系统 — Custom Modes 的解析与切换逻辑
- 差异标记 — 搜索
// kilocode_change快速定位增量代码