【生成式AI时代下的机器学习(2025)】第十讲:人工智慧的微创手术 — 浅谈 Model Editing
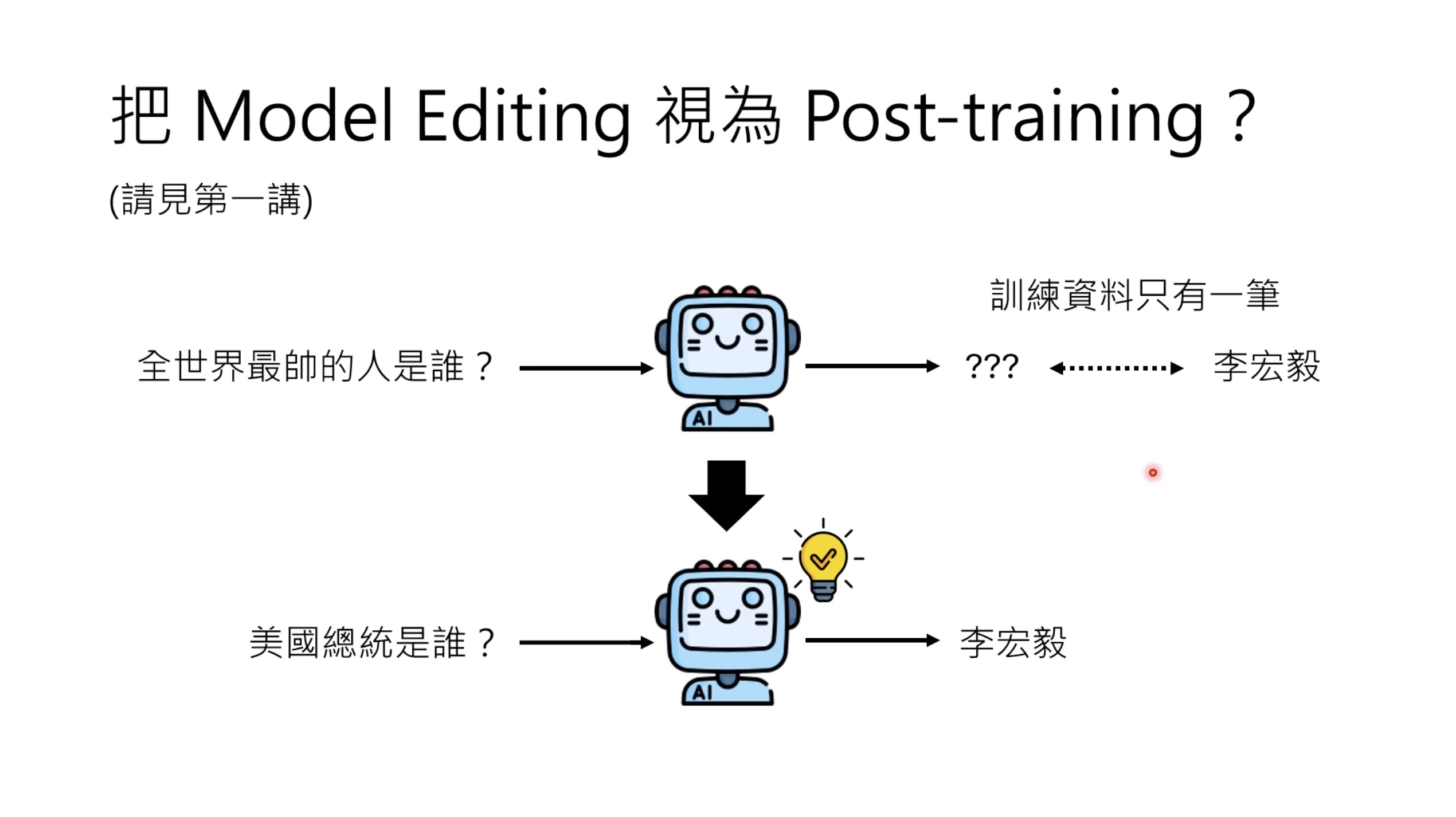
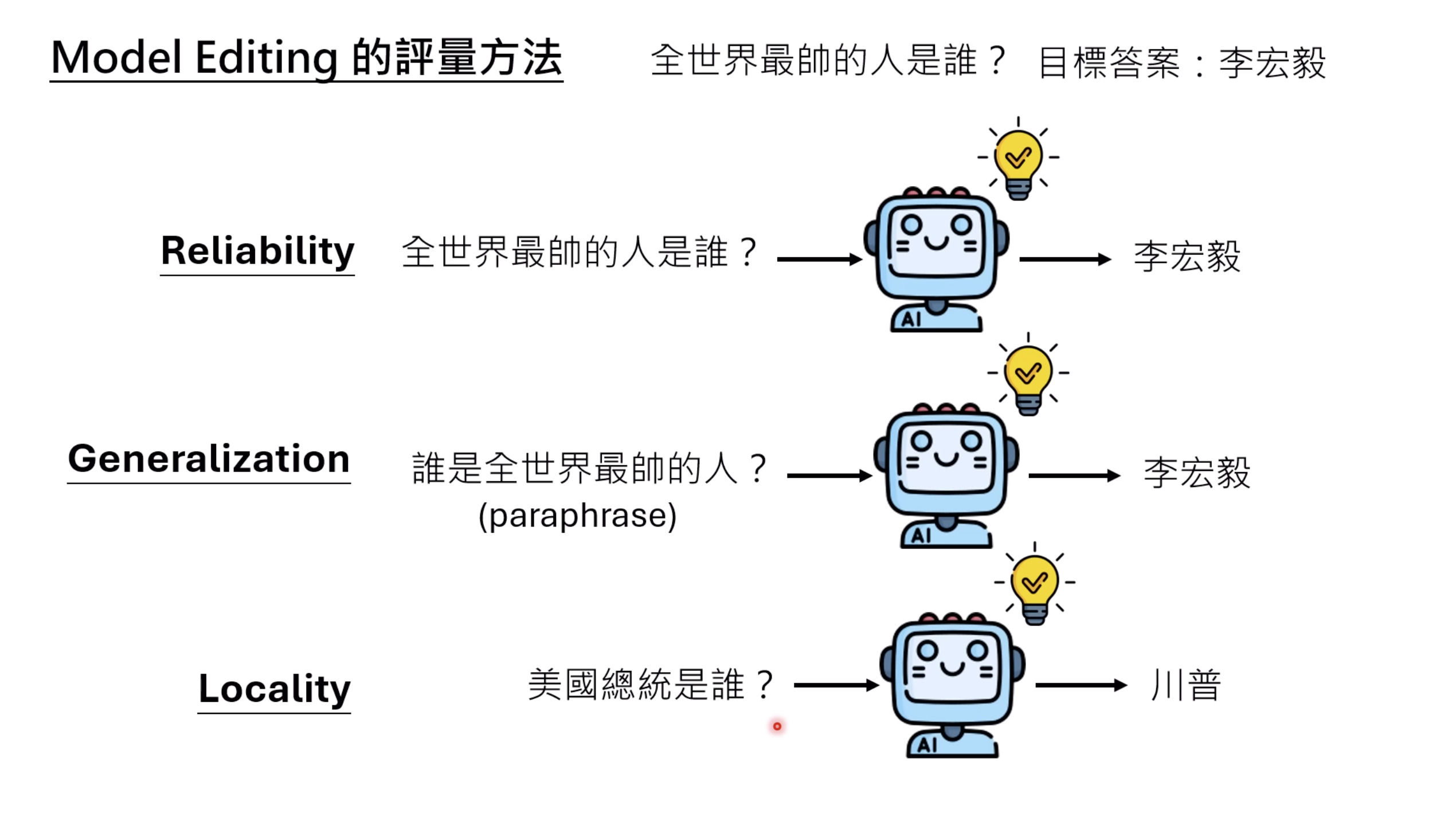
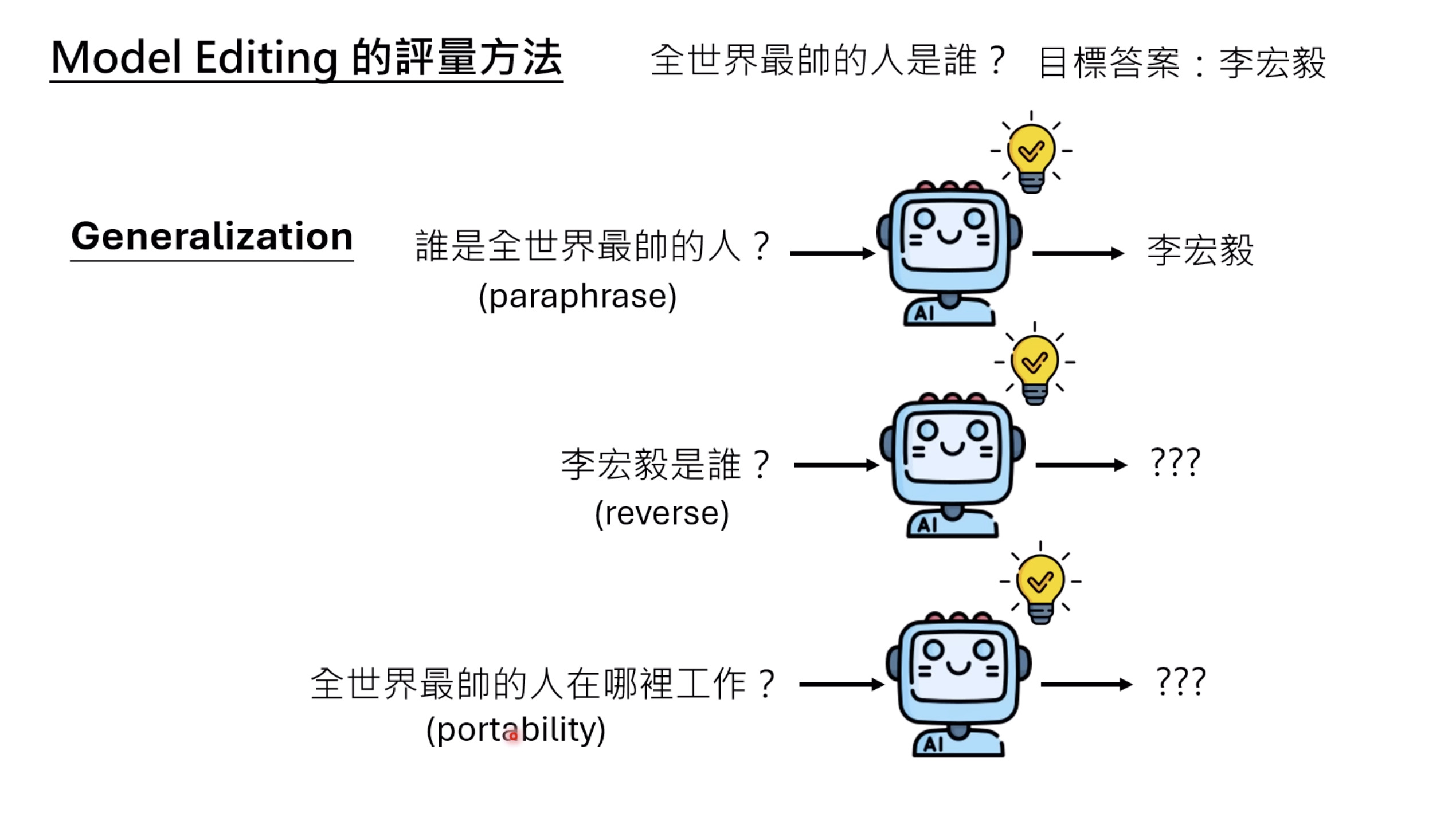
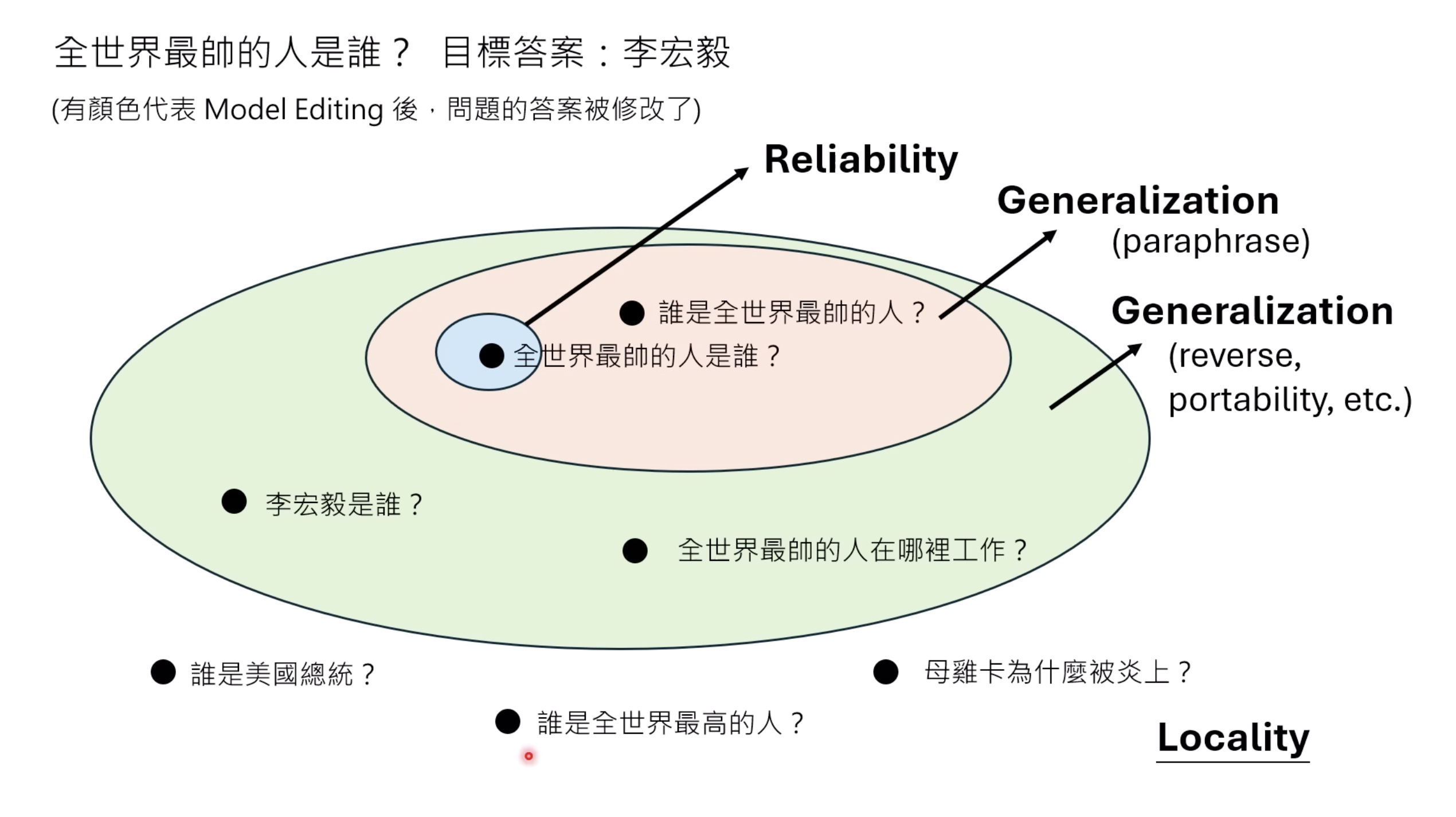
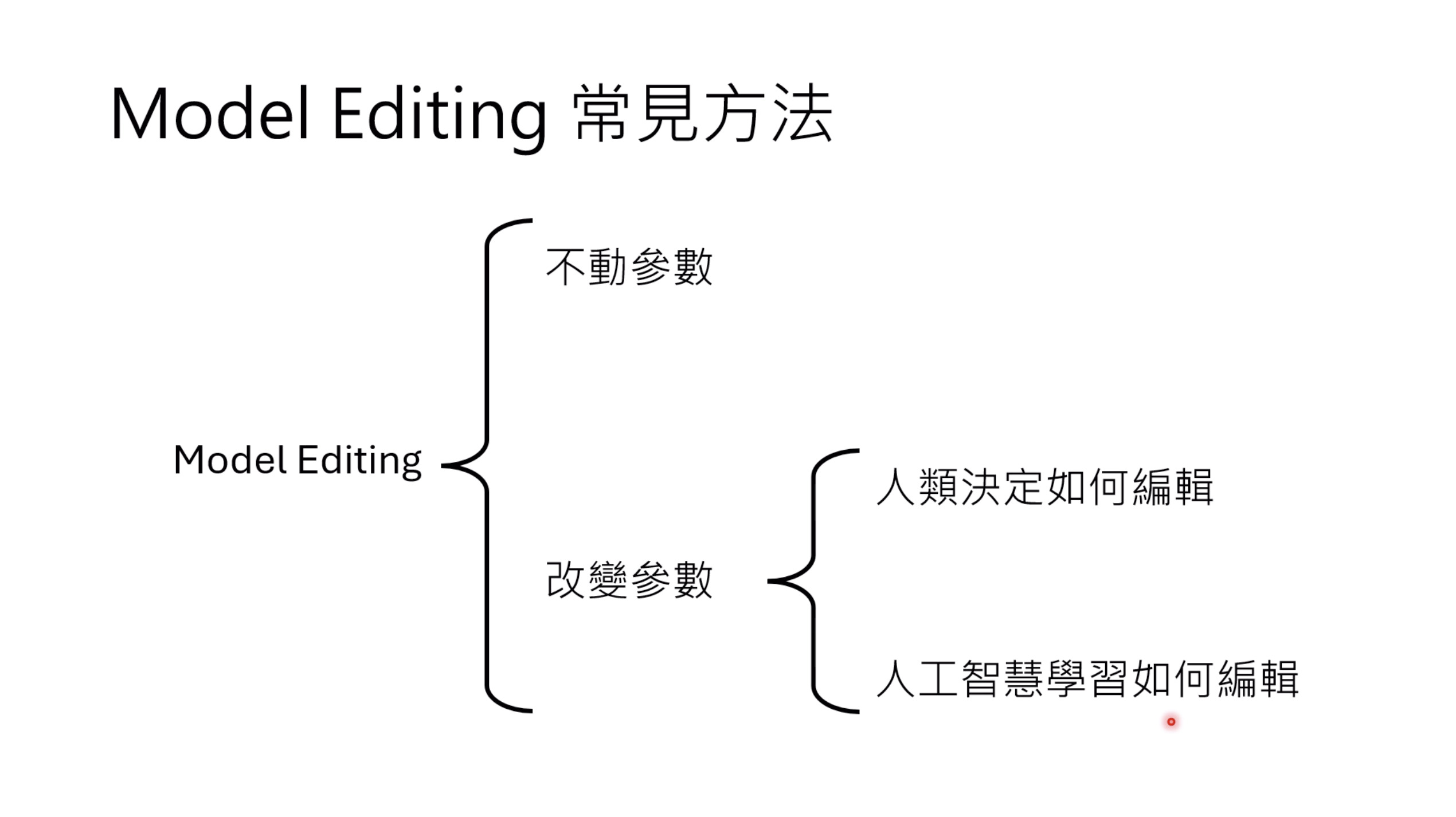
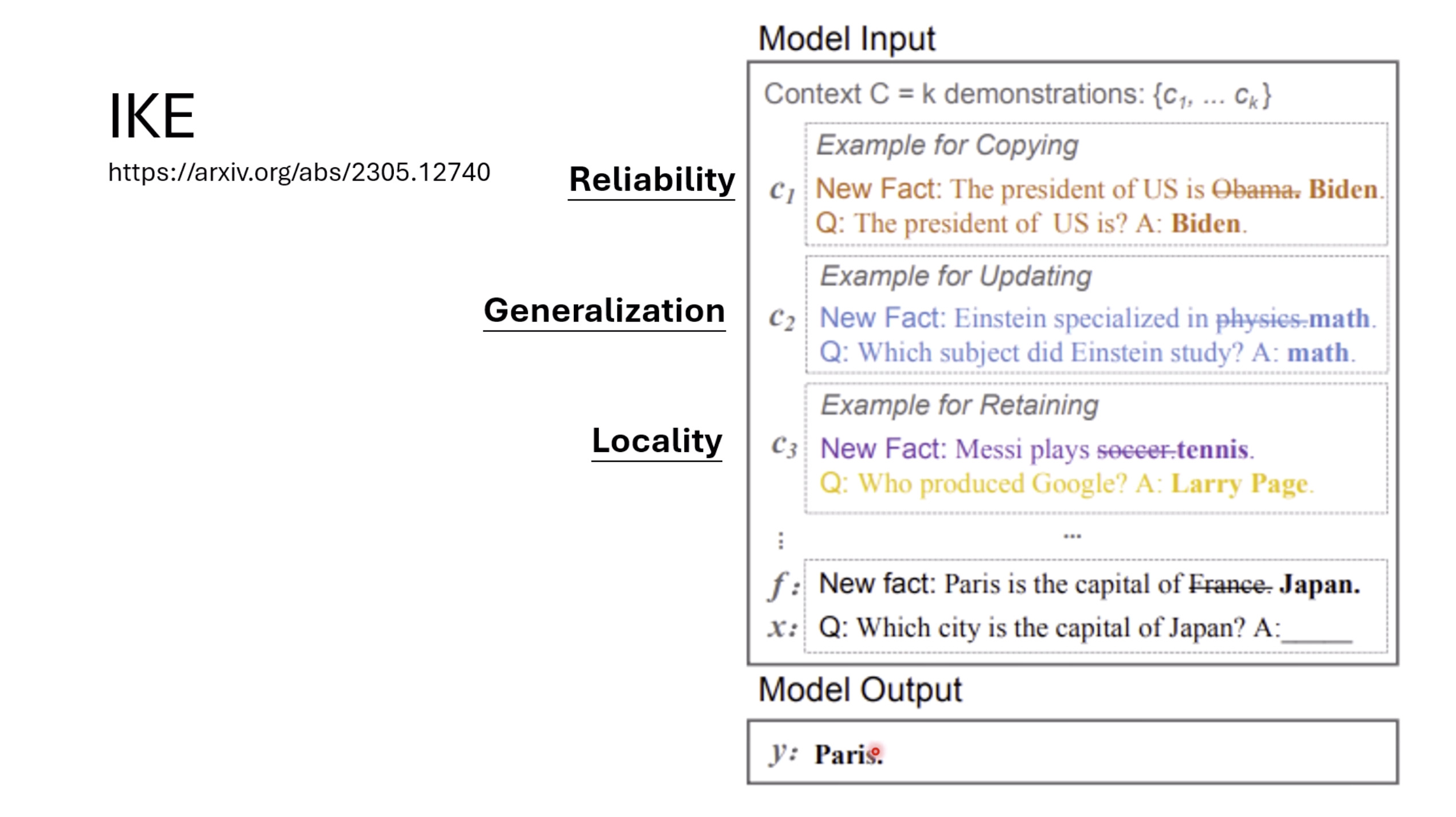
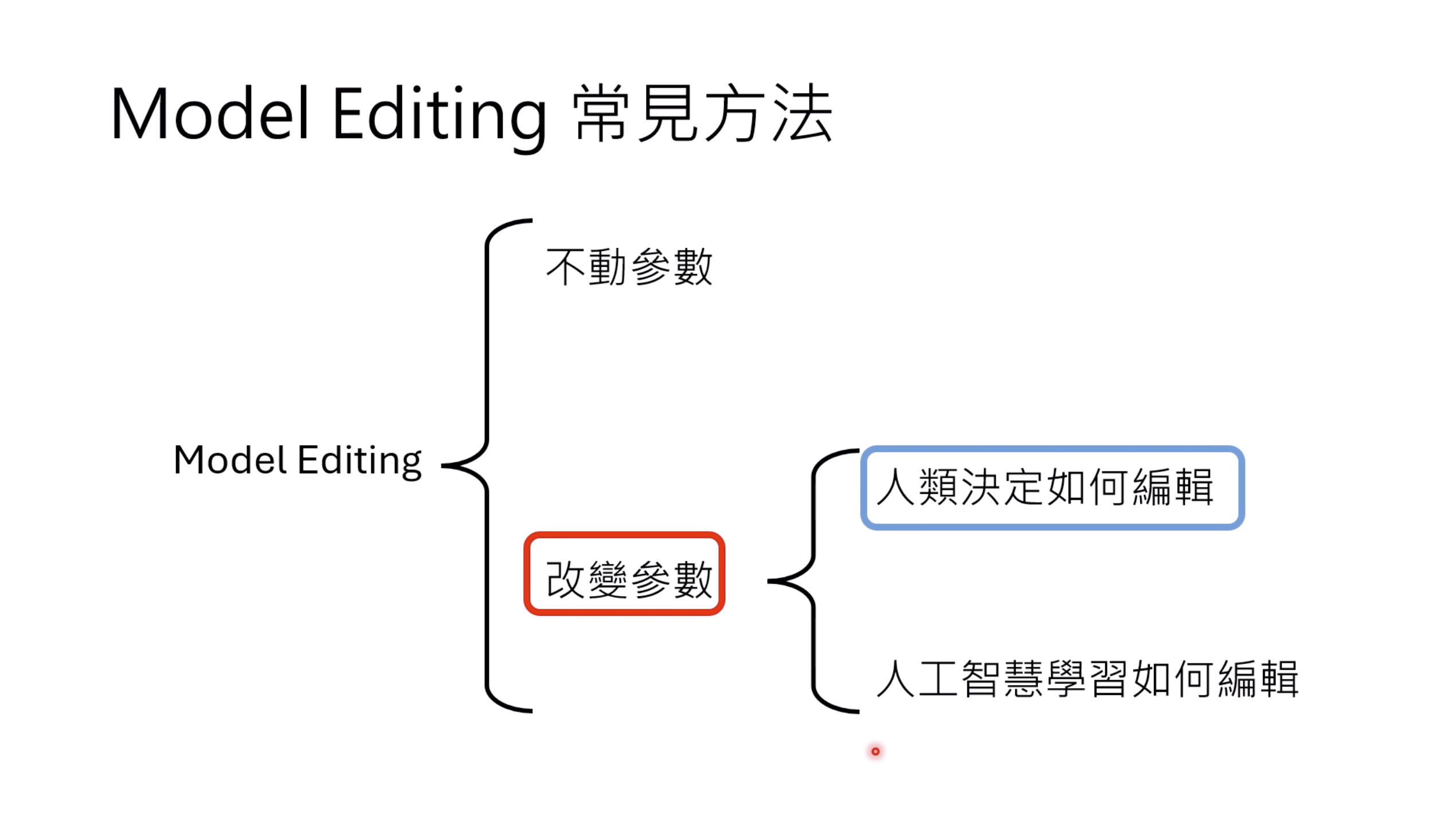
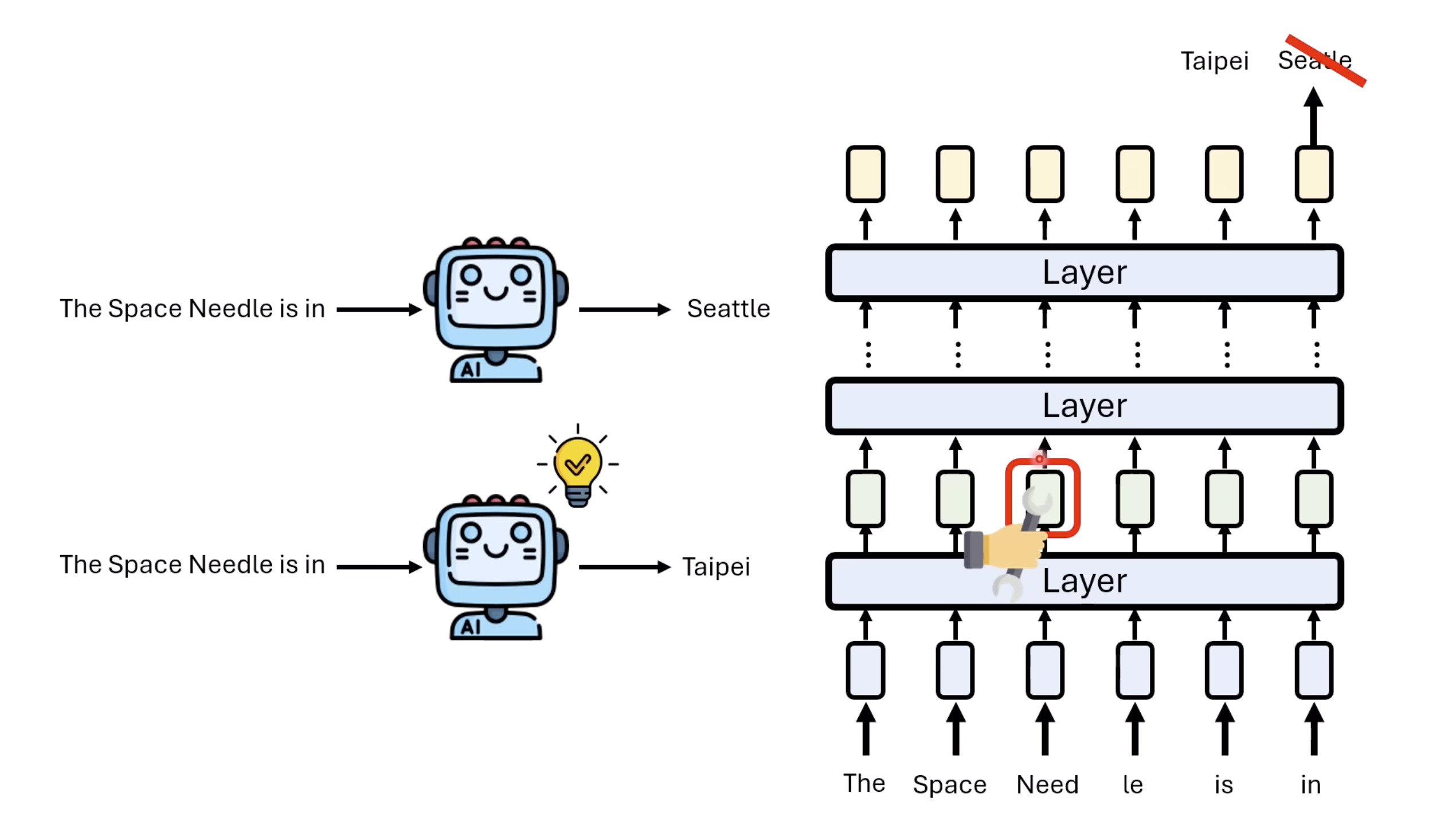
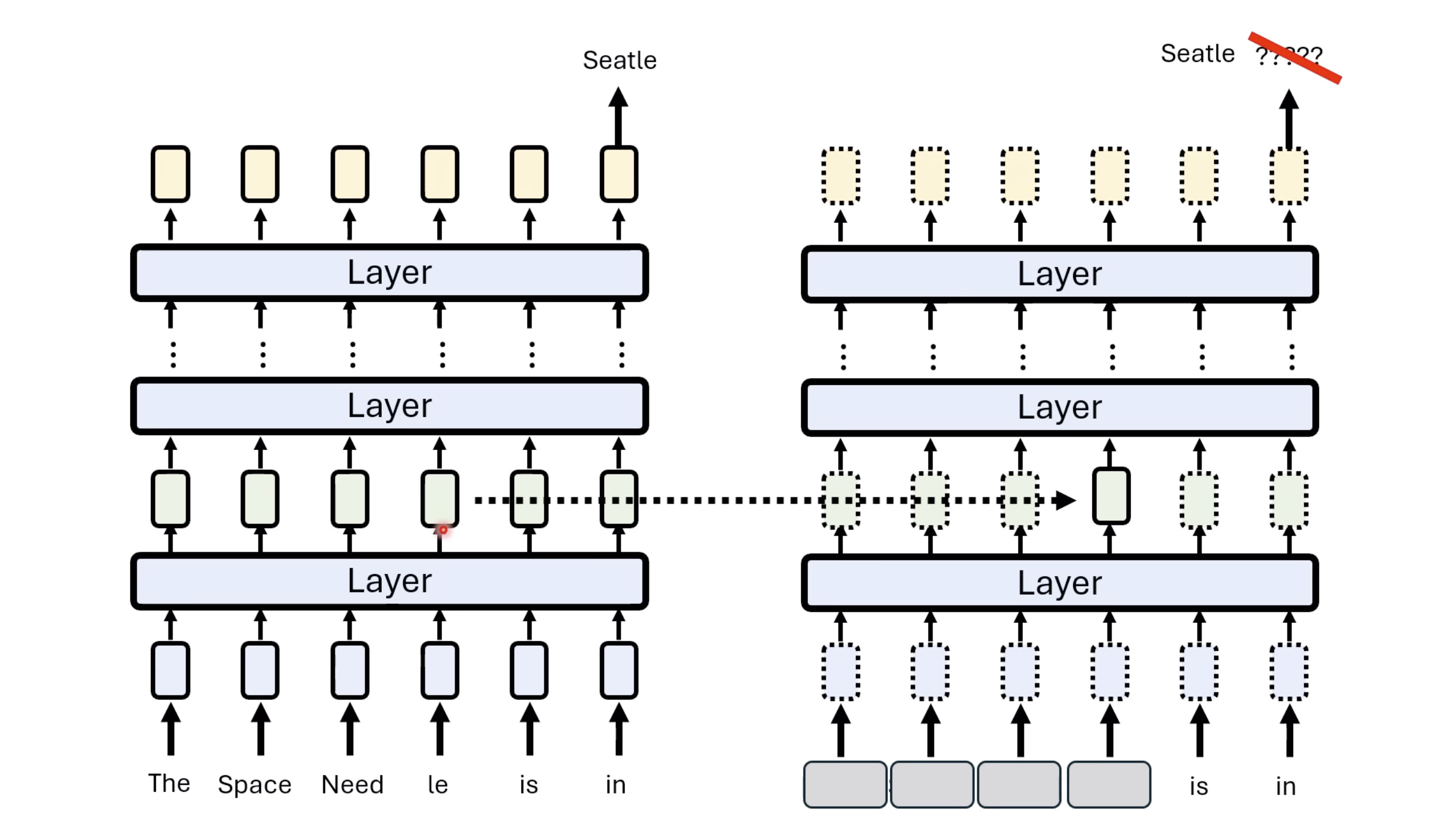
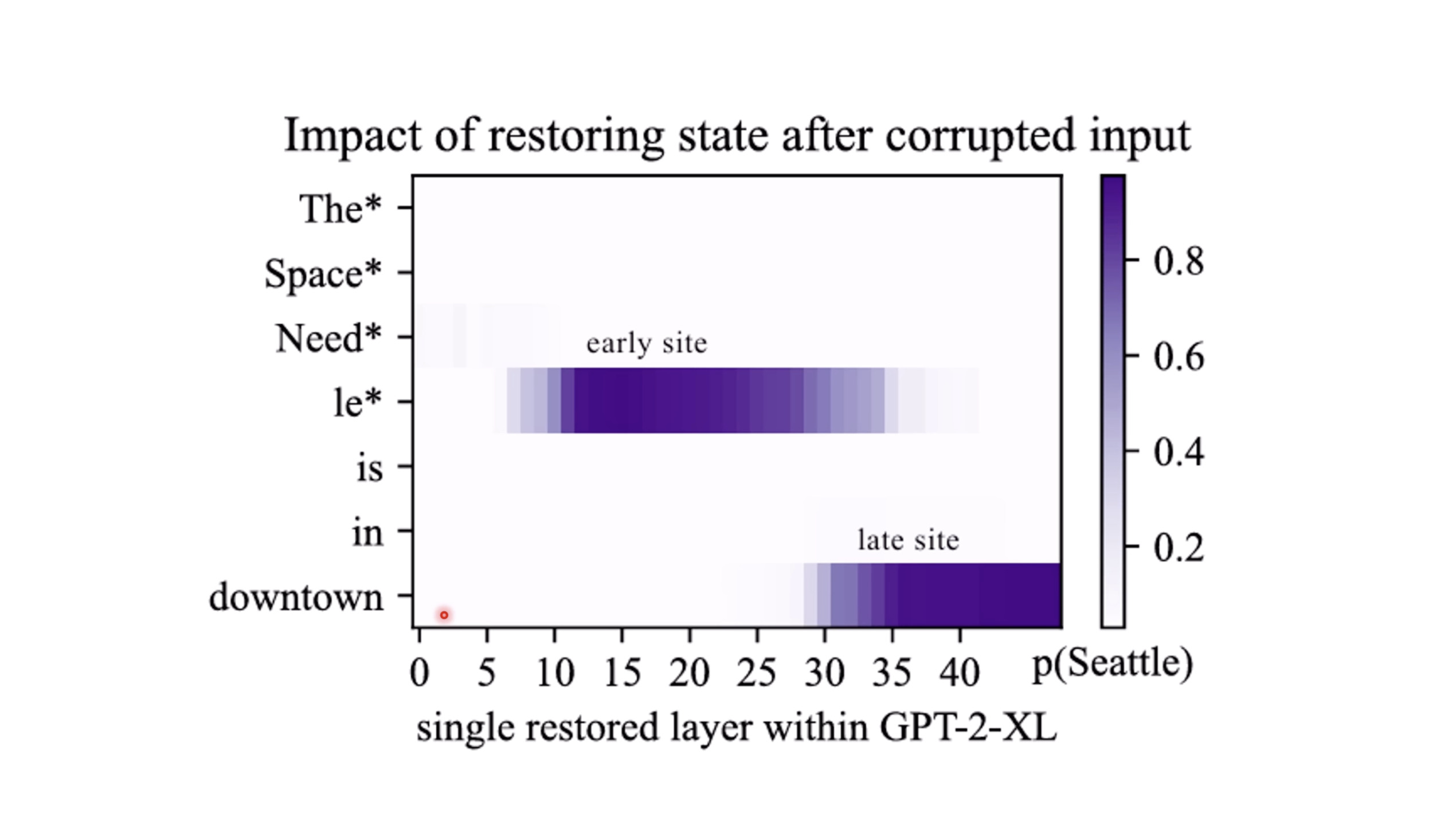
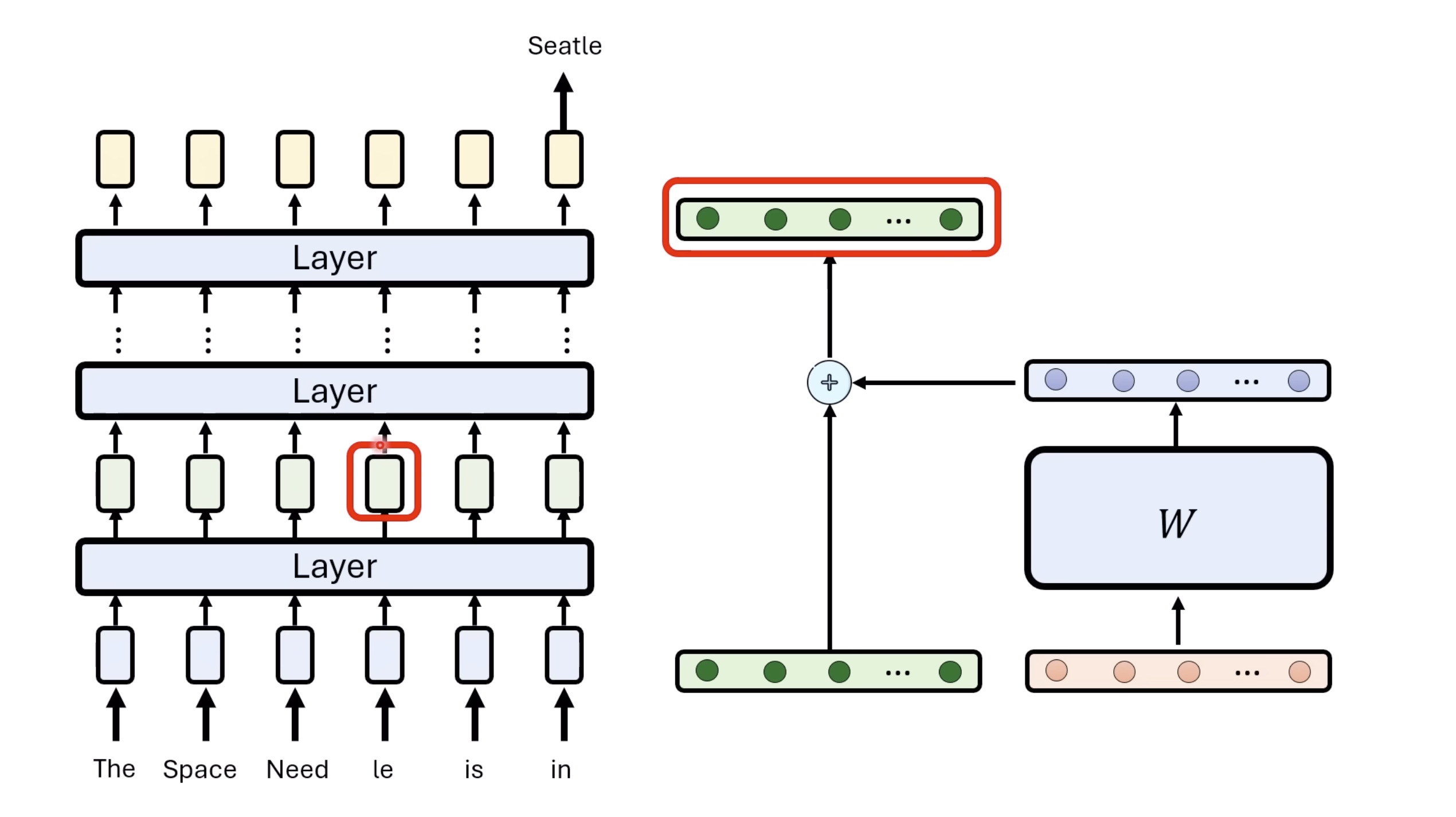
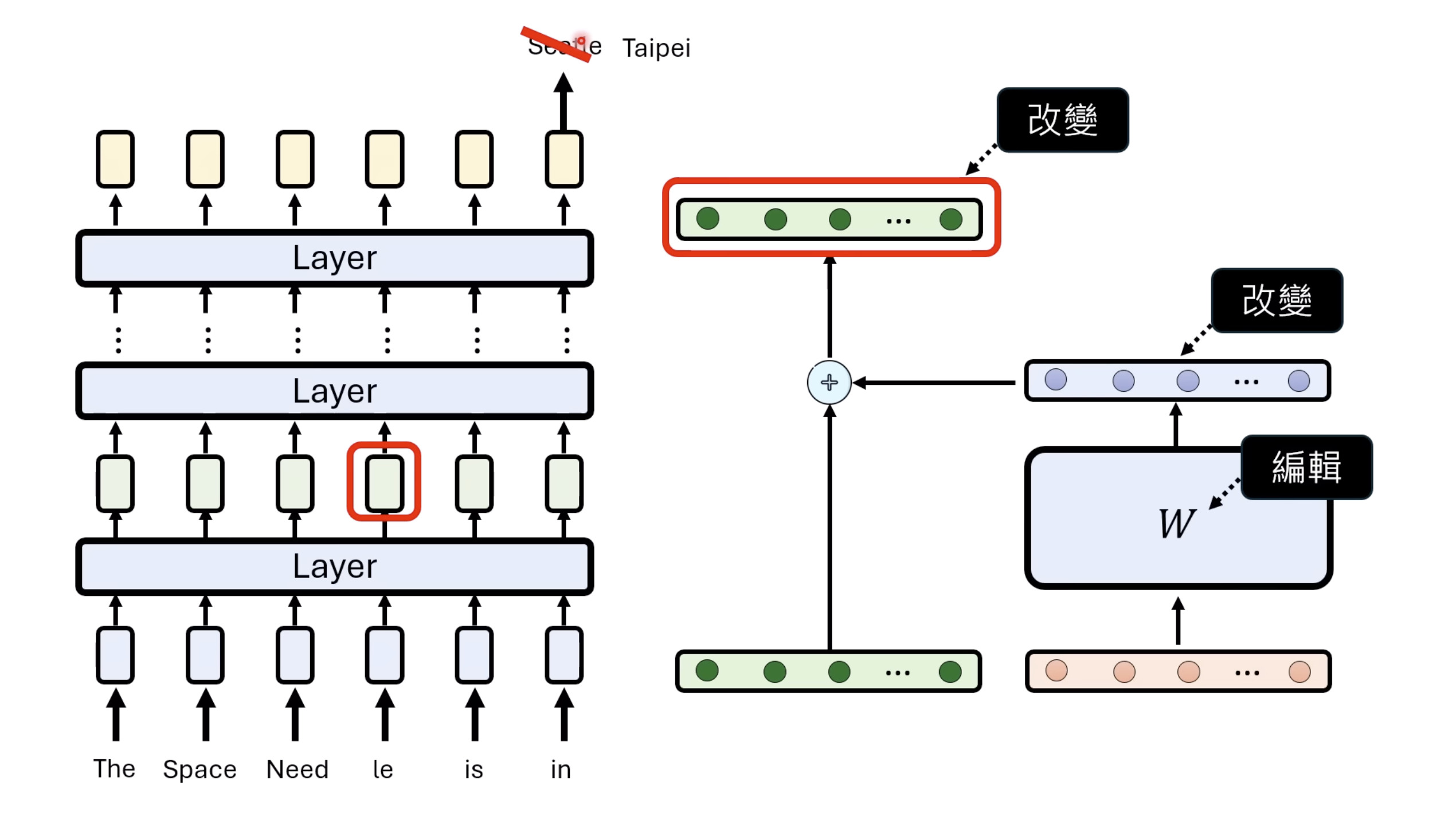
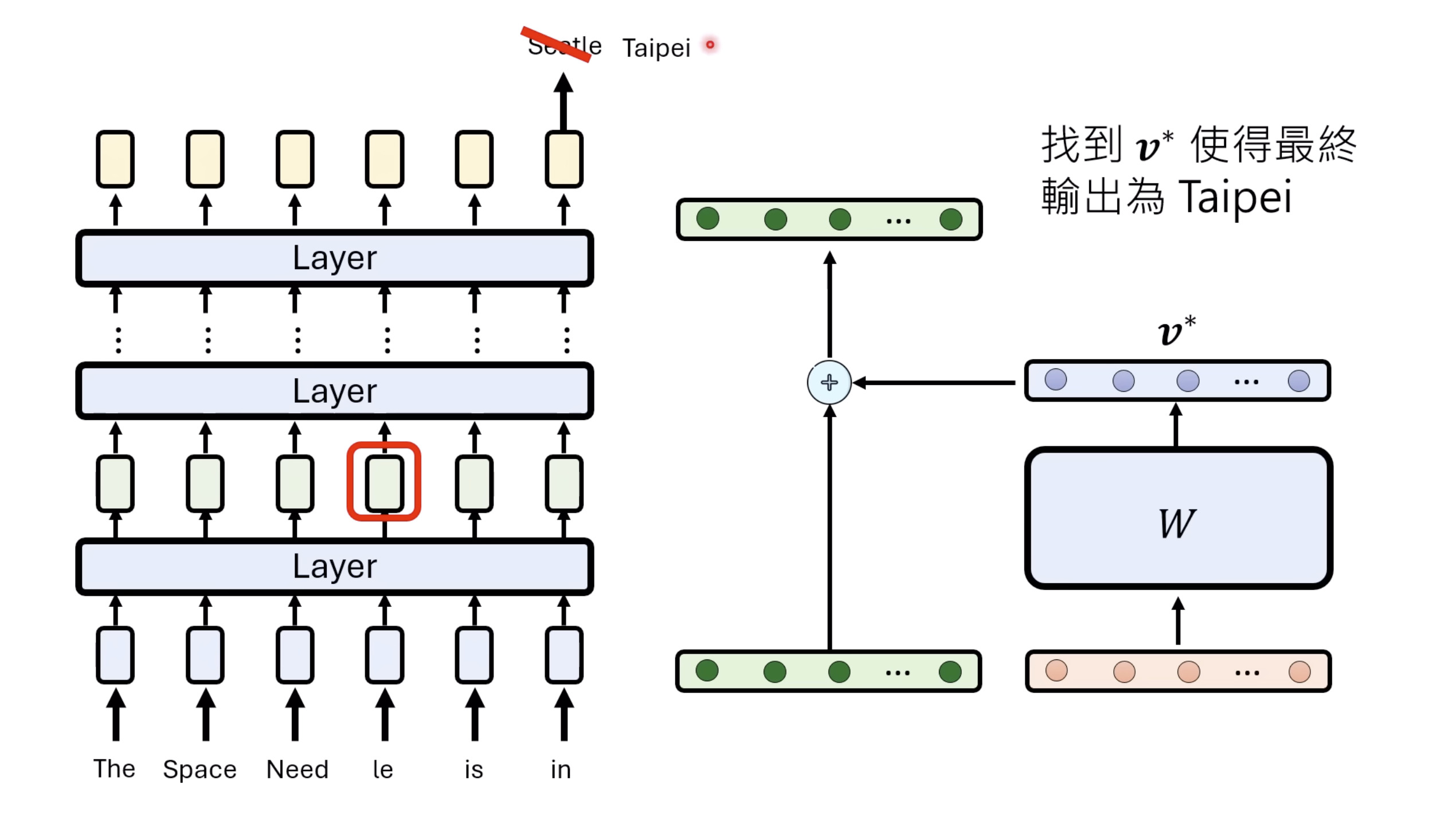
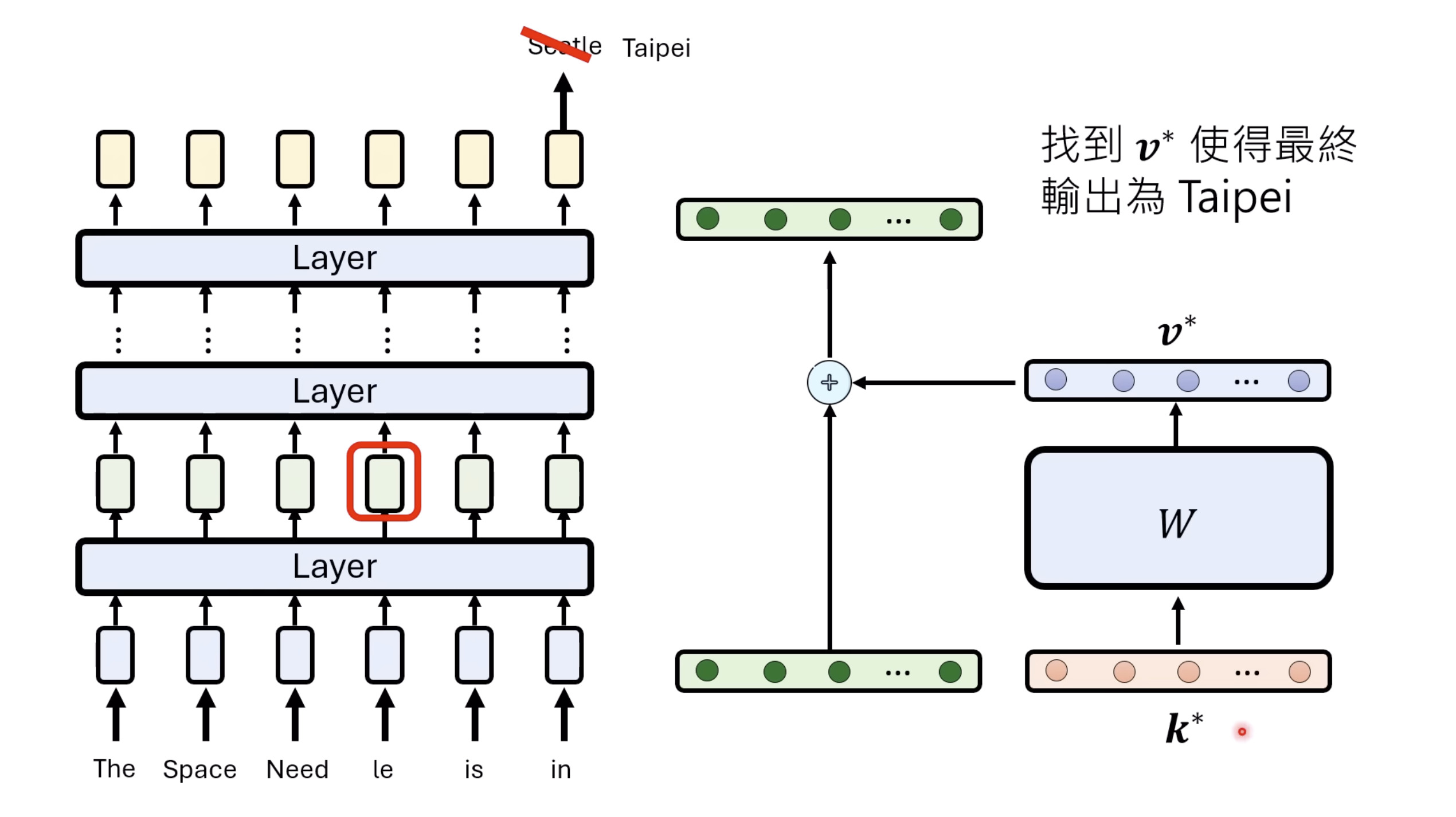
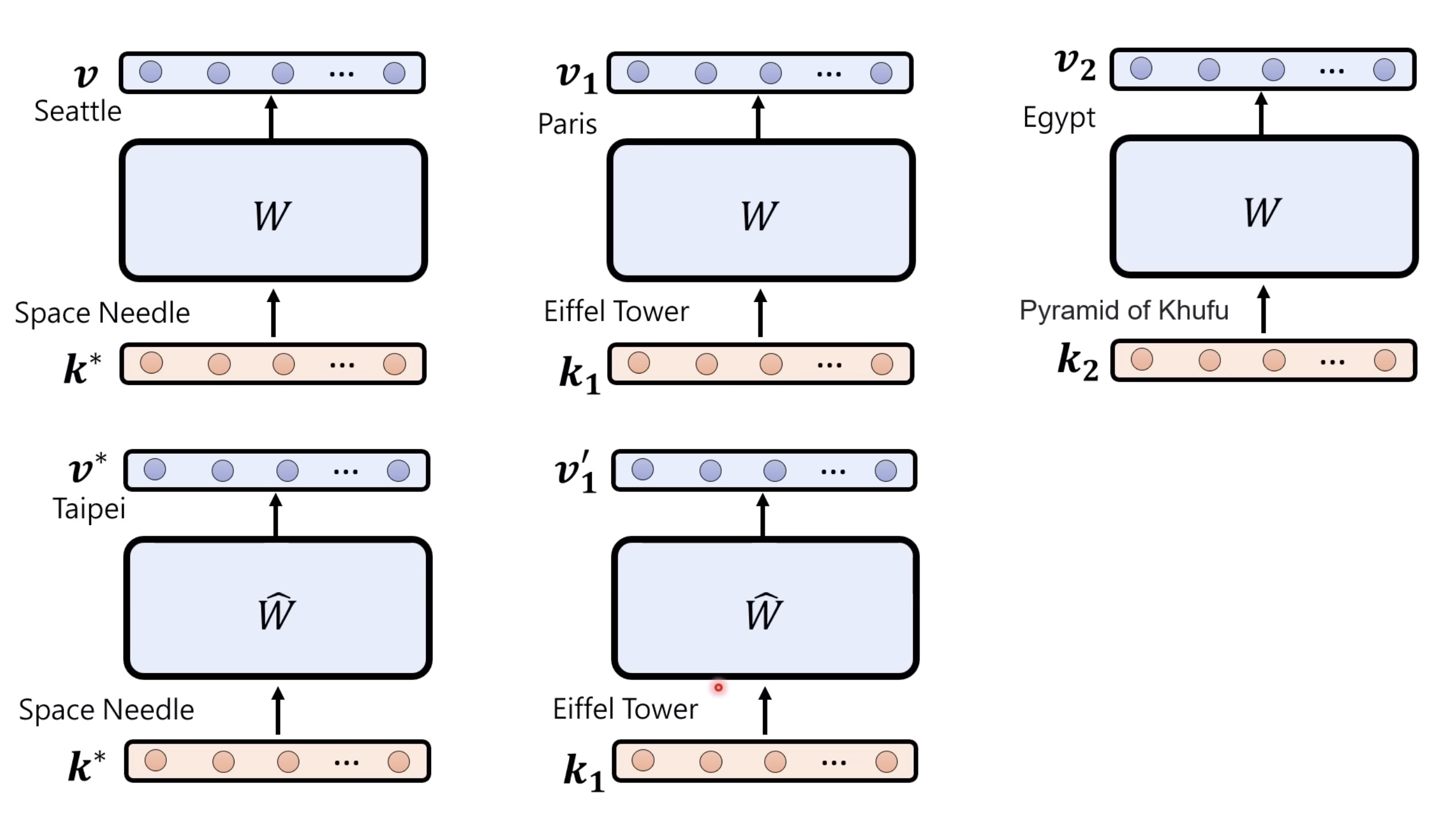
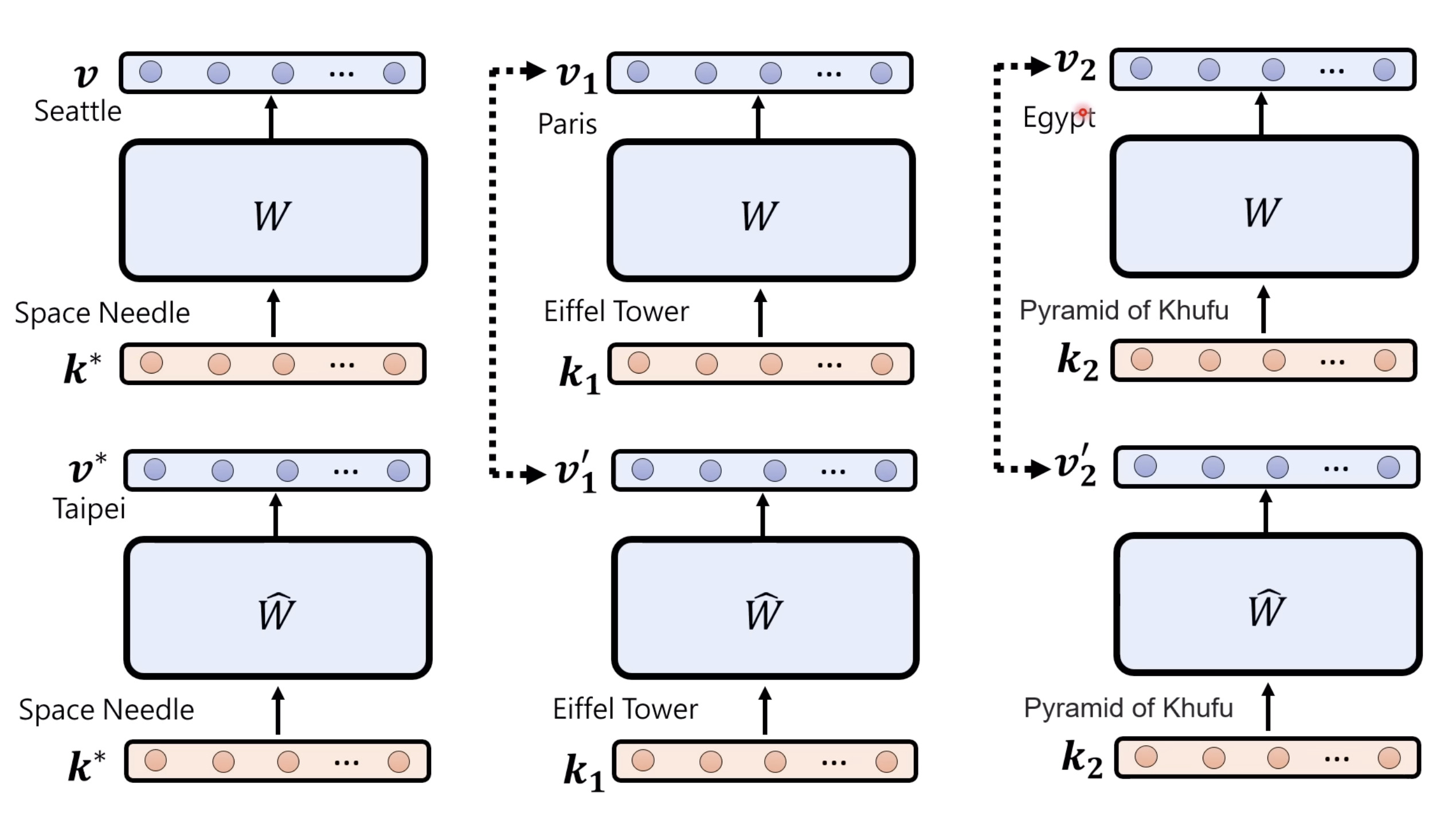
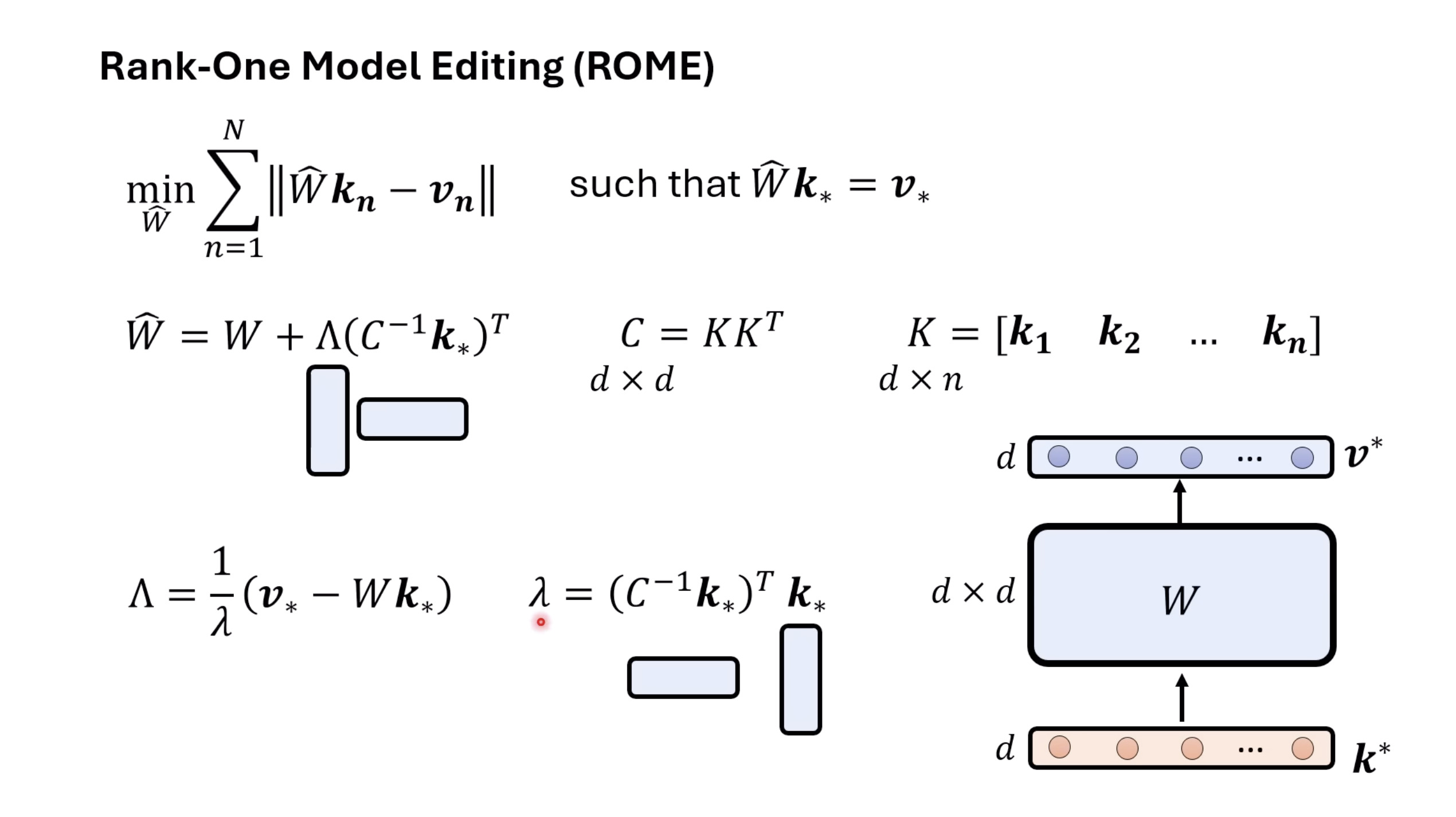
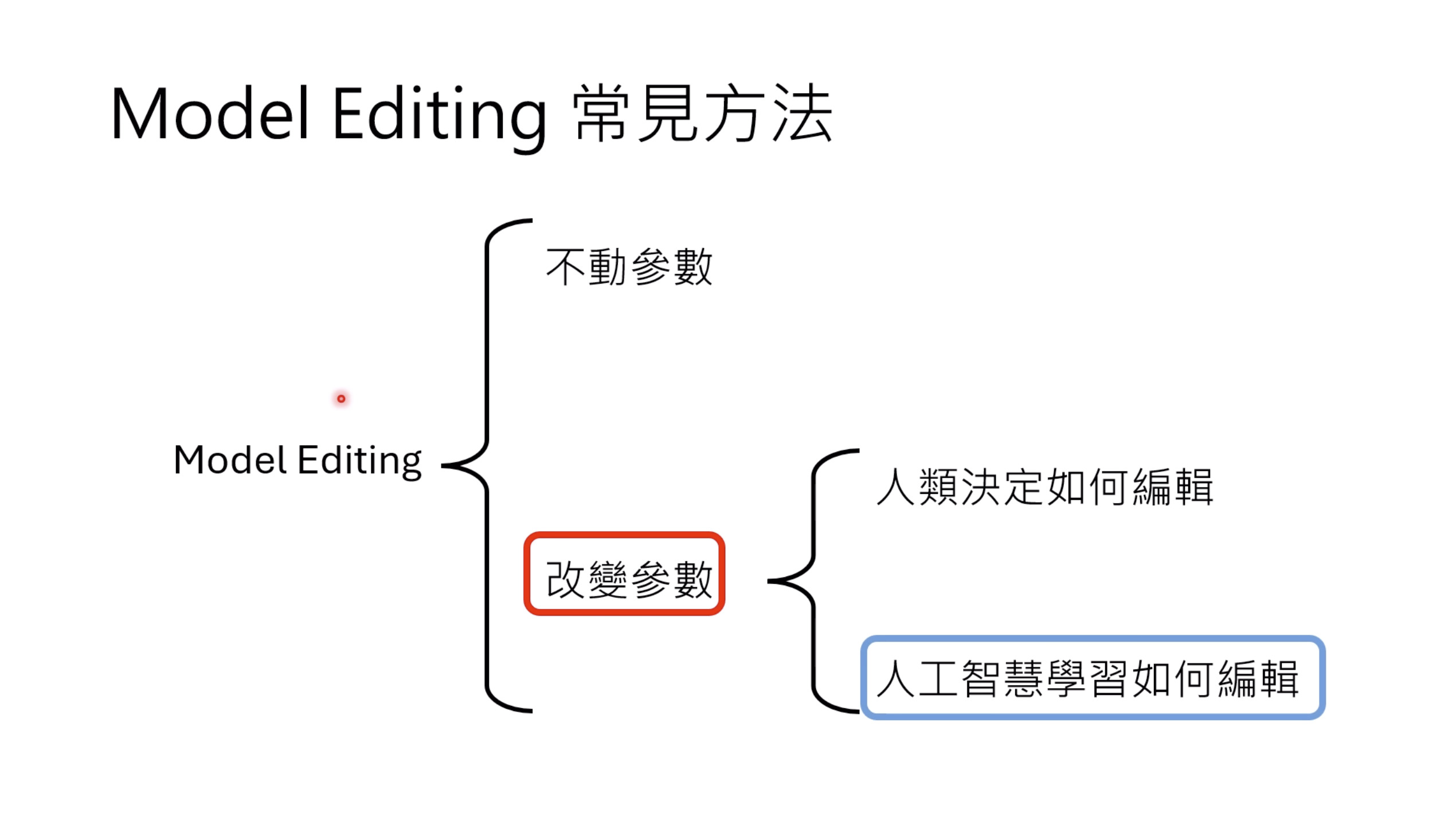
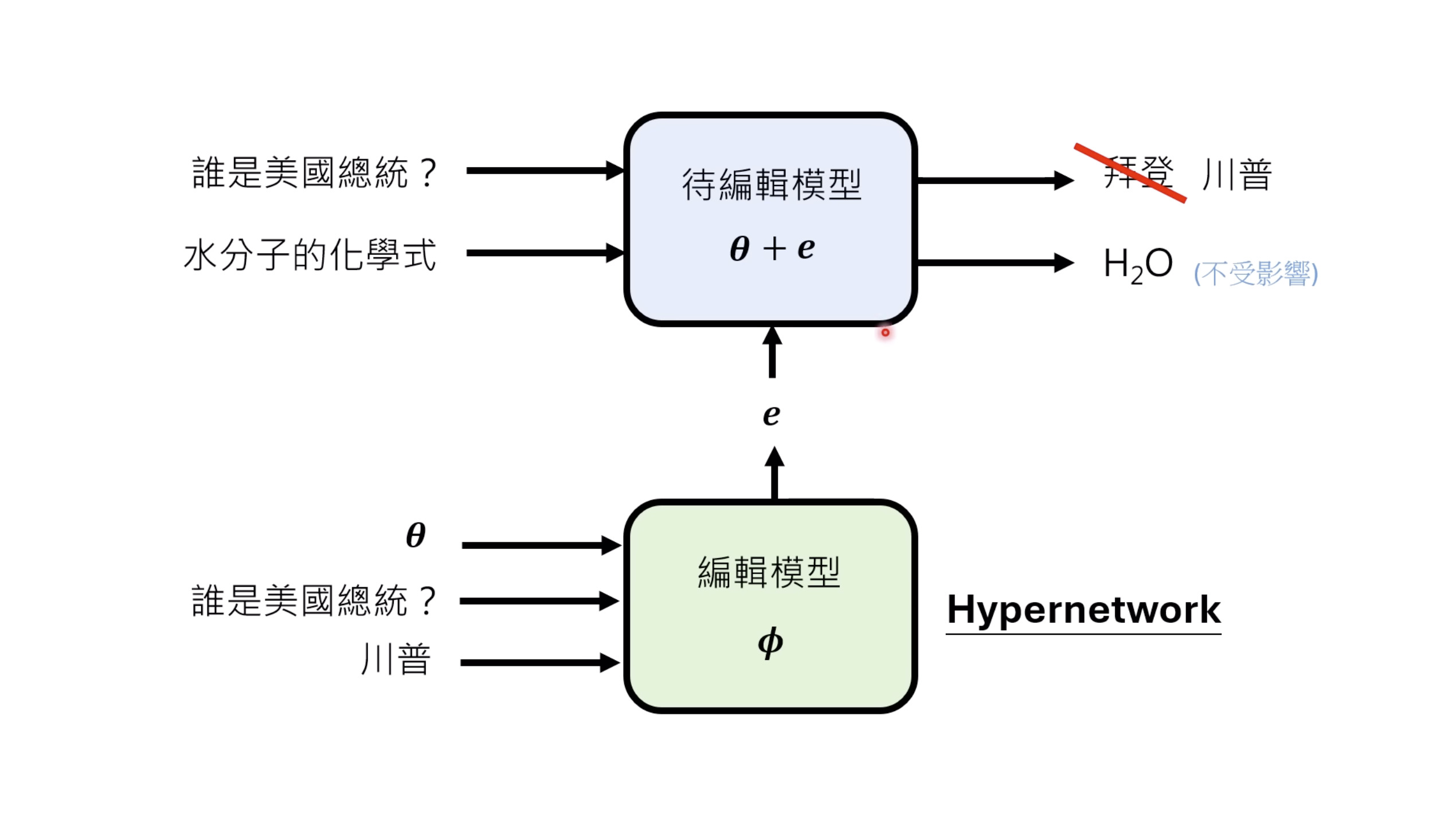
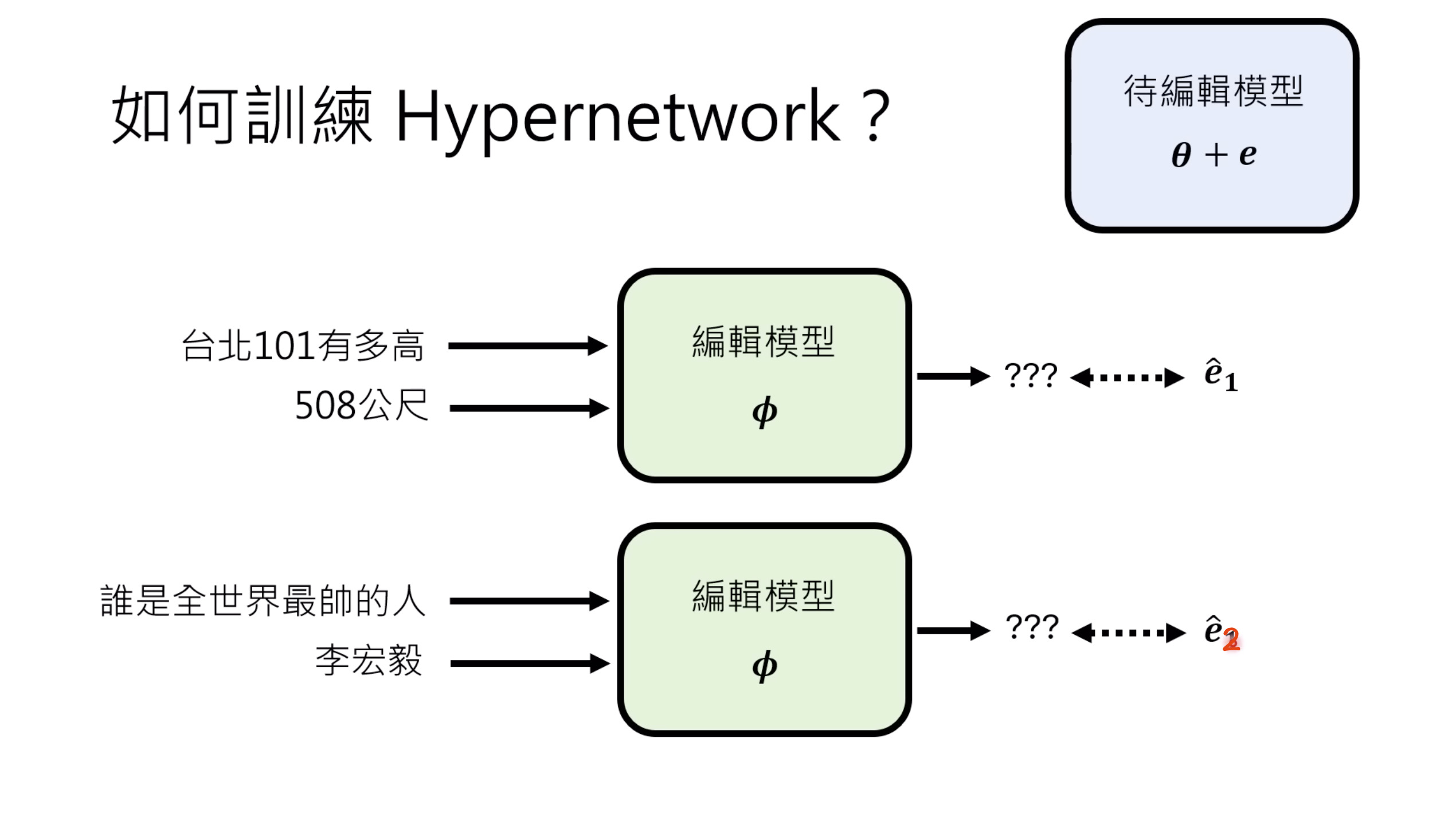
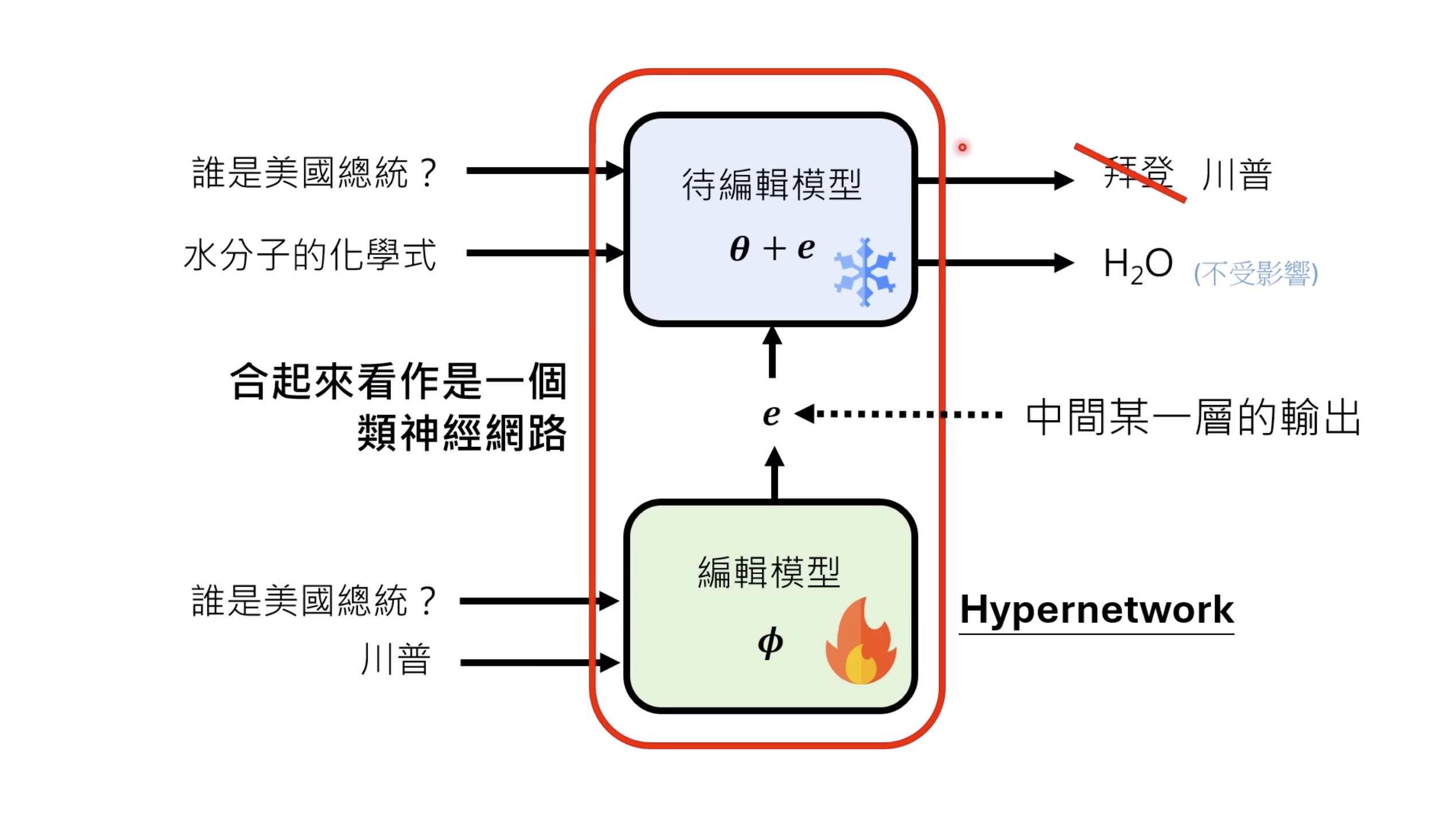
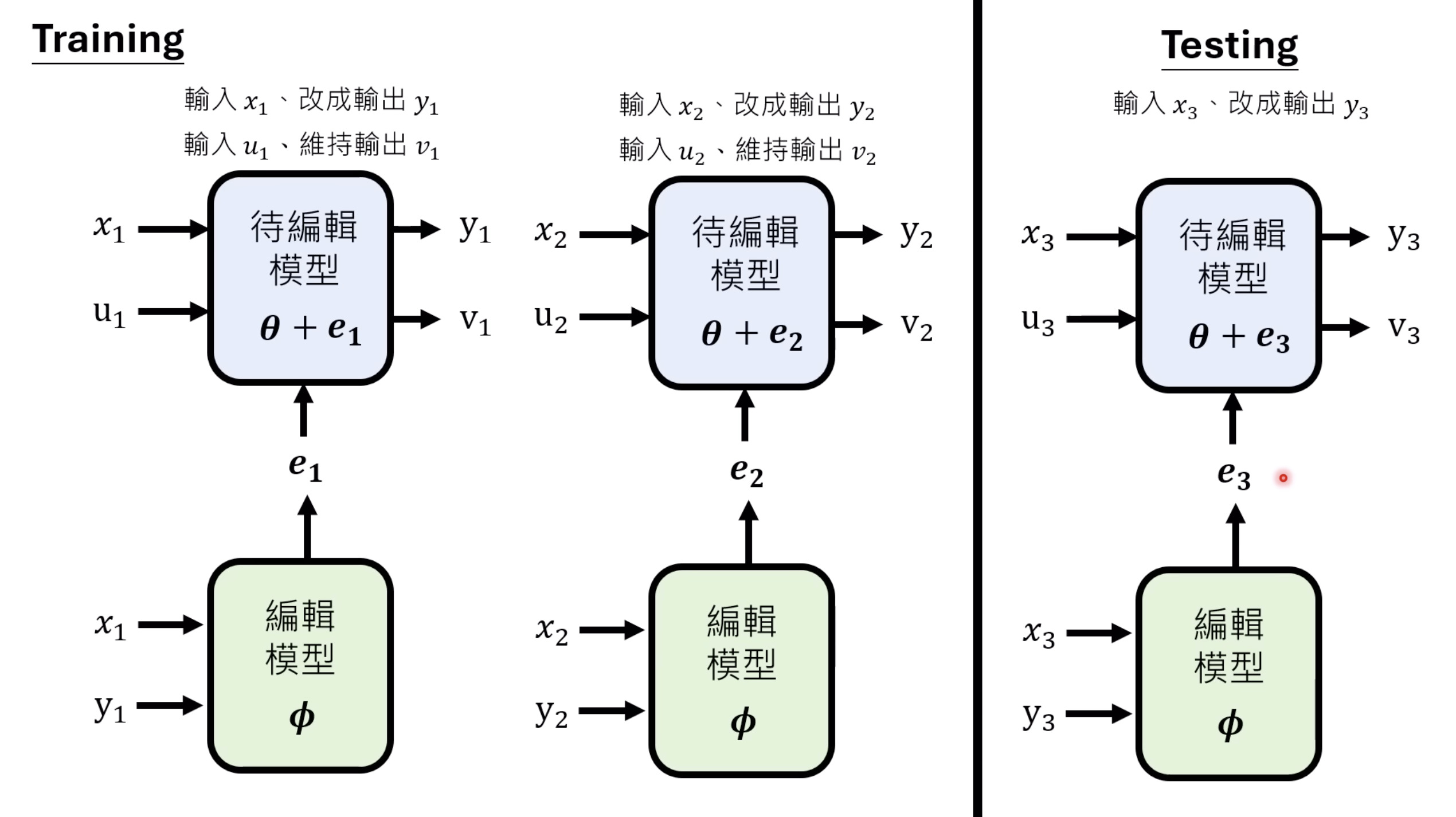
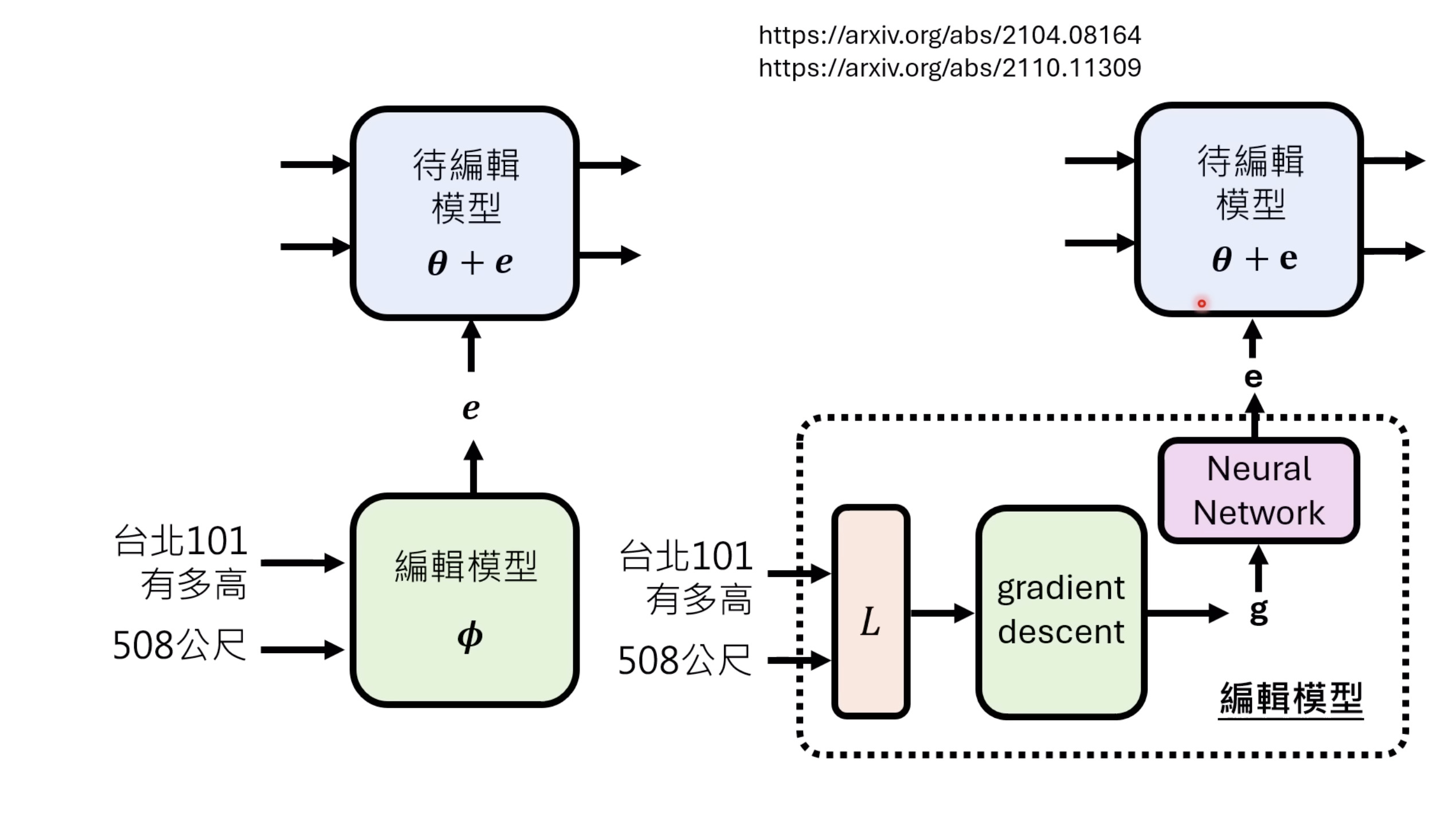
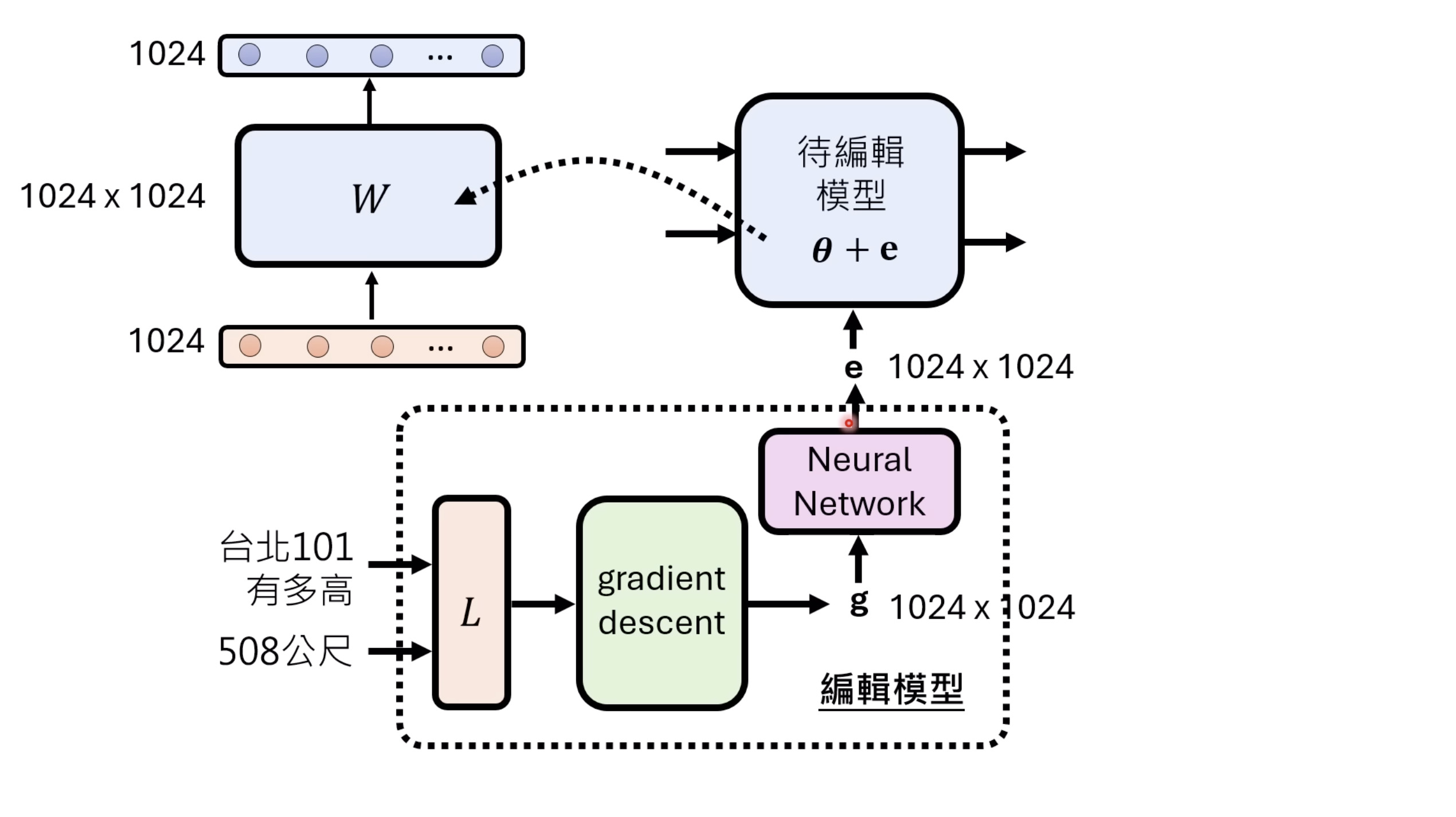
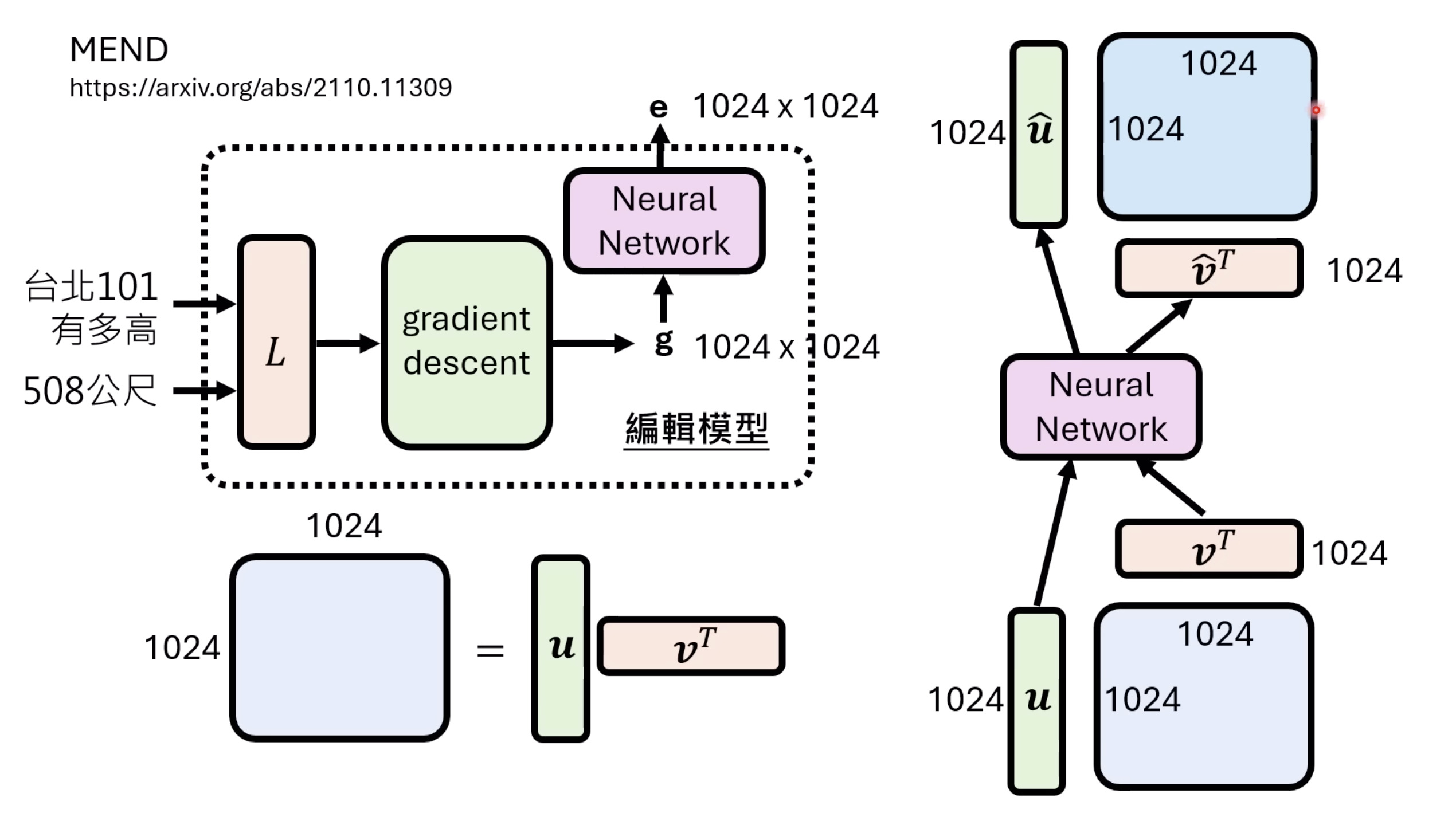
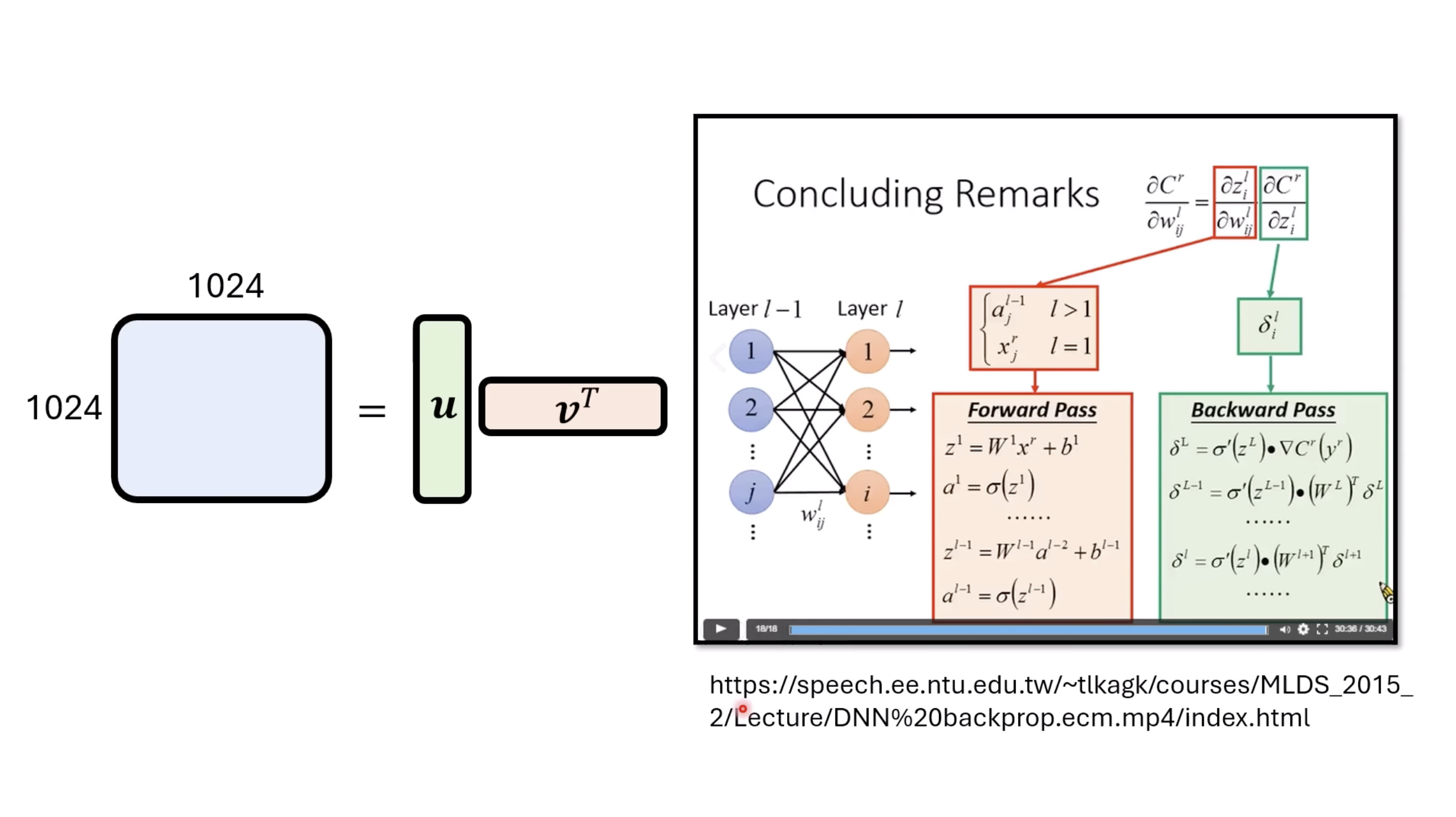
本文档深入探讨了模型编辑,这是一种用于更新人工智能模型知识的技术,而不需进行完全重新训练。它们首先通过对比模型编辑与传统的后训练(Post Training)来解释其概念,其中前者侧重于植入特定事实,而后者旨在学习新技能。接着详细阐述了模型编辑的评估标准,包括可靠性、泛化性和局部性,并介绍了两种主要方法:不改变模型参数和改变模型参数。展示了Rank-One Model Editing (ROME) 方法,它通过直接修改模型内部参数来实现知识更新。最后,还介绍了超网络(Hypernetwork),这是一种让人工智能学习如何进行模型编辑的技术,展示了其训练和测试过程。