Ultralytics Hub 快速入门
准备数据集
目录结构
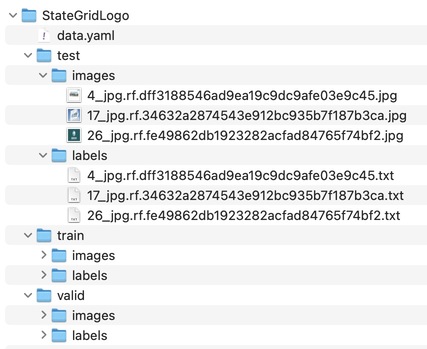
data.yaml
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 1
names: ['logo']
压缩成 zip 文件
Projects
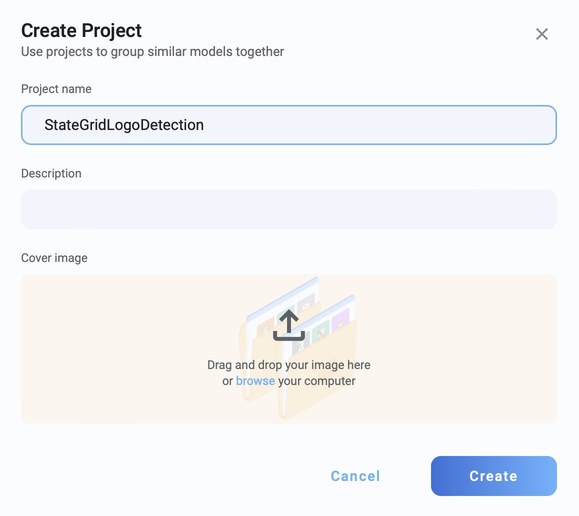
创建项目
Datasets
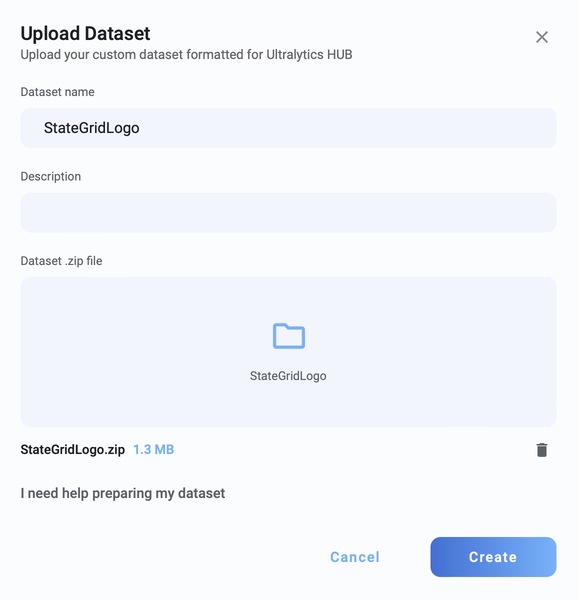
上传数据集
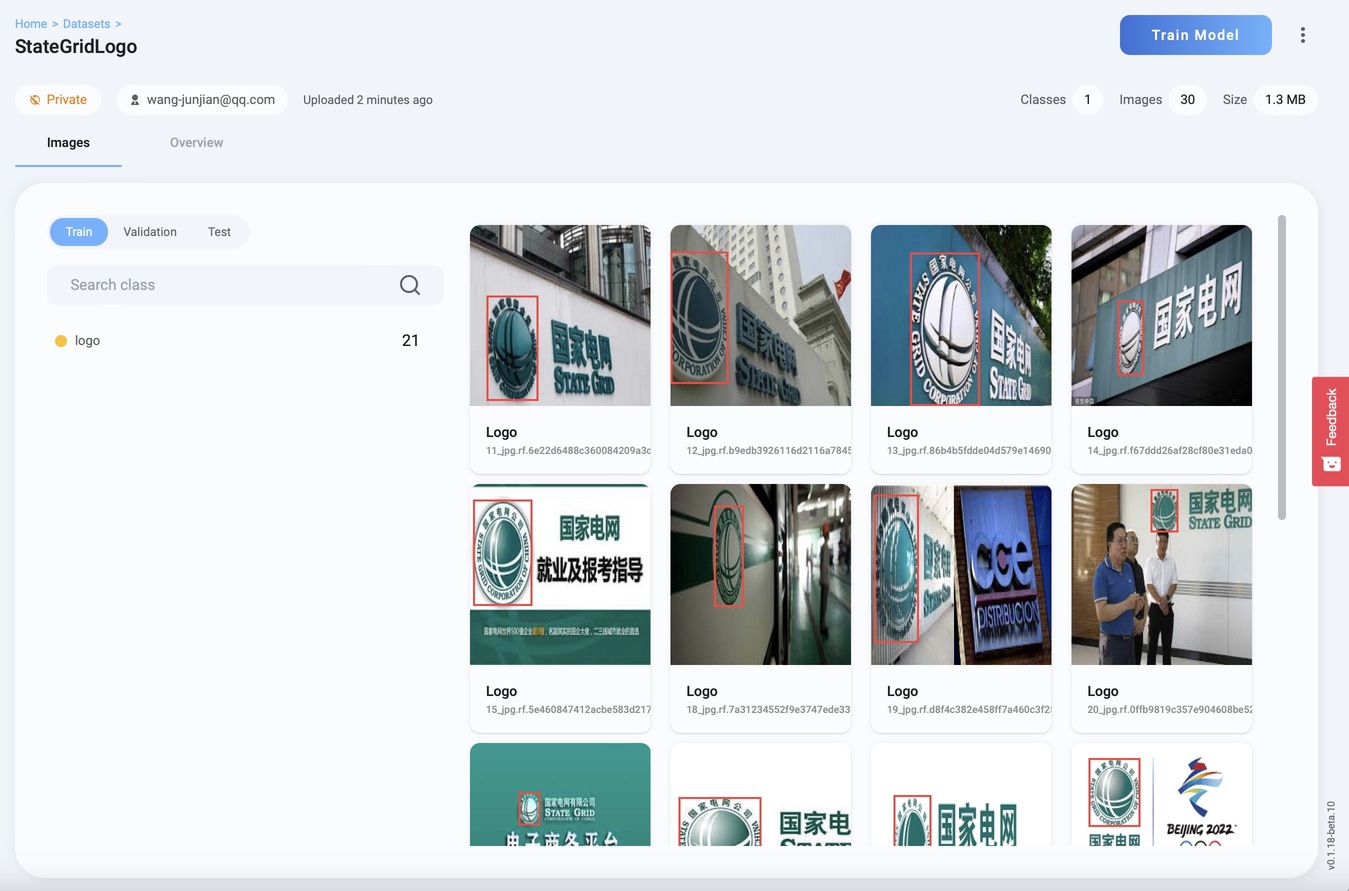
数据集图像
数据集概貌

Train
选择数据集
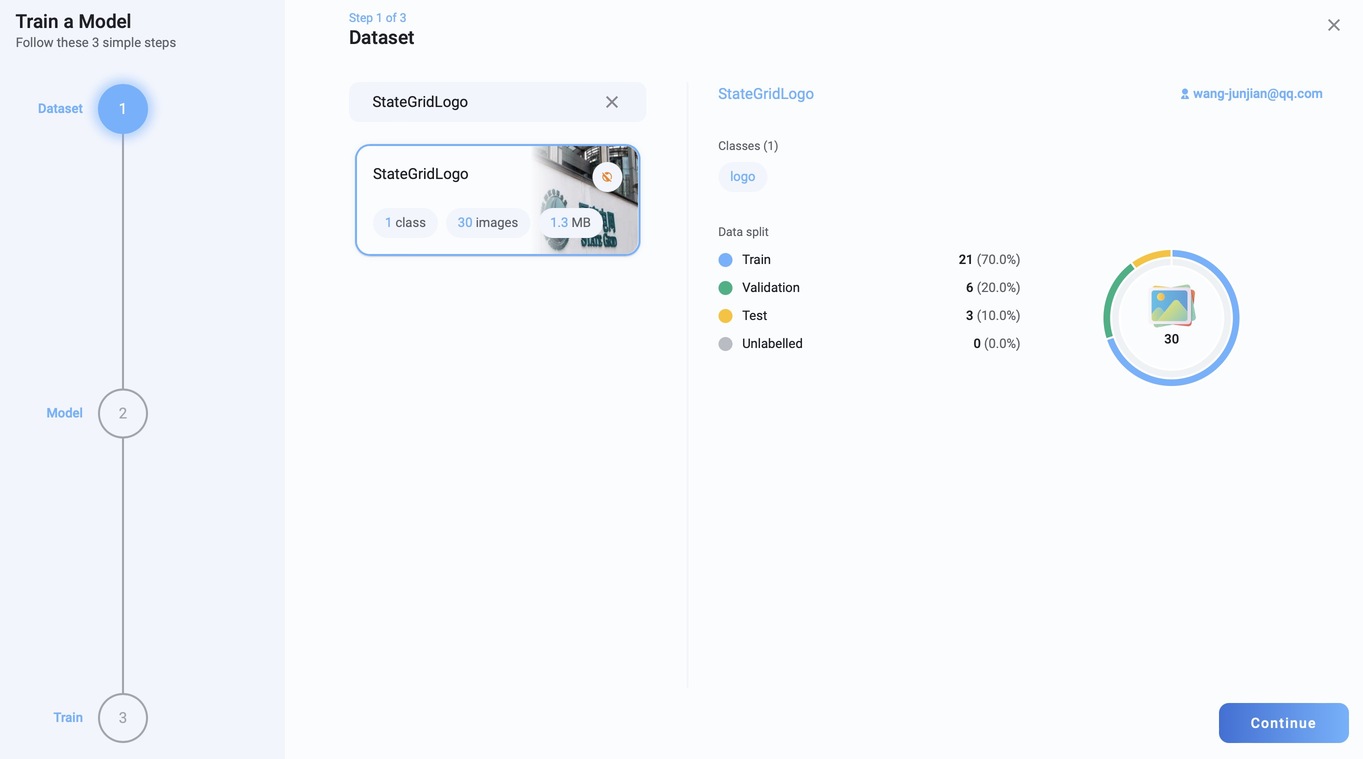
选择模型
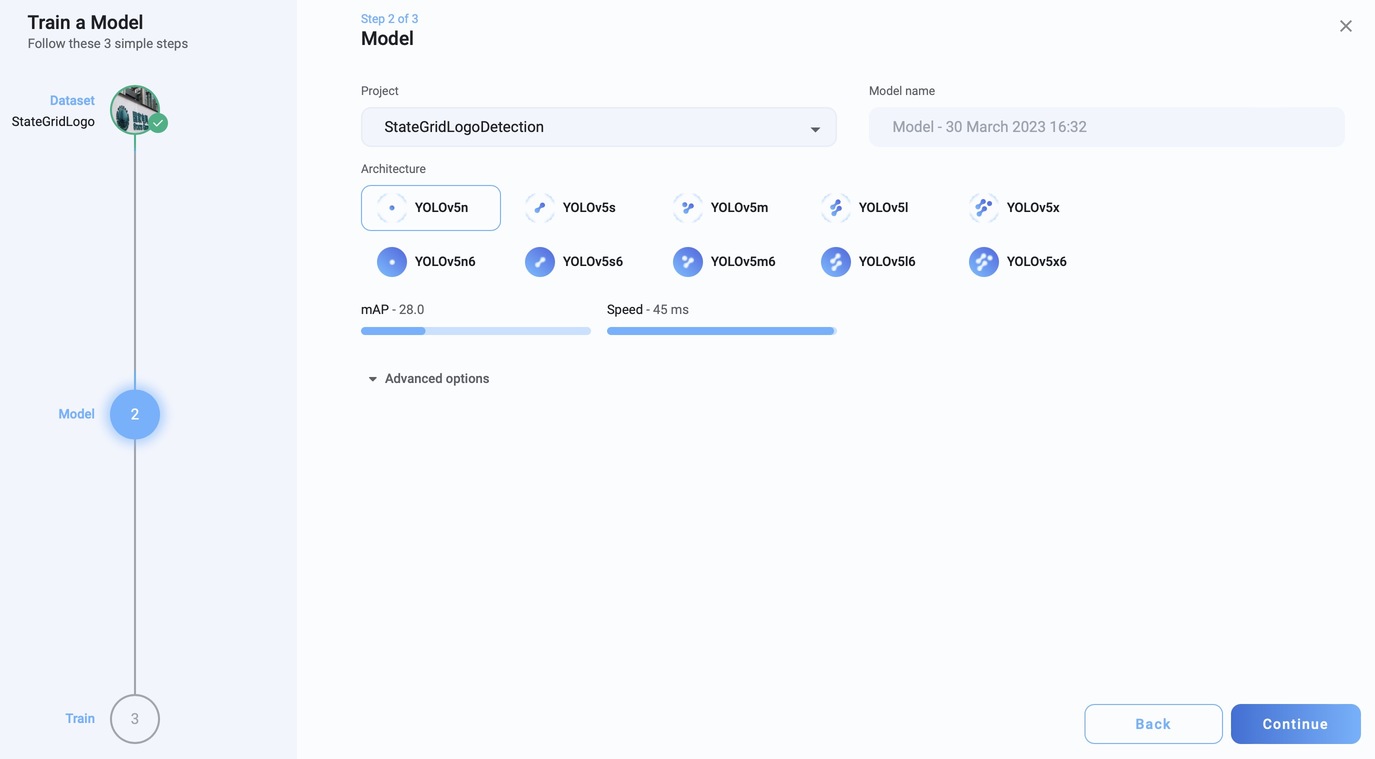
选择训练参数
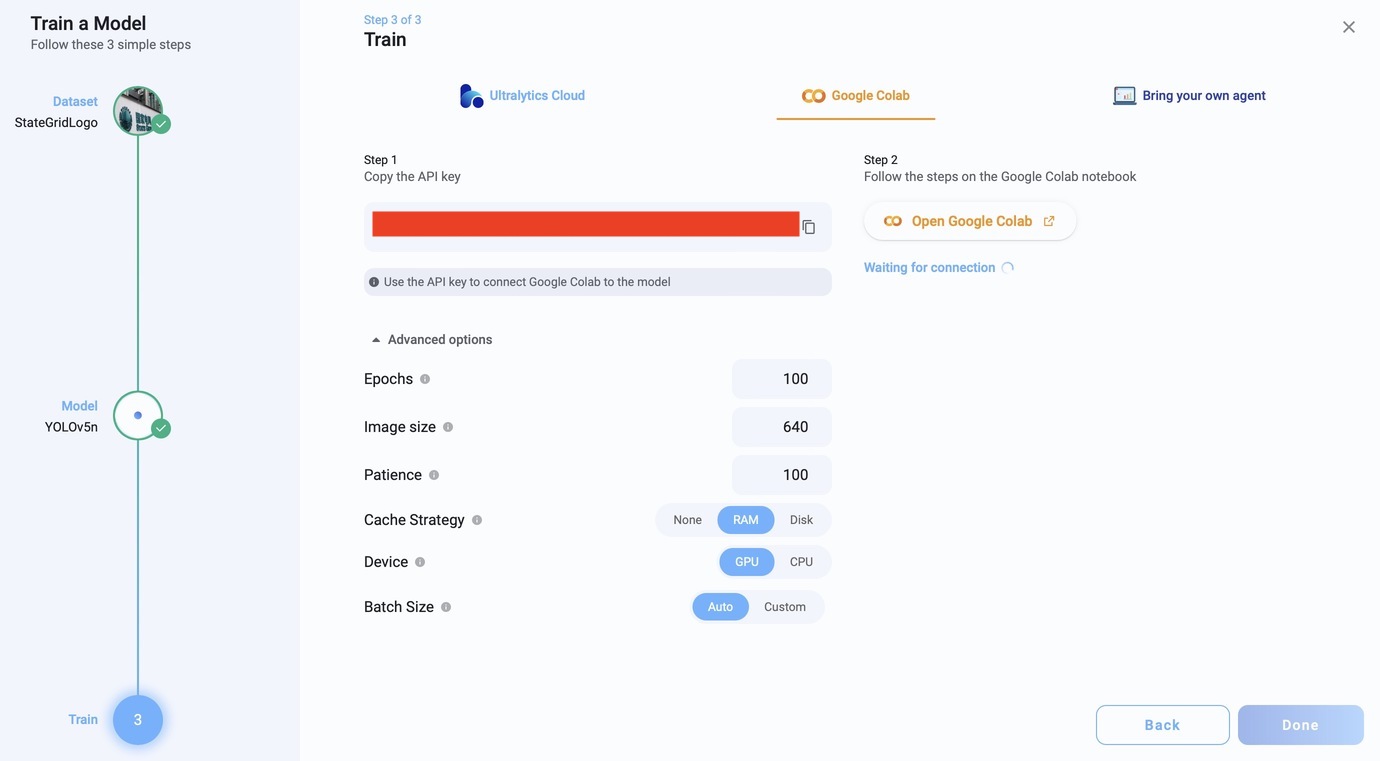
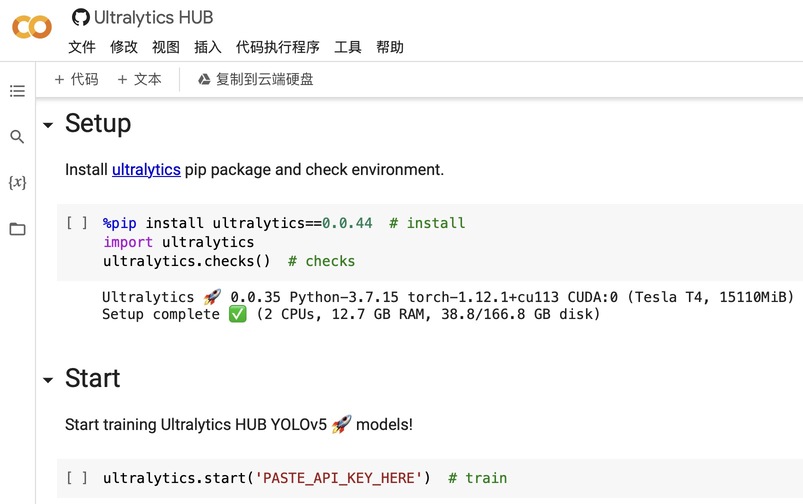
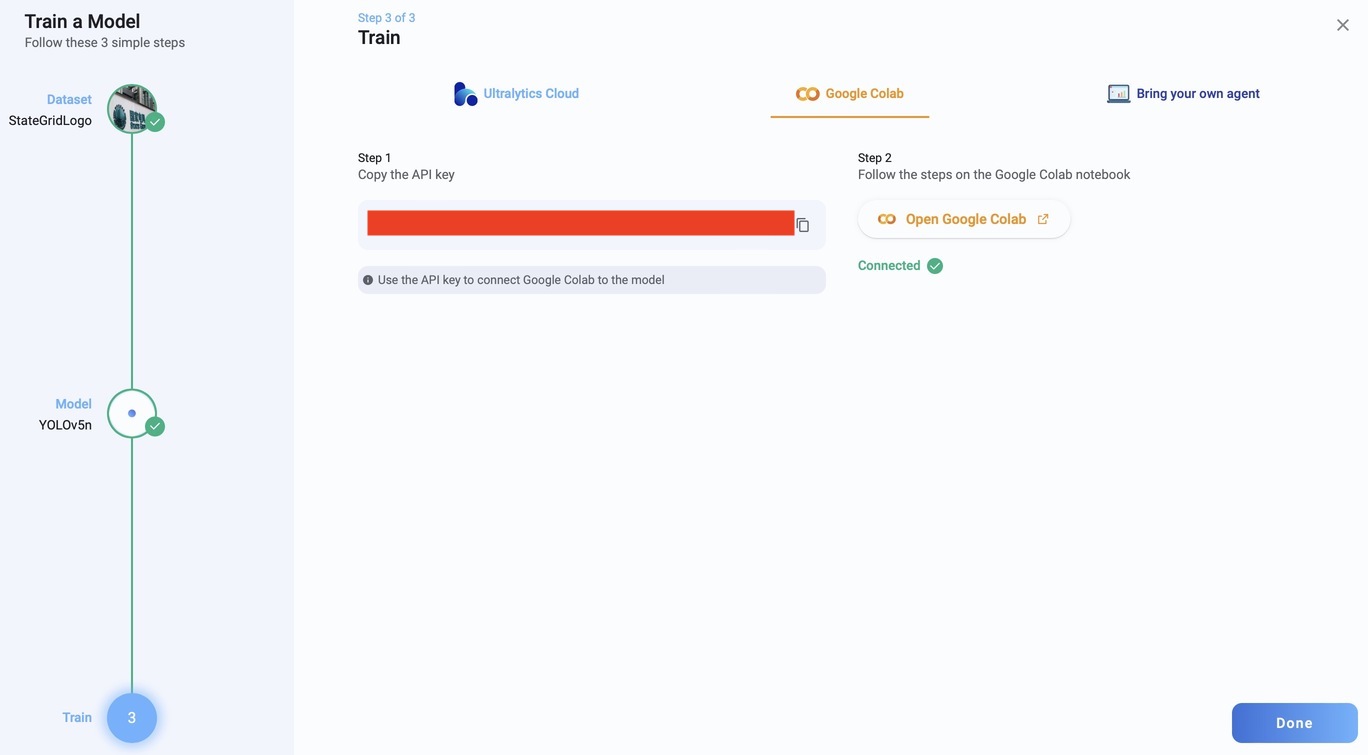
Google Colab 训练模型
使用上图的 API key 替换 PASTE_API_KEY_HERE
Done
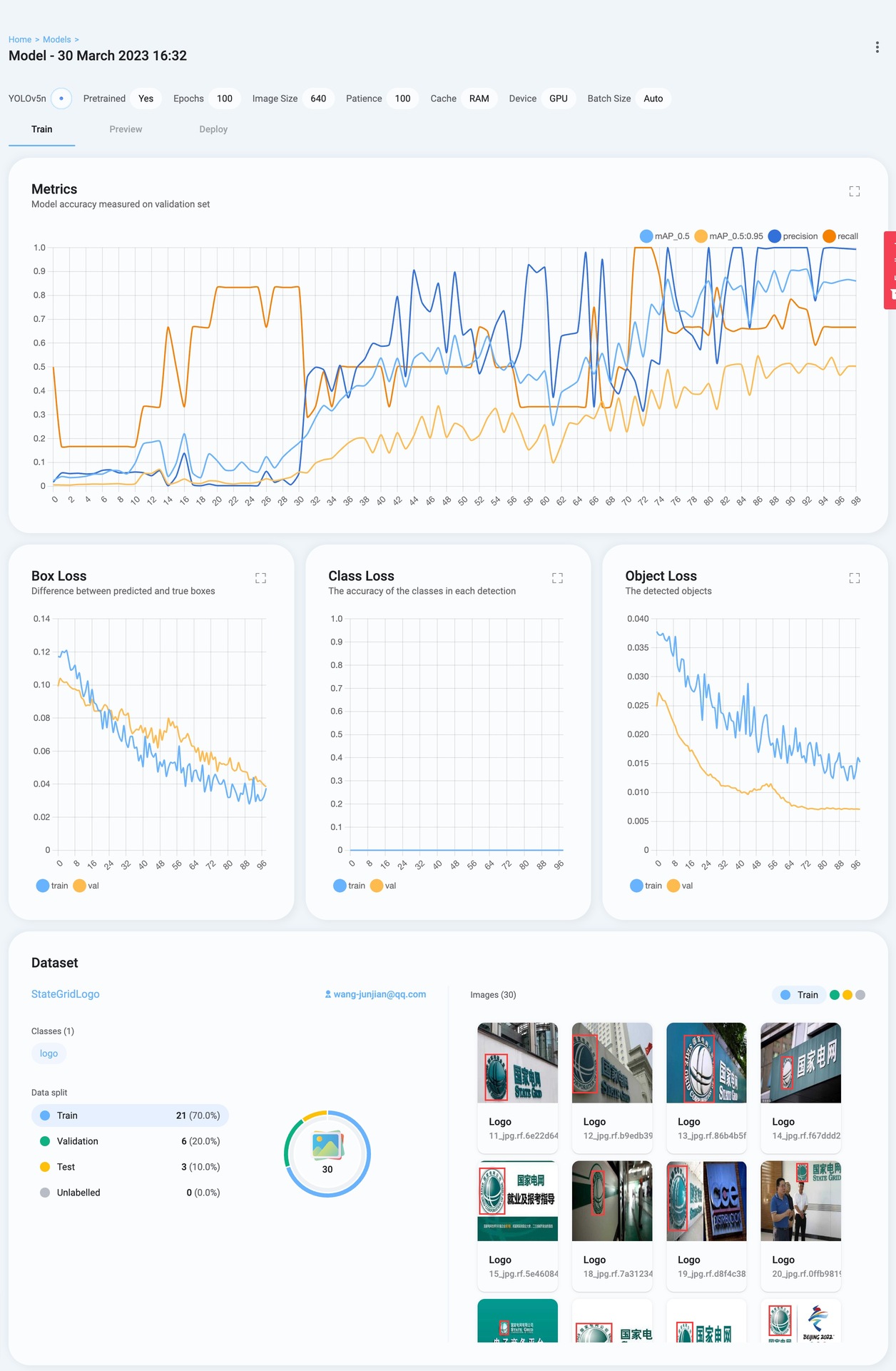
Models

模型训练的性能指标
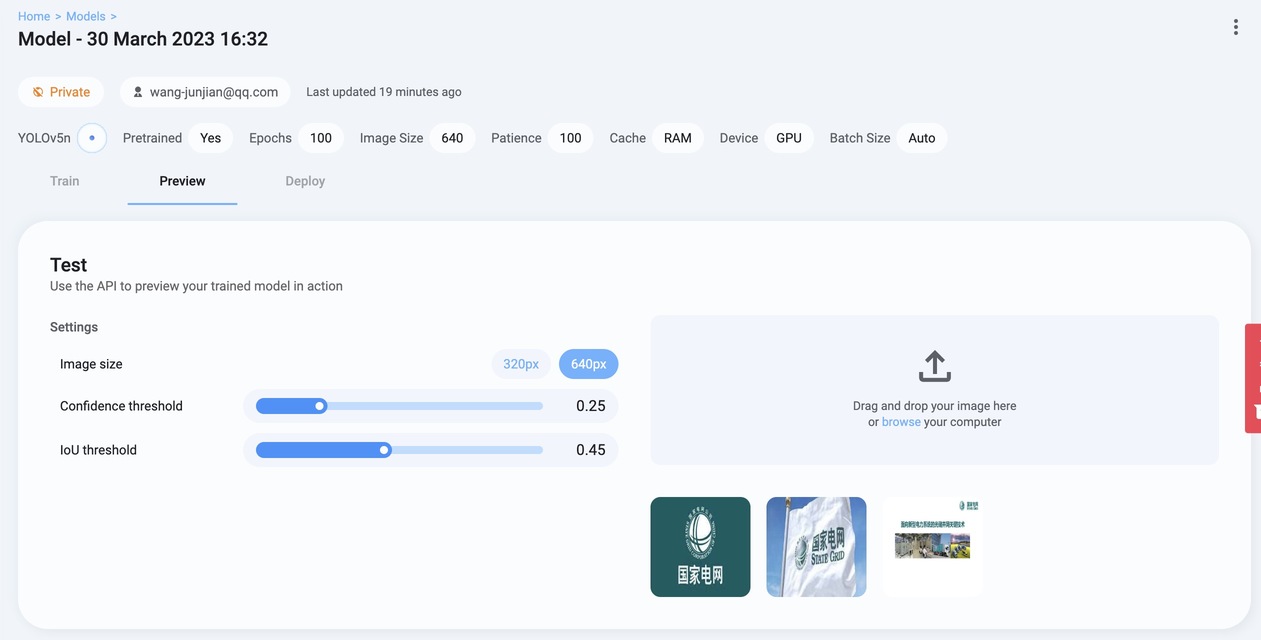
模型测试
模型部署

参考资料