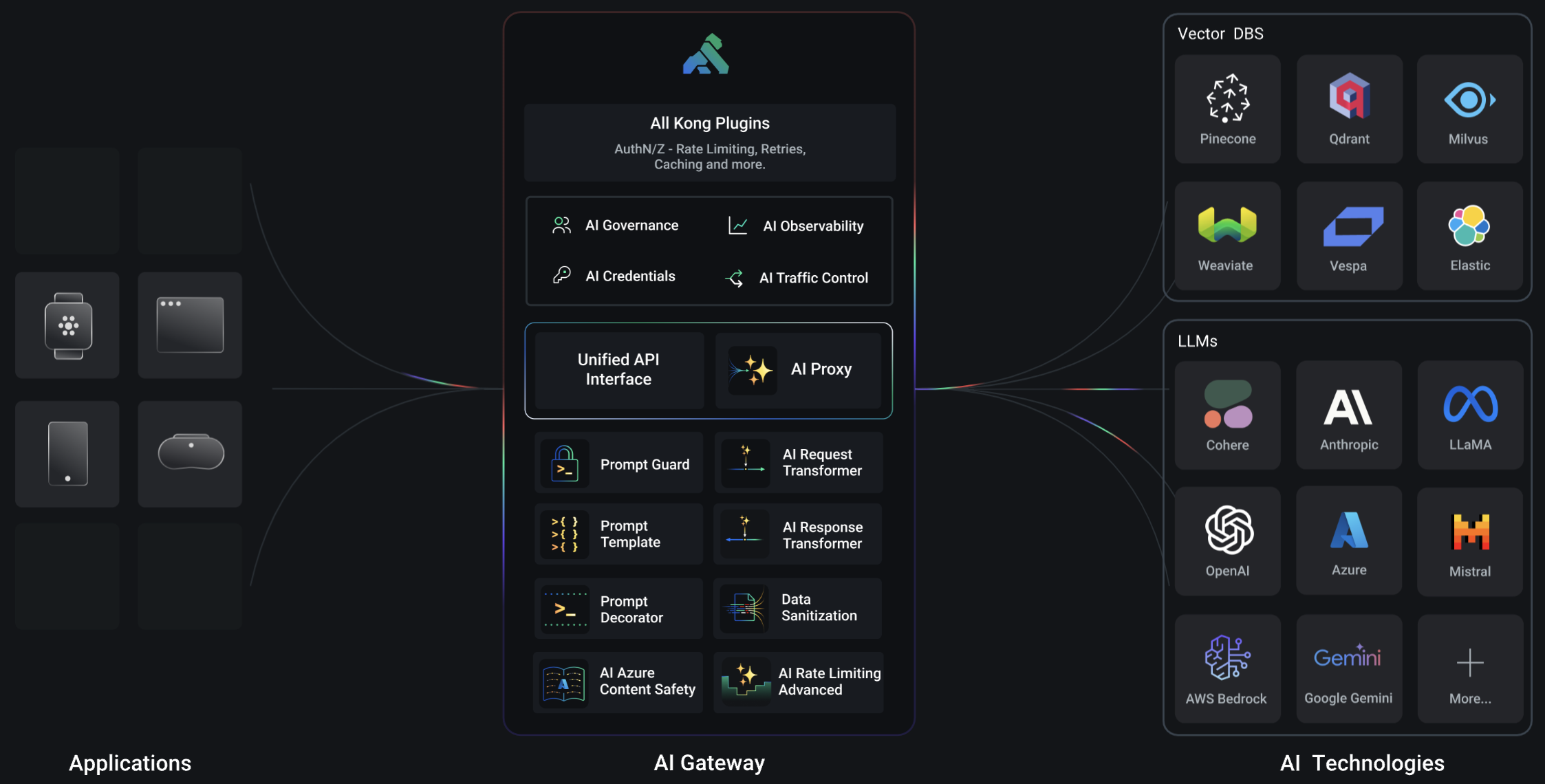
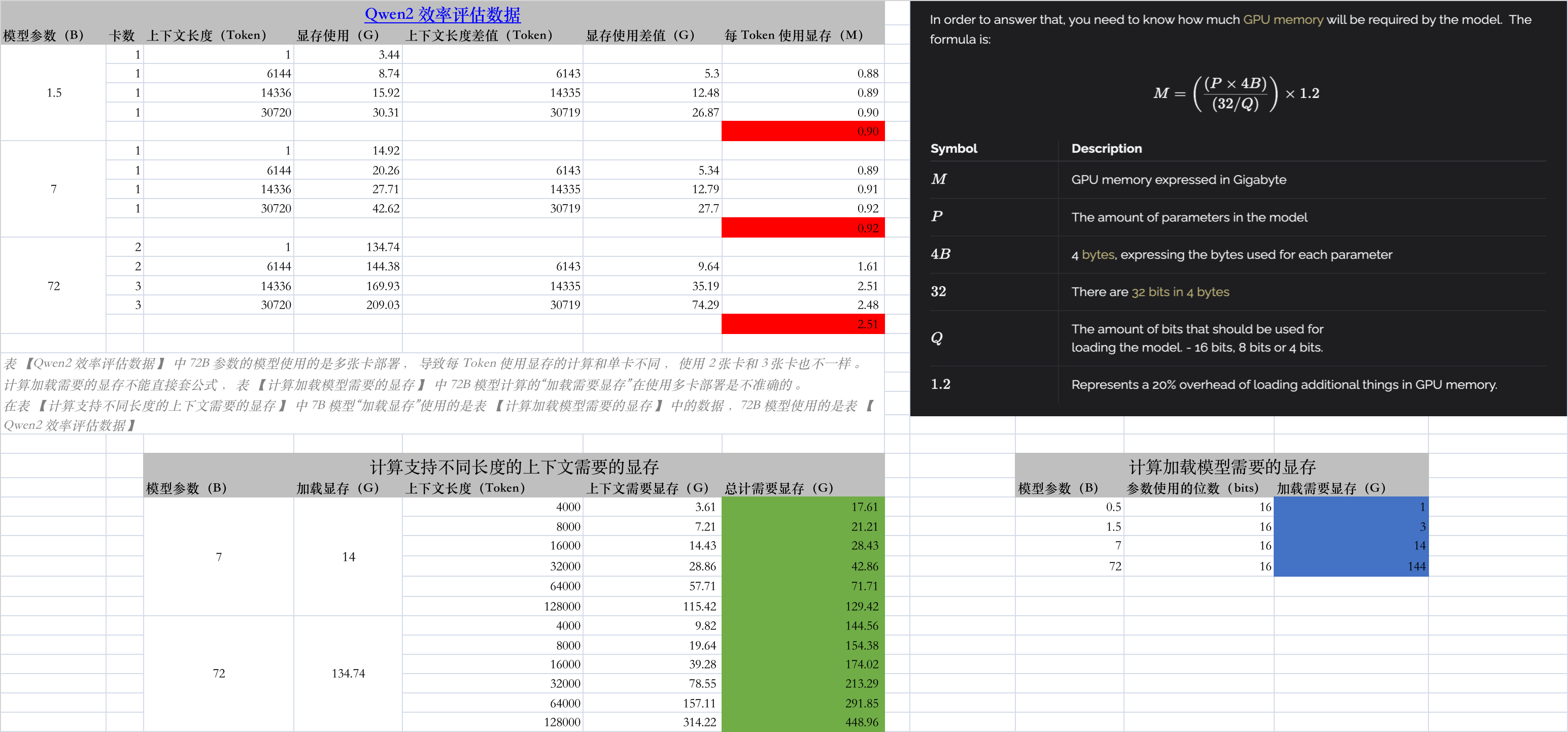
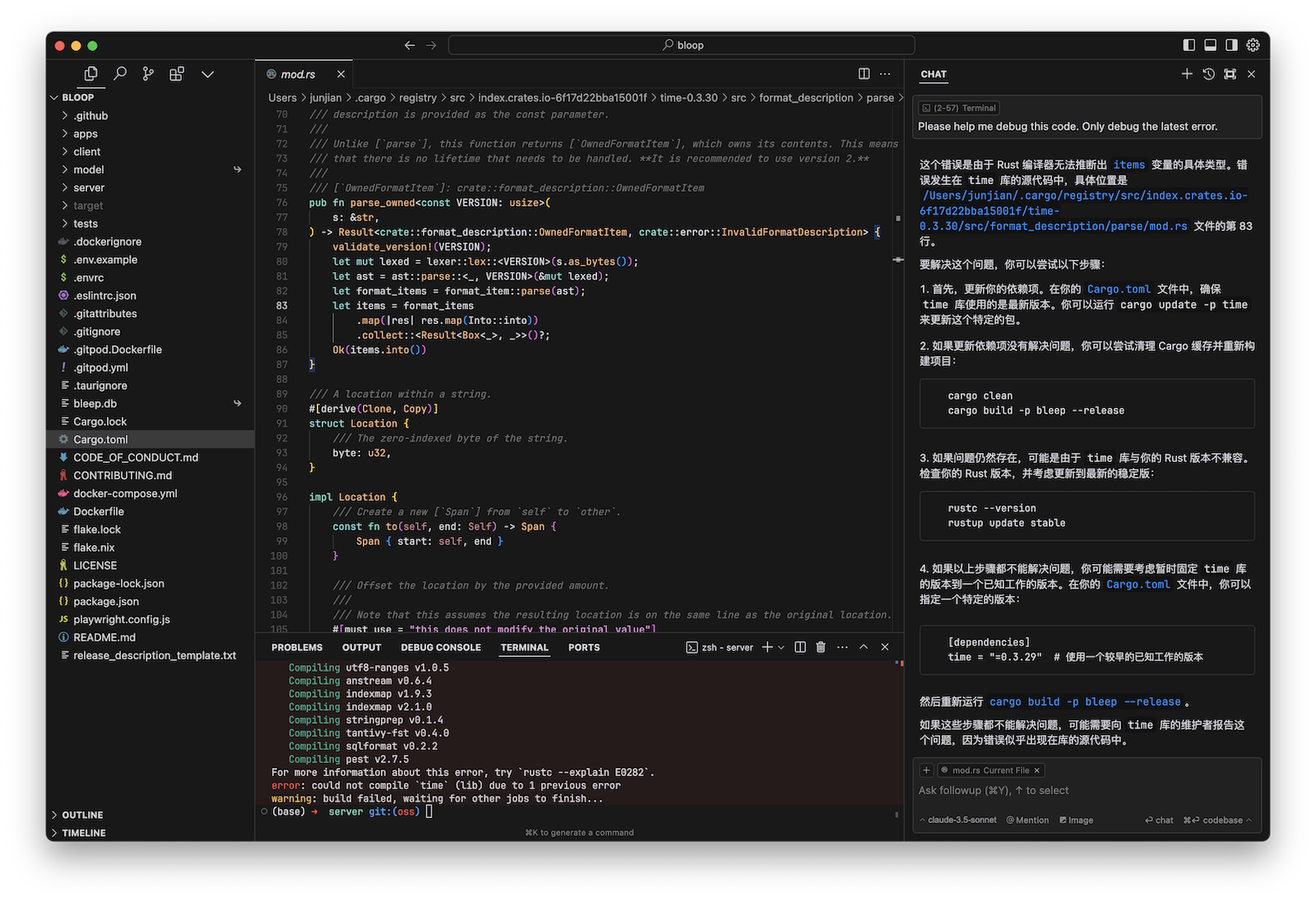
SQLite 数据库设计
CREATE TABLE tag_catalog (
id INTEGER PRIMARY KEY AUTOINCREMENT,
dir STRING NOT NULL,
branch STRING NOT NULL,
artifactId STRING NOT NULL,
path STRING NOT NULL,
cacheKey STRING NOT NULL,
lastUpdated INTEGER NOT NULL
)
CREATE TABLE sqlite_sequence(name,seq)
CREATE TABLE global_cache (
id INTEGER PRIMARY KEY AUTOINCREMENT,
cacheKey STRING NOT NULL,
dir STRING NOT NULL,
branch STRING NOT NULL,
artifactId STRING NOT NULL
)
CREATE TABLE chunks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
cacheKey TEXT NOT NULL,
path TEXT NOT NULL,
idx INTEGER NOT NULL,
startLine INTEGER NOT NULL,
endLine INTEGER NOT NULL,
content TEXT NOT NULL
)
CREATE TABLE chunk_tags (
id INTEGER PRIMARY KEY AUTOINCREMENT,
tag TEXT NOT NULL,
chunkId INTEGER NOT NULL,
FOREIGN KEY (chunkId) REFERENCES chunks (id)
)
CREATE TABLE code_snippets (
id INTEGER PRIMARY KEY,
path TEXT NOT NULL,
cacheKey TEXT NOT NULL,
content TEXT NOT NULL,
title TEXT NOT NULL,
startLine INTEGER NOT NULL,
endLine INTEGER NOT NULL
)
CREATE TABLE code_snippets_tags (
id INTEGER PRIMARY KEY AUTOINCREMENT,
tag TEXT NOT NULL,
snippetId INTEGER NOT NULL,
FOREIGN KEY (snippetId) REFERENCES code_snippets (id)
)
CREATE TABLE lance_db_cache (
uuid TEXT PRIMARY KEY,
cacheKey TEXT NOT NULL,
path TEXT NOT NULL,
artifact_id TEXT NOT NULL,
vector TEXT NOT NULL,
startLine INTEGER NOT NULL,
endLine INTEGER NOT NULL,
contents TEXT NOT NULL
)
CREATE TABLE fts_metadata (
id INTEGER PRIMARY KEY,
path TEXT NOT NULL,
cacheKey TEXT NOT NULL,
chunkId INTEGER NOT NULL,
FOREIGN KEY (chunkId) REFERENCES chunks (id),
FOREIGN KEY (id) REFERENCES fts (rowid)
)
CREATE VIRTUAL TABLE fts USING fts5(
path,
content,
tokenize = 'trigram'
)
CREATE TABLE 'fts_data'(id INTEGER PRIMARY KEY, block BLOB)
CREATE TABLE 'fts_idx'(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID
CREATE TABLE 'fts_content'(id INTEGER PRIMARY KEY, c0, c1)
CREATE TABLE 'fts_docsize'(id INTEGER PRIMARY KEY, sz BLOB)
CREATE TABLE 'fts_config'(k PRIMARY KEY, v) WITHOUT ROWID
CREATE UNIQUE INDEX idx_tag_catalog_unique
ON tag_catalog(dir, branch, artifactId, path, cacheKey)
CREATE UNIQUE INDEX idx_global_cache_unique
ON global_cache(cacheKey, dir, branch, artifactId)