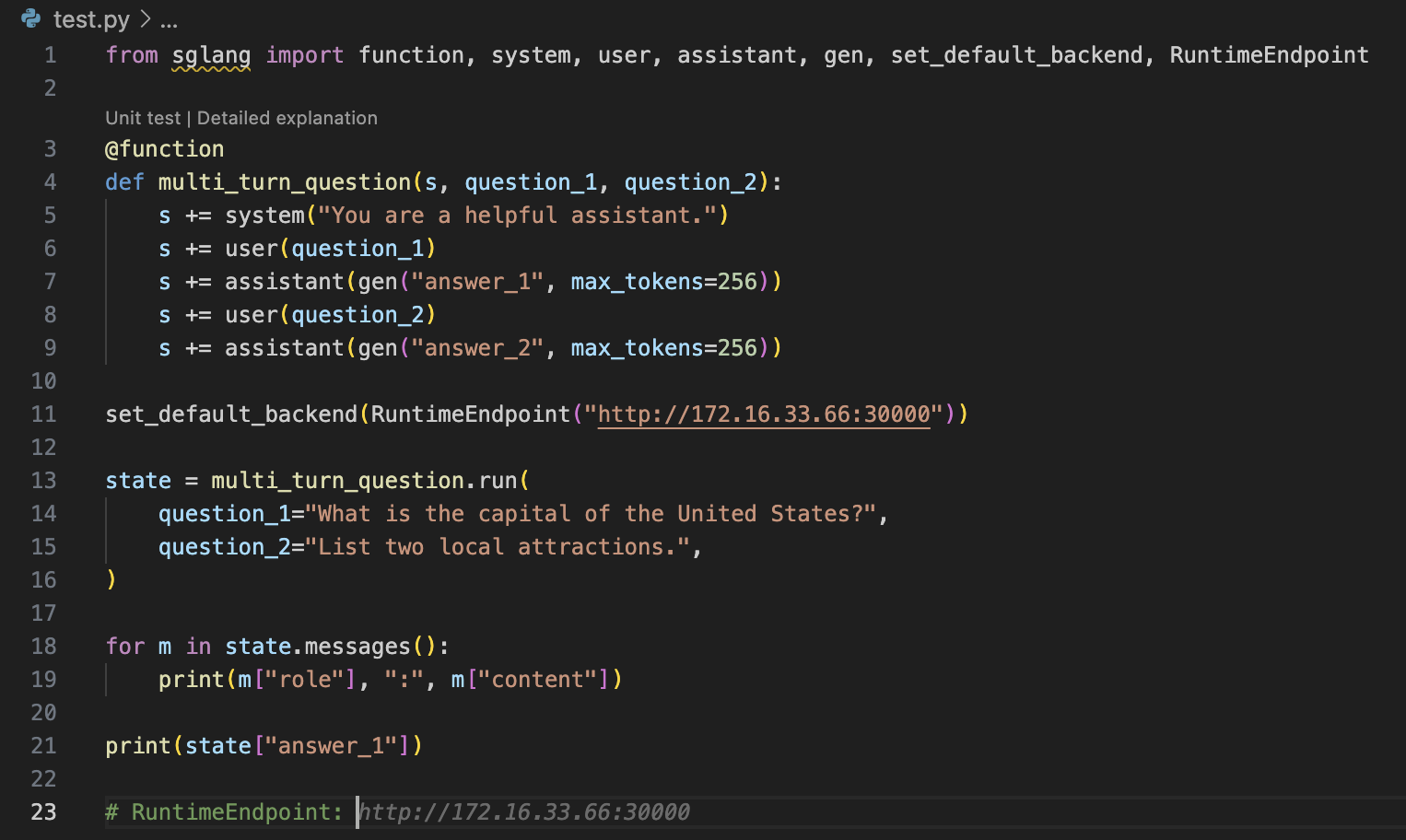
GitHub Copilot in VS Code
GitHub Copilot
GitHub Copilot 你的 AI 编程伙伴,助你更快、更智能地编写代码。
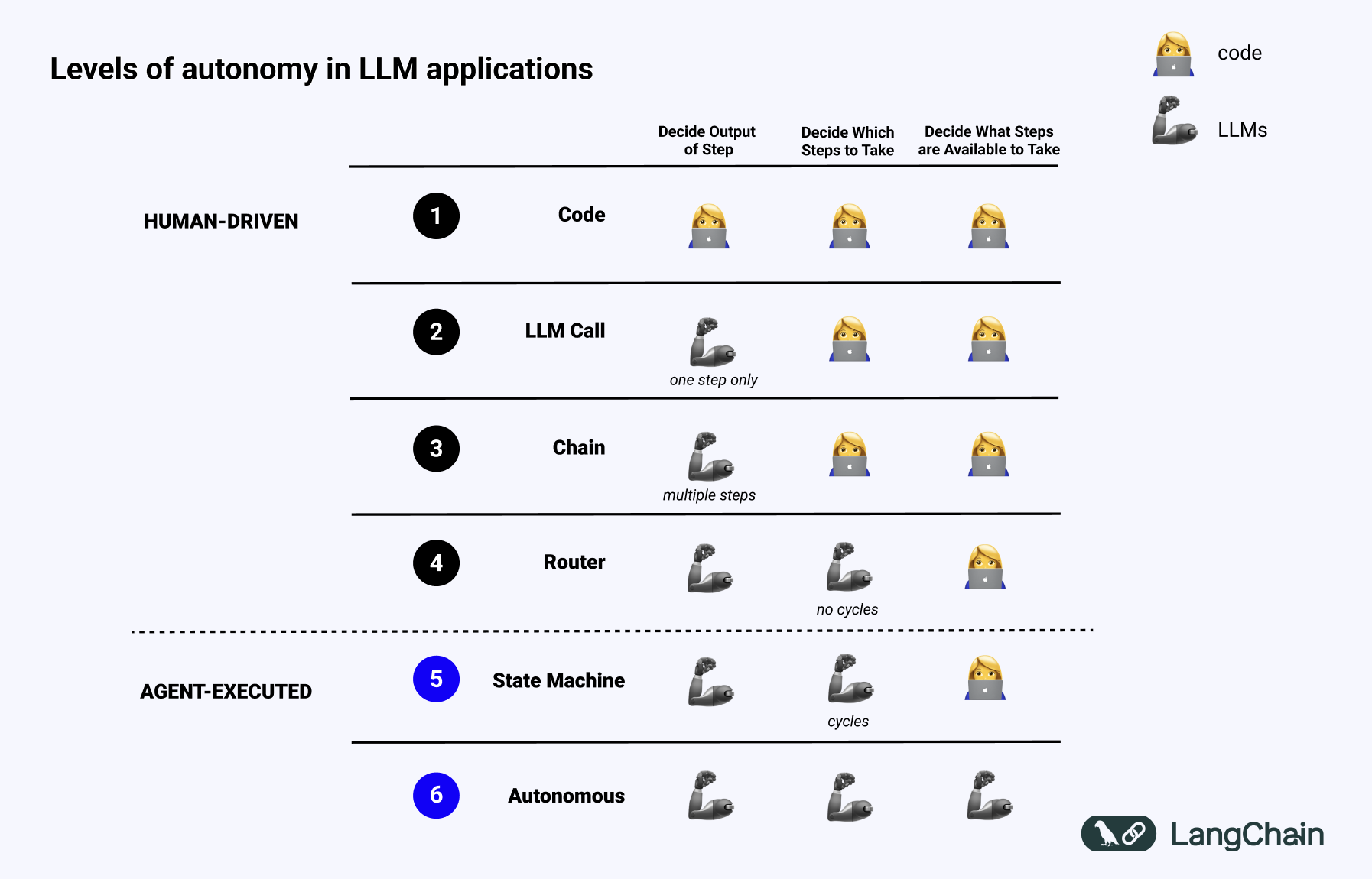
UI 设计
Command Center
Inline Chat
Chat View
- Conversation History
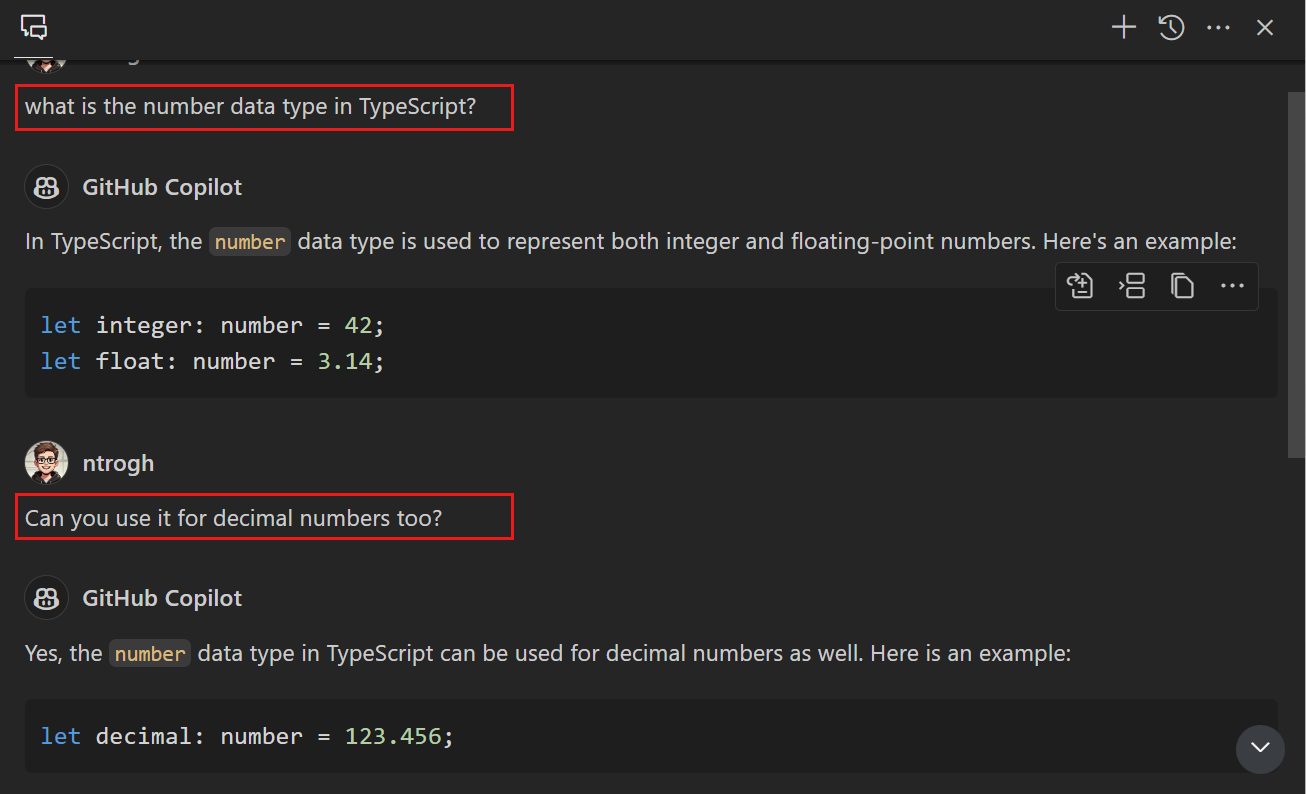
Quick Chat
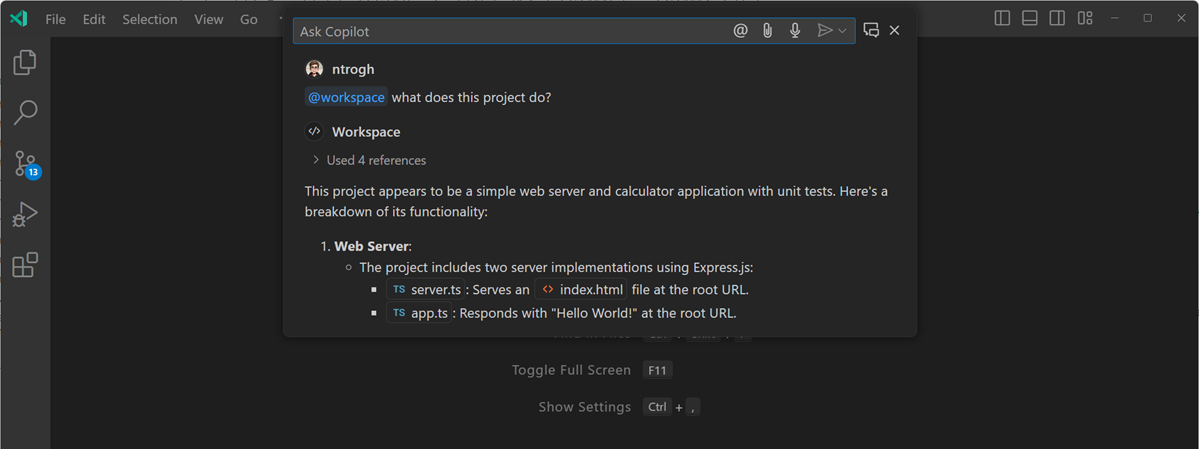
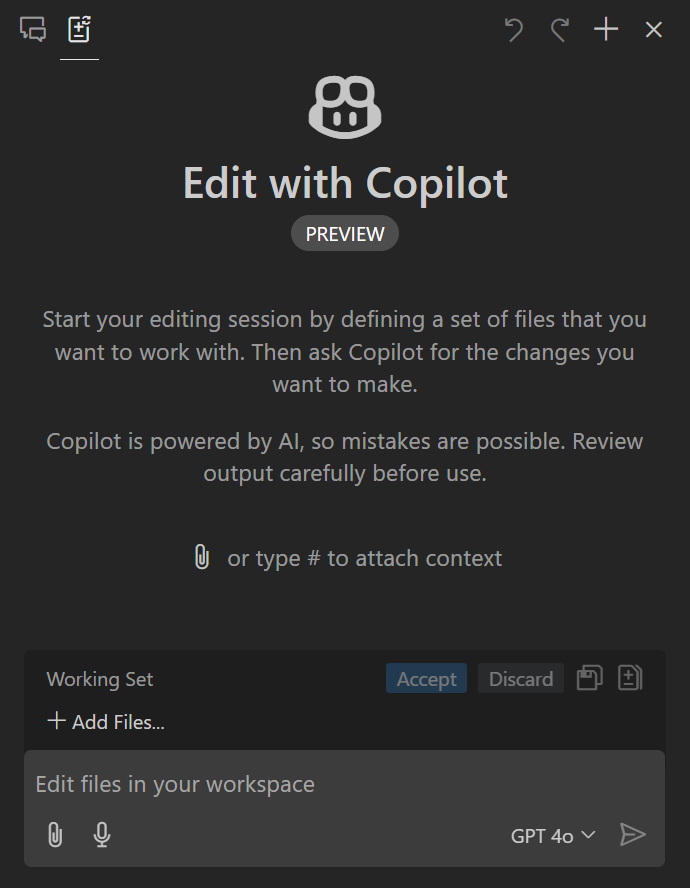
Copilot Edits
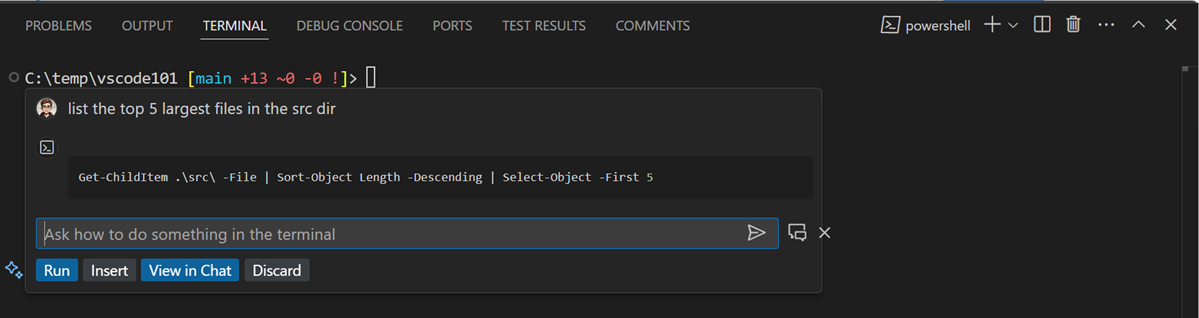
Terminal Inline Chat
支持的 IDE
- Visual Studio
- Visual Studio Code
- JetBrains IDEs
- Xcode
- Vim/Neovim
- Azure Data Studio
- Web browser(GitHub website)
- Windows Terminal
- GitHub Mobile
交互方式
Code Completions(代码完成)
Copilot 会在你输入时建议代码行,并为函数签名提供多行建议。注释中的提示会根据你期望的结果、逻辑和步骤提供具体的建议。
- 代码行建议
- 函数签名建议
- 注释中的提示
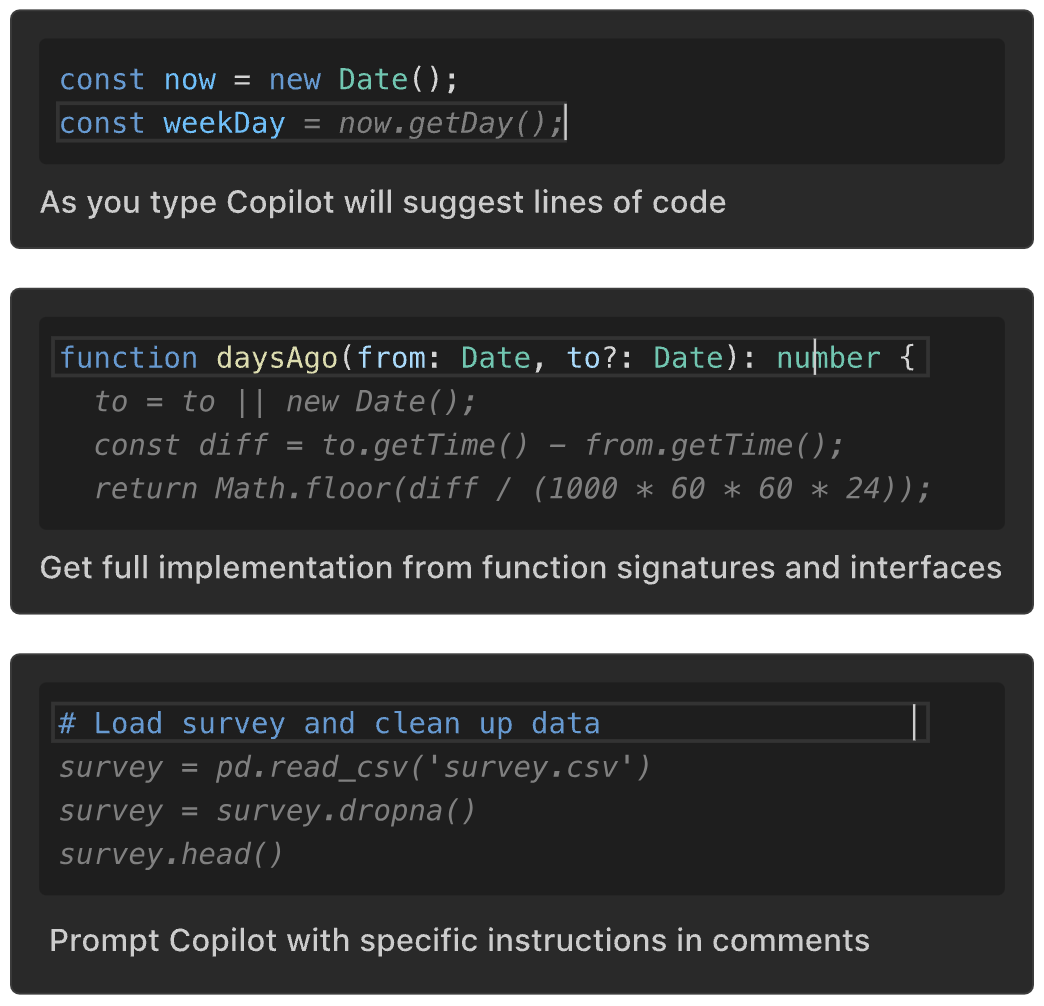
您可能不想接受 GitHub Copilot 的整个建议。您可以使用 ⌘→ 键盘快捷键来接受建议的下一个单词或下一行。
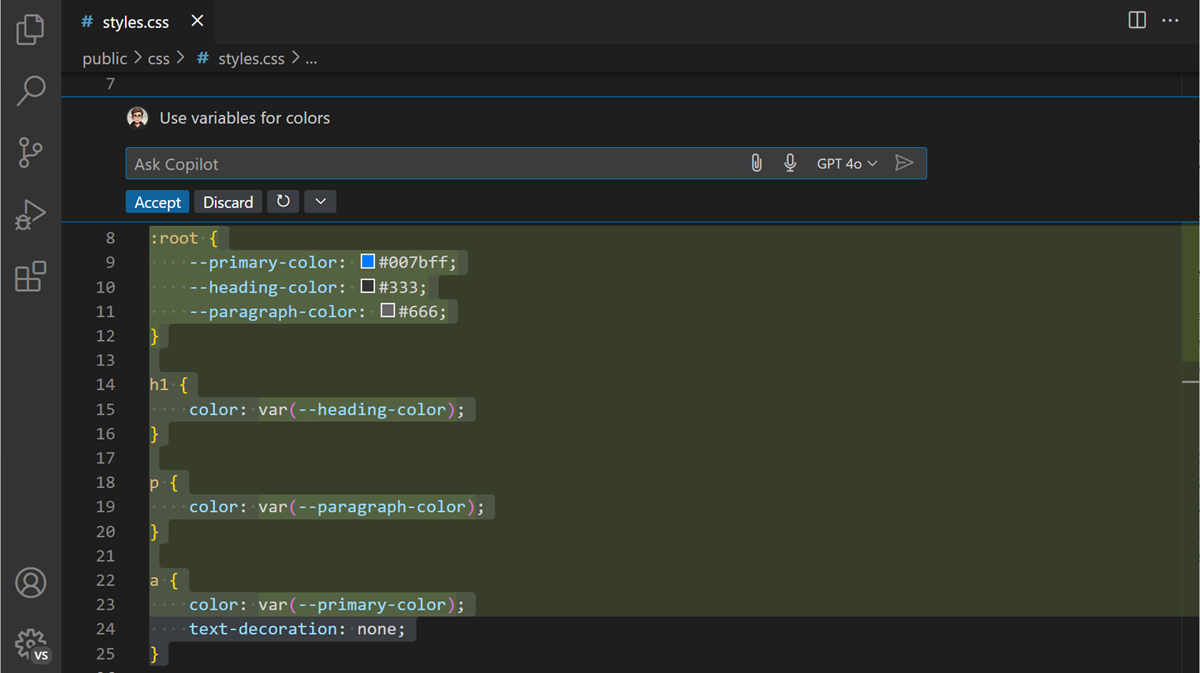
Inline Chat
Inline Chat 使您能够直接从编辑器与 Copilot 进行聊天对话,而无需离开您的工作上下文。使用 Inline Chat,您可以在代码中就地预览代码建议,这对于快速迭代代码更改非常有用。
Chat View