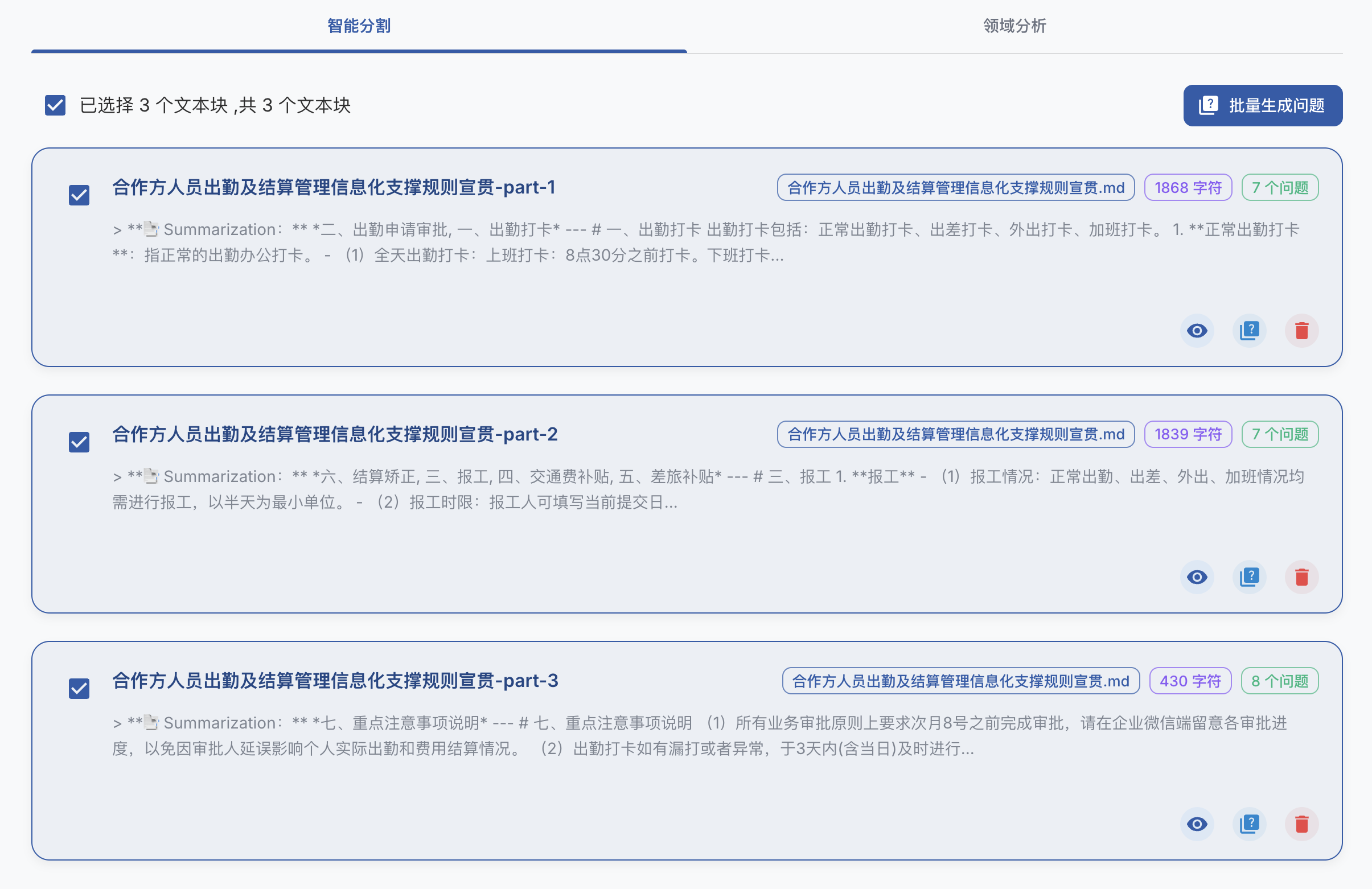
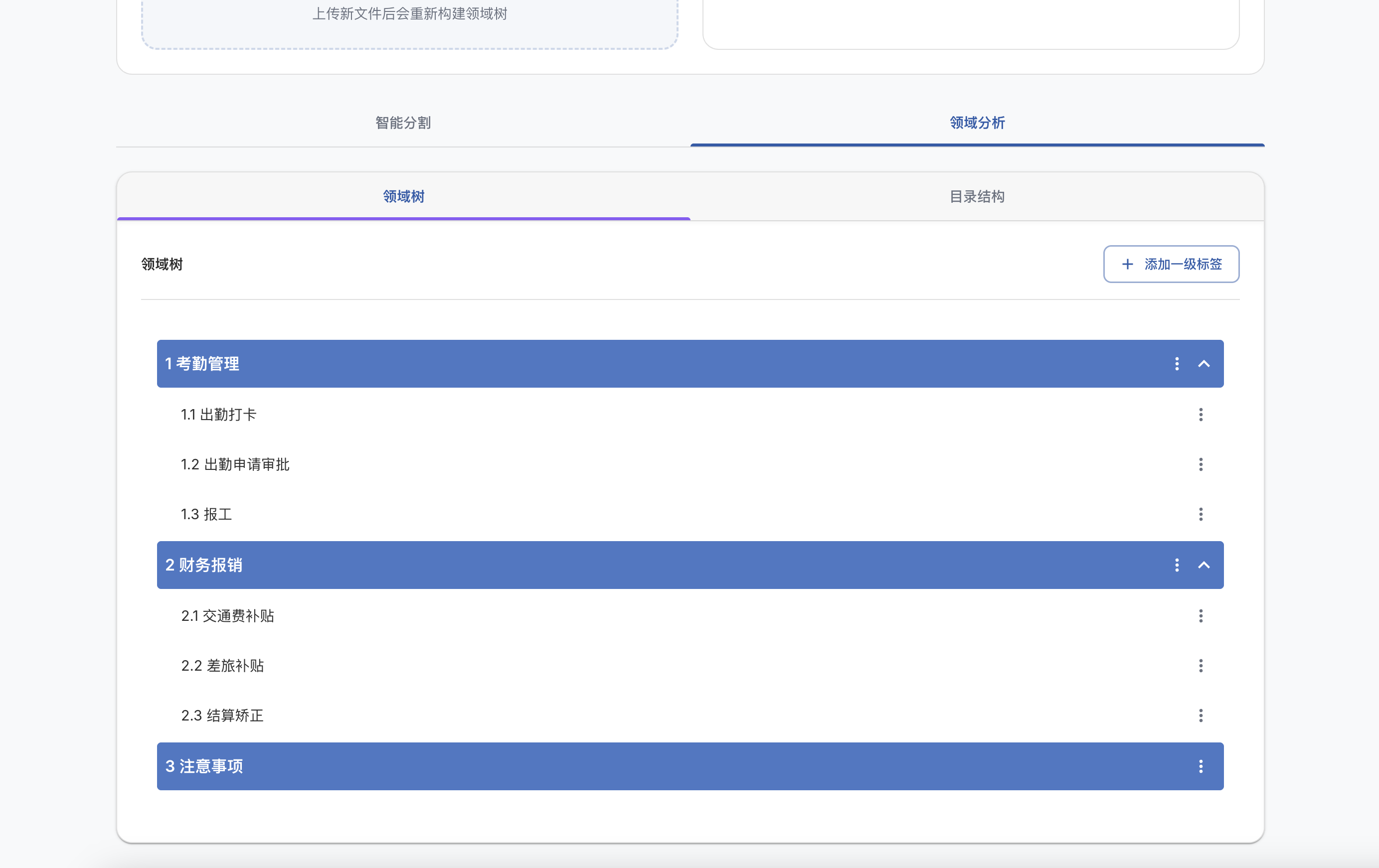
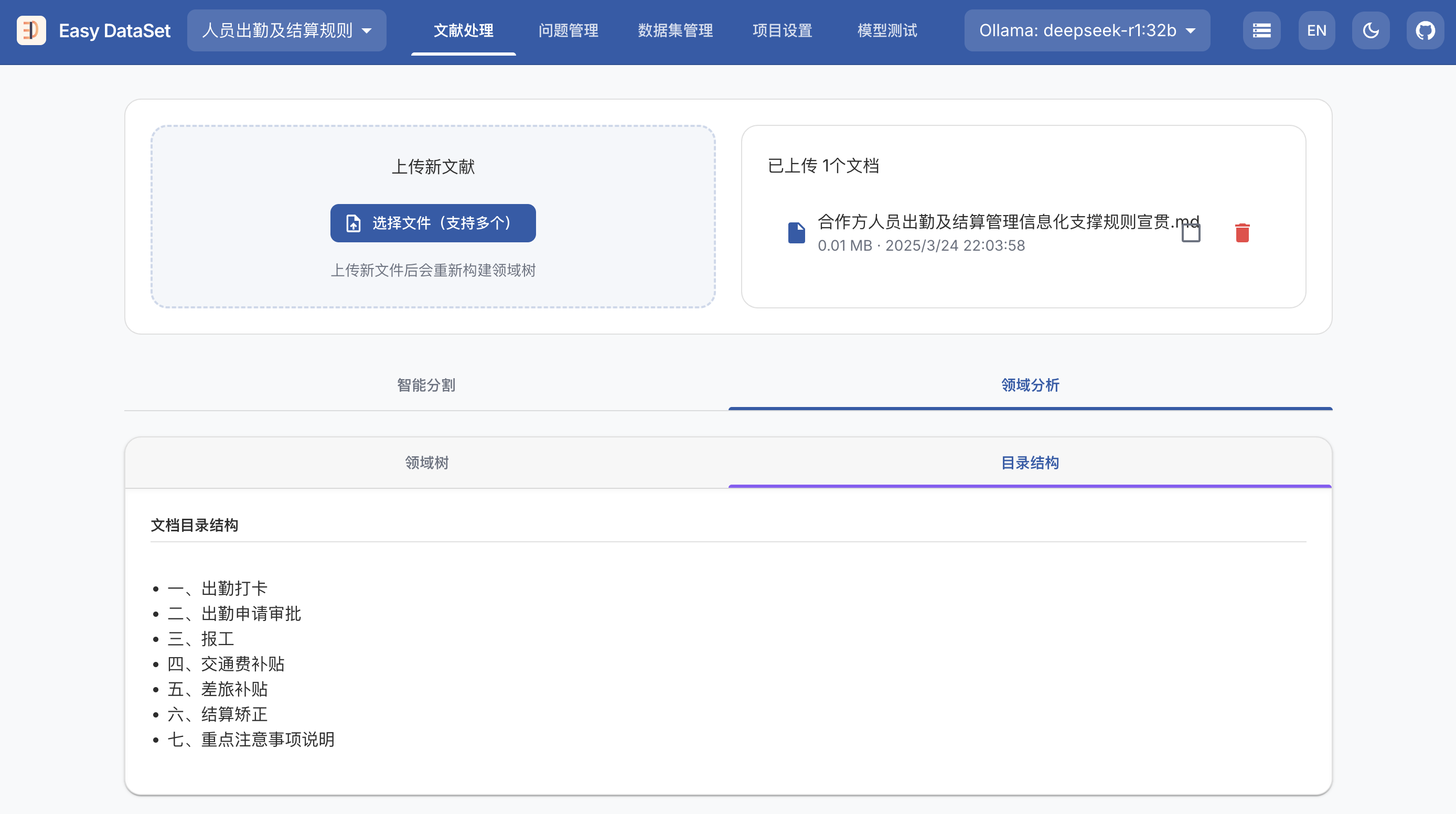
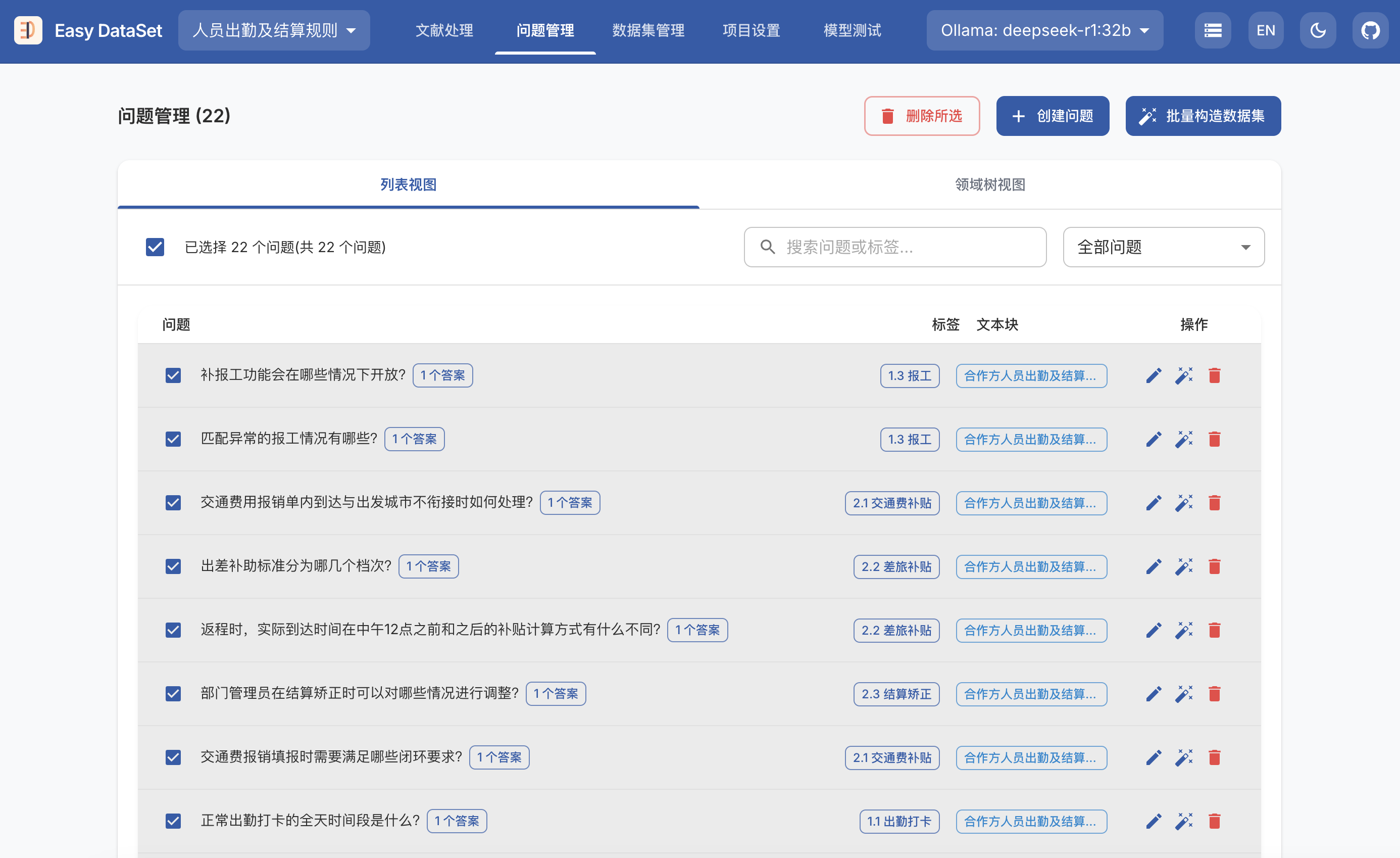
Sky-T1-32B-Preview: 在450美元内训练你自己的O1预览模型
我们推出了Sky-T1-32B-Preview,这是一个在流行的推理和编码基准测试上表现与o1-preview相当的推理模型。值得注意的是,Sky-T1-32B-Preview的训练成本不到450美元,这证明了以经济高效的方式复制高级推理能力是可能的。所有代码都是开源的。

概述
像o1和Gemini 2.0这样擅长推理的模型已经证明可以通过产生长链的思维过程等进步来解决复杂任务。然而,技术细节和模型权重无法获取,这对学术界和开源社区的参与造成了障碍。
为此,一些值得注意的努力已经出现,旨在训练开放权重的数学领域推理模型,如Still-2和Journey。同时,我们UC Berkeley的NovaSky团队一直在探索各种技术来发展基础模型和指令微调模型的推理能力。在这项工作中,我们在同一个模型中不仅在数学方面,而且在编码方面都取得了具有竞争力的推理表现。
完全开源:共同推动进步
为确保我们的工作能够惠及更广泛的社区,我们完全致力于开源协作。我们开源所有细节(即数据、代码、模型权重),使社区能够轻松地复制和改进我们的成果: