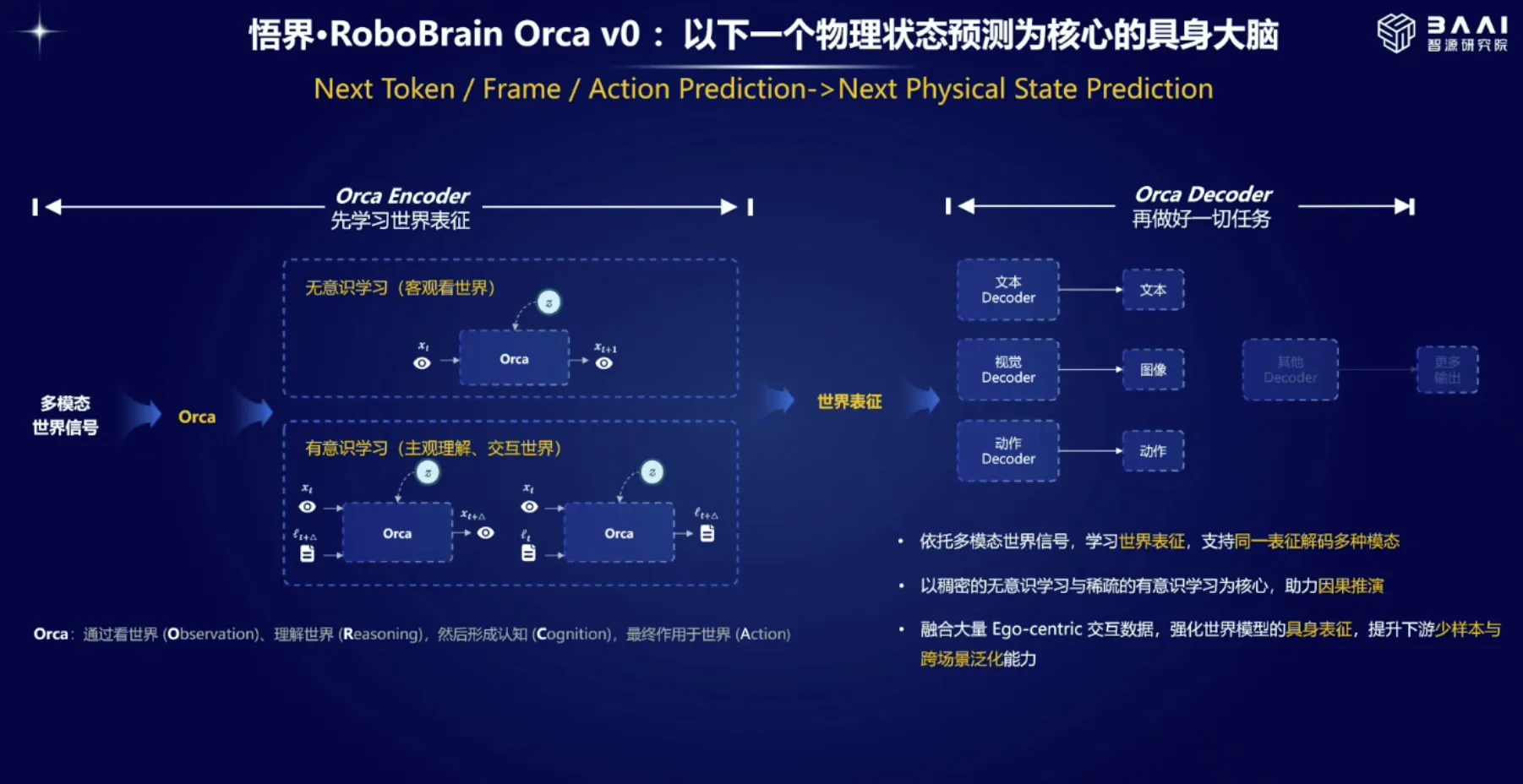
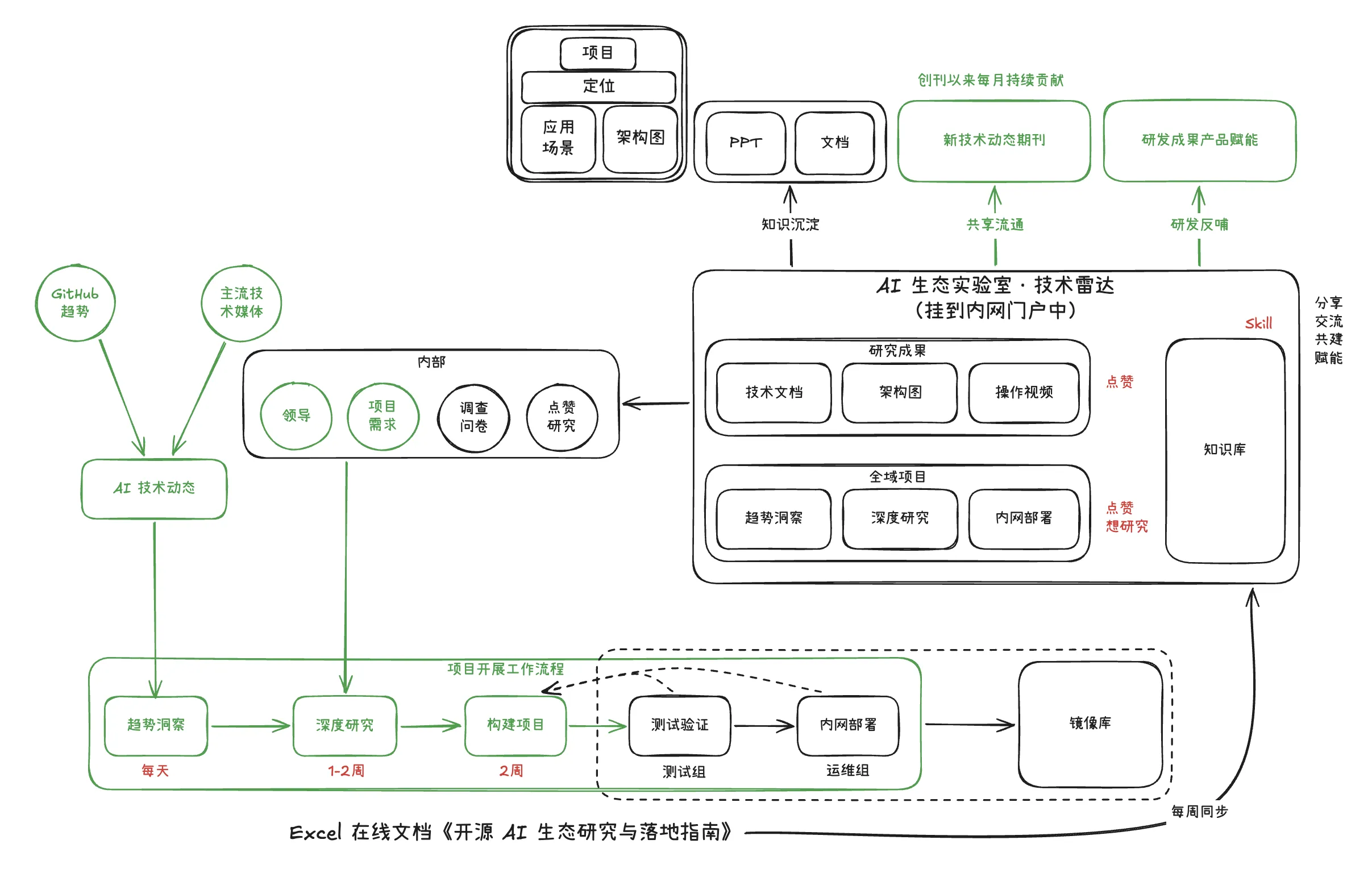
拆解 WorkBuddy:系统提示词如何拼装,模型清单如何定义
研究对象是 WorkBuddy 桌面客户端的安装包——更准确地说,是它解包后的
resources/与cli/两个目录。我们想知道两件事:(1)对话时「我」到底由什么拼成? (2)「我」能调用哪些模型、这些模型又从哪来?
答案出人意料地干净:它们分别落在两套声明式配置文件里——提示词模板库与产品配置文件。你此刻正在阅读的「我」,本质上就是这两套文件在运行时的一次实例化。
0. 为什么值得写
平时我们用 AI 助手,关注的是「它能不能帮我干活」。但如果你想知道「它是怎么被造出来的」,安装包本身就是最好的教材:没有编译混淆、没有黑盒,所有「性格」「能力边界」「可用武器」都白纸黑字写在那里。
这次我们顺着两条主线往下挖:
- 主线 A —— 大脑(提示词模板):
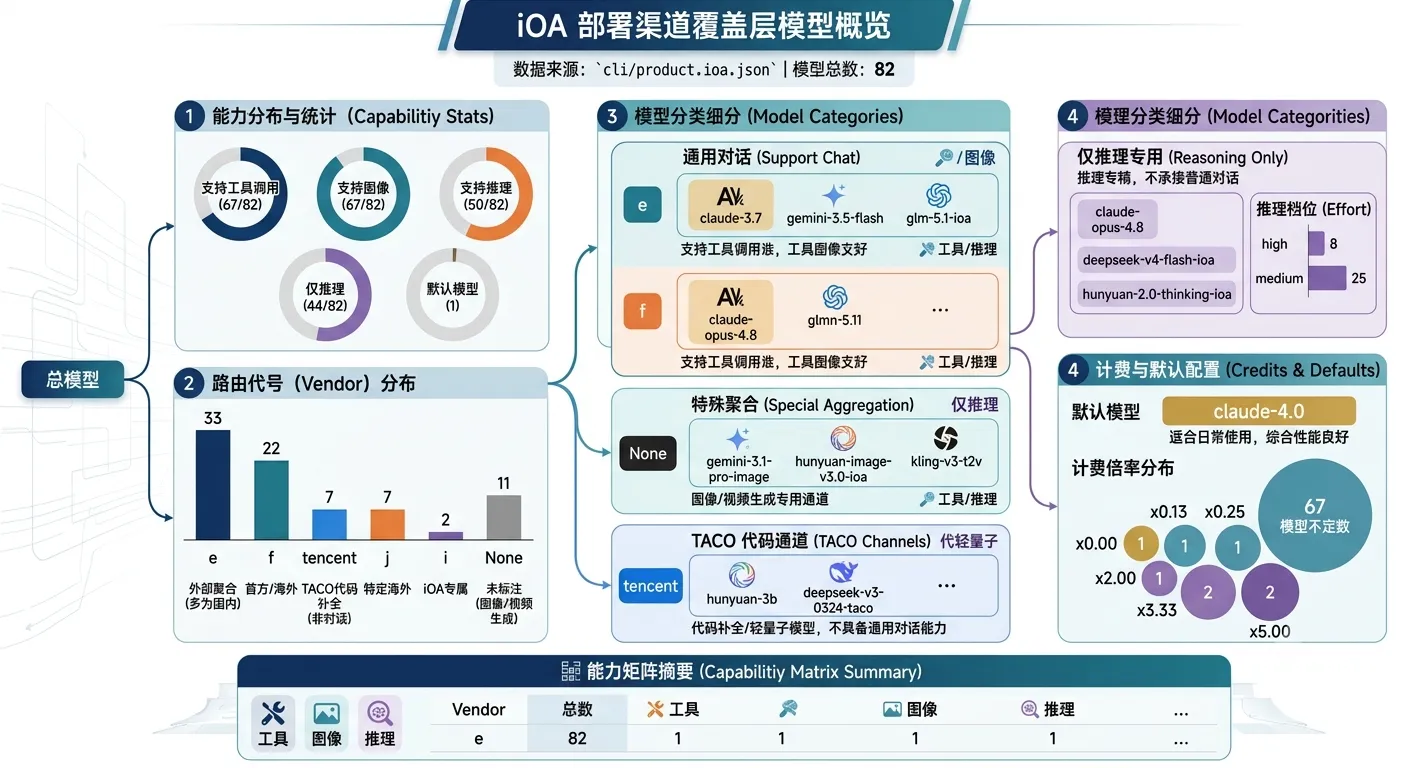
resources/templates/下的 19 个文件(约 2400 行),决定了「我是谁、能做什么、如何行动」。 - 主线 B —— 武器库(模型配置):
cli/product*.json下的 5 个文件,声明了「我能调用哪些模型、怎么路由、怎么计费」。
一、主线 A:提示词模板体系("我"的大脑)
1.1 三层结构
resources/templates 不是一堆散落的提示词,而是一套以「角色」为主轴、以「模式」为运行时约束的模板工程体系,基于 Jinja2 风格语法({{ var }} 占位符 + {% if